你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用基于 vCore 的 Azure Cosmos DB for MongoDB 的检索增强生成 (RAG)
在快速发展的生成式 AI 领域中,GPT-3.5 等大语言模型 (LLM) 改变了自然语言处理。 但 AI 的新兴趋势是使用矢量存储,它在增强 AI 应用程序方面发挥了关键作用。
本教程介绍如何使用 Azure Cosmos DB for MongoDB (vCore)、LangChain 和 OpenAI 实现检索扩充生成 (RAG) 来提升 AI 性能,同时讨论了 LLM 及其限制。 我们将探讨“检索扩充生成”(RAG) 的快速采用模式,并简要讨论 LangChain 框架 和 Azure OpenAI 模型。 最后,我们将这些概念集成到实际应用程序中。 最终,读者将会形成对这些概念的深刻理解。
了解大语言模型 (LLM) 及其限制
大语言模型 (LLM) 是在广泛的文本数据集上训练的高级深度神经网络模型,能够理解和生成类似人工的文本。 虽然 LLM 在自然语言处理方面是革命性的,但它具有固有的限制:
- 幻觉:LLM 有时生成事实错误或无根据的信息,称为“幻觉”。
- 过时数据:LLM 在可能不包含最新信息的静态数据集上训练,从而限制其当前相关性。
- 无权访问用户的本地数据:LLM 无权直接访问个人或本地化数据,从而限制了其提供个性化响应的能力。
- 令牌限制:LLM 的每个交互存在最大令牌限制,这限制了模型可以一次处理的文本量。 例如,OpenAI 的 gpt-3.5-turbo 的令牌限制为 4096。
利用检索增强生成 (RAG)
检索扩充生成 (RAG) 是一种旨在克服 LLM 限制的体系结构。 RAG 使用矢量搜索基于输入查询检索相关文档,从而将这些文档作为上下文提供给 LLM,以便生成更准确的响应。 RAG 不完全依赖于预先训练的模式,而是通过整合最新的相关信息来增强响应。 此方法有助于:
- 在最大程度上减少幻觉:将响应根基于事实信息。
- 确保信息最新:检索最新的数据,以确保提供最新的响应。
- 利用外部数据库:尽管它不授予对个人数据的直接访问权限,但 RAG 允许与外部用户特定的知识库集成。
- 优化令牌使用情况:通过专注于最相关的文档,RAG 可以提高令牌使用的效率。
本教程演示如何使用 Azure Cosmos DB for MongoDB (vCore) 实现 RAG,以生成针对数据定制的问答应用程序。
应用程序体系结构概述
下面的体系结构关系图演示了 RAG 实现的关键组件:
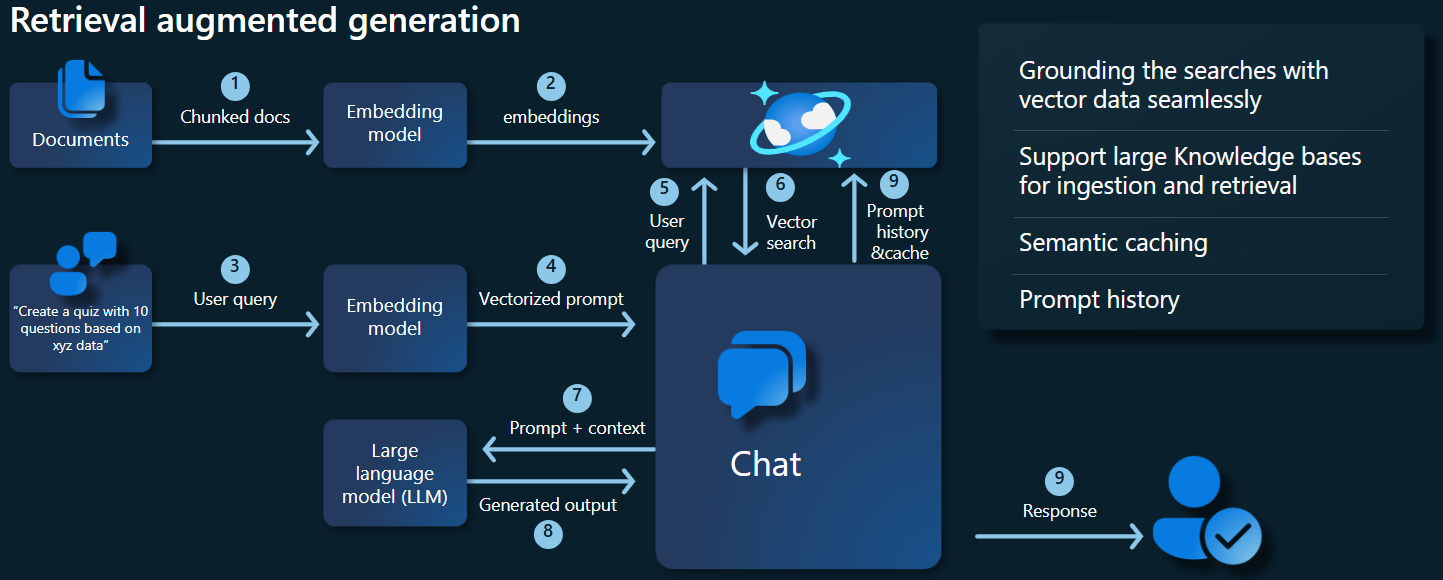
关键组件和框架
现在,我们将讨论本教程中使用的各种框架、模型和组件,着重讨论其角色和细微差别。
Azure Cosmos DB for MongoDB (vCore)
Azure Cosmos DB for MongoDB (vCore) 支持语义相似性搜索,这对于 AI 支持的应用程序至关重要。 它允许将各种格式的数据表示为矢量嵌入,从而可以与源数据和元数据一起存储。 使用分层可导航小型世界 (HNSW) 等近似最近邻算法,可以查询这些嵌入以进行快速语义相似性搜索。
LangChain 框架
LangChain 通过为常见任务提供适用于链、多个工具集成和端到端链的标准接口,简化了 LLM 应用程序的创建过程。 AI 开发人员能够借助它来生成利用外部数据源的 LLM 应用程序。
LangChain 的关键方面:
- 链:用于解决特定任务的组件序列。
- 组件:LLM 包装器、矢量存储包装器、提示模板、数据加载程序、文本拆分器和检索器等模块。
- 模块化:简化开发、调试和维护。
- 热门程度:开放源代码项目迅速获得采用并不断发展以满足用户需求。
Azure 应用服务界面
应用服务提供了一个可靠的平台,用于为 Gen-AI 应用程序构建用户友好的 Web 界面。 本教程使用 Azure 应用服务为应用程序创建交互式 Web 界面。
OpenAI 模型
OpenAI 是 AI 研究领域的领导者,为语言生成、文本矢量化、图像创建和音频转文本转换提供了各种模型。 在本教程中,我们将使用 OpenAI 的嵌入和语言模型,这对于理解和生成基于语言的应用程序至关重要。
嵌入模型与语言生成模型
| 类别 | 文本嵌入模型 | 语言模型 |
|---|---|---|
| 用途 | 将文本转换为矢量嵌入。 | 理解和生成自然语言。 |
| Function | 将文本数据转换为数字的高维数组,从而捕获文本的语义含义。 | 根据给定的输入理解并生成类似人工的文本。 |
| 输出 | 数字数组(矢量嵌入)。 | 文本、回答、翻译、代码等。 |
| 示例输出 | 每个嵌入都以数字形式表示文本的语义含义,其维度由模型确定。 例如,text-embedding-ada-002 会生成具有 1536 个维度的向量。 |
根据提供的输入生成的上下文相关且连贯的文本。 例如,gpt-3.5-turbo 可以生成对问题的响应、翻译文本、编写代码等。 |
| 典型用例 | - 语义搜索 | - 聊天机器人 |
| - 建议系统 | - 自动创建内容 | |
| - 文本数据的聚类分析和分类 | - 语言和翻译 | |
| - 信息检索 | - 汇总 | |
| 数据表示形式 | 数字表示形式(嵌入) | 自然语言文本 |
| 维度 | 数组的长度对应于嵌入空间中的维度数,例如 1536 个维度。 | 通常表示为令牌序列,其长度由上下文确定。 |
应用程序的主要组件
- Azure Cosmos DB for MongoDB vCore:存储和查询矢量嵌入。
- LangChain:构造应用程序的 LLM 工作流。 利用如下工具:
- 文档加载器:用于从目录中加载和处理文档。
- 矢量存储集成:用于在 Azure Cosmos DB 中存储和查询矢量嵌入。
- AzureCosmosDBVectorSearch:Cosmos DB 矢量搜索周围的包装器
- Azure 应用服务:生成 Cosmic Food 应用的用户界面。
- Azure OpenAI:用于提供 LLM 和嵌入模型,包括:
- text-embedding-ada-002:文本嵌入模型,可将文本转换为具有 1536 个维度的矢量嵌入。
- gpt-3.5-turbo:用于理解和生成自然语言的语言模型。
设置环境
要开始使用 Azure Cosmos DB for MongoDB (vCore) 优化检索扩充生成 (RAG),请执行以下步骤:
- 在 Microsoft Azure 上创建以下资源:
- Azure Cosmos DB for MongoDB vCore 群集:请参阅此处的快速入门指南。
- Azure OpenAI 资源,其中包括:
- 嵌入模型部署(例如,
text-embedding-ada-002)。 - 聊天模型部署(例如,
gpt-35-turbo)。
- 嵌入模型部署(例如,
示例文档
在本教程中,我们将使用文档来加载单个文本文件。 这些文件应保存在 src 文件夹中名为“数据”的目录中。 其内容如下所示:
food_items.json
{
"category": "Cold Dishes",
"name": "Hamachi Fig",
"description": "Hamachi sashimi lightly tossed in a fig sauce with rum raisins, and serrano peppers then topped with fried lotus root.",
"price": "16.0 USD"
},
加载文档
设置 Cosmos DB for MongoDB (vCore) 连接字符串、数据库名称、集合名称和索引:
mongo_client = MongoClient(mongo_connection_string) database_name = "Contoso" db = mongo_client[database_name] collection_name = "ContosoCollection" index_name = "ContosoIndex" collection = db[collection_name]初始化嵌入客户端。
from langchain_openai import AzureOpenAIEmbeddings openai_embeddings_model = os.getenv("AZURE_OPENAI_EMBEDDINGS_MODEL_NAME", "text-embedding-ada-002") openai_embeddings_deployment = os.getenv("AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT_NAME", "text-embedding") azure_openai_embeddings: AzureOpenAIEmbeddings = AzureOpenAIEmbeddings( model=openai_embeddings_model, azure_deployment=openai_embeddings_deployment, )根据数据创建嵌入,保存到数据库,并返回与矢量存储、Cosmos DB for MongoDB (vCore) 的连接。
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_documents( json_data, azure_openai_embeddings, collection=collection, index_name=index_name, )在集合上创建以下 HNSW 向量索引(请注意索引的名称与上面相同)。
num_lists = 100 dimensions = 1536 similarity_algorithm = CosmosDBSimilarityType.COS kind = CosmosDBVectorSearchType.VECTOR_HNSW m = 16 ef_construction = 64 vector_store.create_index( num_lists, dimensions, similarity_algorithm, kind, m, ef_construction )
使用 Cosmos DB for MongoDB (vCore) 执行矢量搜索
连接到矢量存储。
vector_store: AzureCosmosDBVectorSearch = AzureCosmosDBVectorSearch.from_connection_string( connection_string=mongo_connection_string, namespace=f"{database_name}.{collection_name}", embedding=azure_openai_embeddings, )定义对查询使用 Cosmos DB 矢量搜索执行语义相似性搜索的函数(请注意,此代码片段只是一个测试函数)。
query = "beef dishes" docs = vector_store.similarity_search(query) print(docs[0].page_content)初始化聊天客户端以实现 RAG 函数。
azure_openai_chat: AzureChatOpenAI = AzureChatOpenAI( model=openai_chat_model, azure_deployment=openai_chat_deployment, )创建 RAG 函数。
history_prompt = ChatPromptTemplate.from_messages( [ MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ( "user", """Given the above conversation, generate a search query to look up to get information relevant to the conversation""", ), ] ) context_prompt = ChatPromptTemplate.from_messages( [ ("system", "Answer the user's questions based on the below context:\n\n{context}"), MessagesPlaceholder(variable_name="chat_history"), ("user", "{input}"), ] )将矢量存储转换为检索器,该检索器可以根据指定的参数搜索相关文档。
vector_store_retriever = vector_store.as_retriever( search_type=search_type, search_kwargs={"k": limit, "score_threshold": score_threshold} )创建了解会话历史记录的检索器链,以确保使用 azure_openai_chat 模型和 vector_store_retriever 进行上下文相关的文档检索。
retriever_chain = create_history_aware_retriever(azure_openai_chat, vector_store_retriever, history_prompt)创建使用语言模型 (azure_openai_chat) 和指定提示 (context_prompt) 将检索到的文档合并为一致响应的链。
context_chain = create_stuff_documents_chain(llm=azure_openai_chat, prompt=context_prompt)创建处理整个检索过程的链,以集成历史记录感知检索器链和文档组合链。 可以执行此 RAG 链来检索和生成上下文准确的响应。
rag_chain: Runnable = create_retrieval_chain( retriever=retriever_chain, combine_docs_chain=context_chain, )
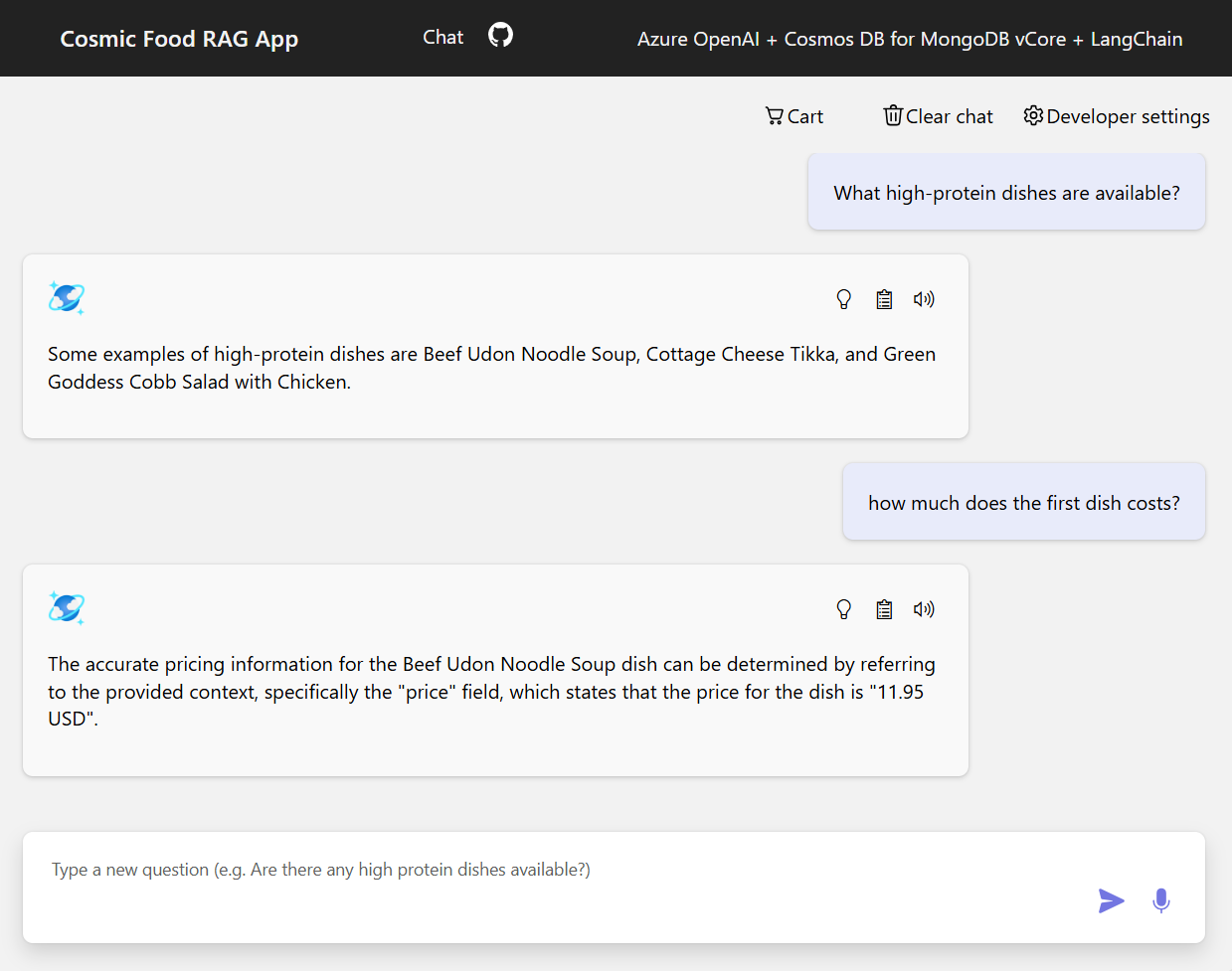
示例输出
下面的屏幕截图演示了各种问题的输出。 纯粹的语义相似性搜索会从源文档返回原始文本,而使用 RAG 体系结构的问答应用会通过将检索到的文档内容与语言模型相结合,以生成精确而个性化的回答。
结束语
在本教程中,我们探讨了了如何使用 Cosmos DB 作为向量存储来构建与专用数据交互的问答应用。 通过利用 LangChain 和 Azure OpenAI 的检索扩充生成 (RAG) 体系结构,我们演示了向量存储对于 LLM 应用程序的重要性。
RAG 是 AI 领域,尤其是自然语言处理方面取得的显著进步,通过结合使用这些技术,可为各种用例创建功能强大的 AI 驱动型应用程序。