你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:通过 NFS 将数据复制到 Azure Data Box Heavy
本教程介绍如何使用本地 Web UI 从主机连接到 Azure Data Box Heavy 并将数据复制到其中。
在本教程中,你将了解如何执行以下操作:
- 先决条件
- 连接到 Data Box Heavy
- 将数据复制到 Data Box Heavy
先决条件
在开始之前,请确保:
- 已完成教程:设置 Azure Data Box Heavy。
- 已收到 Data Box Heavy,并且门户中的订单状态为“已送达”。
- 你有一台主机,其中的数据需复制到 Data Box Heavy。 该主机必须
- 运行支持的操作系统。
- 连接到高速网络。 为获得最快的复制速度,可以同时利用两个 40-GbE 连接(在每个节点上使用一个)。 如果没有可用的 40-GbE 连接,我们建议至少开通两个 10-GbE 连接(在每个节点上使用一个)。
连接到 Data Box Heavy
根据选择的存储帐户,Data Box Heavy 将会:
- 为每个关联的 GPv1 和 GPv2 存储帐户最多创建三个共享。
- 用于高级存储的一个共享。
- 用于 Blob 存储帐户的一个共享。
这些共享是在设备的两个节点上创建的。
在块 Blob 和页 Blob 共享下:
- 一级实体是容器。
- 二级实体是 Blob。
在 Azure 文件的共享下:
- 一级实体是共享。
- 二级实体是文件。
下表显示了 Data Box Heavy 上的共享的 UNC 路径,以及数据上传到的 Azure 存储路径 URL。 最终的 Azure 存储路径 URL 可以从 UNC 共享路径派生。
| 存储 | UNC 路径 |
|---|---|
| Azure 块 Blob | //<DeviceIPAddress>/<StorageAccountName_BlockBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure 页 Blob | //<DeviceIPAddress>/<StorageAccountName_PageBlob>/<ContainerName>/files/a.txthttps://<StorageAccountName>.blob.core.windows.net/<ContainerName>/files/a.txt |
| Azure 文件 | //<DeviceIPAddress>/<StorageAccountName_AzFile>/<ShareName>/files/a.txthttps://<StorageAccountName>.file.core.windows.net/<ShareName>/files/a.txt |
如果使用的是 Linux 主机,请执行以下步骤将设备配置为允许访问 NFS 客户端。
提供允许访问共享的客户端的 IP 地址。 在本地 Web UI 中,转到“连接和复制”页。 在“NFS 设置”下,单击“NFS 客户端访问”。
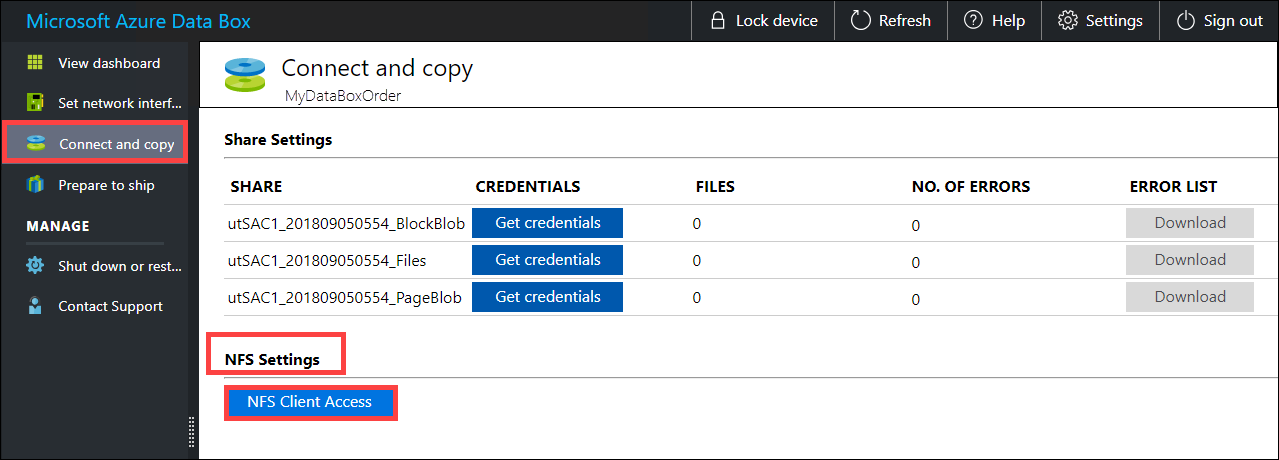
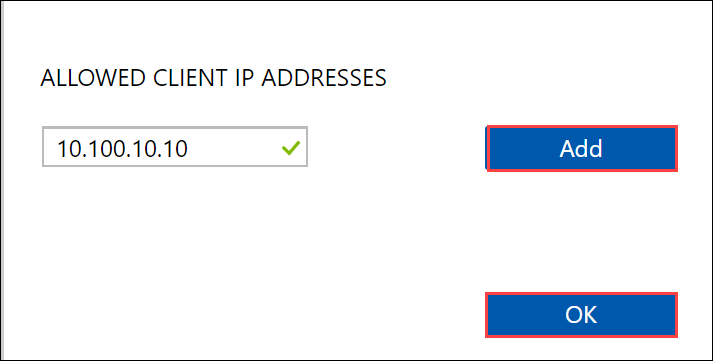
提供 NFS 客户端的 IP 地址,然后单击“添加”。 可以重复此步骤为多个 NFS 客户端配置访问。 单击“确定”。
确保 Linux 主机上已安装受支持版本的 NFS 客户端。 使用特定版本的 Linux 分发版。
安装 NFS 客户端后,使用以下命令在 Data Box 设备上装载 NFS 共享:
sudo mount <Data Box Heavy device IP>:/<NFS share on Data Box Heavy device> <Path to the folder on local Linux computer>以下示例演示如何通过 NFS 连接到 Data Box Heavy 共享。 Data Box Heavy IP 为
10.161.23.130,共享Mystoracct_Blob装载在 ubuntuVM 上,装入点为/home/databoxheavyubuntuhost/databoxheavy。sudo mount -t nfs 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavy对于 Mac 客户端,需要添加一个附加选项,如下所示:
sudo mount -t nfs -o sec=sys,resvport 10.161.23.130:/Mystoracct_Blob /home/databoxheavyubuntuhost/databoxheavy始终为要复制到共享下的文件创建一个文件夹,然后将文件复制到该文件夹。 在块 blob 和页 blob 共享下创建的文件夹表示将数据作为 blob 上传到的容器。 无法将文件直接复制到存储帐户中的 root 文件夹。
将数据复制到 Data Box Heavy
在连接到 Data Box Heavy 共享后,下一步是复制数据。 在开始复制数据之前,请查看以下注意事项:
确保将数据复制到与适当数据格式对应的共享中。 例如,将块 Blob 数据复制到块 Blob 的共享中。 将 VHD 复制到页 Blob。 如果数据格式与相应的共享类型不匹配,则在后续步骤中,数据将无法上传到 Azure。
在复制数据时,请确保数据大小符合 Azure 存储和 Data Box Heavy 限制中所述的大小限制。
如果 Data Box Heavy 正在上传的数据同时已由 Data Box Heavy 外部的其他应用程序上传,则可能会导致上传作业失败和数据损坏。
我们建议不要同时使用 SMB 和 NFS,也不要将相同的数据复制到 Azure 上的同一个最终目标。 在这种情况下,最终的结果不可确定。
始终为要复制到共享下的文件创建一个文件夹,然后将文件复制到该文件夹。 在块 blob 和页 blob 共享下创建的文件夹表示将数据作为 blob 上传到的容器。 无法将文件直接复制到存储帐户中的 root 文件夹。
如果从 NFS 共享中将区分大小写的目录和文件名引入到 Data Box Heavy 上的 NFS,请注意以下事项:
- 名称将保留大小写。
- 文件不区分大小写。
例如,如果复制
SampleFile.txt和Samplefile.Txt,则在复制到设备时,名称将保留大小写,但第二个文件将覆盖第一个文件,因为这些文件被视为同一文件。
如果使用 Linux 主机,请使用类似于 Robocopy 的复制实用工具。 在 Linux 中可用的一些替代工具包括 rsync、FreeFileSync、Unison 或 Ultracopier。
cp 命令是用于复制目录的最佳选项之一。 有关用法详细信息,请转到 cp 手册页。
如果使用 rsync 选项进行多线程复制,请遵循以下准则:
根据 Linux 客户端所用的文件系统,安装 CIFS Utils 或 NFS Utils 包。
sudo apt-get install cifs-utilssudo apt-get install nfs-utils安装 Rsync 和 Parallel(根据 Linux 分发版而异)。
sudo apt-get install rsyncsudo apt-get install parallel创建装入点。
sudo mkdir /mnt/databoxheavy装载卷。
sudo mount -t NFS4 //Databox-heavy-IP-Address/share_name /mnt/databoxheavy镜像文件夹目录结构。
rsync -za --include='*/' --exclude='*' /local_path/ /mnt/databoxheavy复制文件。
cd /local_path/; find -L . -type f | parallel -j X rsync -za {} /mnt/databoxheavy/{}其中,j 指定并行化数目,X 为并行副本数
我们建议从 16 个并行副本开始,并根据可用的资源增加线程数。
重要
不支持以下 Linux 文件类型:符号链接、字符文件、块文件、套接字和管道。 在准备交付步骤期间,这些文件类型将导致失败。
打开目标文件夹,查看并验证复制的文件。 如果复制过程中遇到任何错误,请下载用于故障排除的错误文件。 有关详细信息,请参阅查看将数据复制到 Data Box Heavy 期间生成的错误日志。 有关数据复制期间的错误详细列表,请参阅排查 Data Box Heavy 问题。
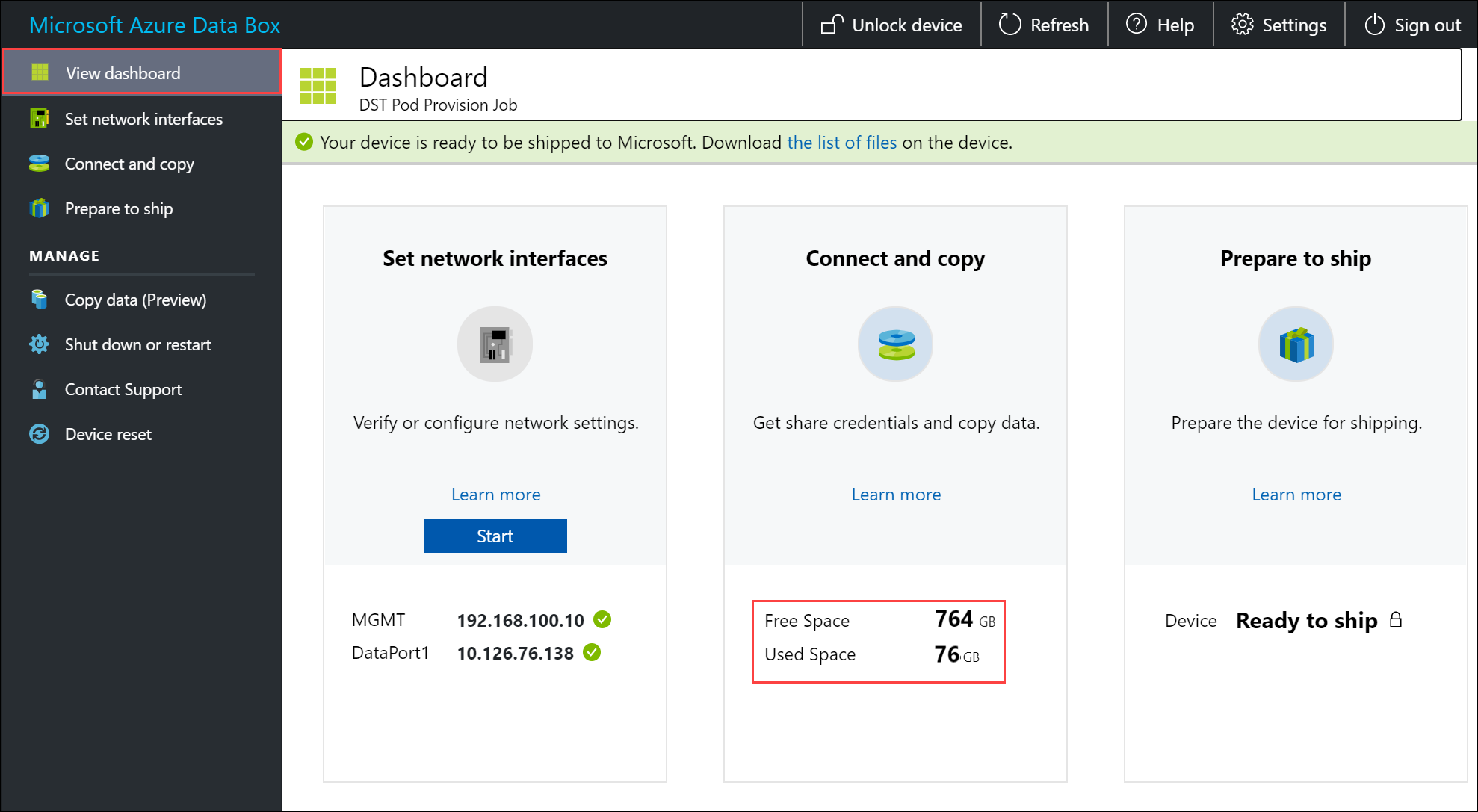
为确保数据完整性,复制数据时将以内联方式计算校验和。 复制完成后,检查设备上的已用空间和可用空间。
后续步骤
本教程介绍了 Azure Data Box Heavy 主题,例如:
- 先决条件
- 连接到 Data Box Heavy
- 将数据复制到 Data Box Heavy
请继续学习下一篇教程,了解如何将 Data Box 寄回 Microsoft。