你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure 数据工厂中使用 Hive 活动转换 Azure 虚拟网络中的数据
适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本教程使用 Azure PowerShell 创建一个数据工厂管道,该管道可以使用 HDInsight 群集上的 Hive 活动转换 Azure 虚拟网络 (VNet) 中的数据。 在本教程中执行以下步骤:
- 创建数据工厂。
- 创作并设置自我托管的集成运行时
- 创作并部署链接服务。
- 创作并部署包含 Hive 活动的管道。
- 启动管道运行。
- 监视管道运行
- 验证输出。
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
先决条件
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 若要开始,请参阅安装 Azure PowerShell。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
Azure 存储帐户。 创建 Hive 脚本并将其上传到 Azure 存储。 Hive 脚本的输出存储在此存储帐户中。 在本示例中,HDInsight 群集使用此 Azure 存储帐户作为主存储。
Azure 虚拟网络。 如果没有 Azure 虚拟网络,请遵照这些说明创建虚拟网络。 在本示例中,HDInsight 位于 Azure 虚拟网络中。 下面是 Azure 虚拟网络的示例配置。
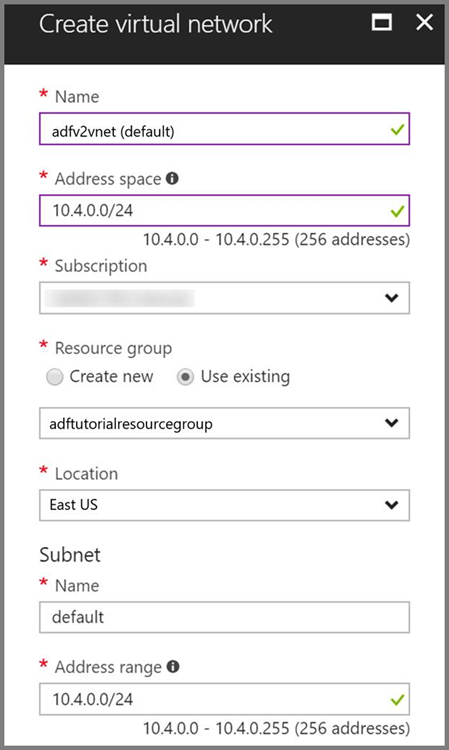
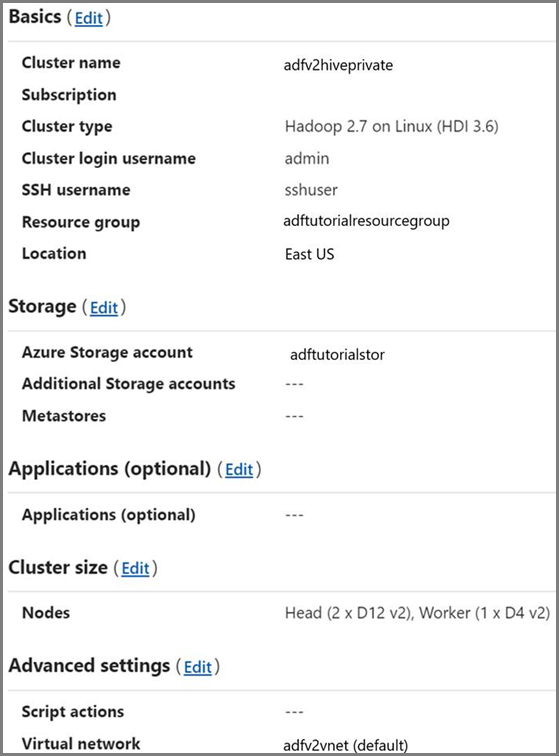
HDInsight 群集。 创建一个 HDInsight 群集,并按照以下文章中所述,将该群集加入到在前一步骤中创建的虚拟网络:使用 Azure 虚拟网络扩展 Azure HDInsight。 下面是虚拟网络中 HDInsight 的示例配置。
Azure PowerShell。 遵循如何安装和配置 Azure PowerShell 中的说明。
将 Hive 脚本上传到 Blob 存储帐户
创建包含以下内容的名为 hivescript.hql 的 Hive SQL 文件:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletable在 Azure Blob 存储中,创建名为 adftutorial 的容器(如果尚不存在)。
创建名为 hivescripts 的文件夹。
将 hivescript.hql 文件上传到 hivescripts 子文件夹。
创建数据工厂
设置资源组名称。 在本教程中创建一个资源组。 不过,也可以使用现有的资源组。
$resourceGroupName = "ADFTutorialResourceGroup"指定数据工厂名称。 必须全局唯一。
$dataFactoryName = "MyDataFactory09142017"指定管道名称。
$pipelineName = "MyHivePipeline" #指定自承载 Integration Runtime 的名称。 当数据工厂需要访问 VNet 中的资源(例如 Azure SQL 数据库)时,你需要自承载 Integration Runtime。
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"启动 PowerShell。 在完成本快速入门之前,请将 Azure PowerShell 保持打开状态。 如果将它关闭再重新打开,则需要再次运行下述命令。 若要查看目前提供数据工厂的 Azure 区域的列表,请在以下页面上选择感兴趣的区域,然后展开“分析”以找到“数据工厂”:可用产品(按区域)。 数据工厂使用的数据存储(Azure 存储、Azure SQL 数据库,等等)和计算资源(HDInsight 等)可以位于其他区域中。
运行以下命令并输入用于登录 Azure 门户的用户名和密码:
Connect-AzAccount运行以下命令查看此帐户的所有订阅:
Get-AzSubscription运行以下命令选择要使用的订阅。 请将 SubscriptionId 替换为自己的 Azure 订阅的 ID:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"创建资源组:ADFTutorialResourceGroup(如果在订阅中尚不存在)。
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"创建数据工厂。
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupName执行以下命令查看输出:
$df
创建自我托管的 IR
在本部分,创建一个自我托管的集成运行时,并将它与 HDInsight 群集所在的同一个 Azure 虚拟网络中的某个 Azure VM 相关联。
创建自我托管的集成运行时。 如果存在同名的集成运行时,请使用唯一名称。
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHosted此命令为自我托管的集成运行时创建逻辑注册。
使用 PowerShell 检索身份验证密钥,以注册自我托管的集成运行时。 复制用于注册自我托管集成运行时的密钥之一。
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-Json下面是示例输出:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }记下 AuthKey1 的值(不包括引号)。
创建一个 Azure VM,并将其加入到 HDInsight 群集所在的同一个虚拟网络。 有关详细信息,请参阅如何创建虚拟机。 将虚拟机加入 Azure 虚拟网络。
在该 Azure VM 上,下载自我托管的集成运行时。 使用上一步骤中获取的身份验证密钥手动注册自我托管的集成运行时。
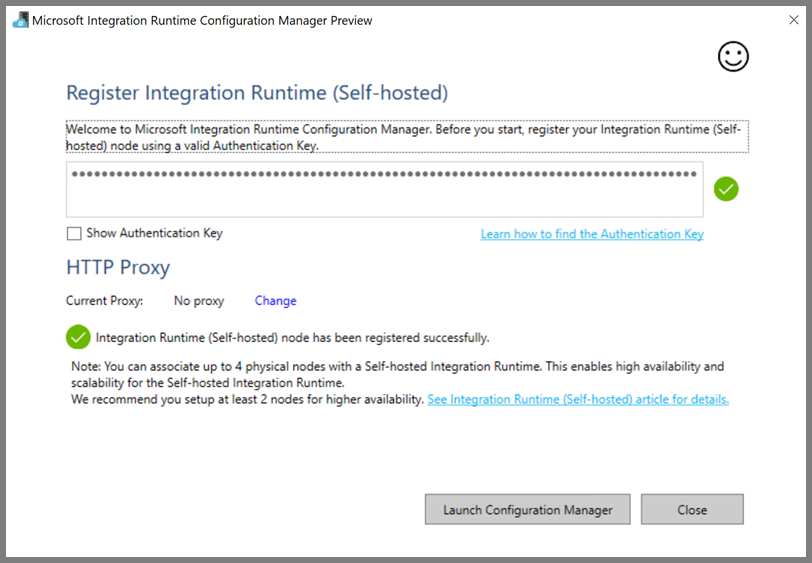
成功注册自承载集成运行时后,会看到以下消息:
将节点连接到云服务后,会看到以下页:
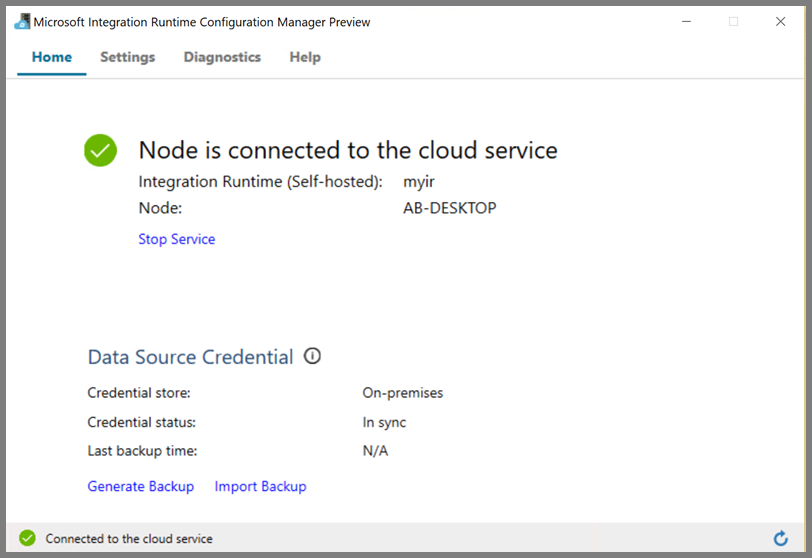
创作链接服务
在本部分中创作并部署两个链接服务:
- 一个 Azure 存储链接服务,用于将 Azure 存储帐户链接到数据工厂。 此存储是 HDInsight 群集使用的主存储。 在本例中,我们还使用此 Azure 存储帐户来保留 Hive 脚本以及脚本的输出。
- 一个 HDInsight 链接服务。 Azure 数据工厂将 Hive 脚本提交到此 HDInsight 群集以供执行。
Azure 存储链接服务
使用偏好的编辑器创建一个 JSON 文件,复制 Azure 存储链接服务的以下 JSON 定义,并将该文件另存为 MyStorageLinkedService.json。
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
将 <accountname> 和 <accountkey> 分别替换为 Azure 存储帐户的名称和密钥。
HDInsight 链接服务
使用偏好的编辑器创建一个 JSON 文件,复制 Azure HDInsight 链接服务的以下 JSON 定义,并将该文件另存为 MyHDInsightLinkedService.json。
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
更新链接服务定义中以下属性的值:
userName。 创建群集时指定的群集登录用户的名称。
password。 用户的密码。
clusterUri。 使用以下格式指定 HDInsight 群集的 URL:
https://<clustername>.azurehdinsight.net。 本文假设你有权通过 Internet 访问该群集。 例如,可以通过https://clustername.azurehdinsight.net连接到该群集。 此地址使用公共网关。如果已使用网络安全组 (NSG) 或用户定义的路由 (UDR) 限制了从 Internet 的访问,则该网关不可用。 要使数据工厂能够将作业提交到 Azure 虚拟网络中的 HDInsight 群集,需要相应地配置 Azure 虚拟网络,使 URL 可解析成 HDInsight 所用的网关的专用 IP 地址。在 Azure 门户中,打开 HDInsight 所在的虚拟网络。 打开名称以
nic-gateway-0开头的网络接口。 记下其专用 IP 地址。 例如 10.6.0.15。如果 Azure 虚拟网络包含 DNS 服务器,请更新 DNS 记录,使 HDInsight 群集 URL
https://<clustername>.azurehdinsight.net可解析成10.6.0.15。 这是建议的做法。 如果 Azure 虚拟网络中没有 DNS 服务器,可以通过编辑已注册为自承载 Integration Runtime 节点的所有 VM 的 hosts 文件 (C:\Windows\System32\drivers\etc) 并添加如下所示的条目,来暂时解决此问题:10.6.0.15 myHDIClusterName.azurehdinsight.net
创建链接服务
在 PowerShell 中切换到在其中创建了 JSON 文件的文件夹,并运行以下命令来部署链接服务:
在 PowerShell 中切换到在其中创建了 JSON 文件的文件夹。
运行以下命令,创建 Azure 存储链接服务。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"运行以下命令,创建 Azure HDInsight 链接服务。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
创作管道
本步骤创建包含 Hive 活动的新管道。 该活动执行 Hive 脚本来返回示例表中的数据,并将其保存到定义的路径。 在偏好的编辑器中创建一个 JSON 文件,复制管道定义的以下 JSON 定义,然后将该文件另存为 MyHivePipeline.json。
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
请注意以下几点:
- scriptPath 指向用于 MyStorageLinkedService 的 Azure 存储帐户中的 Hive 脚本路径。 此路径区分大小写。
- Output 是 Hive 脚本中使用的参数。 使用
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/格式指向 Azure 存储中的现有文件夹。 此路径区分大小写。
切换到在其中创建了 JSON 文件的文件夹,并运行以下命令部署管道:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
启动管道
启动管道运行。 该命令还会捕获管道运行 ID 用于将来的监视。
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineName运行以下脚本来持续检查管道运行状态,直到运行完成为止。
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"下面是示例运行的输出:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"在
outputfolder文件夹中检查作为 Hive 查询结果创建的新文件,其内容应如以下示例输出所示:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
相关内容
已在本教程中执行了以下步骤:
- 创建数据工厂。
- 创作并设置自我托管的集成运行时
- 创作并部署链接服务。
- 创作并部署包含 Hive 活动的管道。
- 启动管道运行。
- 监视管道运行
- 验证输出。
请转到下一篇教程,了解如何在 Azure 上使用 Spark 群集转换数据: