如何创建和查询矢量搜索索引
本文介绍如何使用 Mosaic AI 矢量搜索创建和查询矢量搜索索引。
可使用 UI、Python SDK 或 REST API 创建和管理矢量搜索组件,例如矢量搜索终结点和矢量搜索索引。
要求
- 已启用 Unity Catalog 的工作区。
- 已启用无服务器计算。 有关说明,请参阅连接到无服务器计算。
- 源表必须启用“更改数据馈送”。 有关说明,请参阅在 Azure Databricks 上使用 Delta Lake 更改数据馈送。
- 若要创建索引,必须具有目录架构中支持创建索引的 CREATE TABLE 权限。 若要查询其他用户拥有的索引,必须具有其他权限。 请参阅查询矢量搜索终结点。
- 如果要使用个人访问令牌(不建议用于生产工作负载),请检查是否已启用个人访问令牌。 若要改用服务主体令牌,请使用 SDK 或 API 调用显式传递它。
若要使用 SDK,必须在笔记本中安装它。 使用以下代码:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
from databricks.vector_search.client import VectorSearchClient
创建矢量搜索终结点
可以使用 Databricks UI、Python SDK 或 API 创建矢量搜索终结点。
使用 UI 创建矢量搜索终结点
按照以下步骤使用 UI 创建矢量搜索终结点。
单击左边栏中的“计算”。
单击“矢量搜索”选项卡,然后单击“创建”。

这会打开“创建终结点”窗体。 输入此终结点的名称。
单击“确认” 。
使用 Python SDK 创建矢量搜索终结点
以下示例使用 create_endpoint() SDK 函数创建矢量搜索终结点。
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
使用 REST API 创建矢量搜索终结点
请参阅 REST API 参考文档: POST /api/2.0/vector-search/endpoints。
(可选)创建并配置终结点为嵌入模型提供服务
如果选择让 Databricks 计算嵌入,则可以使用预配置的基础模型 API 终结点或创建模型服务终结点来为所选的嵌入模型提供服务。 有关说明,请参阅按令牌付费的基础模型 API 或创建生成式 AI 模型服务终结点。 有关示例笔记本,请参阅用于调用嵌入模型的笔记本示例。
配置嵌入终结点时,Databricks 建议删除“缩放到零”的默认选择。 服务终结点可能需要几分钟时间来预热,因此在终结点纵向缩减的情况下对索引进行初始查询可能会超时。
注意
如果未为数据集适当配置嵌入终结点,矢量搜索索引初始化可能会超时。 应仅对小型数据集和测试使用 CPU 终结点。 对于较大的数据集,请使用 GPU 终结点实现最佳性能。
创建矢量搜索索引
可以使用 UI、Python SDK 或 REST API 创建矢量搜索索引。 其中 UI 是最简单的方法。
有两种类型的索引:
- “Delta 同步索引”会自动与源 Delta 表同步,并在 Delta 表中的基础数据发生更改时以增量方式自动更新索引。
- “直接矢量访问索引”支持直接读取和写入矢量和元数据。 用户负责使用 REST API 或 Python SDK 更新此表。 无法使用 UI 创建此类索引。 必须使用 REST API 或 SDK 创建。
使用 UI 创建索引
单击左边栏中的“目录”打开目录资源管理器 UI。
导航到你要使用的 Delta 表。
单击右上角的“创建”按钮,然后从下拉菜单中选择“矢量搜索索引”。
使用对话框中的选择器配置索引。
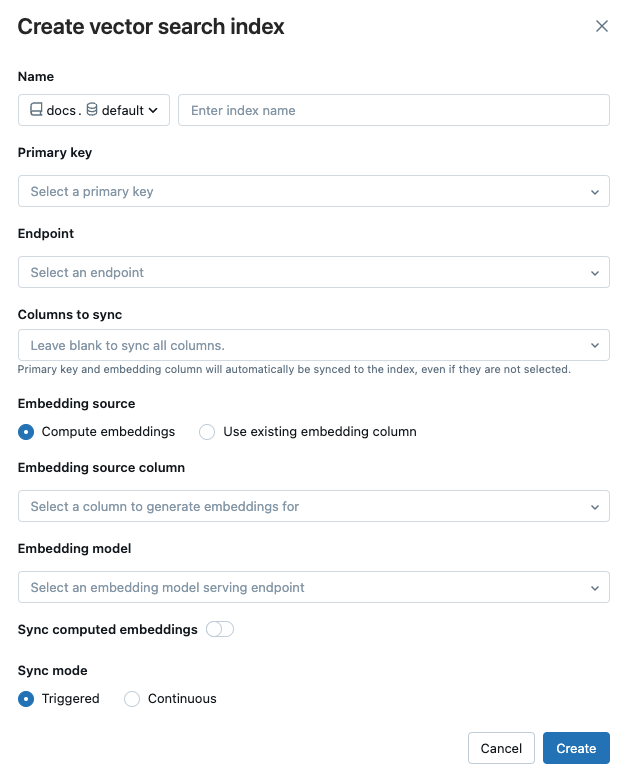
名称:用于 Unity 目录中联机表的名称。 该名称需要三级命名空间
<catalog>.<schema>.<name>。 只允许使用字母数字字符和下划线。主键:用作主键的列。
终结点:选择要使用的矢量搜索终结点。
要同步的列:选择要与矢量索引同步的列。 如果将此字段留空,则源表中的所有列都将与索引同步。 主键列与内嵌源列或内嵌矢量列会始终保持同步。
嵌入源:指示是否希望 Databricks 计算 Delta 表中文本列的嵌入(计算嵌入),或者 Delta 表是否包含预先计算的嵌入(使用现有嵌入列)。
- 如果选择了“计算嵌入”,请选择要为其计算嵌入的列以及为嵌入模型提供服务的终结点。 仅支持文本列。
- 如果选择了“使用现有嵌入列”,请选择包含预先计算的嵌入和嵌入维度的列。 预计算的嵌入列的格式应为
array[float]。
同步计算的嵌入内容:开启此设置,将生成的嵌入内容保存到 Unity Catalog 表。 有关详细信息,请参阅保存生成的嵌入内容表。
同步模式:“连续”模式使索引与延迟秒数保持同步。 但是,由于预配了计算群集以运行连续同步流式处理管道,因此它的成本更高。 对于“连续”和“触发”,更新都是增量更新,即只处理自上次同步以来发生更改的数据。
使用 触发的 同步模式,可以使用 Python SDK 或 REST API 启动同步。请参阅 更新增量同步索引。
完成索引配置后,单击“创建”。
使用 Python SDK 创建索引
以下示例使用 Databricks 计算的嵌入创建 Delta 同步索引。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
以下示例使用自托管嵌入创建增量同步索引。 此示例还演示了如何使用可选参数 columns_to_sync 来仅选择要在索引中使用的列子集。
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
默认情况下,源表中的所有列都将与索引同步。 若要仅同步列的子集,请使用 columns_to_sync。 主键和嵌入列始终包含在索引中。
若要仅同步主键和嵌入列,必须按如下所示在 columns_to_sync 中指定对应的主键和列:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
若要同步其他列,请指定列,如下所示。 无需包括主键和嵌入列,因为它们始终是同步的。
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
以下示例创建直接矢量访问索引。
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
使用 REST API 创建索引
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes。
保存生成的嵌入内容表
如果 Databricks 生成嵌入内容,可以将生成的嵌入内容保存到 Unity Catalog 的表中。 此表是在与矢量索引相同的架构中创建的,并且是从向量索引页链接的。
表的名称是矢量搜索索引的名称,后面追加了 _writeback_table。 该名称不可编辑。
你可以像 Unity Catalog 中的任何其他表一样访问和查询该表。 但是,不应删除或修改该表,因为它未采用手动更新设计。 如果删除索引,则会自动删除该表。
更新矢量搜索索引
更新增量同步索引
以“连续”同步模式创建的索引在源 Delta 表更改时会自动更新。 如果使用 触发同步 模式,请使用 Python SDK 或 REST API 启动同步。
Python SDK
index.sync()
REST API
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes/{index_name}/sync。
更新直接矢量访问索引
可以使用 Python SDK 或 REST API 在直接矢量访问索引中插入、更新或删除数据。
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes。
下面的代码示例演示如何使用个人访问令牌(PAT)更新索引。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
下面的代码示例演示如何使用服务主体更新索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
查询矢量搜索终结点
只能使用 Python SDK、REST API 或 SQL vector_search() AI 函数查询矢量搜索终结点。
注意
如果查询终结点的用户不是矢量搜索索引的所有者,则用户必须具有以下 UC 权限:
- 对包含矢量搜索索引的目录具有 USE CATALOG 权限。
- 对包含矢量搜索索引的架构具有 USE SCHEMA 权限。
- 对矢量搜索索引具有 SELECT 权限。
要执行混合关键字相似度搜索,请将参数 query_type 设置为 hybrid。 默认值为 ann(近似最近的邻域)。
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
请参阅 REST API 参考文档: POST /api/2.0/vector-search/indexes/{index_name}/query。
下面的代码示例演示如何使用个人访问令牌(PAT)查询索引。
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
下面的代码示例演示如何使用服务主体查询索引。
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
重要
vector_search() AI 函数处于公共预览状态。
若要使用此 AI 函数,请参阅 vector_search 函数。
对查询使用筛选器
查询可以根据 Delta 表中的任何列定义筛选器。 similarity_search 仅返回与指定筛选器匹配的行。 支持以下筛选器:
| 筛选器运算符 | 行为 | 示例 |
|---|---|---|
NOT |
对筛选器求反。 键必须以“NOT”结尾。 例如,值为“red”的“color NOT”与颜色不为红色的文档匹配。 | {"id NOT": 2} {“color NOT”: “red”} |
< |
检查字段值是否小于筛选器值。 键必须以“<”结尾。 例如,值为 200 的“price <”与价格小于 200 的文档匹配。 | {"id <": 200} |
<= |
检查字段值是否小于或等于筛选器值。 键必须以“<=”结尾。 例如,值为 200 的“price <=”与价格小于或等于 200 的文档匹配。 | {"id <=": 200} |
> |
检查字段值是否大于筛选器值。 键必须以“>”结尾。 例如,值为 200 的“price >”与价格大于 200 的文档匹配。 | {"id >": 200} |
>= |
检查字段值是否大于或等于筛选器值。 键必须以“>=”结尾。 例如,值为 200 的“price >=”与价格大于或等于 200 的文档匹配。 | {"id >=": 200} |
OR |
检查字段值是否与任何一个筛选器值匹配。 键必须包含 OR 以分隔多个子键。 例如,值为 ["red", "blue"] 的 color1 OR color2 与 color1 为 red 或 color2 为 blue 的文档匹配。 |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
匹配部分字符串。 | {"column LIKE": "hello"} |
| 未指定筛选器运算符 | 筛选器检查是否完全匹配。 如果指定了多个值,则它与其中的任何值匹配。 | {"id": 200} {"id": [200, 300]} |
查看以下代码示例:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
请参阅 POST /api/2.0/vector-search/indexes/{index_name}/query。
示例笔记本
本节中的示例演示了矢量搜索 Python SDK 的用法。
LangChain 示例
请参阅如何将 LangChain 与 Mosaic AI 矢量搜索配合使用,以按与 LangChain 集成的方式使用 Mosaic AI 矢量搜索。
以下笔记本演示如何将相似性搜索结果转换为 LangChain 文档。
矢量搜索与 Python SDK 笔记本
用于调用嵌入模型的笔记本示例
以下笔记本演示了如何配置用于嵌入生成的 Mosaic AI 模型服务终结点。