你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用变更数据捕获 (CDC),以增量方式将 Azure SQL 托管实例中的数据加载到 Azure 存储
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
在本教程中,请创建一个带管道的 Azure 数据工厂,以便根据源 Azure SQL 托管实例数据库中的变更数据捕获 (CDC) 信息将增量数据加载到 Azure Blob 存储。
在本教程中执行以下步骤:
- 准备源数据存储
- 创建数据工厂。
- 创建链接服务。
- 创建源和接收器数据集。
- 创建、调试和运行管道以检查变更的数据
- 修改源表中的数据
- 完成、运行和监视完整的增量复制管道
概述
可以使用 Azure SQL 托管实例 (MI) 和 SQL Server 等数据存储支持的变更数据捕获技术来确定变更的数据。 本教程介绍如何将 Azure 数据工厂与 SQL 变更数据捕获技术配合使用,通过增量方式将增量数据从 Azure SQL 托管实例加载到 Azure Blob 存储中。 有关 SQL 变更数据捕获技术的更具体信息,请参阅 SQL Server 中的变更数据捕获。
端到端工作流
下面是典型的端到端工作流步骤,用于通过变更数据捕获技术以增量方式加载数据。
注意
Azure SQL MI 和 SQL Server 都支持变更数据捕获技术。 本教程使用 Azure SQL 托管实例作为源数据存储。 也可以使用本地 SQL Server。
高级解决方案
在本教程中,请创建管道来执行下述操作:
- 创建查找活动,来计算 SQL 数据库 CDC 表中变更的记录的数量,然后将其传递给“IF 条件”活动。
- 创建 If 条件,来检查是否有变更的记录,如果有,则调用“复制活动”。
- 创建复制活动,来将插入/更新/删除的数据从 CDC 表复制到 Azure Blob 存储。
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
先决条件
- Azure SQL 托管实例。 将数据库用作源数据存储。 如果没有 Azure SQL 数据库托管实例,请参阅创建 Azure SQL 数据库托管实例一文以了解创建步骤。
- Azure 存储帐户。 将 Blob 存储用作接收器数据存储。 如果没有 Azure 存储帐户,请参阅创建存储帐户一文获取创建步骤。 创建名为“raw”的容器。
在 Azure SQL 数据库中创建数据源表
启动 SQL Server Management Studio,然后连接到 Azure SQL 托管实例服务器。
在“服务器资源管理器”中,右键单击你的数据库,然后选择“新建查询”。
针对 Azure SQL 托管实例数据库运行以下 SQL 命令,以创建名为
customers的表作为数据源存储。create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );通过运行以下 SQL 查询,在数据库和源表 (customers) 上启用变更数据捕获机制:
注意
- 将<源架构名称>替换为你的 Azure SQL MI 的架构,其中包含 customers 表。
- 变更数据捕获在更改要跟踪的表的事务中不做任何事情。 而是将插入、更新和删除操作写入事务日志中。 如果没有定期系统地清除数据,更改表中存储的数据将会变得非常大。 有关详细信息,请参阅对数据库启用变更数据捕获
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1通过运行以下命令,将数据插入 customers 表中:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');注意
在启用“变更数据捕获”之前,不会捕获对表的历史更改。
创建数据工厂
如果你还没有数据工厂可供使用,请按照快速入门:使用 Azure 门户创建数据工厂一文中的步骤创建数据工厂。
创建链接服务
可在数据工厂中创建链接服务,将数据存储和计算服务链接到数据工厂。 在本部分中,请创建 Azure 存储帐户和 Azure SQL MI 的链接服务。
创建 Azure 存储链接服务。
在此步骤中,请将 Azure 存储帐户链接到数据工厂。
依次单击“连接”、“+ 新建”。
在“新建链接服务”窗口中,选择“Azure Blob 存储”,然后单击“继续”。
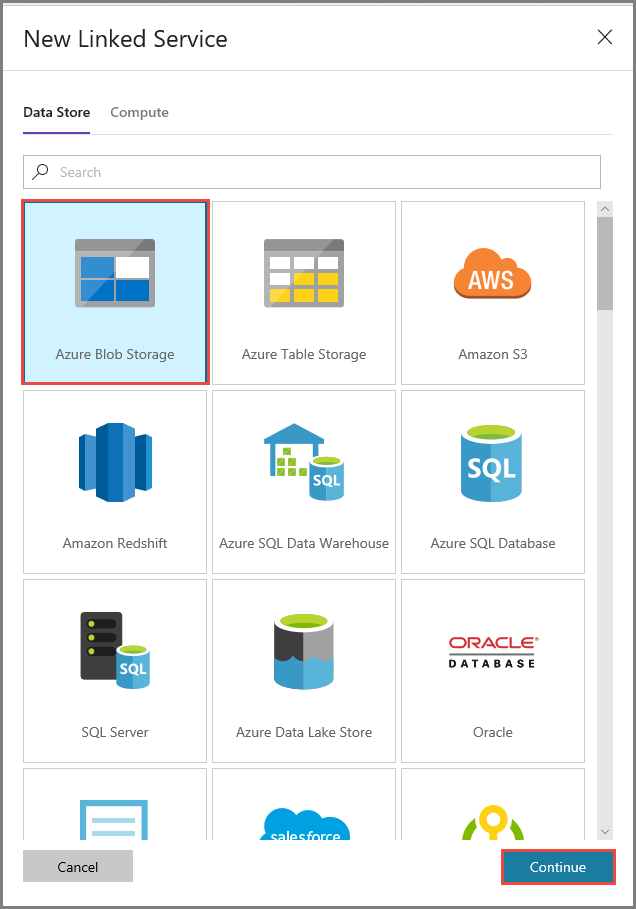
在“新建链接服务”窗口中执行以下步骤:
- 输入 AzureStorageLinkedService 作为名称。
- 对于“存储帐户名称”,请选择自己的 Azure 存储帐户。
- 单击“保存” 。
创建 Azure SQL MI 数据库链接服务。
在此步骤中,将 Azure SQL MI 数据库链接到数据工厂。
注意
对于使用 SQL MI 的用户,请参阅此处以获取通过公共和专用终结点进行访问的相关信息。 如果使用专用终结点,则需要使用自承载集成运行时运行此管道。 这同样适用于在 VM 或 VNet 方案中本地运行 SQL Server 的管道。
依次单击“连接”、“+ 新建”。
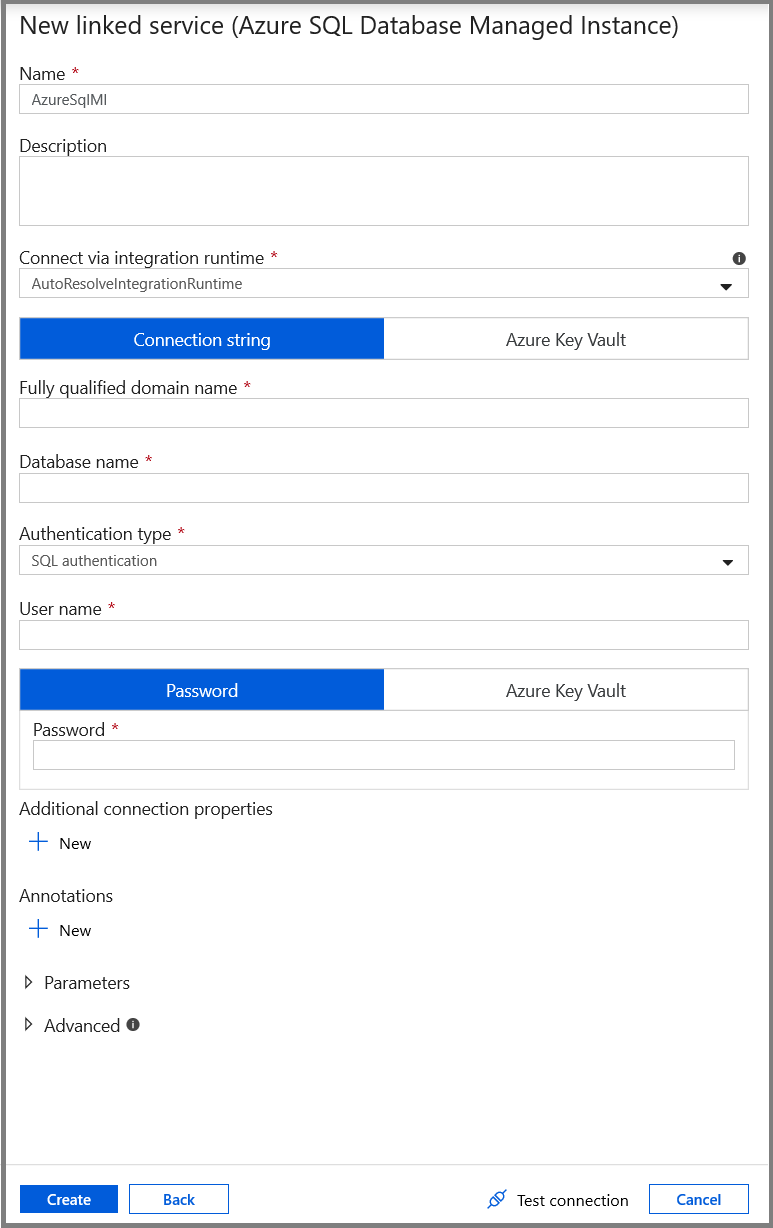
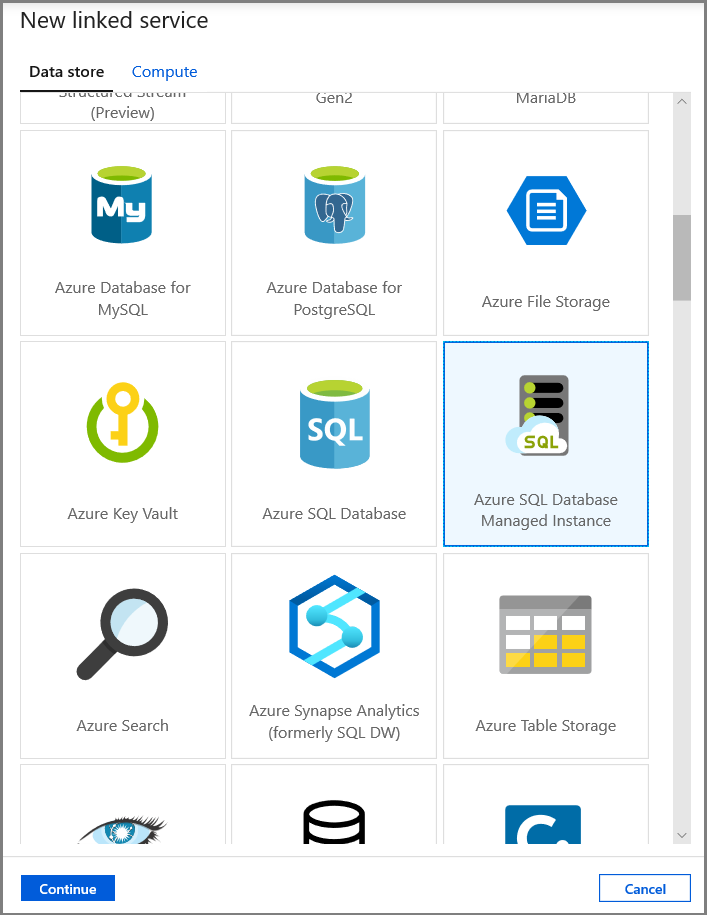
在“新建链接服务”窗口中,选择“Azure SQL 数据库托管实例”,然后单击“继续”。
在“新建链接服务”窗口中执行以下步骤:
- 对于“名称”字段,请输入“AzureSqlMI1”。
- 对于“服务器名称”字段,请选择你的 SQL 服务器。
- 对于“数据库名称”字段,请选择你的 SQL 数据库。
- 对于“用户名”字段,请输入用户的名称。
- 对于“密码”字段,请输入用户的密码。
- 单击“测试连接”以测试连接。
- 单击“保存”保存链接服务。
创建数据集
在此步骤中,请创建用于表示数据源和数据目标的数据集。
创建用于表示源数据的数据集
在此步骤中,请创建一个代表源数据的数据集。
在树状视图中,依次单击“+”(加号)、“数据集”。
选择“Azure SQL 数据库托管实例”,然后单击“继续”。
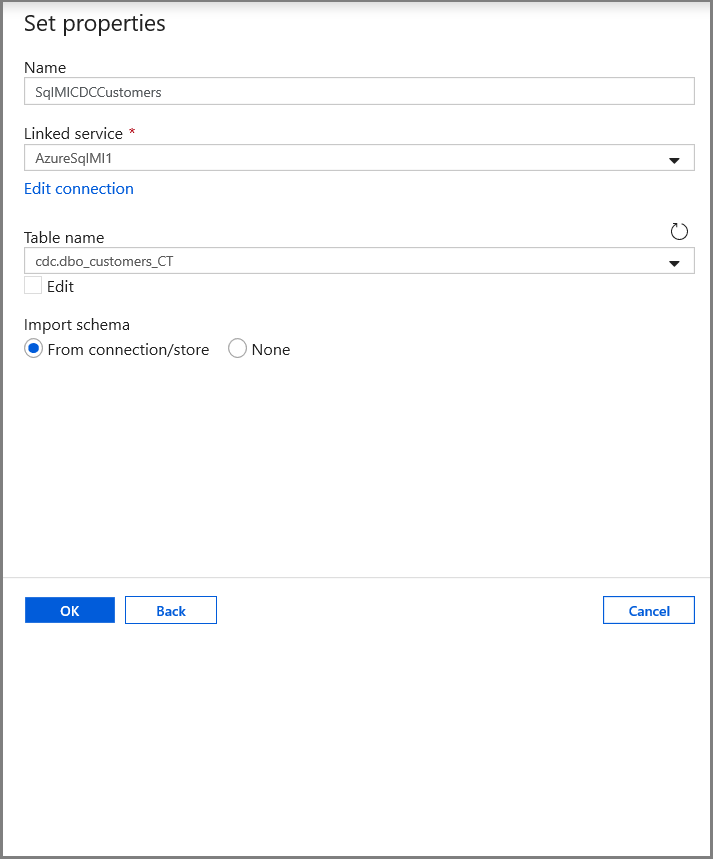
在“设置属性”选项卡中,设置数据集名称和连接信息:
- 对于“链接服务”,请选择“AzureSqlMI1”。
- 对于“表名称”,请选择“[dbo].[dbo_customers_CT]”。 注意:对 customers 表启用 CDC 时,将自动创建此表。 更改的数据永远不会直接从该表查询获得,而是通过 CDC 函数提取获得。
创建一个数据集,用于表示复制到接收器数据存储的数据。
在此步骤中,请创建一个数据集,代表从源数据存储复制的数据。 在执行先决条件中的步骤时,你已在 Azure Blob 存储中创建了 Data Lake 容器。 创建容器(如果不存在),或者将容器设置为现有容器的名称。 在本教程中,输出文件名是使用触发器时间动态生成的,稍后将对其进行配置。
在树状视图中,依次单击“+”(加号)、“数据集”。
选择“Azure Blob 存储”,然后单击“继续”。

选择“DelimitedText”,然后单击“继续”。

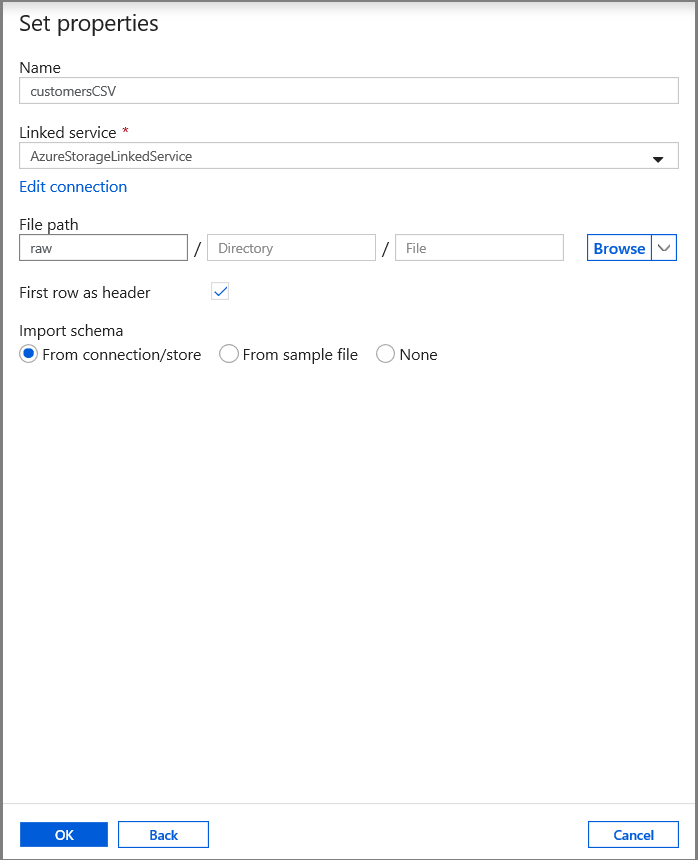
在“设置属性”选项卡中,设置数据集名称和连接信息:
- 为“链接服务”选择“AzureStorageLinkedService”。
- 输入“raw”作为“文件路径”的“容器”部分。
- 启用“第一行作为标题”
- 单击“确定”
创建复制已更改数据的管道
在此步骤中,将创建管道,该管道首先使用查找活动检查 change 表中存在的已更改记录的数量。 “IF 条件”活动检查已更改记录的数量是否大于零,然后运行复制活动以将插入/更新/删除的数据从 Azure SQL 数据库复制到 Azure Blob 存储。 最后,配置翻转窗口触发器,并且开始和结束时间将传递给活动作为开始和结束窗口参数。
在数据工厂 UI 中,切换到“编辑”选项卡。依次单击左窗格中的“+”(加号)、“管道”。
此时会显示用于配置管道的新选项卡。 树状视图中也会显示管道。 在“属性”窗口中,将管道的名称更改为 IncrementalCopyPipeline。
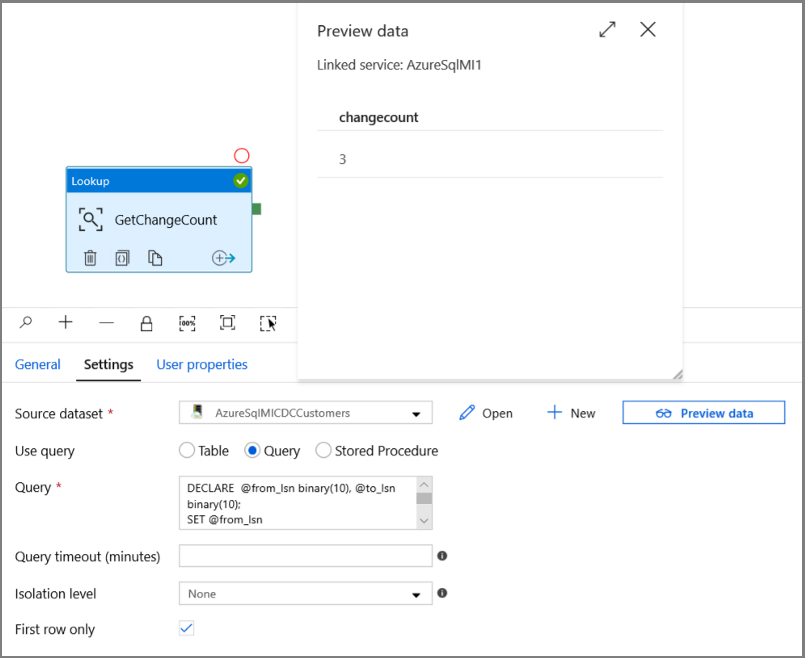
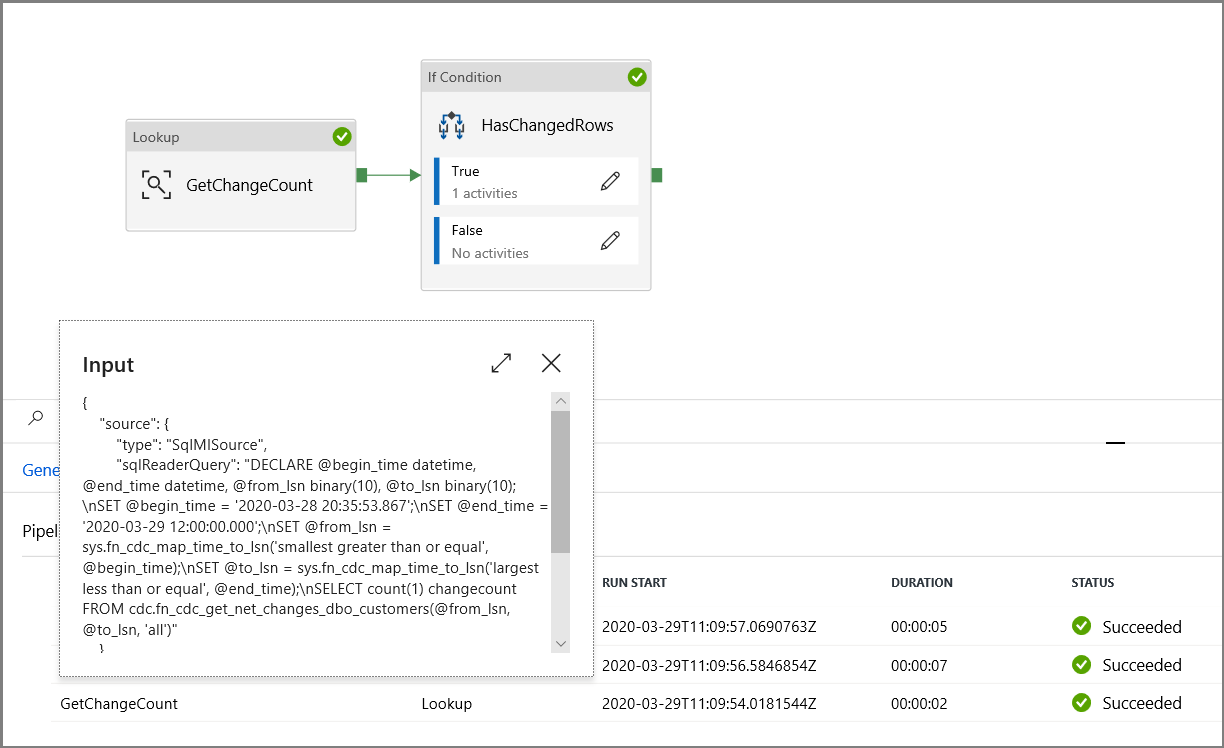
在“活动”工具箱中展开“常规”, 将查找活动拖放到管道设计器图面。 将活动名称设置为“GetChangeCount”。 此活动获取给定时间窗口内 change 表中的记录数。
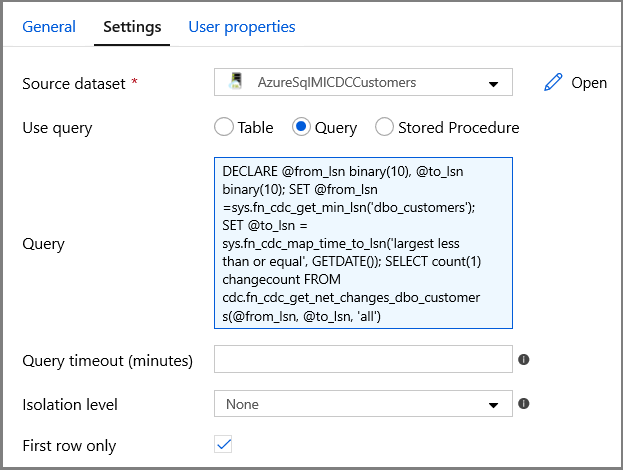
切换到“属性”窗口中的“设置”:
对于源数据集字段,请指定 SQL MI 数据集名称。
选择“查询”选项,并在查询框中输入以下内容:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- 启用“仅第一行”
单击“预览数据”按钮,以确保“查找”活动获取有效输出
在“活动”工具箱中展开“迭代和条件”,然后将“If 条件”活动拖放到管道设计器图面。 将活动名称设置为“HasChangedRows”。
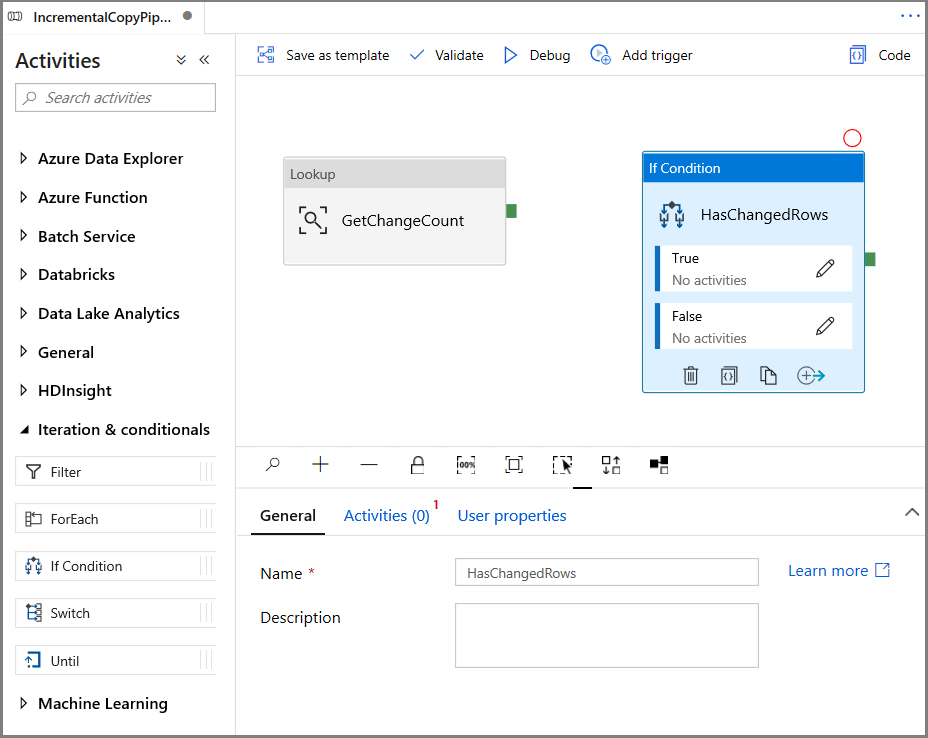
切换到“属性”窗口中的“活动”:
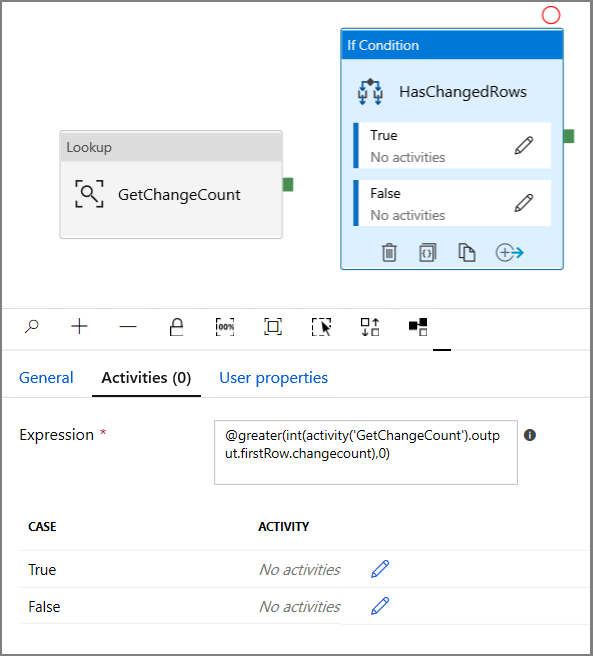
- 输入以下表达式
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- 单击铅笔图标编辑 True 条件。
- 在“活动”工具箱中展开“常规”,然后将“等待”活动拖放到管道设计器图面。 这是为了调试 If 条件的临时活动,将在本教程的后面部分进行更改。
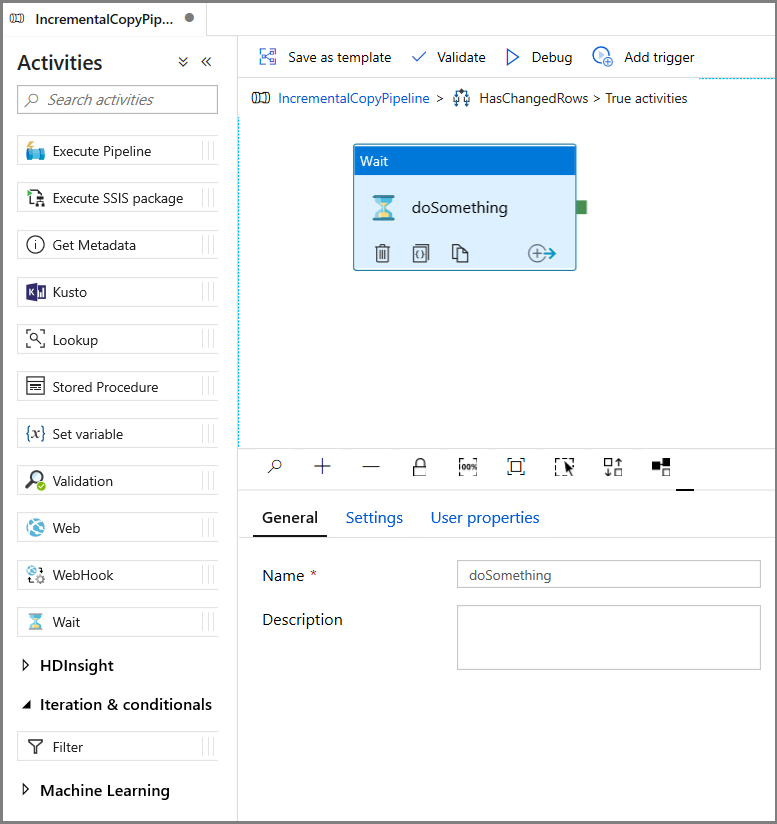
- 单击 IncrementalCopyPipeline 痕迹,以返回到主管道。
在“调试”模式下运行管道,以验证管道是否成功执行。
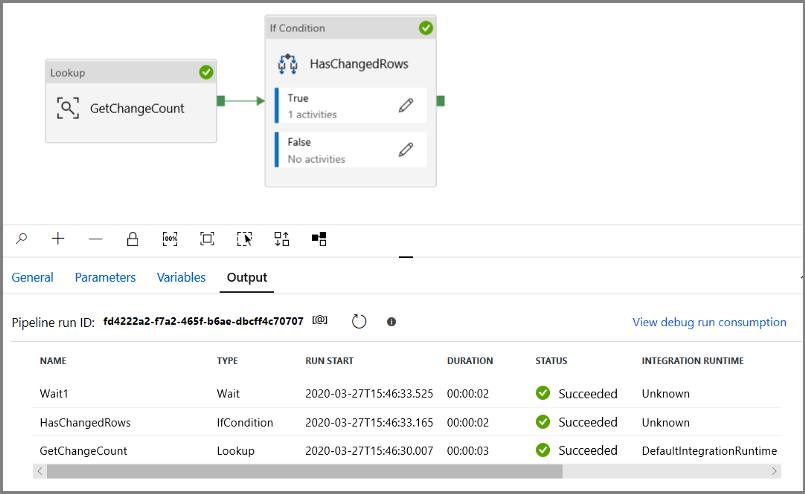
接下来,返回到 True 条件步骤,并删除“等待”活动。 在“活动”工具箱中,展开“移动和转换”,然后将“复制”活动拖放到管道设计器图面。 将活动的名称设置为 IncrementalCopyActivity。
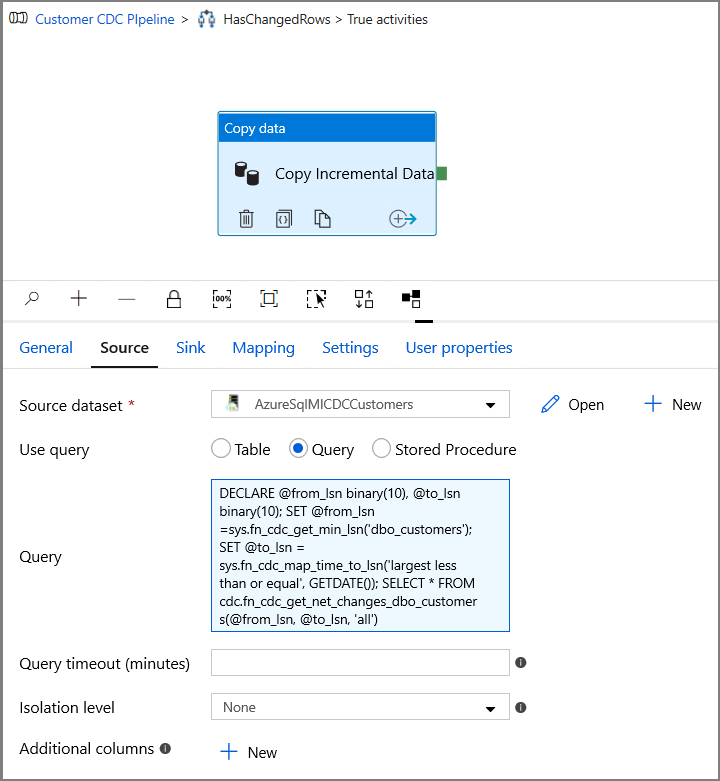
在“属性”窗口中切换到“源”选项卡,然后执行以下步骤:
对于源数据集字段,请指定 SQL MI 数据集名称。
为“使用查询”选择“查询”。
为“查询”输入以下内容。
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
单击“预览”,以验证查询是否正确返回更改的行。
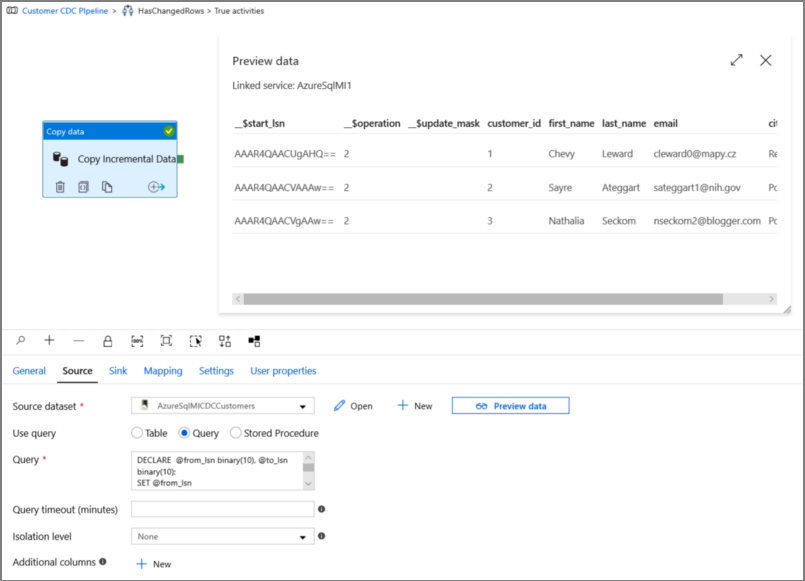
切换到“接收器”选项卡,然后为“接收器数据集”字段指定 Azure 存储数据集。

单击一下返回到主管道画布,然后将“查找”活动逐个连接到“If 条件”活动。 将附加到“查找”活动的绿色按钮拖放到“If 条件”活动。
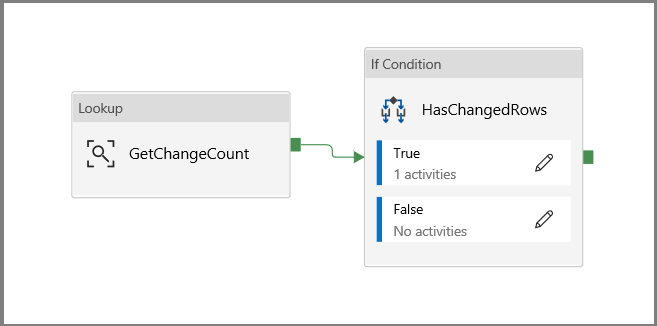
在工具栏中单击“验证”。 确认没有任何验证错误。 单击 >> 关闭“管道验证报告”窗口。
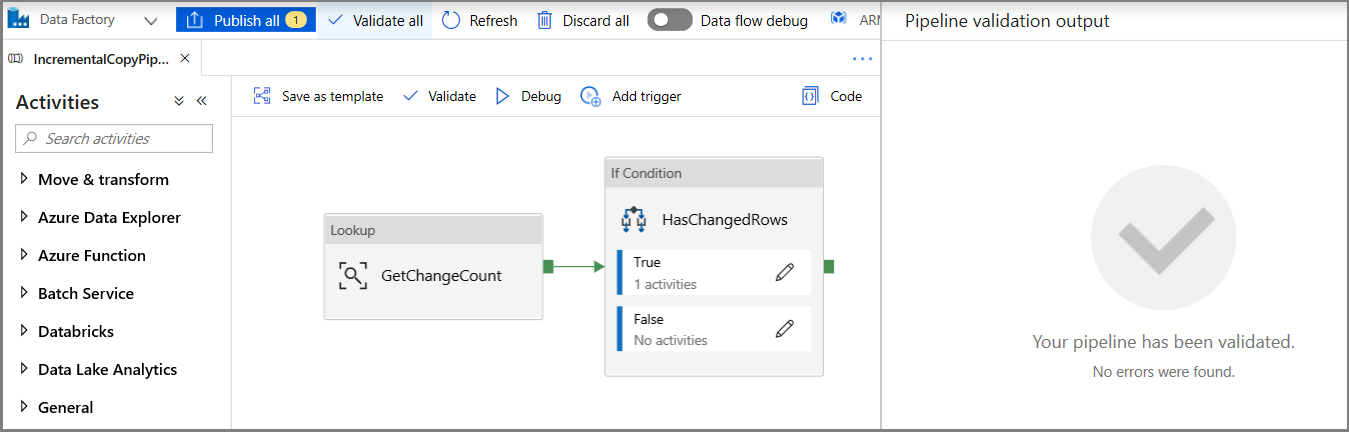
单击“调试”以测试管道,并验证是否在存储位置生成了一个文件。
单击“全部发布”按钮,将实体(链接服务、数据集和管道)发布到数据工厂服务。 等到“发布成功”消息出现。
配置翻转窗口触发器和 CDC 窗口参数
在此步骤中,将创建翻转窗口触发器以便按计划定期运行作业。 将使用翻转窗口触发器的 WindowStart 和 WindowEnd 系统变量,并将它们作为参数传递给要在 CDC 查询中使用的管道。
导航到“IncrementalCopyPipeline”管道的“参数”选项卡,然后使用“+ 新建”按钮将两个参数(triggerStartTime 和 triggerEndTime)添加到管道,这将表示翻转窗口的开始和结束时间。 出于调试目的,请以格式 YYYY-MM-DD HH24:MI:SS.FFF 添加默认值,但确保 triggerStartTime 不早于要对该表启用的 CDC,否则这将导致错误。
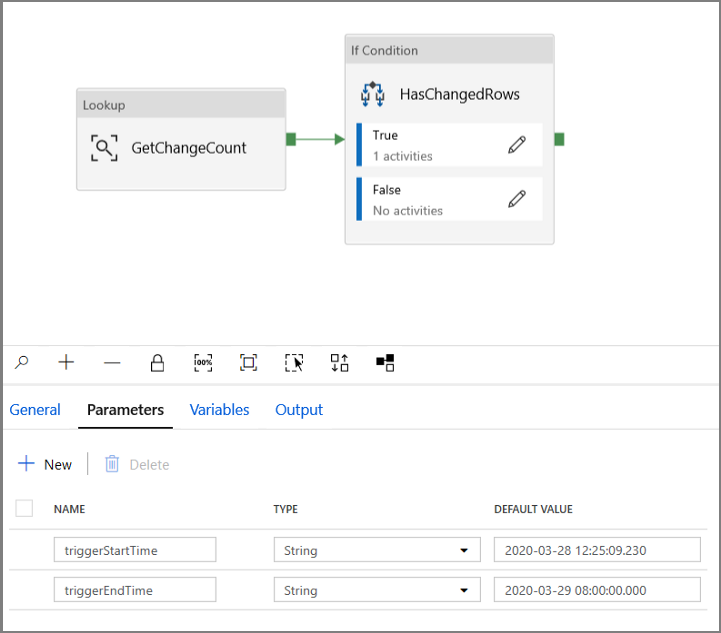
单击“查找”活动的“设置”选项卡,并将查询配置为使用 start 和 end 参数。 将以下内容复制到查询:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')在“If 条件”活动为 True 的情况下,导航到“复制”活动,然后单击“源”选项卡。将以下内容复制到查询:
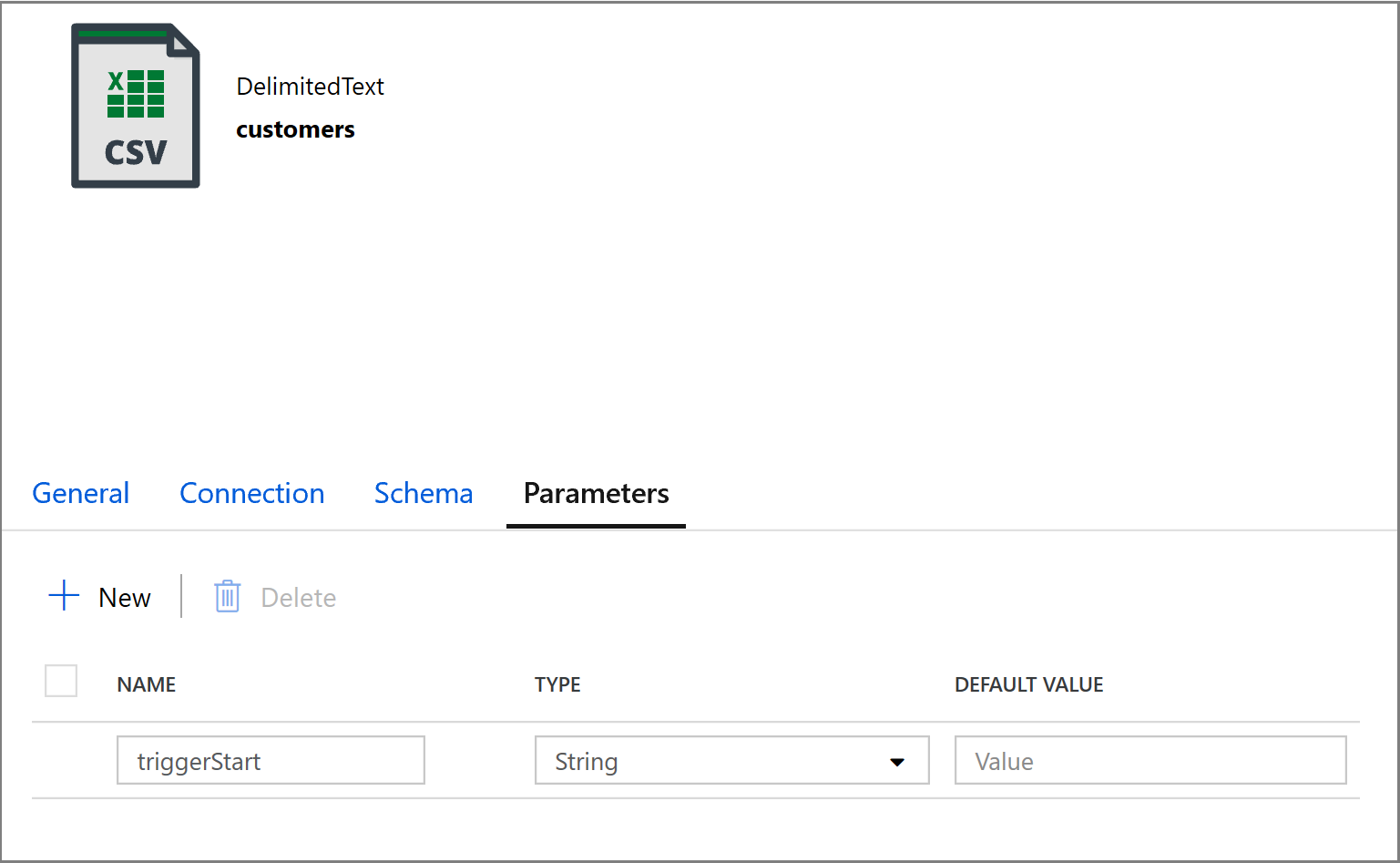
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')单击“复制”活动的“接收器”选项卡,然后单击“打开”以编辑数据集属性。 单击“参数”选项卡,然后添加名为“triggerStart”的新参数
接下来,配置数据集属性以将数据存储在具有基于日期的分区的“客户/增量”子目录中。
单击数据集属性的“连接”选项卡,然后为“目录”和“文件”部分添加动态内容。
单击文本框下方的动态内容链接,在“目录”部分中输入以下表达式:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))在“文件”部分中输入以下表达式。 这将根据触发器的开始日期和时间创建文件名,其后缀为 csv 扩展名:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')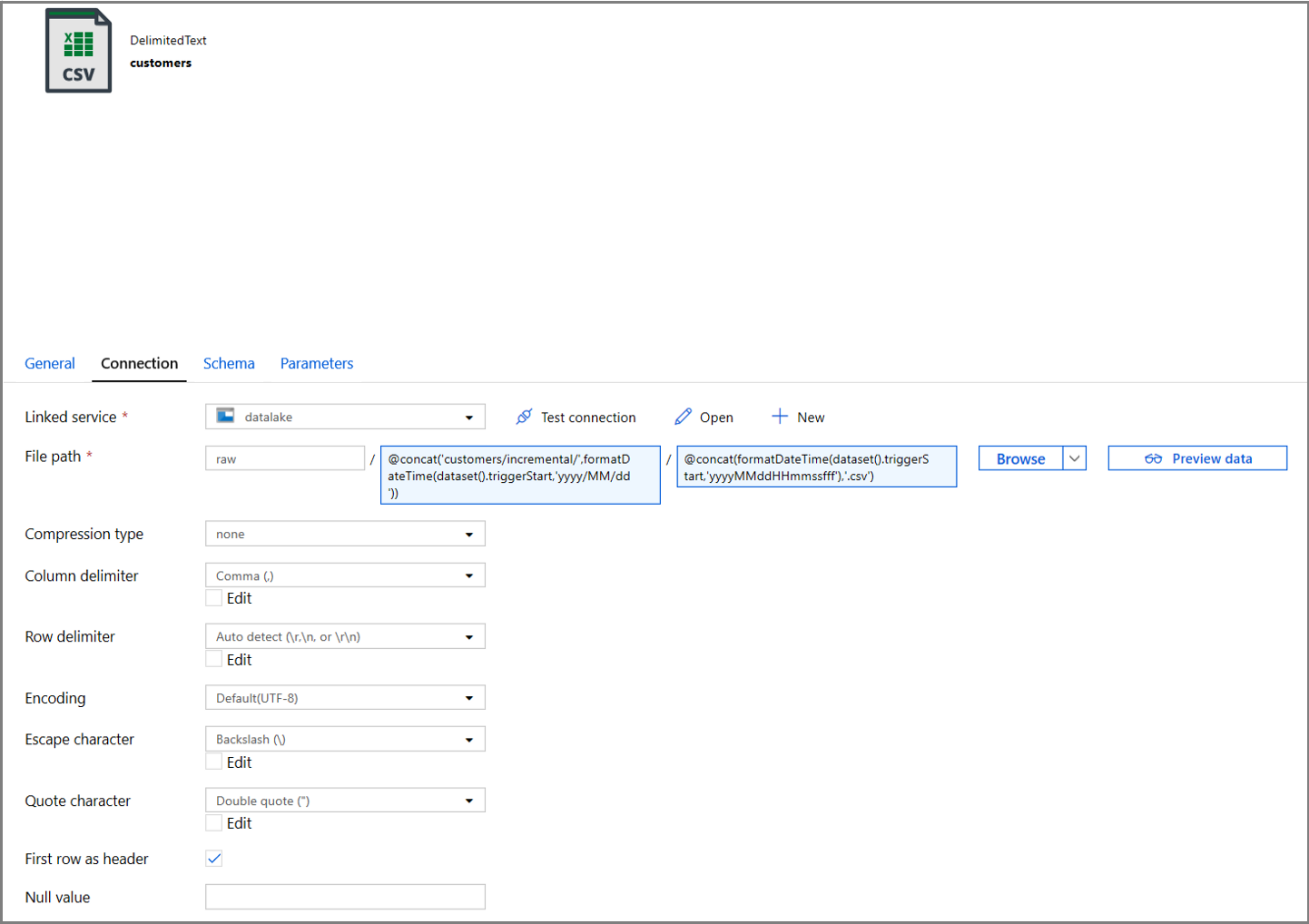
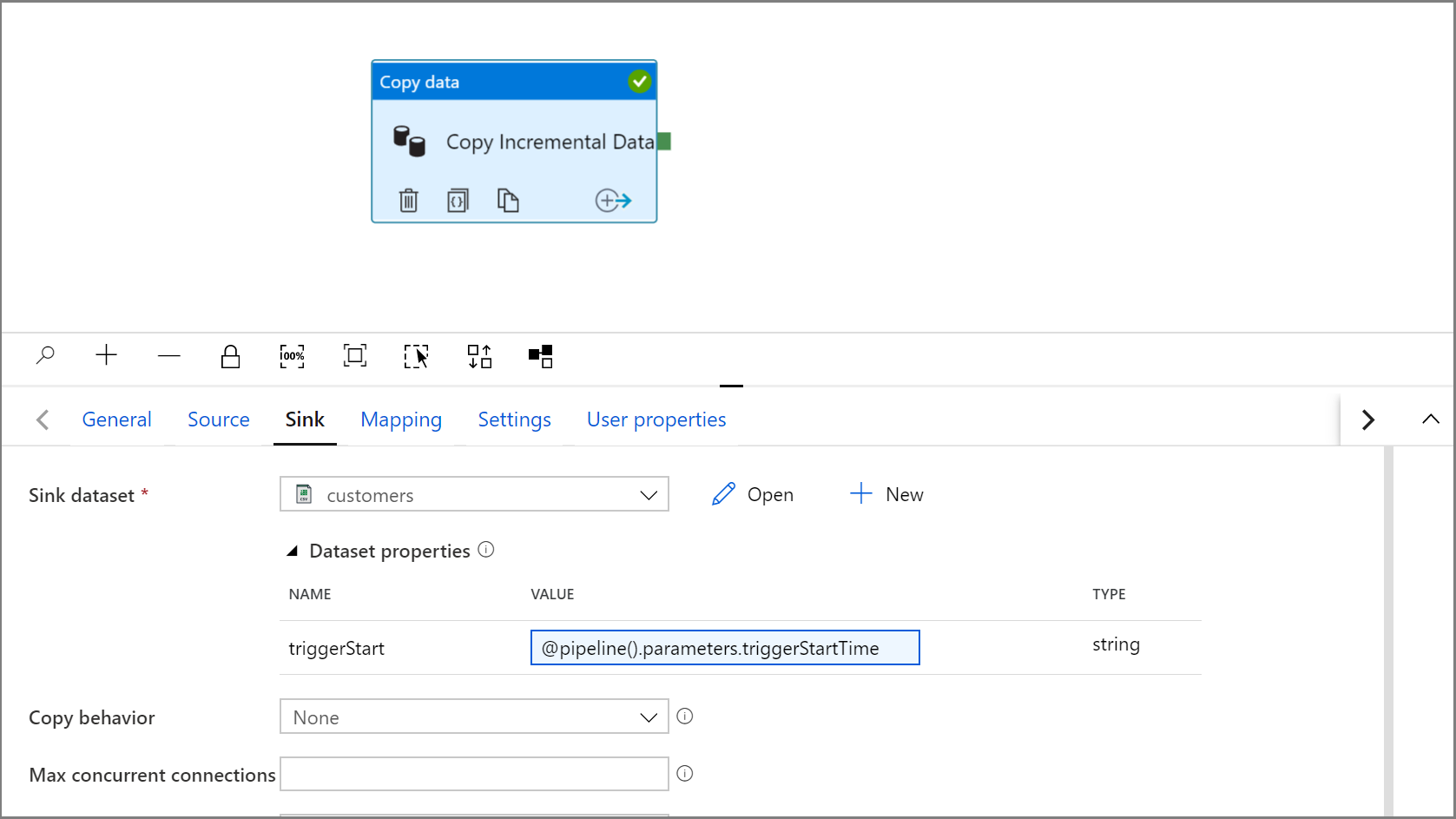
单击“IncrementalCopyPipeline”选项卡,导航回到“复制”活动中的“接收器”设置。
展开数据集属性,然后使用以下表达式在 triggerStart 参数值中输入动态内容:
@pipeline().parameters.triggerStartTime
单击“调试”以测试管道,并确保文件夹结构和输出文件按预期生成。 下载并打开该文件以验证内容。
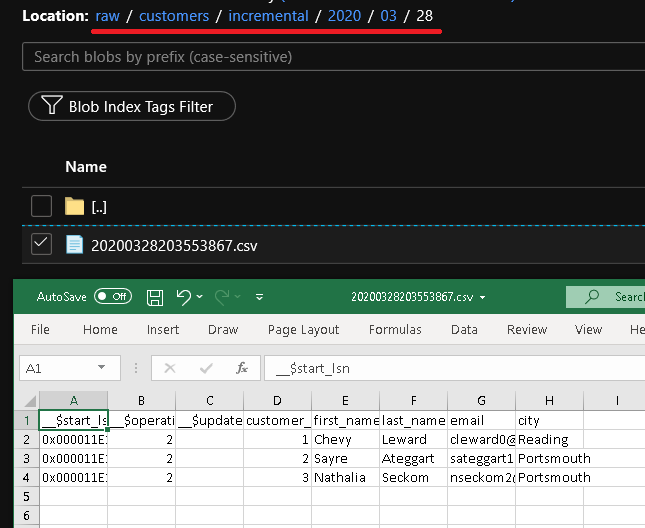
通过查看管道运行的输入参数,确保参数将注入到查询中。
单击“全部发布”按钮,将实体(链接服务、数据集和管道)发布到数据工厂服务。 等到“发布成功”消息出现。
最后,配置翻转窗口触发器以便按固定间隔运行管道,并设置开始时间和结束时间参数。
- 单击“添加触发器”按钮,然后选择“新建/编辑”
- 输入触发器名称并指定开始时间,该时间等于上述调试窗口的结束时间。
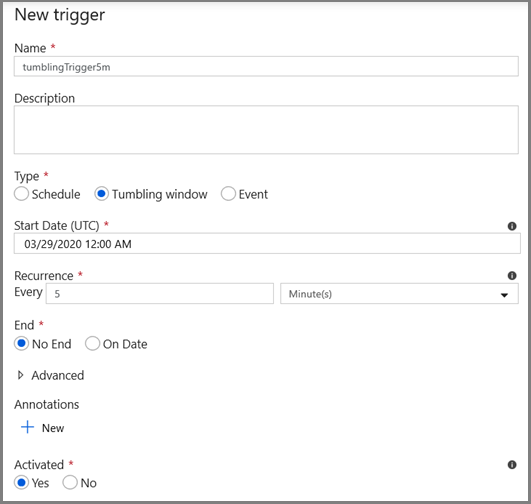
在下一个屏幕上,分别为 start 和 end 参数指定以下值。
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')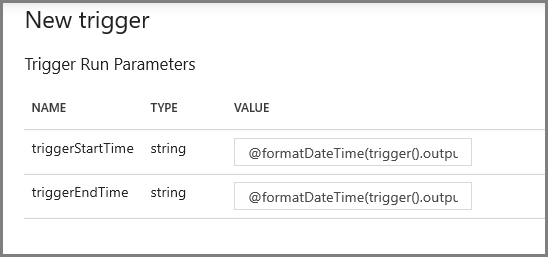
注意
触发器仅在发布后运行。 此外,翻转窗口的预期行为是运行从开始日期到现在的所有历史间隔。 有关翻转窗口触发器的详细信息,请参阅此处。
使用 SQL Server Management Studio,通过运行以下 SQL 对 customer 表进行一些其他更改:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;单击“全部发布”按钮。 等到“发布成功”消息出现。
几分钟后,管道将触发并且新文件将加载到 Azure 存储中
监视增量复制管道
单击左侧的“监视”选项卡。 可以在列表中查看管道运行及其状态。 若要刷新列表,请单击“刷新”。 将鼠标光标悬停在管道名称附近,以访问“重新运行”操作和“消耗”报告。
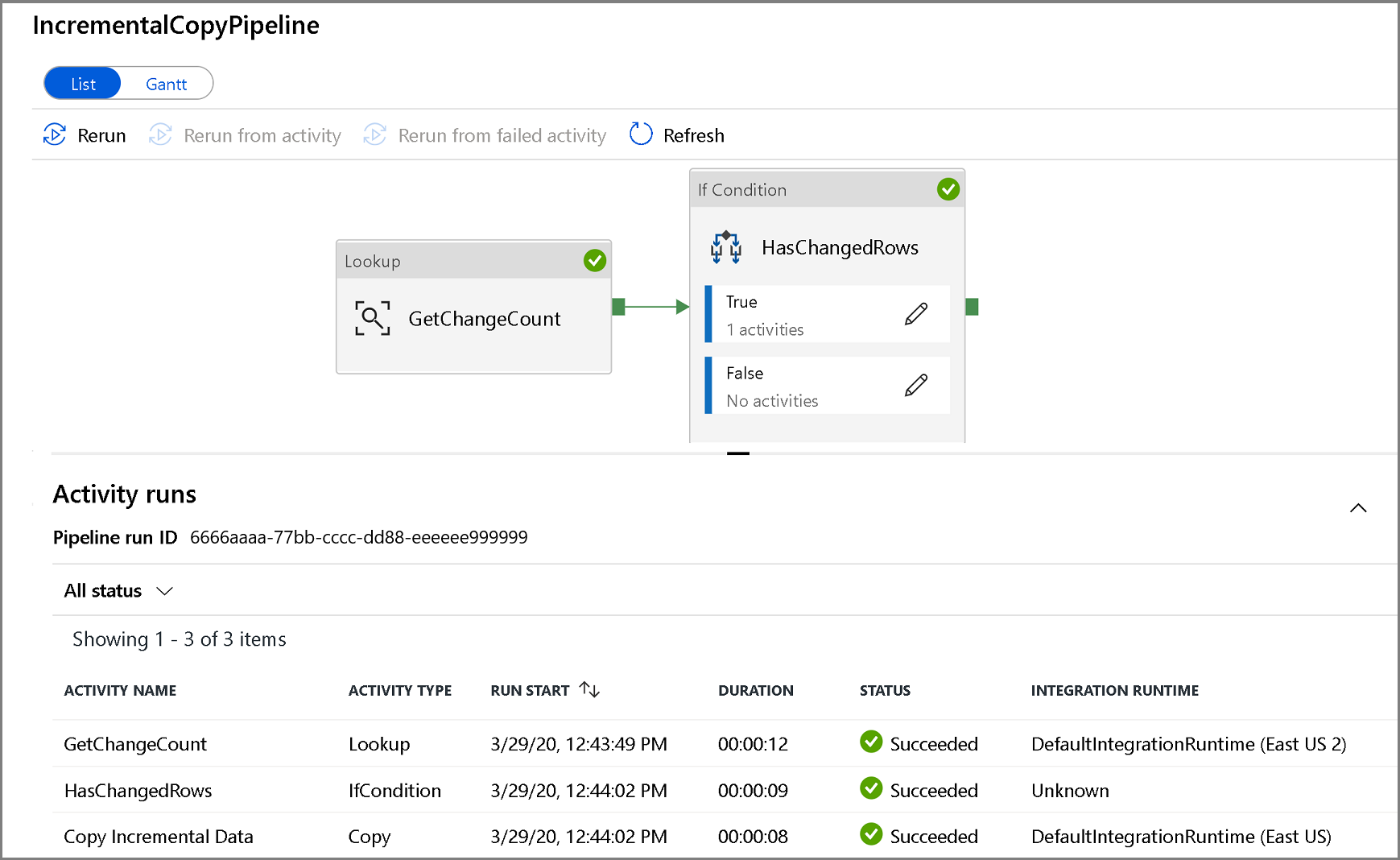
若要查看与管道运行关联的活动运行,请单击管道名称。 如果检测到更改的数据,将有三个活动(包括复制活动),否则列表中将只有两个条目。 若要切换回到管道运行视图,请单击顶部的“所有管道”链接。
查看结果
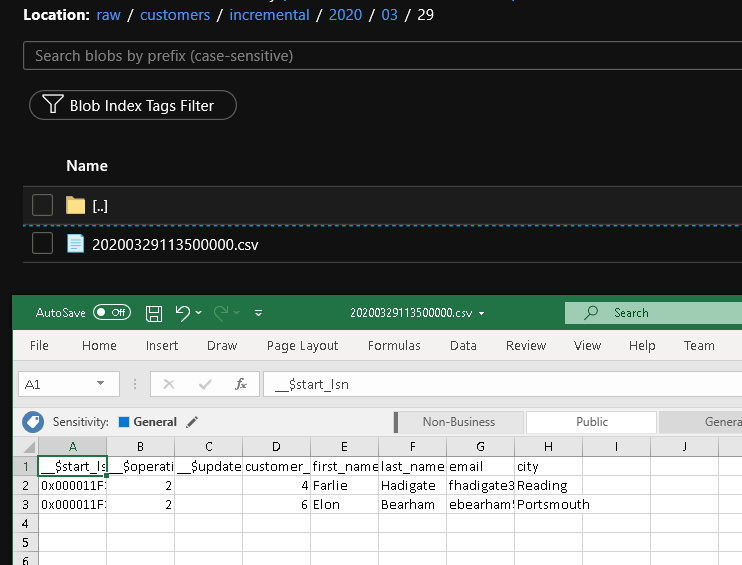
可以在 raw 容器的 customers/incremental/YYYY/MM/DD 文件夹中看到第二个文件。
相关内容
继续查看以下教程,了解如何仅基于 LastModifiedDate 来复制新的和更改的文件: