在代码中创作 AI 代理
本文介绍如何使用 MLflow ChatModel在代码中创作 AI 代理。 Azure Databricks 利用 MLflow ChatModel 来确保与 Databricks AI 代理功能(例如评估、跟踪和部署)的兼容性。
什么是 ChatModel?
ChatModel 是一个 MLflow 类,旨在简化聊天 AI 代理的创建。 它提供了一个标准化接口,用于生成与 openAI 的 ChatCompletion API兼容的模型。
ChatModel 扩展 OpenAI 的 ChatCompletion 架构。 此方法允许你与支持 ChatCompletion 标准的平台保持广泛的兼容性,同时添加自己的自定义功能。
通过使用 ChatModel,开发人员可以创建与 Databricks 和 MLflow 工具兼容的代理,以便进行代理跟踪、评估和生命周期管理,这对于部署生产就绪模型至关重要。
请参阅 MLflow:ChatModel 入门。
要求
Databricks 建议在开发代理时安装最新版本的 MLflow Python 客户端。
若要使用本文中的方法创作和部署代理,必须满足以下要求:
- 安装
databricks-agents版本 0.15.0 及更高版本 - 安装
mlflow版本 2.20.0 及更高版本
%pip install -U -qqqq databricks-agents>=0.15.0 mlflow>=2.20.0
创建 ChatModel 代理
可以将您的代理编写为 mlflow.pyfunc.ChatModel的子类。 此方法具有以下优势:
- 允许使用类型化的 Python 类编写与 ChatCompletion 架构兼容的代理代码。
- 即使没有
input_example,MLflow 也会在记录代理时自动推断聊天补全兼容的签名。 这简化了注册和部署代理的过程。 请参阅在日志记录期间推断模型签名。
以下代码最好在 Databricks 笔记本中执行。 笔记本提供了一个方便的环境,用于开发、测试和迭代代理。
MyAgent 类扩展 mlflow.pyfunc.ChatModel,实现所需的 predict 方法。 这可确保与马赛克 AI 代理框架兼容。
该类还包括用于处理流输出的可选方法 _create_chat_completion_chunk 和 predict_stream。
from dataclasses import dataclass
from typing import Optional, Dict, List, Generator
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import (
# Non-streaming helper classes
ChatCompletionRequest,
ChatCompletionResponse,
ChatCompletionChunk,
ChatMessage,
ChatChoice,
ChatParams,
# Helper classes for streaming agent output
ChatChoiceDelta,
ChatChunkChoice,
)
class MyAgent(ChatModel):
"""
Defines a custom agent that processes ChatCompletionRequests
and returns ChatCompletionResponses.
"""
def predict(self, context, messages: list[ChatMessage], params: ChatParams) -> ChatCompletionResponse:
last_user_question_text = messages[-1].content
response_message = ChatMessage(
role="assistant",
content=(
f"I will always echo back your last question. Your last question was: {last_user_question_text}. "
)
)
return ChatCompletionResponse(
choices=[ChatChoice(message=response_message)]
)
def _create_chat_completion_chunk(self, content) -> ChatCompletionChunk:
"""Helper for constructing a ChatCompletionChunk instance for wrapping streaming agent output"""
return ChatCompletionChunk(
choices=[ChatChunkChoice(
delta=ChatChoiceDelta(
role="assistant",
content=content
)
)]
)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
last_user_question_text = messages[-1].content
yield self._create_chat_completion_chunk(f"Echoing back your last question, word by word.")
for word in last_user_question_text.split(" "):
yield self._create_chat_completion_chunk(word)
agent = MyAgent()
model_input = ChatCompletionRequest(
messages=[ChatMessage(role="user", content="What is Databricks?")]
)
response = agent.predict(context=None, model_input=model_input)
print(response)
在一个笔记本中定义代理类 MyAgent 时,应创建单独的驱动程序笔记本。 驱动程序笔记本将代理记录到模型注册表,并使用 Model Service 部署代理。
这种区分遵循 Databricks 建议的工作流,以便使用 MLflow 的 "Models from Code" 方法记录模型。
示例:在 ChatModel 中包装 LangChain
如果你有现有的 LangChain 模型并想要将其与其他马赛克 AI 代理功能集成,则可以将其包装在 MLflow ChatModel 中,以确保兼容性。
此代码示例执行以下步骤,将 LangChain 运行对象包装成 ChatModel:
- 使用
mlflow.langchain.output_parsers.ChatCompletionOutputParser包装 LangChain 的最终输出,以生成聊天完成输出签名 LangchainAgent类扩展mlflow.pyfunc.ChatModel并实现两个关键方法:predict:通过调用链并返回格式化的响应来处理同步预测。predict_stream:通过调用链并生成响应区块来处理流式预测。
from mlflow.langchain.output_parsers import ChatCompletionOutputParser
from mlflow.pyfunc import ChatModel
from typing import Optional, Dict, List, Generator
from mlflow.types.llm import (
ChatCompletionResponse,
ChatCompletionChunk
)
chain = (
<your chain here>
| ChatCompletionOutputParser()
)
class LangchainAgent(ChatModel):
def _prepare_messages(self, messages: List[ChatMessage]):
return {"messages": [m.to_dict() for m in messages]}
def predict(
self, context, messages: List[ChatMessage], params: ChatParams
) -> ChatCompletionResponse:
question = self._prepare_messages(messages)
response_message = self.chain.invoke(question)
return ChatCompletionResponse.from_dict(response_message)
def predict_stream(
self, context, messages: List[ChatMessage], params: ChatParams
) -> Generator[ChatCompletionChunk, None, None]:
question = self._prepare_messages(messages)
for chunk in chain.stream(question):
yield ChatCompletionChunk.from_dict(chunk)
使用参数配置代理
在代理框架中,可以使用参数来控制代理的执行方式。 这样,您可以在不更改代码的情况下,通过特征的变化快速迭代代理。 参数是在 Python 字典或 .yaml 文件中定义的键值对。
若要配置代码,请创建 ModelConfig(一组键值参数)。 ModelConfig 是 Python 字典或 .yaml 文件。 例如,可以在开发期间使用字典,然后将其转换为生产部署和 CI/CD .yaml 文件。 有关 ModelConfig的详细信息,请参阅 MLflow 文档。
下面显示了一个示例 ModelConfig。
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
若要从代码调用配置,请使用以下项之一:
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
value = model_config.get('sample_param')
设置检索器架构
AI 代理通常使用检索器,这是一种使用矢量搜索索引查找和返回相关文档的代理工具。 有关检索器的详细信息,请参阅 非结构化检索 AI 代理工具。
若要确保检索器跟踪正确,请在代码中定义代理时调用 mlflow.models.set_retriever_schema。 使用 set_retriever_schema 将返回表中的列名映射到 MLflow 的预期字段,例如 primary_key、text_column和 doc_uri。
# Define the retriever's schema by providing your column names
# These strings should be read from a config dictionary
mlflow.models.set_retriever_schema(
name="vector_search",
primary_key="chunk_id",
text_column="text_column",
doc_uri="doc_uri"
# other_columns=["column1", "column2"],
)
注释
在评估检索器的性能时,doc_uri 列尤为重要。 doc_uri 是检索器返回的文档的主要标识符,使你可以将它们与地面真相评估集进行比较。 请参阅评估集。
还可以通过在 other_columns 字段中提供列名列表,在检索器的架构中指定其他列。
如果有多个检索器,则可以为每个检索器架构使用唯一名称来定义多个架构。
自定义输入和输出
某些方案可能需要其他代理输入,例如 client_type 和 session_id,或者检索源链接等输出,这些源链接不应包含在聊天历史记录中供将来交互使用。
对于这些场景,MLflow ChatModel 本机支持使用 ChatParams 字段 custom_input 和 custom_output 来增强 OpenAI 聊天补全请求和响应。
请参阅以下示例,了解如何为 PyFunc 和 LangGraph 代理创建自定义输入和输出。
警告
代理评估评审应用目前不支持为具有其他输入字段的代理呈现跟踪。
PyFunc 自定义架构
以下笔记本显示了使用 PyFunc 的自定义架构示例。
PyFunc 自定义架构代理笔记本
PyFunc 自定义架构驱动程序笔记本
LangGraph 自定义架构
以下笔记本显示了使用 LangGraph 的自定义架构示例。 可以修改笔记本中的 wrap_output 函数,以便从消息流中分析和提取信息。
LangGraph 自定义架构代理笔记本
LangGraph 自定义架构驱动程序笔记本
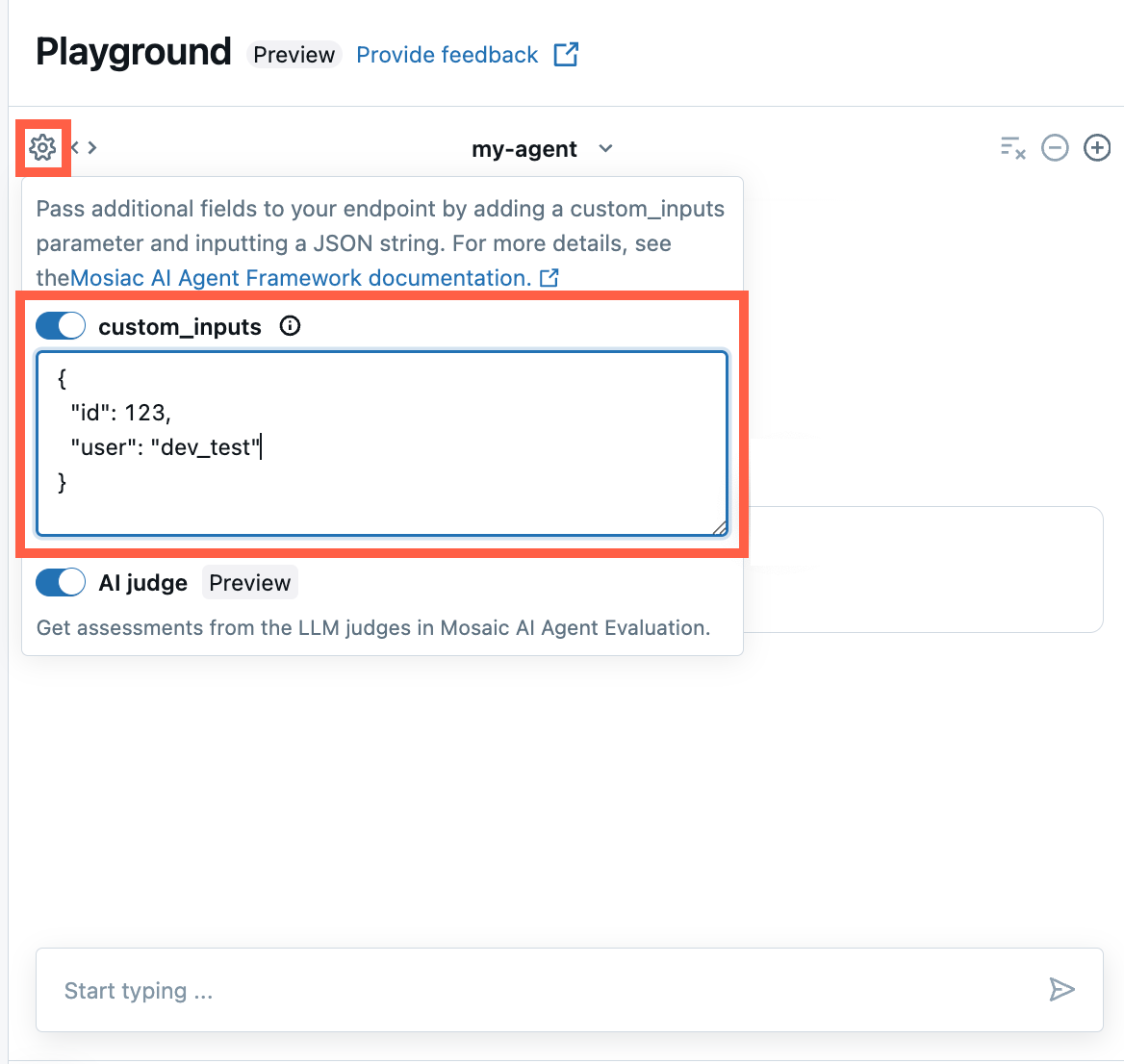
在 AI 操场和代理评审应用中提供 custom_inputs
如果代理使用 custom_inputs 字段接受其他输入,则可以在 AI Playground 和 代理评审应用中手动提供这些输入。
在 AI 操场或代理评审应用中,选择齿轮图标
 。
。启用 custom_inputs。
提供与代理定义的输入架构匹配的 JSON 对象。
流式处理错误传播
在使用 databricks_output.error 下的最后一个标记进行流式处理时,Mosaic AI 传播遇到的任何错误。 由调用客户端来正确处理和显示此错误。
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute"
}
}
}
示例笔记本
这些笔记本创建一个简单的“Hello, world”链,以演示如何在 Databricks 中创建代理。 第一个示例创建一个简单的链,第二个示例笔记本演示了如何使用参数来最大程度地减少开发过程中的代码更改。