你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
映射数据流性能和优化指南
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
Azure 数据工厂和 Synapse 管道中的映射数据流提供一个无代码界面,用于大规模设计和运行数据转换。 如果你不熟悉映射数据流,请参阅映射数据流概述。 本文重点介绍调整和优化数据流以使它们达到性能基准的各种方法。
观看下面的视频,看看显示了用数据流转换数据的一些示例计时。
监视数据流性能
使用调试模式验证转换逻辑后,以管道中活动的形式端到端地运行数据流。 数据流使用执行数据流活动在管道内进行操作化。 相较于其他活动,数据流活动具有独特的监视体验,其中显示了转换逻辑的详细执行计划和性能配置文件。 若要查看数据流的详细监视信息,请选择管道的活动运行输出中的眼镜图标。 有关详细信息,请参阅监视映射数据流。

监视数据流性能时,需注意四个潜在瓶颈:
- 群集启动时间
- 从源中读取
- 转换时间
- 写入接收器
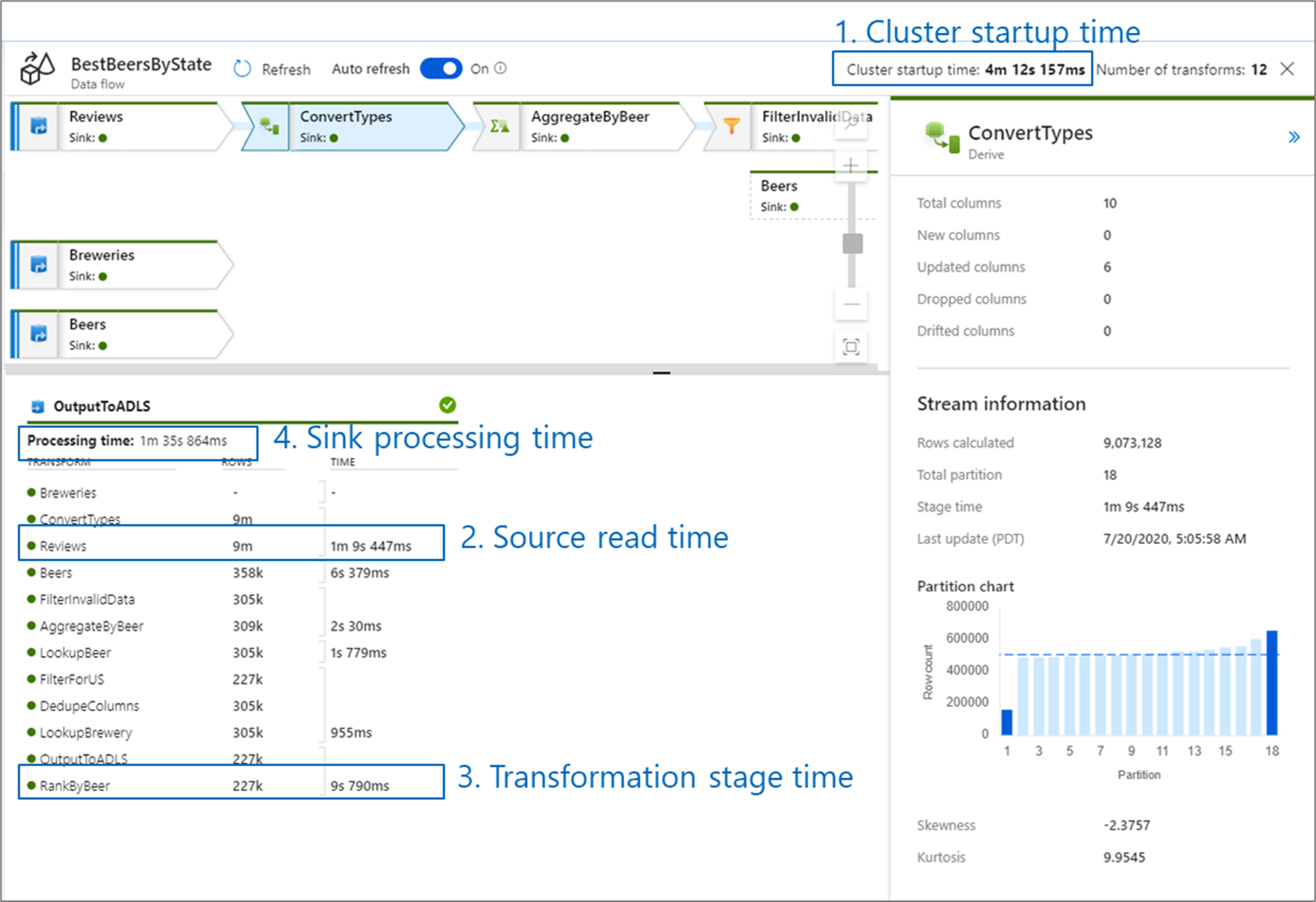
群集启动时间是指启动 Apache Spark 群集所需的时间。 该值位于监视屏幕的右上角。 数据流在实时模型上运行,其中每个作业都使用独立的群集。 该启动时间通常为 3-5 分钟。 对于顺序作业,可以通过启用生存时间值来缩短启动时间。 有关详细信息,请参阅 Integration Runtime 性能中的“生存时间”部分。
数据流利用 Spark 优化器对“阶段”中的业务逻辑进行重新排序并运行,从而尽可能快地执行。 对于数据流写入的每个接收器,监视输出列出每个转换阶段的持续时间,以及将数据写入接收器所需的时间。 最长的持续时间可能就是数据流的瓶颈。 如果耗时最久的转换阶段包含源,则建议考虑进一步优化读取时间。 如果转换耗时久,则可能需要重新分区或增加集成运行时的大小。 如果接收器处理时间耗时久,则可能需要扩展数据库或验证是否未输出到单个文件。
确定数据流的瓶颈后,请使用以下优化策略来优化性能。
测试数据流逻辑
从 UI 设计和测试数据流时,调试模式支持以交互方式测试实时 Spark 群集,这样你可以预览数据并执行数据流,而无需等待群集预热。 有关详细信息,请参阅调试模式。
“优化”选项卡
“优化”选项卡包含用于配置 Spark 群集的分区方案的设置。 此选项卡存在于数据流的每个转换中,可指定是否要在转换完成后对数据进行重新分区。 调整分区可对跨计算节点的数据分布以及数据局部优化提供控制度,但会对数据流的总体性能同时造成正面影响和负面影响。
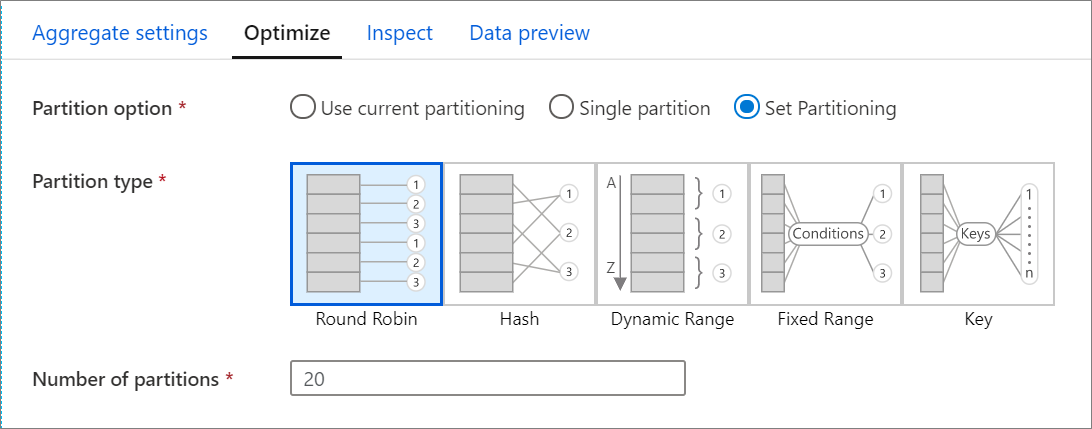
默认选中“使用当前分区”,这指示服务保留转换的当前输出分区。 由于对数据进行重新分区需要时间,因此在大多数情况下建议选择“使用当前分区”。 建议对数据进行重新分区的情况包括:“进行会严重倾斜数据的聚合和联接后”或“在 SQL 数据库上使用源分区时”。
若要更改任何转换的分区,请选择“优化”选项卡并选择“设置分区”单选按钮 。 你会看到一系列用于分区的选项。 最佳的分区方法根据数据量、候选键、null 值和基数而异。
重要
单一分区将所有分布式数据合并到一个分区。 此操作非常慢,还会严重影响所有下游转换和写入。 除非有明确的业务原因要使用此选项,否则极不建议使用它。
以下分区选项在每个转换中都可用:
轮循机制
轮循机制将数据平均分布到各个分区。 如果没有适当的候选键用于实施可靠、智能的分区策略,请使用轮循机制。 可以设置物理分区数目。
哈希
服务将生成列的哈希来生成统一的分区,使包含类似值的行划归到同一分区。 使用“哈希”选项时,请测试是否存在分区倾斜。 可以设置物理分区数目。
动态范围
动态范围基于提供的列或表达式使用 Spark 动态范围。 可以设置物理分区数目。
固定范围
生成一个表达式用于在分区的数据列中提供值的固定范围。 使用此选项之前,应该充分了解你的数据,以避免分区倾斜。 为表达式输入的值将用作分区函数的一部分。 可以设置物理分区数目。
键
如果你已充分了解数据的基数,则键分区可能是不错的策略。 键分区为列中的每个唯一值创建分区。 无法设置分区数目,因为该数目基于数据中的唯一值。
提示
手动设置分区方案会重新组合数据,可能会抵消 Spark 优化器的优势。 最佳做法是不要手动设置分区,除非有需要。
日志记录级别
如果不需要数据流活动的每个管道执行完整地记录所有详细的遥测日志,则可根据需要将日志记录级别设置为“基本”或“无”。 在“详细”模式(默认)下执行数据流时,要求此服务在数据转换期间完整地记录每个分区级别的活动。 该操作成本昂贵,因此仅在进行故障排除时启用“详细”模式可优化整体数据流和管道性能。 “基本”模式仅记录转换持续时间,而“无”模式仅提供持续时间的摘要。

相关内容
请参阅与性能相关的其他数据流文章: