AI 开发中的 RAG 简介
本文介绍检索增强生成 (RAG):它的本质、工作原理和关键概念。
什么是检索增强生成?
RAG 是一种技术,它使大型语言模型 (LLM) 能够使用从外部信息源检索到的支持数据来增强用户提示,从而生成经过扩充的响应。 通过合并检索到的这些信息,RAG 使 LLM 能够生成更准确、更高质量的响应,而不是使用额外的上下文来增强提示。
例如,假设你正在构建问答聊天机器人,以帮助员工回答有关公司专有文档的问题。 如果没有专门的培训,独立 LLM 将无法准确回答有关这些文档的内容的问题。 LLM 可能会因为缺乏信息而拒绝回答,或者更糟的是,它可能会生成不正确的响应。
为了解决这个问题,RAG 首先根据用户的查询从公司文档检索相关信息,然后将检索到的信息作为额外的上下文提供给 LLM。 这样,LLM 就可以根据在相关文档中找到的特定详细信息生成更准确的响应。 从本质上讲,RAG 使 LLM 能够“咨询”检索到的信息来表述其答案。
RAG 应用程序的核心组件
RAG 应用程序是复合 AI 系统的一个示例:它通过与其他工具和程序相结合来扩展模型本身的语言功能。
使用独立 LLM 时,用户将请求(如问题)提交给 LLM,LLM 仅根据其训练数据给出答案。
在最基本的形式中,以下步骤在 RAG 应用程序中发生:
- 检索:用户的请求用于查询信息源以外的内容。 这可能意味着查询矢量存储、对某些文本执行关键字搜索或查询 SQL 数据库。 检索步骤的目标是获取支持数据,以帮助 LLM 提供有用的响应。
- 增强:从检索步骤获得的支持数据与用户的请求相结合,通常使用带有附加格式和 LLM 说明的模板来创建提示。
- 生成:生成的提示将传递给 LLM,LLM 将生成对用户请求的响应。
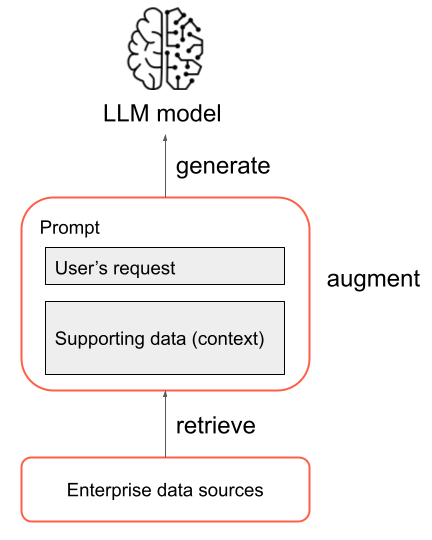
这是 RAG 过程的简化概述,但请务必注意,实现 RAG 应用程序涉及许多复杂任务。 预处理源数据来使其适用于 RAG、有效检索数据、格式化增强提示以及评估生成的响应,这些都需要仔细考虑和努力。 本指南后面的部分将更详细地介绍这些主题。
为何使用 RAG?
下表概述了使用 RAG 对比独立 LLM 的优势:
| 只使用 LLM | 将 LLM 与 RAG 配合使用 |
|---|---|
| 没有专有知识:LLM 通常使用公开可用的数据进行训练,因此它们无法准确回答有关公司内部或专有数据的问题。 | RAG 应用程序可合并专有数据:RAG 应用程序可以将专有文档(如备忘录、电子邮件和设计文档)提供给 LLM,使其能够回答有关这些文档的问题。 |
| 知识不实时更新:LLM 无法访问训练后发生的事件的相关信息。 例如,独立 LLM 目前无法告诉你有关股票走势的任何信息。 | RAG 应用程序可访问实时数据:RAG 应用程序可以从更新的数据源中向 LLM 提供及时的信息,使其能够对超出训练截止日期的事件提供有用的答案。 |
| 缺少引文:LLM 在响应时无法引用特定信息来源,使用户无法验证响应是实际正确还是虚构的。 | RAG 可引用来源:用作 RAG 应用程序的一部分时,可以要求 LLM 引用其来源。 |
| 缺少数据访问控制 (ACL):LLM 无法根据特定用户权限可靠地为不同用户提供不同的答案。 | RAG 允许数据安全/ACL:检索步骤旨在仅查找用户有凭据可访问的信息,使 RAG 应用程序能够有选择地检索个人或专有信息。 |
RAG 类型
RAG 体系结构可以处理两种类型的支持数据:
| 结构化数据 | 非结构化数据 | |
|---|---|---|
| 定义 | 以特定架构按行和列排列的表格数据,例如数据库中的表。 | 没有特定结构或组织的数据,例如包含文本和图像的文档,或者音频或视频等多媒体内容。 |
| 示例数据源 | - BI 或数据仓库系统中的客户记录 - 来自 SQL 数据库的事务数据 - 来自应用程序 API(例如 SAP、Salesforce 等)的数据 |
- BI 或数据仓库系统中的客户记录 - 来自 SQL 数据库的事务数据 - 来自应用程序 API(例如 SAP、Salesforce 等)的数据 - Google 或 Microsoft Office 文档 - Wiki - 图像 - 视频 |
根据用例为 RAG 选择数据。 本教程的其余部分重点介绍非结构化数据的 RAG。