你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure Cosmos DB 中的索引概述
适用对象:![]() NoSQL
NoSQL![]() MongoDB
MongoDB![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() 表
表
Azure Cosmos DB 是一种架构不可知的数据库,你可用它来迭代应用程序,而无需处理架构或索引管理。 默认情况下,Azure Cosmos DB 自动对容器中所有项的每个属性编制索引,不用定义任何架构或配置辅助索引。
本文的目的是说明 Azure Cosmos DB 如何为数据编制索引以及如何使用索引来提高查询性能。 建议先阅读本部分,然后再了解如何自定义索引策略。
从项到树
每次在容器中存储项时,项的内容都投影为 JSON 文档,然后转换为树表示形式。 此转换意味着,该项的每个属性都在树中以节点的形式呈现。 伪根节点被创建为项的所有第一级属性的父级。 叶节点包含项带有的实际标量值。
例如,请看以下项:
{
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
此树表示示例 JSON 项:
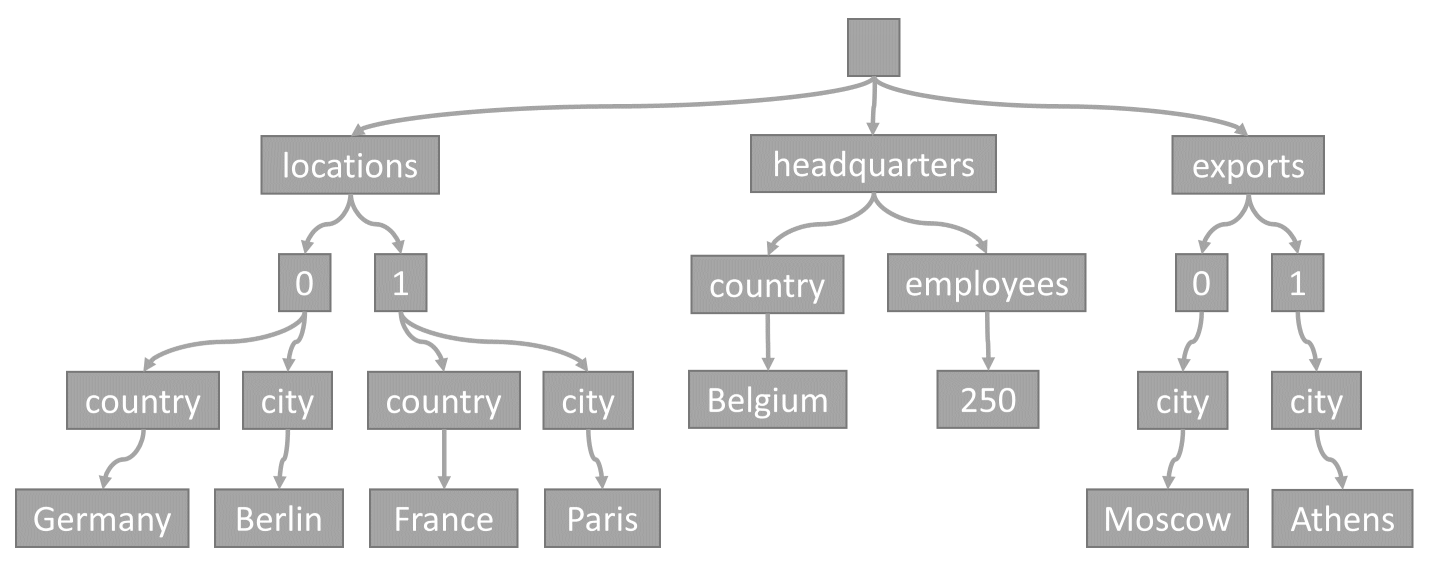
请注意数组是如何在树中进行编码的:数组中的每个条目都获得一个中间节点,该节点标记了该数组中该条目的索引(0、1 等等)。
从树到属性路径
Azure Cosmos DB 将项转换为树的原因是,它允许系统通过这些树中属性的路径来引用属性。 若要获取属性的路径,可从根节点到该属性来遍历树,并将每个遍历的节点的标签连接起来。
下面是之前描述的示例项中每个属性的路径:
/locations/0/country:"Germany"/locations/0/city:"Berlin"/locations/1/country:"France"/locations/1/city:"Paris"/headquarters/country:"Belgium"/headquarters/employees:250/exports/0/city:"Moscow"/exports/1/city:"Athens"
写入项时,Azure Cosmos DB 会有效地对每个属性的路径及其相应的值编制索引。
索引类型
Azure Cosmos DB 目前支持三种类型的索引。 定义索引策略时,可以配置这些索引类型。
范围索引
范围索引基于已排序的树形结构。 范围索引类型用于:
相等查询:
SELECT * FROM container c WHERE c.property = 'value'SELECT * FROM c WHERE c.property IN ("value1", "value2", "value3")数组元素上的相等匹配
SELECT * FROM c WHERE ARRAY_CONTAINS(c.tags, "tag1")范围查询:
SELECT * FROM container c WHERE c.property > 'value'注意
(适用于
>、<、>=、<=、!=)检查属性是否存在:
SELECT * FROM c WHERE IS_DEFINED(c.property)字符串系统函数:
SELECT * FROM c WHERE CONTAINS(c.property, "value")SELECT * FROM c WHERE STRINGEQUALS(c.property, "value")ORDER BY查询:SELECT * FROM container c ORDER BY c.propertyJOIN查询:SELECT child FROM container c JOIN child IN c.properties WHERE child = 'value'
范围索引可用于标量值(字符串或数字)。 新建容器的默认索引策略会对任何字符串或数字强制使用范围索引。 若要了解如何配置范围索引,请参阅范围索引策略示例
注意
按单个属性排序的 ORDER BY 子句总是需要一个范围索引,如果它引用的路径没有范围索引,则会失败。 同样地,按多个属性排序的 ORDER BY 查询总是需要一个组合索引。
空间索引
空间索引可对地理空间对象(例如点、线、多边形和多面)进行有效查询。 这些查询使用ST_DISTANCE、ST_WITHIN 和 ST_INTERSECTS 关键字。 下面是使用空间索引类型的一些示例:
地理空间距离查询:
SELECT * FROM container c WHERE ST_DISTANCE(c.property, { "type": "Point", "coordinates": [0.0, 10.0] }) < 40在查询的地理空间:
SELECT * FROM container c WHERE ST_WITHIN(c.property, {"type": "Point", "coordinates": [0.0, 10.0] })地理空间相交查询:
SELECT * FROM c WHERE ST_INTERSECTS(c.property, { 'type':'Polygon', 'coordinates': [[ [31.8, -5], [32, -5], [31.8, -5] ]] })
空间索引可在格式正确的 GeoJSON 对象上使用。 目前支持点、线串、多边形和多面。 若要了解如何配置空间索引,请参阅空间索引策略示例
组合索引
对多个字段执行操作时,组合索引可提高效率。 复合索引类型用于:
对多个属性的
ORDER BY查询:SELECT * FROM container c ORDER BY c.property1, c.property2使用筛选器和
ORDER BY的查询。 如果在ORDER BY子句中添加筛选器属性,则这些查询可使用组合索引。SELECT * FROM container c WHERE c.property1 = 'value' ORDER BY c.property1, c.property2对两个或更多属性进行的带筛选器的查询,其中至少一个属性是等式筛选器
SELECT * FROM container c WHERE c.property1 = 'value' AND c.property2 > 'value'
只要一个筛选器谓词使用其中一种索引类型,查询引擎就会在扫描其余内容之前先对其进行评估。 例如,如果你有一个 SQL 查询,如 SELECT * FROM c WHERE c.firstName = "Andrew" and CONTAINS(c.lastName, "Liu")
上面的查询将先使用索引筛选 firstName = "Andrew" 的条目, 然后通过后续管道传递所有 firstName = "Andrew" 的条目来评估 CONTAINS 筛选器谓词。
使用执行完全扫描的函数(如 CONTAINS)时,可以加快查询速度并避免扫描整个容器。 可以添加更多使用索引的筛选器谓词来加快这些查询的速度。 筛选子句的顺序并不重要。 查询引擎将确定哪些谓词更具选择性,并相应地运行查询。
若要了解如何配置组合索引,请参阅组合索引策略示例
矢量索引
矢量索引可在使用 VectorDistance 系统函数执行矢量搜索时提高效率。 利用矢量索引时,矢量搜索的延迟明显降低、吞吐量变高、RU 消耗量降低。
若要了解如何配置矢量索引,请参阅矢量索引策略示例
ORDER BY矢量搜索查询:SELECT TOP 10 * FROM c ORDER BY VectorDistance(c.vector1, c.vector2)矢量搜索查询中相似性分数的投影:
SELECT TOP 10 c.name, VectorDistance(c.vector1, c.vector2) AS SimilarityScore FROM c ORDER BY VectorDistance(c.vector1, c.vector2)基于相似性分数的范围筛选器。
SELECT TOP 10 * FROM c WHERE VectorDistance(c.vector1, c.vector2) > 0.8 ORDER BY VectorDistance(c.vector1, c.vector2)
索引使用情况
查询引擎可采用 5 种方式来评估查询筛选器,按效率从高到低排序:
- 索引查找
- 精确索引扫描
- 扩展索引扫描
- 完全索引扫描
- 完全扫描
索引属性路径时,查询引擎会尽可能高效地自动使用索引。 除了索引新的属性路径外,无需配置任何内容即可优化查询使用索引的方式。 查询的请求单位 (RU) 费用是索引使用量的 RU 费用与加载项的 RU 费用之和。
下表汇总了在 Azure Cosmos DB 中使用索引的不同方式:
| 索引查找类型 | 说明 | 常见示例 | 索引使用量的 RU 费用 | 从事务数据存储中加载项的 RU 费用 |
|---|---|---|---|---|
| 索引查找 | 只读取所需的索引值,并且只从事务数据存储中加载匹配项 | 相等筛选器,IN | 每个相等筛选器的费用相同 | 根据查询结果中的项数增加 |
| 精确索引扫描 | 索引值的二进制搜索,并且只从事务数据存储中加载匹配项 | 范围比较(>、<、<= 或 >=),StartsWith | 与索引查找相比,根据索引属性的基数略有增加 | 根据查询结果中的项数增加 |
| 扩展索引扫描 | 索引值的优化搜索(但比二进制文搜索的效率低),并且只从事物数据存储中加载匹配项 | StartsWith(不区分大小写的),StringEquals(不区分大小写) | 根据索引属性的基数略有增加 | 根据查询结果中的项数增加 |
| 完全索引扫描 | 读取一组非重复的索引值,并且只从事务数据存储中加载匹配项 | Contains、EndsWith、RegexMatch、LIKE | 根据索引属性的基数呈线性增加 | 根据查询结果中的项数增加 |
| 完全扫描 | 从事务数据存储加载所有项 | Upper、Lower | 不适用 | 根据容器中的项数增加 |
编写查询时,应采用尽可能有效使用索引的筛选谓词。 例如,如果 StartsWith 或 Contains 都适合你的用例,应选择 StartsWith,因为它将执行精确索引扫描,而不是完全索引扫描。
索引使用情况详细信息
在此部分,我们将更详细地介绍查询是如何使用索引的。 如果是 Azure Cosmos DB 入门,那么这不是必学内容,但此级别的详细记录供感兴趣的用户查看。 我们将参考在本文档前面分享的示例项:
示例项:
{
"id": 1,
"locations": [
{ "country": "Germany", "city": "Berlin" },
{ "country": "France", "city": "Paris" }
],
"headquarters": { "country": "Belgium", "employees": 250 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" }
]
}
{
"id": 2,
"locations": [
{ "country": "Ireland", "city": "Dublin" }
],
"headquarters": { "country": "Belgium", "employees": 200 },
"exports": [
{ "city": "Moscow" },
{ "city": "Athens" },
{ "city": "London" }
]
}
Azure Cosmos DB 使用倒排索引。 索引的工作原理是将每个 JSON 路径映射到包含该值的一组项中。 对于容器,项 ID 映射跨多个不同的索引页表示。 以下是包含两个示例项的容器的倒排索引示例示意图:
| 路径 | 值 | 项 ID 列表 |
|---|---|---|
| /locations/0/country | Germany | 1 |
| /locations/0/country | Ireland | 2 |
| /locations/0/city | Berlin | 1 |
| /locations/0/city | Dublin | 2 |
| /locations/1/country | France | 1 |
| /locations/1/city | Paris | 1 |
| /headquarters/country | Belgium | 1, 2 |
| /headquarters/employees | 200 | 2 |
| /headquarters/employees | 250 | 1 |
倒排索引具有 2 个重要属性:
- 对于给定路径,值按升序排序。 因此,查询引擎可轻松地从索引中提供
ORDER BY。 - 对于给定路径,查询引擎可扫描一组非重复的可能值,以确定存在结果的索引页。
查询引擎使用倒排索引的方式有以下 4 种:
索引查找
请考虑下列查询:
SELECT location
FROM location IN company.locations
WHERE location.country = 'France'
查询谓词(对项进行筛选,其中任何位置都采用“France”作为其国家/地区)与此示意图中用红色突出显示的路径相匹配:
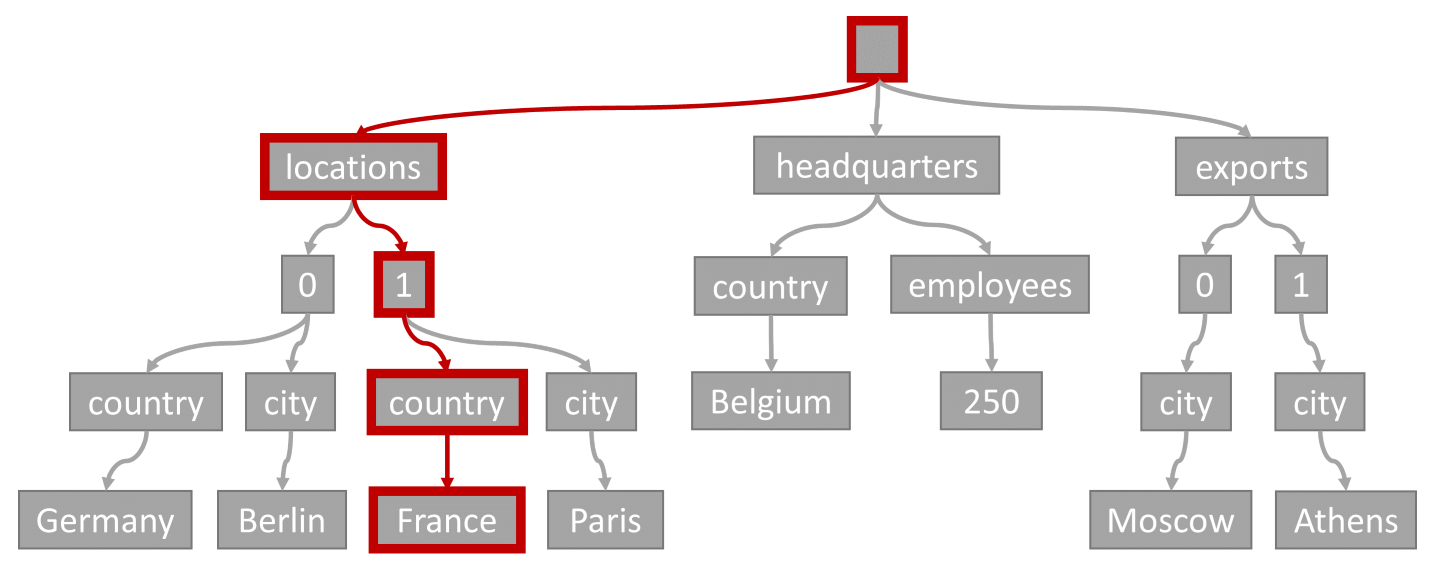
由于此查询具有相等筛选器,因此在遍历此树后,我们可以快速识别包含查询结果的索引页。 在这种情况下,查询引擎将读取包含项 1 的索引页。 索引查找是使用索引最有效的方式。 通过索引查找,我们只读取必要的索引页,并且只加载查询结果中的项。 因此,无论总数据量是多少,索引查找的查找时间都很短,并且 RU 费用低。
精确索引扫描
请考虑下列查询:
SELECT *
FROM company
WHERE company.headquarters.employees > 200
查询谓词(对具有超过 200 名员工的项进行筛选)可通过 headquarters/employees 路径的精确索引扫描进行评估。 执行精确索引扫描时,查询引擎首先对一组非重复的可能值进行二进制搜索,来查找 headquarters/employees 路径的值 200 的位置。 由于每个路径的值都是按升序排序的,因此查询引擎可轻松执行二进制搜索。 查询引擎找到值 200 后,将开始读取所有剩余的索引页(按升序反向)。
查询引擎可执行二进制搜索来避免扫描不必要的索引页,因此精确索引扫描的延迟和 RU 费用与索引查找操作相当。
扩展索引扫描
请考虑下列查询:
SELECT *
FROM company
WHERE STARTSWITH(company.headquarters.country, "United", true)
查询谓词(对总部位于以不区分大小写的“United”开头的位置的项目进行筛选)可通过 headquarters/country 路径的扩展索引扫描进行评估。 执行扩展索引扫描的操作具有一些优化,可帮助避免扫描每个索引页,但比精确索引扫描的二进制搜索略贵。
例如,在评估不区分大小写的 StartsWith 时,查询引擎将检查索引中是否有大写值和小写值混用的情况。 此优化使查询引擎能够避免读取大多数索引页。 不同的系统函数具有不同的优化,它们可用于避免读取每个索引页,因此我们可将其大致分类为扩展索引扫描。
完全索引扫描
请考虑下列查询:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
查询谓词(对总部位于包含“United”的位置的项目进行筛选)可通过 headquarters/country 路径的索引扫描进行评估。 与精确索引扫描不同,完全索引扫描将始终扫描一组非重复的可能值,以确定存在结果的索引页。 在这种情况下,索引上会运行 Contains。 索引扫描的索引查找时间和 RU 费用会随着路径基数的增加而增加。 换句话说,查询引擎需要扫描的可能的非重复值越多,执行完全索引扫描的延迟和 RU 费用就越高。
例如,请考虑两个属性:town 和 country。 town 的基数是 5,000,country 的基数是 200。 下面是两个示例查询,每个查询都有一个 Contains 系统函数来对 town 属性执行完全索引扫描。 第一个查询比第二个查询使用更多的 RU,因为 town 的基数高于 country 的基数。
SELECT *
FROM c
WHERE CONTAINS(c.town, "Red", false)
SELECT *
FROM c
WHERE CONTAINS(c.country, "States", false)
完全扫描
在某些情况下,查询引擎可能无法使用索引评估查询筛选器。 在这种情况下,为了评估查询筛选器,查询引擎需要从事务存储中加载所有的项。 完全扫描不使用索引,而且其 RU 费用根据总数据大小呈线性增加。 幸运的是,很少有需要完全扫描的操作。
没有定义的矢量索引的矢量搜索查询
如果你未定义矢量索引策略并在 ORDER BY 子句中使用 VectorDistance 系统函数,则这将导致完全扫描,并且具有比定义矢量索引策略更高的 RU 费用。 类似地,如果你将 VectorDistance 与设置为 true 的暴力破解布尔值一起使用,并且没有为矢量路径定义的 flat 索引,则将发生完全扫描。
具有复杂筛选表达式的查询
在前面的示例中,我们只考虑到具有简单筛选表达式的查询(例如,只具有单个相等或范围筛选器的查询)。 实际上,大多数查询都具有更复杂的筛选表达式。
请考虑下列查询:
SELECT *
FROM company
WHERE company.headquarters.employees = 200 AND CONTAINS(company.headquarters.country, "United")
要执行此查询,查询引擎必须对 headquarters/employees 和 headquarters/country 分别执行索引查找和完全索引扫描。 查询引擎具有内部启发法,用于尽可能高效地评估查询筛选表达式。 在这种情况下,查询引擎通过首先执行索引查找来避免读取不必要的索引页。 例如,如果只有 50 个项与相等筛选器匹配,则查询引擎只需要在包含这 50 个项的索引页上评估 Contains。 无需对整个容器执行完全索引扫描。
标量聚合函数的索引使用率
具有聚合函数的查询必须以独占方式依赖索引才能使用它。
在某些情况下,索引会返回假正。 例如,在索引上评估 Contains 时,索引中的匹配项数可能超过查询结果数。 查询引擎会加载所有索引匹配项,评估已加载的项上的筛选器,并且只返回正确的结果。
对于大多数查询,加载假正索引匹配项不会对索引利用率产生任何显著影响。
例如,考虑以下查询:
SELECT *
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
Contains 系统函数可能返回一些假正匹配项,因此查询引擎需要验证每个已加载的项是否与筛选表达式匹配。 在此示例中,查询引擎可能只需要加载额外几项,因此对索引使用率和 RU 费用的影响微乎其微。
但是,具有聚合函数的查询必须以独占方式依赖索引才能使用它。 例如,考虑使用具有 Count 聚合的以下查询:
SELECT COUNT(1)
FROM company
WHERE CONTAINS(company.headquarters.country, "United")
与第一个示例类似,Contains 系统函数可能返回一些假正匹配项。 但与 SELECT * 查询不同,Count 查询无法通过评估已加载项上的筛选表达式来验证所有索引匹配项。 Count 查询必须以独占方式依赖索引,因此如果筛选表达式可能返回假正匹配项,查询引擎将采用完全扫描。
具有以下聚合函数的查询必须以独占方式依赖索引,因此评估某些系统函数需要采用完全扫描。
后续步骤
阅读以下文章中有关索引的详细信息: