如果选择不实现与数据无关的引擎以从操作源一次性引入数据,或者与数据无关的引擎中没有实现复杂连接,则应创建一个源对齐数据应用程序。 从外部数据源引入数据时,它应遵循与数据无关的引擎相同的流程。
概述
应用程序资源组负责只从外部源(例如遥测、财务或 CRM)引入和扩充数据。 此层可以在实时、批处理和微批处理模式下操作。
本部分介绍为数据登陆区域内每个数据应用程序(源对齐)资源组部署的基础结构。
提示
对于数据网格,可以选择为每个源或每个域部署其中一个。 数据标准化、数据质量和数据世系的原则仍必须遵循。 数据平台运营团队可以开发标准代码片段,并调用它们来实现此目的。
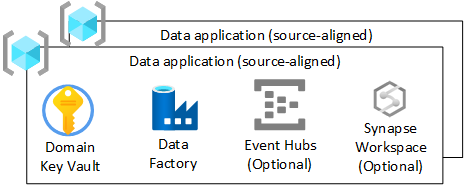
对于数据登陆区域中的每个数据应用程序(源对齐)资源组,我们应该创建:
- 一个 Azure Key Vault
- 一个 Azure 数据工厂,用于运行已开发的工程管道,以便将数据从原始状态转换为扩充状态
- 一个服务主体,供数据应用程序(源对齐)用于将引入作业部署到 Azure Databricks(仅当使用 Azure Databricks 时)
也可创建其他服务(例如 Azure 事件中心、Azure IoT 中心、Azure 流分析和 Azure 机器学习)的实例。
注意
需要使用 Spark 引擎(如 Azure Synapse Spark 或 Azure Databricks)来强制实施 Delta Lake 标准。
如果决定使用 Azure Databricks,建议部署 Azure 数据工厂而不是 Azure Synapse Analytics 工作区,以将外围应用减少至仅剩所需功能的程度。
但是,如果需要一个包含管道和 Spark 的全方位开发领域,请使用 Azure Synapse Analytics。 应用策略以仅允许使用 Spark 和管道,以避免在 Azure Synapse SQL 池中创建孤岛。
Azure Key Vault
尽可能使用 Azure Key Vault 功能将机密存储在 Azure 中。
每个数据应用程序(源对齐)资源组或数据域(如果使用网格)都会有一个 Azure Key Vault。 这确保加密密钥、机密和证书派生符合环境的要求。 这可以更好地分离管理职责,并降低混合密钥、集成以及不同分类的机密的风险。
与数据应用程序(源对齐)相关的所有密钥都应包含在 Azure Key Vault 中。
重要
数据应用程序(源对齐)密钥保管库应遵循最低特权模型,并应避免事务规模限制和跨环境进行机密共享。
Azure 数据工厂
部署 Azure 数据工厂,以便数据应用程序团队编写的管道获取已使用开发的管道从原始状态转换为扩充状态的数据。 使用映射数据流进行转换,然后中断,以使用 Azure Databricks(引入)工作区或 Azure Synapse Spark 进行复杂转换。
应将 Azure 数据工厂连接到数据应用程序(源对齐)存储库的 DevOps 实例。 此连接允许 CI/CD 部署。
事件中心
如果数据应用程序(源对齐)需要将数据流式传输进来,则可以在数据应用程序(源对齐)资源组中部署下游事件中心。