数据访问配置
本文介绍可用于工作区 SQL 仓库的数据访问设置。
注意
Databricks 建议使用 Unity 目录卷或外部位置连接到云对象存储。 Unity Catalog 提供一个集中位置来管理和审核帐户中多个工作区的数据访问,从而简化了数据的安全性和治理。 请参阅什么是 Unity Catalog?和使用外部位置的建议。
重要
更改这些设置将重启所有正在运行的 SQL 仓库。
要求
- 必须是 Azure Databricks 工作区管理员才能配置这些设置。
配置服务主体
若要使用服务主体配置 SQL 仓库对 Azure Data Lake Storage Gen2 存储帐户的访问权限,请执行以下步骤:
注册 Microsoft Entra ID(前 Azure Active Directory)应用程序并记录以下属性:
- 应用程序(客户端) ID:用于唯一标识 Microsoft Entra ID 应用程序的 ID。
- 目录(租户) ID:用于唯一标识 Microsoft Entra ID 实例的 ID(在 Azure Databricks 中称为“目录(租户) ID”)。
- 客户端机密:为注册此应用程序而创建的客户端机密值。 应用程序将使用此机密字符串来证明其标识。
在存储帐户上,为在上一步中注册的应用程序添加角色分配,以授予其对存储帐户的访问权限。
创建 Azure 密钥库支持的或 Databricks 范围的机密范围,请参阅“管理机密范围”,并记录范围名称属性的值:
- 范围名称:创建的机密范围的名称。
如果使用 Azure 密钥库,请使用“值”字段中的“客户端密码”在 Azure 密钥库中创建机密。 有关示例,请参阅步骤 4:将客户端密码添加到 Azure 密钥库。 保留所选机密名称的记录。
- 机密名称:创建的 Azure 密钥保管库机密的名称。
如果使用 Databricks 支持的范围,请使用 Databricks CLI 创建新的机密,并使用该机密来存储在步骤 1 中获取的客户端机密。 记下在此步骤中输入的密钥。
- 密钥:创建的 Databricks 支持的机密的密钥。
注意
(可选)可以创建一个额外的机密来存储在步骤 1 中获取的客户端 ID。
在工作区顶部栏中单击你的用户名,然后从下拉列表中选择“设置”。
单击“计算”选项卡。
单击“SQL 仓库”旁边的“管理”。
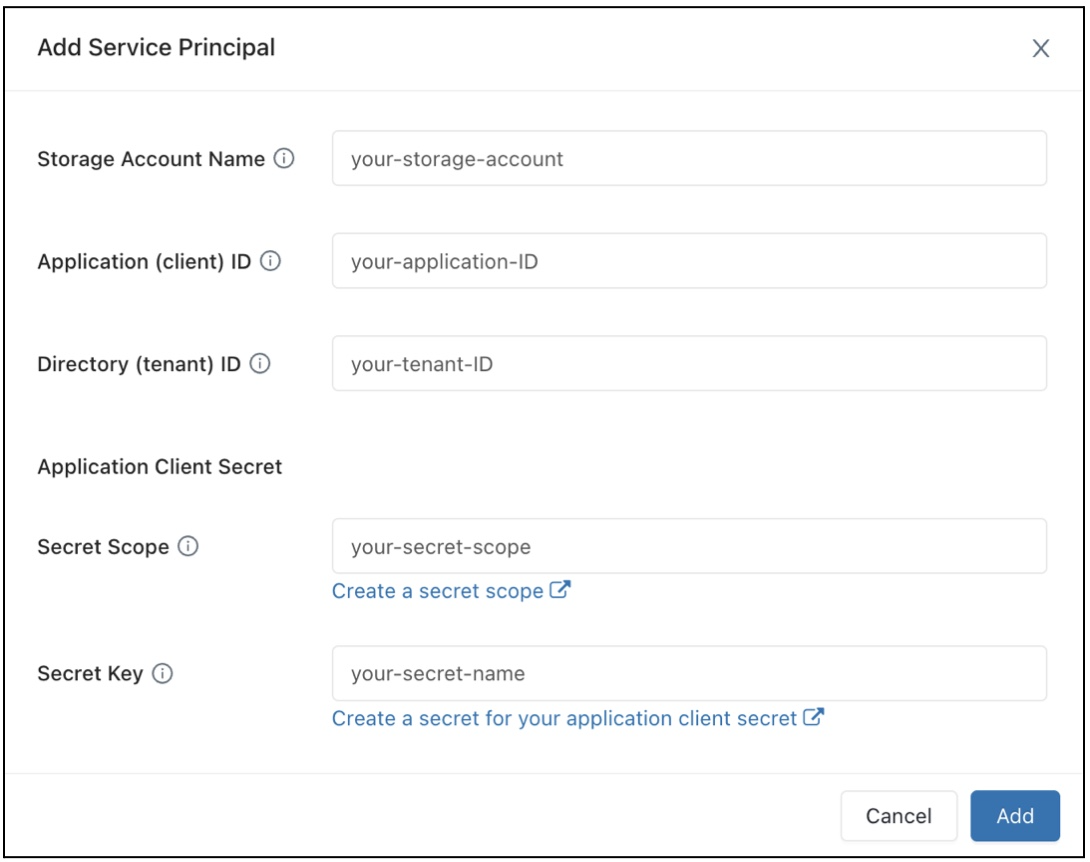
在“数据访问配置”字段中,单击“添加服务主体”按钮。
配置 Azure Data Lake Storage Gen2 存储帐户的属性。
单击“添加” 。
你将看到新条目已添加到“数据访问配置”文本框中。
单击“ 保存”。
还可以直接编辑“数据访问配置”文本框条目。
配置 SQL 仓库的数据访问属性
若要使用数据访问属性配置所有仓库:
在工作区顶部栏中单击你的用户名,然后从下拉列表中选择“设置”。
单击“计算”选项卡。
单击“SQL 仓库”旁边的“管理”。
在“数据访问配置”文本框中,指定包含元存储属性的键值对。
重要
若要将 Spark 配置属性设置为机密的值而不向 Spark 公开机密值,请将值设置为
{{secrets/<secret-scope>/<secret-name>}}。 将<secret-scope>替换为机密范围,并将<secret-name>替换为机密名称。 该值必须以{{secrets/开头,以}}结尾。 有关此语法的详细信息,请参阅 “管理机密”。单击“ 保存”。
还可以使用 Databricks Terraform 提供程序和 databricks_sql_global_config 配置数据访问属性。
支持的属性
对于以
*结尾的条目,支持该前缀内的所有属性。例如,
spark.sql.hive.metastore.*指示同时支持spark.sql.hive.metastore.jars和spark.sql.hive.metastore.version,以及以spark.sql.hive.metastore开头的任何其他属性。对于其值包含敏感信息的属性,可以将敏感信息存储在机密中并使用以下语法将属性的值设置为机密名称:
secrets/<secret-scope>/<secret-name>。
SQL 仓库支持以下属性:
spark.sql.hive.metastore.*spark.sql.warehouse.dirspark.hadoop.datanucleus.*spark.hadoop.fs.*spark.hadoop.hive.*spark.hadoop.javax.jdo.option.*spark.hive.*
若要详细了解如何设置这些属性,请参阅外部 Hive 元存储。