你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure Monitor 为 Azure Cosmos DB 创建警报
适用对象:![]() NoSQL
NoSQL![]() MongoDB
MongoDB![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() 表
表
警报用于设置重复测试,以监视 Azure Cosmos DB 资源的可用性和响应能力。 当指标之一达到阈值时或活动日志中记录了特定事件时,警报可以通过电子邮件向你发送通知,或执行某个 Azure 函数。
可以根据 Azure Cosmos DB 帐户上的指标、活动日志事件或 Log Analytics 日志接收警报:
指标 - 当指定指标的值超出分配的阈值时,会触发警报。 例如,当所使用的请求单位总数超出 1000 RU/秒时,会触发警报。 首次满足条件时,以及之后不再满足条件时,都会触发此警报。 有关 Azure Cosmos DB 中可用的各种指标,请参阅监视数据参考一文。
活动日志事件 - 在出现特定事件时触发此警报。 例如,当 Azure Cosmos DB 帐户的密钥被访问或刷新时触发此警报。
Log Analytics - 当 Log Analytics 查询结果中指定属性的值超过分配的阈值时,将触发此警报。 例如,你可以编写 Log Analytics 查询来监视逻辑分区键的存储是否达到 Azure Cosmos DB 中的 20 GB 逻辑分区键存储限制。
可以通过 Azure 门户中的“Azure Cosmos DB”窗格或 Azure Monitor 服务设置警报。 这两个界面提供相同的选项。 本文介绍了如何使用 Azure Monitor 为 Azure Cosmos DB 设置警报。
创建警报规则
本部分展示了如何创建一个在你收到 HTTP 状态代码 429 时会发出的警报。当请求存在速率限制时,用户会收到该警报。 例如,你可能想要在有 100 个或更多个速率受限请求时收到警报。 本文介绍了如何使用 HTTP 状态代码为此类场景配置警报。 你还可以使用类似的步骤来配置其他类型的警报,只需根据要求选择其他条件即可。
提示
此处使用基于超过阈值的出现 429 的数量的警报方案进行说明。 这并不意味着在数据库或容器上看到 429 时存在任何本质上的错误。 一般情况下,如果生产工作负荷中 1-5% 的请求出现 429,并且应用程序的总体延迟在要求范围内,则这是一个正常的符号,表示你完全使用预配的吞吐量 (RU/s)。 详细了解如何解释和调试 429 异常。
登录到 Azure 门户。
在左侧导航栏中选择“监视”,然后选择“警报”。
选择“新建警报规则”按钮以打开“创建警报规则”窗格。
填充“作用域”部分:
打开“选择资源”窗格,配置以下内容:
选择订阅名称。
选择“Azure Cosmos DB 帐户”作为“资源类型”。
选择 Azure Cosmos DB 帐户的“位置”。
填写详细信息后,会显示所选范围中的 Azure Cosmos DB 帐户的列表。 选择要为其配置警报的帐户,然后选择“完成”。
填充“条件”部分:
打开“选择条件”窗格,以便打开“选择信号”页并配置以下内容:
选择一个信号。 信号类型可以是指标、活动日志或 Log (Log Analytics)。 在此方案中选择“指标”,因为当请求单位总数指标发生速率限制时,需要获取警报。
对于“Azure Monitor 服务”,请选择“全部”
选择一个信号名称。 若要获取 HTTP 状态代码的警报,请选择“请求单位总数”信号。
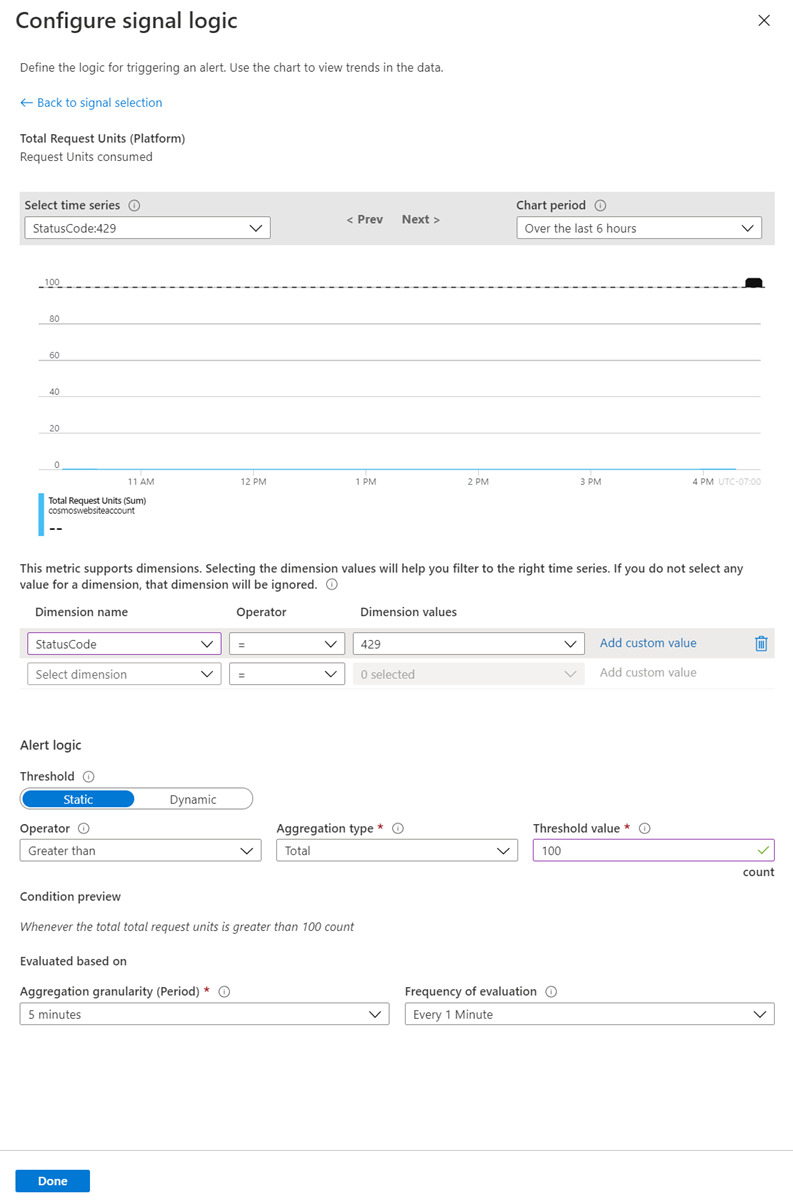
现在你可以定义警报触发逻辑,并使用图表查看 Azure Cosmos DB 帐户的趋势。 “请求单位总数”指标支持维度。 可以按这些维度对指标进行筛选。 例如,可以使用维度来筛选到要监视的特定数据库或容器。 如果你未选择任何维度,系统会忽略此值。
选择“StatusCode”作为维度名称。 选择“添加自定义值”,将状态代码设置为 429。
在“警报逻辑”中,将“阈值”设置为“静态”。 静态阈值使用用户定义的阈值来评估规则,而动态阈值则使用内置的机器学习算法来持续学习指标行为模式并自动计算阈值。
将“运算符”设置为“大于”,将“聚合类型”设置为“总计”,将“阈值”设置为“100”。 使用此逻辑时,如果客户端发现状态代码为 429 的请求超过 100 个,则会触发警报。 你还可以根据自己的需求配置聚合类型、聚合粒度和评估频率。
填充此窗体后,选择“完成”。 以下屏幕截图显示了警报逻辑的详细信息:
填充“操作组”部分:
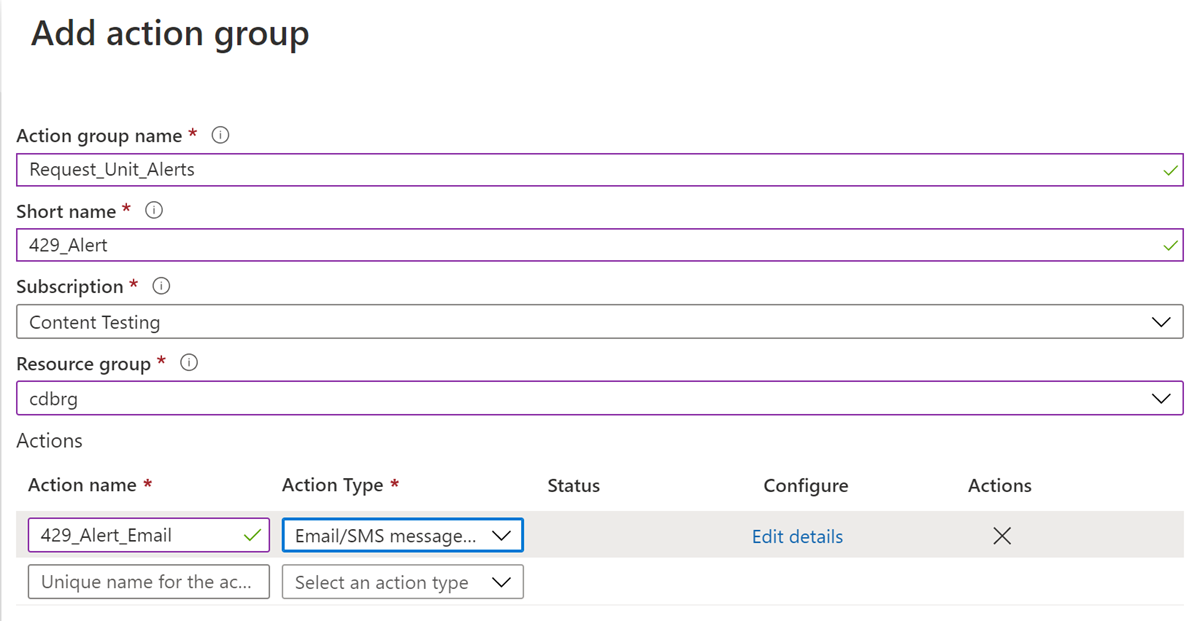
在“创建规则”窗格中,选择一个现有的“操作组”或创建一个新的操作组。 操作组用于定义在发生警报条件时要执行的操作。 在此示例中,请创建一个新的操作组,用于在触发警报时接收电子邮件通知。 打开“添加操作组”窗格,填充以下详细信息:
操作组名称 - 操作组名称在资源组中必须独一无二。
短名称 - 操作组的短名称。此值包含在电子邮件和短信通知中,用于标识哪个操作组是通知来源。
选择要在其中创建此操作组的订阅和资源组。
为操作提供一个名称,并选择“电子邮件/短信/推送/语音”作为“操作类型”。 以下屏幕截图显示了操作类型的详细信息:
填充“警报规则详细信息”部分:
- 定义规则的名称,提供可选说明和警报的严重性级别,选择是否在创建规则后启用规则,然后选择“创建规则警报”以创建指标规则警报。
创建警报后,它会在 10 分钟内激活。
常见警报场景
下面是一些可以使用警报的场景:
- 当更新了 Azure Cosmos DB 帐户的密钥时。
- 当某个容器、数据库或区域所使用的数据或索引超过特定数目的字节时。
- 当逻辑分区键的存储达到 Azure Cosmos DB 20 GB 逻辑分区存储限制时。
- 当规范化 RU/秒消耗量大于特定百分比时。 规范化 RU 消耗指标提供副本集内的最大吞吐量使用率。 若要了解相关信息,请参阅如何监视规范化 RU/秒。
- 当添加、删除了某个区域或该区域进入脱机状态时。
- 当创建、删除或更新了数据库或容器时。
- 当数据库或容器的吞吐量发生变化时。
后续步骤
- 如何在 Azure Cosmos DB 容器中监视规范化 RU/秒指标。
- 如何监视 Azure Cosmos DB 中的操作的吞吐量或请求单位用量。