你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
弹性缩放 Azure Cosmos DB for Apache Cassandra 帐户
适用对象:![]() Cassandra
Cassandra
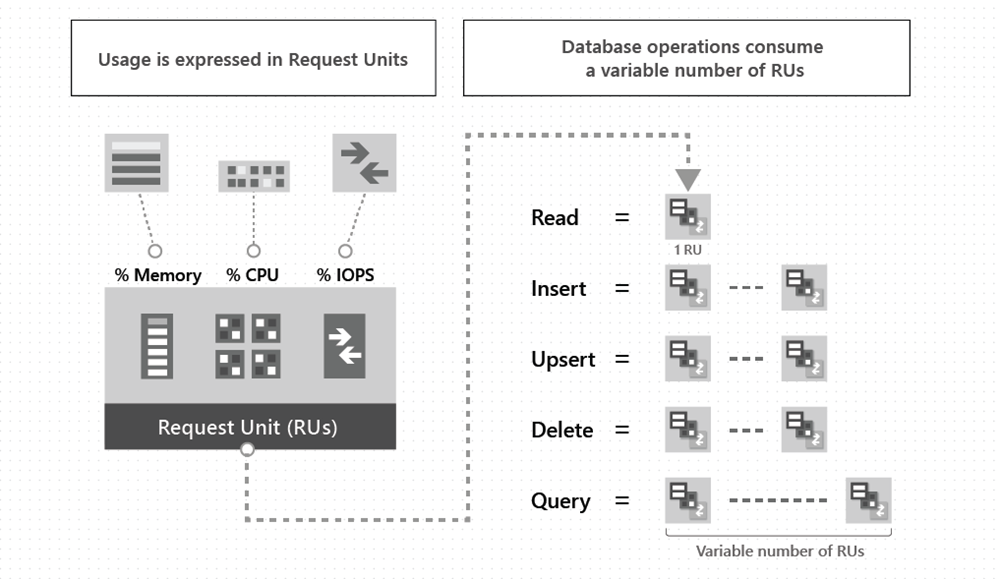
有多种选项可用于探索Azure Cosmos DB for Apache Cassandra 的弹性特性。 若要了解如何在 Azure Cosmos DB 中有效地进行缩放,必须了解如何预配合适数量的请求单位(RU/秒),以考虑系统的性能需求。 若要了解请求单位的详细信息,请参阅请求单位一文。
对于 Cassandra API,可以使用 .NET 和 Java SDK 检索各个查询的请求单位费用。 这有助于确定你在服务中需要预配的 RU 数/秒。
处理速率限制(429 错误)
如果客户端消耗的资源(RU/秒)超过了预配的量,Azure Cosmos DB 将返回速率限制 (429) 错误。 Azure Cosmos DB 中的 API for Cassandra 在 Cassandra 本机协议中将这些异常解释为过载错误。
如果系统对延迟不敏感,使用重试可能就足以应对吞吐量速率限制。 查看 Apache Cassandra Java 驱动程序的版本 3 和版本 4 的 Java 代码示例,了解如何以透明方式处理速率限制。 这些示例在 Java 中实现默认 Cassandra 重试策略的自定义版本。 还可以使用 Spark 扩展来处理速率限制。 使用 Spark 时,请确保遵循有关优化 Spark 连接器吞吐量配置的指南。
管理缩放
如果需要最大程度地减少延迟,可以使用一系列选项来管理 Cassandra API 中的缩放和预配吞吐量 (RU):
下面的几节介绍了这些方法的优缺点。 然后,可以确定最佳的策略,以便在系统的缩放需求、整体成本以及解决方案的效率需求之间做出平衡。
使用 Azure 门户
可以通过 Azure 门户对 Azure Cosmos DB for Apache Cassandra 帐户中的资源进行缩放。 有关详细信息,请参阅有关对容器和数据库预配吞吐量的文章。 此文解释了通过 Azure 门户在数据库或容器级别设置吞吐量的相对优势。 这些文章中提到的术语“数据库”和“容器”分别对应于 Cassandra API 的“密钥空间”和“表”。
此方法的优点是能够以直截了当的统包方式管理数据库的吞吐量。 但缺点是,在许多情况下,缩放方法可能要求实现某些程度的自动化,它既要确保经济高效,同时又要具备高性能。 后续部分将介绍相关的方案和方法。
使用控制平面
用于 Cassandra 的 Azure Cosmos DB API 提供使用各种控制平面功能以编程方式调整吞吐量的功能。 有关指导和示例,请参阅 Azure 资源管理器、PowerShell 和 Azure CLI 文章。
此方法的优点是可以根据计时器自动扩展或缩减资源,以反映活动的高峰或低活动期。 请参阅此处的示例,了解如何使用 Azure Functions 和 PowerShell 实现此目的。
此方法的一个缺点是,你无法实时响应不可预知的规模需求变化。 相反,你可能需要在客户端/SDK 级别利用系统中的应用程序上下文,或使用自动缩放。
将 CQL 查询与特定的 SDK 配合使用
可以针对给定的数据库或容器执行 CQL ALTER 命令,通过代码动态缩放系统。
此方法的优点在于,能够以适合应用程序的自定义方式动态应对缩放需求。 使用此方法,仍可利用标准 RU/秒的费用和速率。 如果系统的缩放需求大部分是可预测的(大约 70% 或更多),那么将 SDK 与 CQL 配合使用可能是一种比使用自动缩放更为经济高效的自动缩放方法。 此方法的缺点是,实现重试可能会很复杂,同时,速率限制可能会增大延迟。
使用自动缩放预配吞吐量
除了标准(手动)或以编程方式预配吞吐量外,还可以在自动缩放预配的吞吐量中配置 Azure Cosmos DB 容器。 自动缩放会自动立即缩放,以满足指定 RU 范围内的消耗需求,而不会影响 SLA。 若要了解详细信息,请参阅在自动缩放中创建 Azure Cosmos DB 容器和数据库一文。
此方法的优点是,它是在系统中管理缩放需求的最简单的方法。 它不会在已配置的 RU 范围内应用速率限制。 缺点是,如果系统中的缩放需求是可预测的,那么相比使用上面提到的定制控制平面或 SDK 级别方法,自动缩放在处理缩放需求方面可能并没有那么经济高效。
若要设置或更改使用 CQL 的自动缩放的最大吞吐量 (RU),请使用以下内容(相应地替换密钥空间/表名称):
# to set max throughput (RUs) for autoscale at keyspace level:
create keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at keyspace level:
alter keyspace <keyspace name> WITH cosmosdb_autoscale_max_throughput=4000;
# to set max throughput (RUs) for autoscale at table level:
create table <keyspace name>.<table name> (pk int PRIMARY KEY, ck int) WITH cosmosdb_autoscale_max_throughput=5000;
# to alter max throughput (RUs) for autoscale at table level:
alter table <keyspace name>.<table name> WITH cosmosdb_autoscale_max_throughput=4000;
后续步骤
- 入门:使用 Java 应用程序创建 API for Cassandra 帐户、数据库和表