创建 AI 代理
本文介绍在 Azure Databricks 上创建 AI 代理的过程,并概述了创建代理的可用方法。
若要详细了解代理,请参阅 什么是复合 AI 系统和 AI 代理?。
在代码中撰写代理
马赛克 AI 代理框架和 MLflow 框架提供了工具,可帮助你在 Python 中开发企业级代理。
Databricks 支持使用第三方代理创作库(如 LangGraph/LangChain、LlamaIndex 或自定义 Python 实现)创作代理。
若要了解如何在 Databricks 上创建 AI 代理,请参阅 在代码创作 AI 代理。
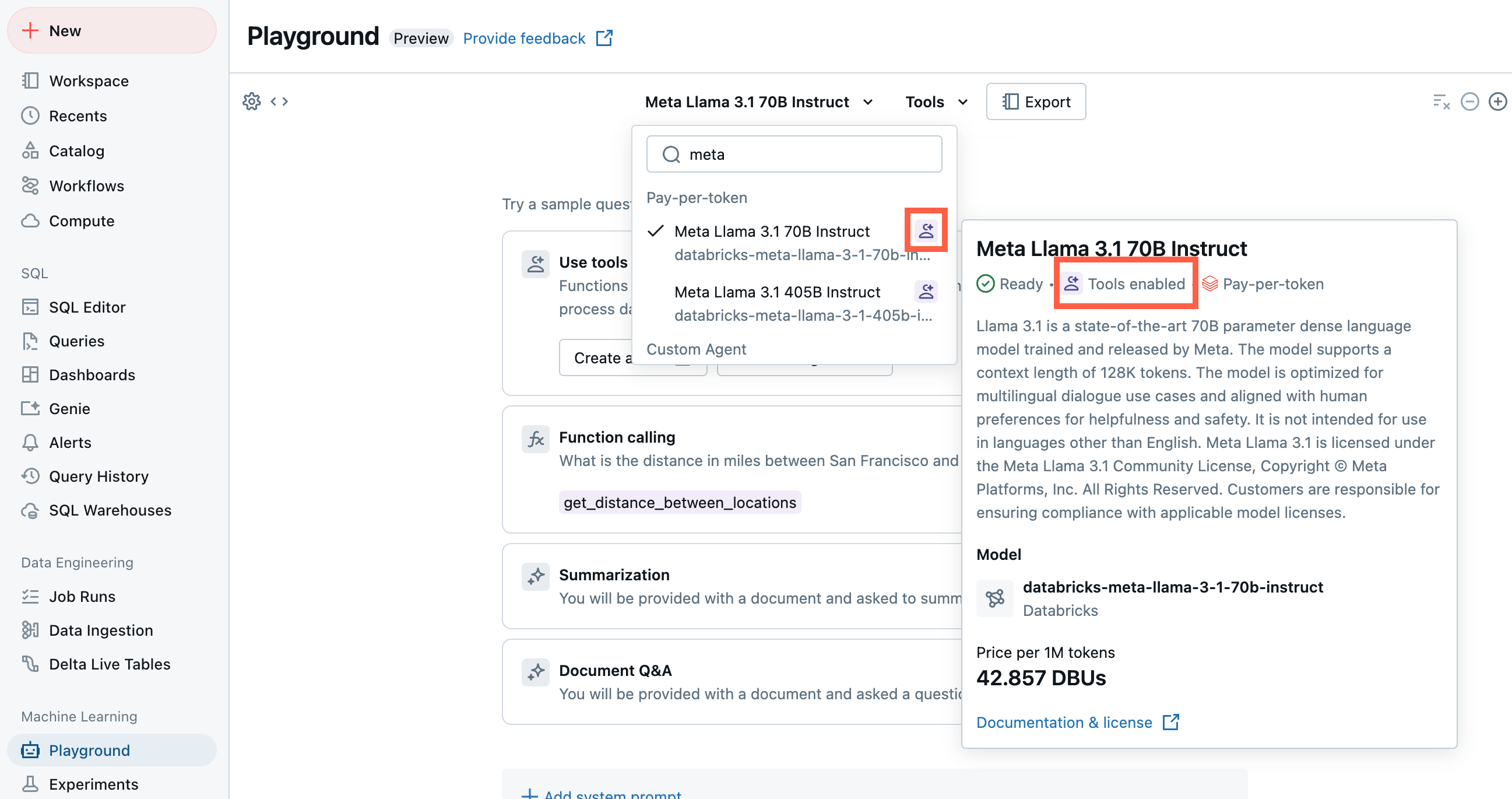
使用 AI Playground 的原型代理
AI Playground 是在 Azure Databricks 上创建代理的最简单方法。 借助 AI Playground,可以从各种 LLM 中进行选择,并使用低代码 UI 快速将工具添加到 LLM。 然后,可以与代理聊天以测试其响应,然后将代理导出到代码进行部署或进一步开发。
请参阅 AI Playground 中的原型工具调用代理。
了解模型签名以确保与 Databricks 功能的兼容性
Databricks 使用 MLflow 模型签名 来定义代理的输入和输出架构。 AI Playground 等产品功能假设代理具有一组受支持的模型签名。
如果遵循 建议的创作代理方法,MLflow 将自动推断与 Databricks 产品功能兼容的代理的签名,而无需执行额外的工作。
否则,必须确保代理遵循 旧版输入和输出代理架构中的其他签名之一,以确保与 Databricks 功能兼容。