在模型服务端点上配置 AI 网关
本文介绍如何在模型服务端点上配置 Mosaic AI 网关。
要求
- 外部模型支持的区域或预配吞吐量支持的区域中的一个 Databricks 工作区。
- 一个模型服务终结点。
- 若要为外部模型创建终结点,请完成 创建提供终结点的外部模型的步骤 1 和 2。
- 若要创建预配吞吐量的终结点,请参阅 预配吞吐量基础模型 API。
使用 UI 配置 AI 网关
本部分介绍如何使用服务 UI 在终结点创建过程中配置 AI 网关。 如果希望以编程方式执行此操作,请参阅 Notebook 示例。
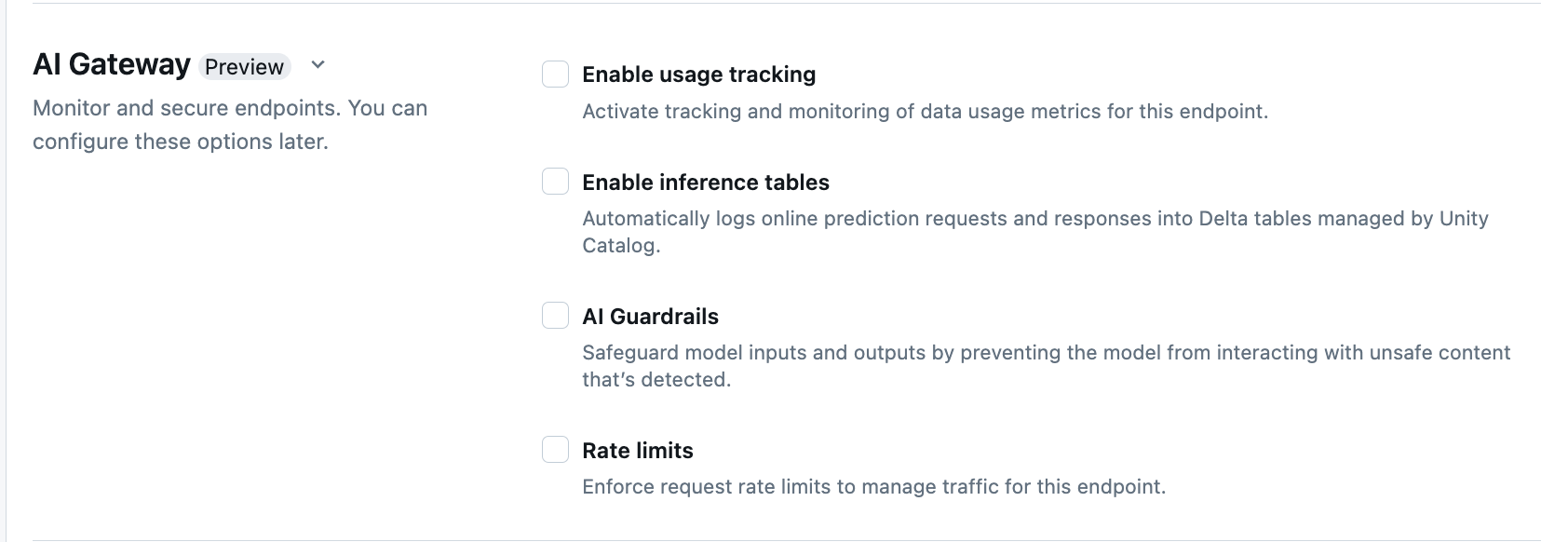
在终结点创建页的 AI 网关 部分中,可以单独配置 AI 网关功能。 请参阅 支持的功能,了解哪些功能可用于外部模型服务端点和预配吞吐量端点。
| 功能 | 如何启用 | 详细信息 |
|---|---|---|
| 使用情况跟踪 | 选择“启用使用情况跟踪”,以启用对数据使用情况指标的跟踪和监视。 | - 必须已启用 Unity Catalog。 - 帐户管理员必须在使用系统表之前 启用服务系统表架构: system.serving.endpoint_usage 捕获终结点每个请求的令牌计数,system.serving.served_entities 用于存储每个基础模型的元数据。- 请参阅使用情况跟踪表架构 - 只有帐户管理员才有权限查看或查询 served_entities 表或 endpoint_usage 表,即使管理端点的用户必须启用使用情况跟踪。 请参阅授予对系统表的访问权限- 如果模型未返回令牌计数,则输入和输出令牌计数估计为 ( text_length+1)/4。 |
| 有效负载日志记录 | 选择“启用推理表”,将端点的请求和响应自动记录到 Unity Catalog 管理的 Delta 表中。 | - 必须启用 Unity Catalog 并在指定的目录构架中拥有 CREATE_TABLE 的访问权限。- 由 AI 网关启用的推理表 具有与为提供自定义模型的模型服务终结点 创建的 推理表不同的架构。 请参阅已启用 AI 网关的推理表架构。 - 有效负载日志记录数据在查询端点后不到一小时就会填充到这些表中。 - 不会记录大于 1 MB 的有效负载。 - 响应有效负载聚合了所有返回区块的响应。 - 支持流式处理。 在流式传输场景中,响应载荷聚合了返回区块的响应。 |
| AI 护栏 | 请参阅在 UI 中配置 AI 护栏。 | - 护栏可防止模型与在模型输入和输出中检测到的不安全且有害的内容进行交互。 - 嵌入模型或流式处理不支持输出护栏。 |
| 速率限制 | 可以强制实施请求速率限制,以便根据每个用户和每个端点管理终结点的流量 | - 速率限制在每分钟查询 (QPM) 中定义。 - 对于每个用户和每个端点,默认情况下为“无限制”。 |
| 流量路由 | 若要在端点上配置流量路由,请参阅向端点提供多个外部模型。 |
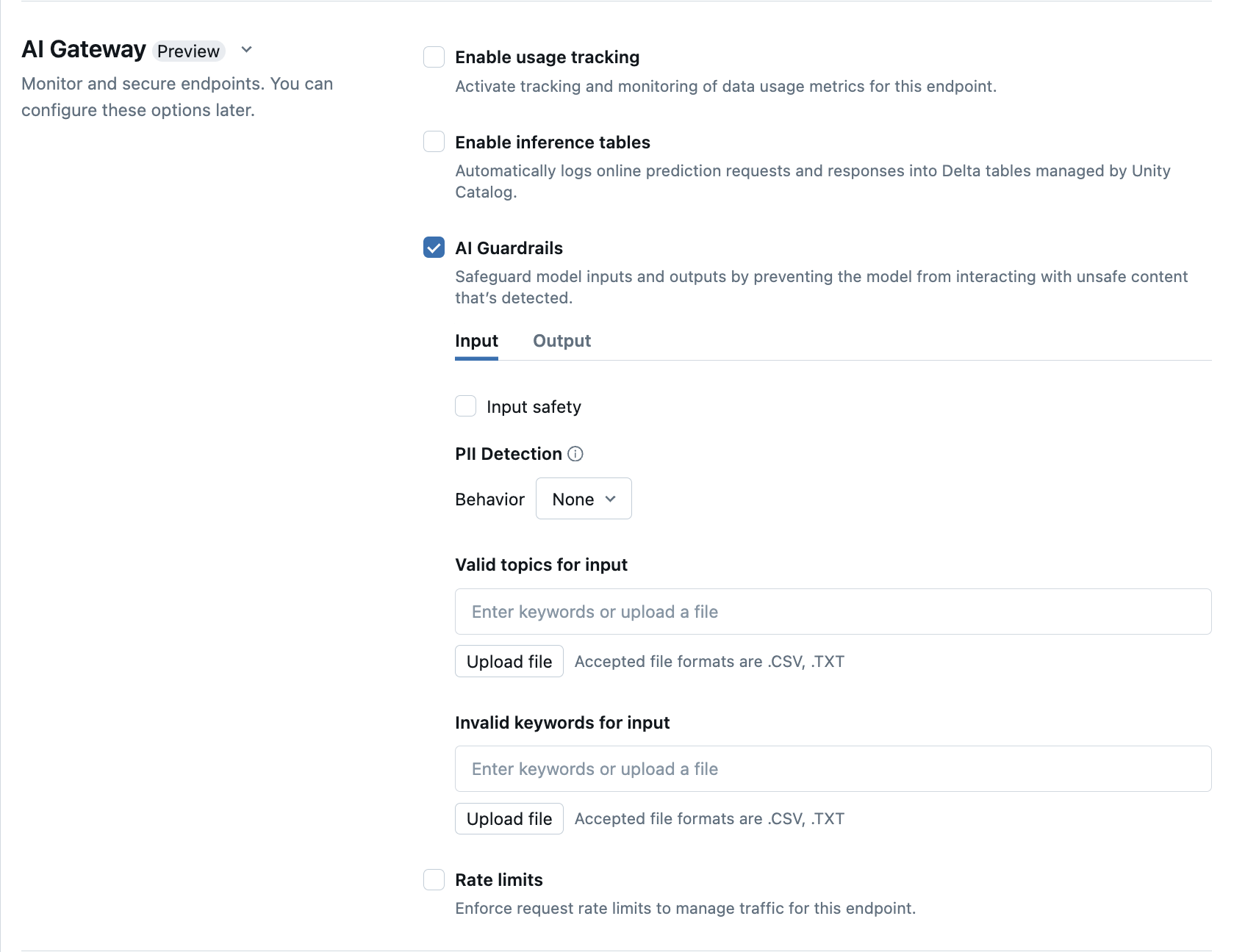
在 UI 中配置 AI 护栏
下表演示了如何配置支持的护栏。
| 护栏 | 如何启用 | 详细信息 |
|---|---|---|
| 安全 | 选择“安全”以启用安全措施,防止模型与不安全且有害的内容进行交互。 | |
| 个人身份信息 (PII) 检测 | 选择 PII 检测以检测 PII 数据,例如姓名、地址、信用卡号码。 | |
| 有效主题 | 可以直接在此字段键入主题。 如果有多个项目,请确保在每个主题后按 Enter 键。 或者,可以上传文件 .csv 或 .txt 文件。 |
最多可以指定 50 个有效主题。 每个主题不能超过 100 个字符 |
| 无效关键字 | 可以直接在此字段键入主题。 如果有多个项目,请确保在每个主题后按 Enter 键。 或者,可以上传文件 .csv 或 .txt 文件。 |
最多可以指定 50 个无效关键字。 每个关键字不能超过 100 个字符。 |
使用情况跟踪表架构
system.serving.served_entities 使用情况跟踪系统表具有以下架构:
| 列名 | 说明 | 类型 |
|---|---|---|
served_entity_id |
服务实体的唯一 ID。 | STRING |
account_id |
Delta 共享的客户帐户 ID。 | STRING |
workspace_id |
服务端点的客户工作区 ID。 | STRING |
created_by |
创建者的 ID。 | STRING |
endpoint_name |
服务端点的名称。 | STRING |
endpoint_id |
服务端点的唯一 ID。 | STRING |
served_entity_name |
服务实体的名称。 | STRING |
entity_type |
服务的实体的类型。 可以是 FEATURE_SPEC、EXTERNAL_MODEL、FOUNDATION_MODEL 或 CUSTOM_MODEL |
STRING |
entity_name |
实体的基础名称。 不同于用户提供的名称 served_entity_name。 例如,entity_name 是 Unity Catalog 模型的名称。 |
STRING |
entity_version |
服务实体的版本。 | STRING |
endpoint_config_version |
端点配置的版本。 | INT |
task |
任务类型。 可以是 llm/v1/chat、llm/v1/completions 或 llm/v1/embeddings。 |
STRING |
external_model_config |
外部模型的配置。 例如: {Provider: OpenAI} |
STRUCT |
foundation_model_config |
基础模型的配置。 例如 {min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUCT |
custom_model_config |
自定义模型的配置。 例如 { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
功能规范的配置。 例如: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
change_time |
服务实体的更改时间戳。 | TIMESTAMP |
endpoint_delete_time |
实体删除的时间戳。 端点是服务实体的容器。 删除端点后,服务实体也会被删除。 | TIMESTAMP |
system.serving.endpoint_usage 使用情况跟踪系统表具有以下架构:
| 列名 | 说明 | 类型 |
|---|---|---|
account_id |
客户帐户 ID。 | STRING |
workspace_id |
服务端点的客户工作区 ID。 | STRING |
client_request_id |
用户提供的请求标识符,可在模型服务请求正文中指定。 | STRING |
databricks_request_id |
附加到所有模型服务请求的 Azure Databricks 生成的请求标识符。 | STRING |
requester |
用户或服务主体的 ID,其权限用于服务端点的调用请求。 | STRING |
status_code |
从模型返回的 HTTP 状态代码。 | INTEGER |
request_time |
接收请求的时间戳。 | TIMESTAMP |
input_token_count |
输入的令牌计数。 | LONG |
output_token_count |
输出的令牌计数。 | LONG |
input_character_count |
输入字符串或提示符的字符计数。 | LONG |
output_character_count |
响应的输出字符串的字符计数。 | LONG |
usage_context |
用户提供的映射,包含对端点进行调用的最终用户或客户应用程序的标识符。 请参阅使用 usage_context 进一步定义使用情况。 | MAP |
request_streaming |
请求是否处于流模式。 | BOOLEAN |
served_entity_id |
用于与 system.serving.served_entities 维度表联接的唯一 ID,可查找有关端点和服务实体的信息。 |
STRING |
使用 usage_context 进一步定义使用情况
查询启用了使用情况跟踪的外部模型时,可以提供类型 usage_context 的 Map[String, String] 参数。 用法上下文映射显示在 usage_context 列的使用情况跟踪表中。 地图 usage_context 大小不能超过 10 KiB。
帐户管理员可以根据用法上下文合并不同的行,以获取见解,并且可以将此信息与有效负载日志记录表中的信息进行联接。 例如,可以将 end_user_to_charge 添加到 usage_context,以跟踪最终用户的成本归因。
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
更新端点上的 AI 网关功能
可在以前启用 AI 网关功能和未启用该功能的模型服务端点上更新 AI 网关功能。 AI 网关配置的更新需要大约 20-40 秒才能应用,但速率限制更新最长可能需要 60 秒。
下面演示了如何使用服务 UI 更新模型服务端点上的 AI 网关功能。
在端点页面的“网关”部分,可以看到已启用了哪些功能。 若要更新这些功能,请单击“编辑 AI 网关”。

笔记本示例
以下笔记本演示了如何以编程方式启用和使用 Databricks Mosaic AI 网关功能,以管理和治理来自提供商的模型。 有关 REST API 的详细信息,请参阅以下内容: