你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure Cosmos DB 中的分层分区键
适用范围:![]() NoSQL
NoSQL
Azure Cosmos DB 根据分区键跨逻辑分区和物理分区分布数据,来支持横向缩放。 通过使用分层分区键(也称为“子分区”),你可以为分区键配置多达三级的层次结构,从而进一步优化数据分布并实现更高级别的扩展。
如果目前使用合成键,则分区键可以超过 20 GB 数据,或者如果希望确保每个租户的文档映射到其自己的逻辑分区,则子分区可以帮助。 如果使用此功能,逻辑分区键前缀可超过 20 GB 和每秒 10,000 个请求单位 (RU/s)。 按前缀划分的查询可有效地路由到保存数据的分区子集。
选择分层分区键
如果有多租户应用程序,并且当前按分区键隔离租户,分层分区可能会使你受益。 分层分区允许缩放超过 20 GB 的逻辑分区键限制,如果你希望确保每个租户的文档可以无限缩放,这是一个很好的解决方案。 如果当前分区键或单个分区键频繁达到 20 GB,那么分层分区是工作负载的极佳选择。
但是,根据工作负荷的性质以及第一级键的基数情况,我们可以在分层分区方案页中深入介绍一些权衡。
选择分层分区键的每个级别时,请务必记住以下常规分区概念,并了解每个分区概念如何影响工作负荷:
对于所有容器,分层分区键的完整路径的每个级别(从第一级开始)应该:
具有较高的基数。 分层分区的第一个键、第二个键和第三个键(若适用)都应具有大范围的可能值。
- 在分层分区键的第一级具有低基数时,会将引入时的所有写入操作限制为仅一个物理分区,直到达到 50 GB,并拆分为两个物理分区。 例如,假设第一个级别密钥位于
TenantId,并且只有 5 个唯一租户。 这些租户的每个操作将限定为一个物理分区,将吞吐量消耗限制为该物理分区上的内容。 这是因为分层分区针对在同一物理分区上并置且具有相同一级键的所有文档进行了优化,以避免完全扇出查询。 - 虽然对于一次性引入所有租户数据的工作负荷而言,这也许没问题,但之后以下操作主要是读取密集型操作,但对于业务要求在特定时间内引入数据的工作负荷来说,这可能并不理想。 例如,如果你有严格的避免延迟的业务要求,则工作负荷理论上可以达到的引入数据的最大吞吐量是物理分区数 * 10k。 如果顶级键的基数较低,则物理分区数可能为 1,除非有足够的数据让第 1 级键在拆分后分散在多个分区中,这可能需要 4-6 小时才能完成。
- 在分层分区键的第一级具有低基数时,会将引入时的所有写入操作限制为仅一个物理分区,直到达到 50 GB,并拆分为两个物理分区。 例如,假设第一个级别密钥位于
将请求单位 (RU) 消耗和数据存储均匀分配到所有逻辑分区上。 这样的分散方式可确保跨物理分区均匀分配 RU 消耗和存储。
- 如果选择一个似乎具有高基数(如
UserId)的第一级键,但实际上,工作负荷只对一个特定的UserId执行操作,则很可能遇到热分区,因为所有操作将只限定为一个或几个物理分区。
- 如果选择一个似乎具有高基数(如
读取密集型工作负荷:建议选择在查询中频繁出现的分层分区键。
- 例如,如果工作负载在多租户应用程序中频繁运行查询来筛选出特定用户会话,那么该工作负载可从分层分区键
TenantId、UserId和SessionId(遵循此顺序)中受益。 通过在筛选器谓词中包含分区键,查询可以高效地专门路由到相关的物理分区。 若要详细了解如何为读取密集型工作负载选择分区键,请参阅分区概述。
- 例如,如果工作负载在多租户应用程序中频繁运行查询来筛选出特定用户会话,那么该工作负载可从分层分区键
写入密集型工作负荷:我们建议对分层分区键的一级使用高基数值。 高基数意味着第一级键(以及后续级别)至少有数千个唯一值和比物理分区数更多的唯一值。
例如,假设我们有一个工作负荷,它按分区键隔离租户,并且有几个大型租户比其他租户更写入密集型。 目前,如果数据超过 20 GB,Azure Cosmos DB 将停止在任何分区键值上引入数据。 在此工作负荷中,Microsoft 和 Contoso 是大型租户,我们预计其增长速度远高于其他租户。 为了避免无法为这些租户引入数据的风险,分层分区键允许我们将这些租户扩展,超出 20 GB 的限制。 我们可以添加更多级别,例如 UserId 和 SessionId,以确保租户之间的可伸缩性更高。
为了确保工作负荷能够容纳具有相同一级密钥的所有文档的写入,请考虑将项 ID 用作第二级或第三级密钥。
如果你的第一个级别没有较高的基数,并且当前在分区键上达到 20 GB 的逻辑分区限制,我们建议使用合成分区键,而不是分层分区键。
示例用例
假设你有一个多租户场景,其中你在每个租户存储用户的事件信息。 事件信息可能显示事件发生情况,包括但不限于登录、点击流或付款事件。
在实际场景中,一些租户可能会变得很大,具有数千名用户,而许多其他租户会变得更小,只有几名用户。 按 /TenantId 进行分区可能会导致在单个逻辑分区上超出 Azure Cosmos DB 20 GB 存储限制。 如果按 /UserId 进行分区,则跨分区对租户进行所有查询。 这两种方法都有明显的缺点。
如果使用组合了 TenantId 和 UserId 的合成分区键,应用程序会更加复杂。 此外,针对租户的合成分区键查询仍将是跨分区的,除非所有用户都是已知并已事先指定的。
如果工作负荷具有大致相同的工作负荷模式的租户,分层分区键可能会有所帮助。 使用分层分区键,你可先按 TenantId 进行分区,然后按 UserId 进行分区。 如果需要使用 TenantId 和 UserId 的组合生成超过 20 GB 的分区,你甚至可进一步向下分区到另一个级别,例如 SessionId。 总体深度不能超过三个级别。 当物理分区超过 50 GB 的存储空间时,Azure Cosmos DB 会自动拆分物理分区,以便大约一半的数据在一个物理分区上,一半数据在另一个物理分区上。 实际上,子分区意味着单个 TenantId 可以超过 20 GB 的数据,并且 TenantId 数据可以跨越多个物理分区。
指定 TenantId 或指定 TenantId 和 UserId 的查询会有效地路由到包含相关数据的物理分区子集。 指定完整的或前缀子分区的分区键路径将有效地避免完全的扇出查询。 例如,如果容器有 1,000 个物理分区,但特定的 TenantId 值只在其中 5 个物理分区上,则查询会路由到数量更少的相关物理分区。
在层次结构中使用项 ID
如果容器的属性采用大范围的可能值,那么对于层次结构的最后一个级别,该属性可能是一个很好的分区键选择。 此类属性的一个可能示例是项 ID。 系统属性“项 ID”存在于容器中的每一项内。 如果将项 ID 添加为另一个级别,即保证可扩展到超出 20 GB 这一逻辑分区键限制。 对于第一级的键,或者对于第一级和第二级的键,可扩展到超出此限制。
例如,你可能有一个用于多租户工作负载的容器,该容器按 TenantId 和 UserId 进行分区。 如果 TenantId 和 UserId 的单个组合可能超过 20 GB,建议使用三个级别的键进行分区,其中第三级的键具有高基数。 这种情况的一个例子是,如果第三级的键是具有自然高基数的 GUID。 TenantId、UserId 和 GUID 的组合不太可能超过 20 GB,因此 TenantId 和 UserId 的组合可以有效地扩展到 20 GB 以上。
若要详细了解如何使用项 ID 作为分区键,请参阅分区概述。
开始使用
重要
仅在以下 SDK 版本中支持使用分层分区键的容器。 必须使用受支持的 SDK 才能创建具有分层分区键的新容器,以及对数据执行创建、读取、更新和删除 (CRUD) 或查询操作。 如果你想要使用的 SDK 或连接器目前不受支持,请在我们的社区论坛上提交请求。
查找每个受支持 SDK 的最新预览版:
| SDK | 支持的版本 | 包管理器链接 |
|---|---|---|
| .NET SDK v3 | >= 3.33.0 | https://www.nuget.org/packages/Microsoft.Azure.Cosmos/3.33.0/ |
| Java SDK v4 | >= 4.42.0 | https://github.com/Azure/azure-sdk-for-java/blob/main/sdk/cosmos/azure-cosmos/CHANGELOG.md#4420-2023-03-17/ |
| JavaScript SDK v4 | 4.0.0 | https://www.npmjs.com/package/@azure/cosmos/ |
| Python SDK | >= 4.6.0 | https://pypi.org/project/azure-cosmos/4.6.0/ |
使用分层分区键创建容器
若要开始,请使用包含最多三个深度级别的子分区键路径的预定义列表创建新容器。
可使用以下选项之一创建新容器:
- Azure 门户
- SDK
- Azure Resource Manager 模板
- Azure Cosmos DB 模拟器
Azure 门户
要创建容器和指定分层分区键,最简单的方法是使用 Azure 门户。
登录 Azure 门户。
转到现有的 Azure Cosmos DB for NoSQL 帐户页。
在左侧菜单中,选择“数据资源管理器”。
在“数据资源管理器”上,选择“新建容器”选项。
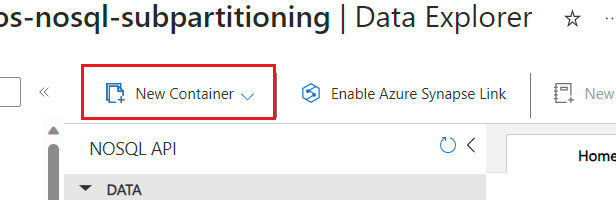
在“新建容器”中,对于“分区键”,输入
/TenantId。 对于其余字段,输入与你的场景匹配的任何值。注意
我们在这里以
/TenantId为例。 在你自己的容器上实现分层分区键时,可为第一个级别指定任何键。选择“添加分层分区键”两次。
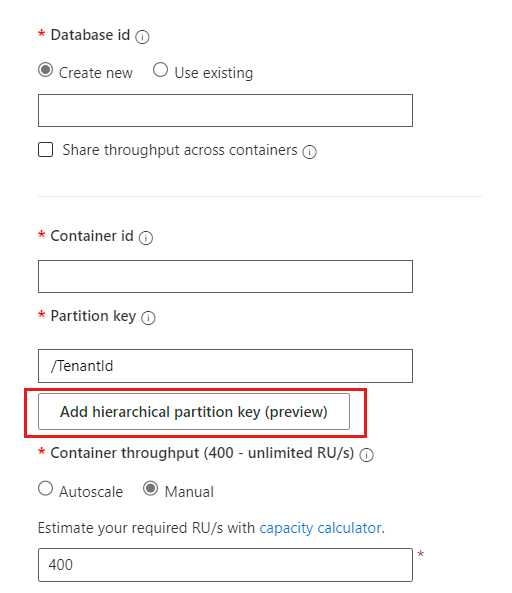
对于子分区的第二层和第三层,请分别输入
/UserId和/SessionId。
选择“确定” 创建容器。




SDK
使用 SDK 创建新容器时,请定义最多三个深度级别的子分区键路径的列表。 配置新容器的属性时,请使用子分区键的列表。
// List of partition keys, in hierarchical order. You can have up to three levels of keys.
List<string> subpartitionKeyPaths = new List<string> {
"/TenantId",
"/UserId",
"/SessionId"
};
// Create a container properties object
ContainerProperties containerProperties = new ContainerProperties(
id: "<container-name>",
partitionKeyPaths: subpartitionKeyPaths
);
// Create a container that's subpartitioned by TenantId > UserId > SessionId
Container container = await database.CreateContainerIfNotExistsAsync(containerProperties, throughput: 400);
Azure 资源管理器模板
用于子分区容器的 Azure 资源管理器模板与标准容器大致相同。 唯一的关键区别是 properties/partitionKey 路径的值。 有关为 Azure Cosmos DB 资源创建 Azure 资源管理器模板的详细信息,请参阅用于 Azure Cosmos DB 的 Azure 资源管理器模板参考。
使用下表中的值配置 partitionKey 对象,以创建子分区容器:
| 路径 | 值 |
|---|---|
paths |
分层分区键(深度最多为三个级别)的列表 |
kind |
MultiHash |
version |
2 |
示例分区键定义
例如,假设你有一个分层分区键,它由 TenantId>UserId>SessionId 构成。 partitionKey 对象会配置为包含 paths 属性中的全部三个值、一个 kind 值 MultiHash 和一个 version 值 2。
partitionKey: {
paths: [
'/TenantId'
'/UserId'
'/SessionId'
]
kind: 'MultiHash'
version: 2
}
有关 partitionKey 对象的详细信息,请参阅 ContainerPartitionKey 规范。
Azure Cosmos DB 模拟器
可以使用最新版本的 Azure Cosmos DB 本地模拟器测试子分区功能。 若要在模拟器上启用子分区,请使用 /EnablePreview 标志从安装目录启动模拟器:
.\CosmosDB.Emulator.exe /EnablePreview
警告
仿真器目前不支持所有分层分区键功能作为门户。 仿真器当前不支持:
- 使用数据资源管理器创建具有分层分区键的容器
- 使用数据资源管理器导航到使用分层分区键的项并与之交互
有关详细信息,请参阅 Azure Cosmos DB 模拟器。
通过 SDK 使用具有分层分区键的容器
创建具有分层分区键的容器后,请使用前面指定的 .NET 或 Java SDK 版本在该容器上执行操作和查询。
向容器添加项
有两个选项可用于向启用了分层分区键的容器添加新项:
- 自动提取
- 手动指定路径
自动提取
如果在设置了分区键值的情况下传入对象,SDK 可以自动提取完整的分区键路径。
// Create a new item
UserSession item = new UserSession()
{
id = "f7da01b0-090b-41d2-8416-dacae09fbb4a",
TenantId = "Microsoft",
UserId = "00aa00aa-bb11-cc22-dd33-44ee44ee44ee",
SessionId = "0000-11-0000-1111"
};
// Pass in the object, and the SDK automatically extracts the full partition key path
ItemResponse<UserSession> createResponse = await container.CreateItemAsync(item);
手动指定路径
SDK 中的 PartitionKeyBuilder 类可以为以前定义的分层分区键路径构造值。 在将新项添加到启用了子分区的容器时,请使用此类。
提示
在规模很大的情况下,如果指定完整的分区键路径,性能可能会得到提升,即使 SDK 可以从对象中提取路径也是如此。
// Create a new item object
PaymentEvent item = new PaymentEvent()
{
id = Guid.NewGuid().ToString(),
TenantId = "Microsoft",
UserId = "00aa00aa-bb11-cc22-dd33-44ee44ee44ee",
SessionId = "0000-11-0000-1111"
};
// Specify the full partition key path when creating the item
PartitionKey partitionKey = new PartitionKeyBuilder()
.Add(item.TenantId)
.Add(item.UserId)
.Add(item.SessionId)
.Build();
// Create the item in the container
ItemResponse<PaymentEvent> createResponse = await container.CreateItemAsync(item, partitionKey);
执行项目的键/值查找(点读取)
键/值查找(点读取)的执行方式类似于非子分区容器。 例如,假设你有一个分层分区键,它由 TenantId>UserId>SessionId 组成。 项的唯一标识符是 GUID。 它表示为字符串,用作唯一文档事务标识符。 若要对单个项执行点读取,请传入该项的 id 属性和分区键的完整值(包括路径的全部三个组成部分)。
// Store the unique identifier
string id = "f7da01b0-090b-41d2-8416-dacae09fbb4a";
// Build the full partition key path
PartitionKey partitionKey = new PartitionKeyBuilder()
.Add("Microsoft") //TenantId
.Add("00aa00aa-bb11-cc22-dd33-44ee44ee44ee") //UserId
.Add("0000-11-0000-1111") //SessionId
.Build();
// Perform a point read
ItemResponse<UserSession> readResponse = await container.ReadItemAsync<UserSession>(
id,
partitionKey
);
运行查询
用于在子分区容器上运行查询的 SDK 代码与在非子分区容器上运行查询相同。
当查询在 WHERE 筛选器中或键层次结构的前缀中指定分区键的所有值时,SDK 会自动将该查询路由到相应的物理分区。 仅提供层次结构“中间部分”的查询是跨分区查询。
例如,请考虑一个由 TenantId>UserId>SessionId 构成的分层分区键。 查询筛选器的组成部分可确定查询是单分区查询、定向跨分区查询还是扇出查询。
| 查询 | 路由 |
|---|---|
SELECT * FROM c WHERE c.TenantId = 'Microsoft' AND c.UserId = '00aa00aa-bb11-cc22-dd33-44ee44ee44ee' AND c.SessionId = '0000-11-0000-1111' |
路由到包含指定值 TenantId、UserId 和 SessionId 的数据的单个逻辑和物理分区。 |
SELECT * FROM c WHERE c.TenantId = 'Microsoft' AND c.UserId = '00aa00aa-bb11-cc22-dd33-44ee44ee44ee' |
仅路由到包含指定值 TenantId 和 UserId 的数据的逻辑和物理分区目标子集。 此查询是一个定向跨分区查询,它返回一个租户中特定用户的数据。 |
SELECT * FROM c WHERE c.TenantId = 'Microsoft' |
仅路由到包含指定值 TenantId 的数据的逻辑和物理分区目标子集。 此查询是一个定向跨分区查询,它返回一个租户中所有用户的数据。 |
SELECT * FROM c WHERE c.UserId = '00aa00aa-bb11-cc22-dd33-44ee44ee44ee' |
路由到所有物理分区,从而导致一个扇出跨分区查询。 |
SELECT * FROM c WHERE c.SessionId = '0000-11-0000-1111' |
路由到所有物理分区,从而导致一个扇出跨分区查询。 |
子分区容器上的单分区查询
以下示例运行一个查询,该查询包含所有子分区级别,从而有效地使该查询变成了单分区查询。
// Define a single-partition query that specifies the full partition key path
QueryDefinition query = new QueryDefinition(
"SELECT * FROM c WHERE c.TenantId = @tenant-id AND c.UserId = @user-id AND c.SessionId = @session-id")
.WithParameter("@tenant-id", "Microsoft")
.WithParameter("@user-id", "00aa00aa-bb11-cc22-dd33-44ee44ee44ee")
.WithParameter("@session-id", "0000-11-0000-1111");
// Retrieve an iterator for the result set
using FeedIterator<PaymentEvent> results = container.GetItemQueryIterator<PaymentEvent>(query);
while (results.HasMoreResults)
{
FeedResponse<UserSession> resultsPage = await resultSet.ReadNextAsync();
foreach(UserSession result in resultsPage)
{
// Process result
}
}
子分区容器上的定向多分区查询
以下示例查询包含一部分子分区级别,从而有效地使该查询变成了目标多分区查询。
// Define a targeted cross-partition query specifying prefix path[s]
QueryDefinition query = new QueryDefinition(
"SELECT * FROM c WHERE c.TenantId = @tenant-id")
.WithParameter("@tenant-id", "Microsoft")
// Retrieve an iterator for the result set
using FeedIterator<PaymentEvent> results = container.GetItemQueryIterator<PaymentEvent>(query);
while (results.HasMoreResults)
{
FeedResponse<UserSession> resultsPage = await resultSet.ReadNextAsync();
foreach(UserSession result in resultsPage)
{
// Process result
}
}
限制和已知问题
- 只有 .NET v3 SDK、Java v4 SDK、Python SDK 和 JavaScript SDK 预览版支持使用具有分层分区键的容器。 必须使用受支持的 SDK 才能创建具有分层分区键的新容器以及对数据执行 CRUD 或查询操作。 目前不支持其他 SDK(包括 Python)。
- 各种 Azure Cosmos DB 连接器(例如 Azure 数据工厂)存在限制。
- 只能指定深度不超过三层的分层分区键。
- 目前只能在新容器上启用分层分区键。 必须在创建容器时设置分区键路径,以后不能更改它们。 若要对现有容器使用分层分区,请使用分层分区键集创建新容器,并使用容器复制作业移动数据。
- 分层分区键目前仅支持用于 API for NoSQL 帐户。 目前不支持 MongoDB 和 Cassandra 的 API。
- 用户和权限功能目前不支持分层分区键。 你无法向分层分区键路径的部分前缀分配权限。 权限只能分配给整个逻辑分区键路径。 例如,如果已按
TenantId- >UserId进行分区,你将无法分配对应于某个TenantId特定值的权限。 但是,如果同时为TenantId和“UserId”指定了值,则可以为分区键分配权限。
后续步骤
- 请参阅有关分层分区键的常见问题解答。
- 详细了解 Azure Cosmos DB 中的分区。
- 详细了解如何将 Azure 资源管理器模板与 Azure Cosmos DB 配合使用。