本文解释了对于规划或管理安全 Azure 机器学习部署的安全最佳做法。 最佳做法来自 Microsoft 和客户在 Azure 机器学习方面的体验。 每个准则都解释了这种做法及其基本原理。 本文还提供了指向操作说明和参考文档的链接。
建议的网络安全体系结构(托管网络)
建议的机器学习网络安全体系结构是托管 虚拟网络。 Azure 机器学习托管虚拟网络保护工作区、关联的 Azure 资源和所有托管计算资源。 它通过预先配置所需的输出并在网络中自动创建托管资源,简化了网络安全的配置和管理。 可以使用专用终结点允许 Azure 服务访问网络,还可以选择定义出站规则以允许网络访问 Internet。
托管虚拟网络有两种可配置模式:
允许 Internet 出站 - 此模式允许与位于 Internet 上的资源的出站通信,例如公共 PyPi 或 Anaconda 包存储库。

仅允许批准的出站 - 此模式仅允许工作区正常运行所需的最小出站通信。 对于必须与 Internet 隔离的工作区,建议使用此模式。 或者,仅允许通过服务终结点、服务标记或完全限定的域名对特定资源进行出站访问。

有关详细信息,请参阅 托管虚拟网络隔离。
建议的网络安全体系结构(Azure 虚拟网络)
如果由于业务要求而无法使用托管虚拟网络,则可以使用以下子网的 Azure 虚拟网络:
- “训练”包含用于训练的计算资源,例如机器学习计算实例或计算群集。
- “评分”包含用于评分的计算资源,例如 Azure Kubernetes 服务 (AKS)。
- “防火墙”包含允许进出公共 Internet 的流量的防火墙,如 Azure 防火墙。
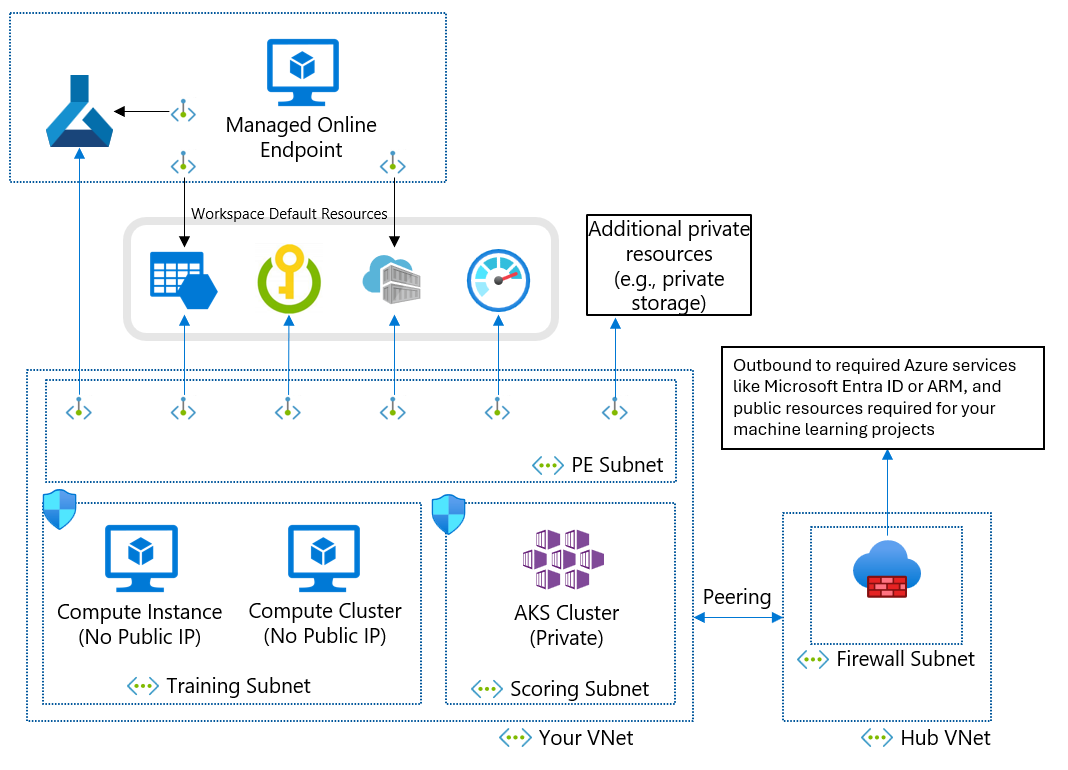
虚拟网络还包含 机器学习工作区和以下依赖服务的专用终结点 :
- Azure 存储帐户
- Azure Key Vault
- Azure 容器注册表
来自虚拟网络的出站通信必须能够访问以下 Microsoft 服务:
- 机器学习
- Microsoft Entra ID
- Azure 容器注册表,以及 Microsoft 维护的特定注册表
- Azure Front Door
- Azure Resource Manager
- Azure 存储
远程客户端使用 Azure ExpressRoute 或虚拟专用网络 (VPN) 连接连接到虚拟网络。
虚拟网络和专用终结点设计
设计 Azure 虚拟网络、子网和专用终结点时,请考虑以下要求:
一般情况下,为训练和评分创建单独的子网,并将训练子网用于所有专用终结点。
对于 IP 寻址,每个计算实例都需要一个专用 IP。 计算群集每个节点需要一个专用 IP。 AKS 群集需要许多专用 IP 地址,如规划 AKS 群集的 IP 寻址中所述。 至少 AKS 的单独子网有助于防止 IP 地址耗尽。
训练和评分子网中的计算资源必须访问存储帐户、密钥保管库和容器注册表。 为存储帐户、密钥保管库和容器注册表创建专用终结点。
机器学习工作区默认存储需要两个专用终结点,一个终结点用于 Azure Blob 存储,另一个终结点用于 Azure 文件存储存储。
如果使用Azure 机器学习工作室,工作区和存储专用终结点应位于同一虚拟网络中。
如果你有多个工作区,请对每个工作区使用一个虚拟网络,以在工作区之间创建一个显式网络边界。
使用专用 IP 地址
专用 IP 地址可最大程度地减少 Azure 资源对 Internet 的暴露。 机器学习使用许多 Azure 资源,而机器学习工作区专用终结点对于端到端专用 IP 来说是不够的。 下表显示了机器学习使用的主要资源以及如何为资源启用专用 IP。 计算实例和计算群集是唯一没有专用 IP 功能的资源。
| 资源 | 专用 IP 解决方案 | 文档 |
|---|---|---|
| 工作区 | 专用终结点 | 为 Azure 机器学习工作区配置专用终结点 |
| 注册表 | 专用终结点 | 使用 Azure 机器学习注册表进行网络隔离 |
| 关联资源 | ||
| 存储 | 专用终结点 | 使用服务终结点保护 Azure 存储帐户 |
| 密钥保管库 | 专用终结点 | 保护 Azure 密钥库 |
| 容器注册表 | 专用终结点 | 启用 Azure 容器注册表 |
| 培训资源 | ||
| 计算实例 | 专用 IP (无公共 IP) | 保护训练环境 |
| 计算群集 | 专用 IP (无公共 IP) | 保护训练环境 |
| 托管资源 | ||
| 托管联机终结点 | 专用终结点 | 通过托管联机终结点进行的网络隔离 |
| 联机终结点 (Kubernetes) | 专用终结点 | 保护联机终结点Azure Kubernetes 服务 |
| Batch 终结点 | 专用 IP(继承自计算群集) | 批处理终结点中的网络隔离 |
控制虚拟网络入站和出站流量
使用防火墙或 Azure 网络安全组 (NSG) 来控制虚拟网络入站和出站流量。 有关入站和出站要求的详细信息,请参阅配置入站和出站网络流量。 有关组件之间的流量流的详细信息,请参阅 安全工作区中的网络流量流。
确保对工作区的访问权限
若要确保专用终结点可以访问机器学习工作区,请执行以下步骤:
确保可以使用 VPN 连接、ExpressRoute 或具有 Azure Bastion 访问权限的跳转盒虚拟机 (VM) 访问你的虚拟网络。 公共用户无法使用专用终结点访问机器学习工作区,因为只能从虚拟网络访问它。 有关详细信息,请参阅使用虚拟网络保护工作区。
请确保可以使用专用 IP 地址解析工作区完全限定的域名 (FQDN)。 如果你使用自己的域名系统 (DNS) 服务器或集中式 DNS 基础结构,则需要配置 DNS 转发器。 有关详细信息,请参阅如何将工作区与自定义 DNS 服务器结合使用。
工作区访问管理
定义机器学习标识和访问管理控件时,可将定义对 Azure 资源的访问权限的控件与管理对数据资产的访问权限的控件分开。 根据用例,考虑是使用自助式、以数据为中心还是以项目为中心的标识和访问管理。
自助式模式
在自助式模式中,数据科学家可以创建和管理工作区。 此模式最适合需要灵活尝试不同配置的概念证明情况。 缺点是数据科学家需要具备预配 Azure 资源的专业知识。 当需要严格控制、资源使用、审核跟踪和数据访问时,此方法不太合适。
定义 Azure 策略,为资源预配和使用设置护栏,例如允许的群集大小和 VM 类型。
创建用于保存工作区的资源组,并向数据科学家授予资源组中的“参与者”角色。
数据科学家现在可以采用自助方式创建工作区并关联资源组中的资源。
若要访问数据存储,请创建用户分配的托管标识,并在存储上授予标识读取访问角色。
数据科学家创建计算资源时,可以将托管标识分配给计算实例,以获得数据访问权限。
有关最佳做法,请参阅云规模分析的身份验证。
以数据为中心模式
在以数据为中心的模式中,工作区属于可能处理多个项目的单个数据科学家。 此方法的优点是数据科学家可跨项目重用代码或训练管道。 只要工作区仅限于单个用户,就可以在审核存储日志时将数据访问追溯到该用户。
缺点是,数据访问不会按项目进行隔离或限制,并且添加到工作区的任何用户都可以访问相同的资产。
创建工作区。
创建启用了系统分配的托管标识的计算资源。
当数据科学家需要访问给定项目的数据时,请授予计算托管标识对数据的读取访问权限。
向计算托管标识授予对其他所需资源的访问权限,例如使用自定义 Docker 映像的容器注册表进行训练。
此外,授予工作区对数据的托管标识读取访问权限角色,以启用数据预览。
授予数据科学家对工作区的访问权限。
数据科学家现在可以创建数据存储来访问项目所需的数据,并提交使用该数据的训练运行。
(可选)创建 Microsoft Entra 安全组并向其授予对数据的访问权限,然后将托管标识添加到安全组。 此方法减少了资源上的直接角色分配数,以避免达到角色分配的订阅限制。
以项目为中心模式
以项目为中心模式为特定项目创建机器学习工作区,许多数据科学家在同一工作区中协作。 数据访问仅限于特定项目,使该方法非常适合处理敏感数据。 此外,在项目中添加或删除数据科学家也很简单。
此方法的缺点是跨项目共享资产可能很困难。 在审核期间,也很难跟踪特定用户的数据访问。
创建工作区
标识项目所需的数据存储实例,创建用户分配的托管标识,并授予标识对存储的读取访问权限。
可以有选择地授予工作区的托管标识对数据存储的访问权限,以允许数据预览。 对于不适合预览的敏感数据,可以省略此访问权限。
为存储资源创建无凭据数据存储。
在工作区内创建计算资源,并将托管标识分配给计算资源。
向计算托管标识授予对其他所需资源的访问权限,例如使用自定义 Docker 映像的容器注册表进行训练。
为处理项目的数据科学家授予针对工作区的角色。
通过使用 Azure 基于角色的访问控制 (RBAC),可以限制数据科学家使用不同的托管标识创建新的数据存储或新的计算资源。 这种做法可防止访问并非特定于项目的数据。
(可选)若要简化项目成员身份管理,可以为项目成员创建 Microsoft Entra 安全组,并授予组对工作区的访问权限。
使用凭据直通身份验证的 Azure Data Lake Storage
可以使用 Microsoft Entra 用户标识从机器学习工作室进行交互式存储访问。 启用了分层命名空间的 Data Lake Storage 允许增强数据资产的组织以进行存储和协作。 使用 Data Lake Storage 分层命名空间,可通过向不同用户授予对不同文件夹和文件的基于访问控制列表 (ACL) 的访问权限来隔离数据访问。 例如,只能向一部分用户授予对机密数据的访问权限。
RBAC 和自定义角色
Azure RBAC 可帮助你管理谁有权访问机器学习资源,并配置谁可以执行操作。 例如,你可能希望仅向特定用户授予工作区管理员角色以管理计算资源。
访问范围可能因环境不同而不同。 在生产环境中,你可能想要限制用户更新推理终结点的能力。 而你可以向授权服务主体授予该权限。
机器学习具有多个默认角色:所有者、参与者、读者和数据科学家。 你也可以创建自己的自定义角色,例如创建反映组织结构的权限。 有关详细信息,请参阅管理对 Azure 机器学习工作区的访问权限。
随着时间的推移,团队的组成可能会发生变化。 如果为每个团队角色和工作区创建 Microsoft Entra 组,可以将 Azure RBAC 角色分配给 Microsoft Entra 组,并单独管理资源访问和用户组。
用户主体和服务主体可以是同一 Microsoft Entra 组的一部分。 例如,创建Azure 数据工厂用于触发机器学习管道的用户分配托管标识时,可以在 ML 管道执行程序 Microsoft Entra 组中包括托管标识。
集中 Docker 映像管理
Azure 机器学习提供可用于训练和部署的特选 Docker 映像。 但是,企业合规性要求可能要求使用公司管理的专用存储库中的映像。 机器学习有两种使用中央存储库的方法:
使用中央存储库中的映像作为基础映像。 机器学习环境管理安装包并创建运行训练或推理代码的 Python 环境。 使用此方法,可以轻松更新包依赖项,而无需修改基本映像。
按原样使用映像,而不使用机器学习环境管理。 此方法提供更高的控制度,但也要求你仔细构造 Python 环境作为映像的一部分。 需要满足运行代码所需的所有依赖项,并且任何新依赖项都需要重新生成映像。
有关详细信息,请参阅 “管理环境”。
数据加密
机器学习静态数据有两个数据源:
存储包含所有数据,包括训练和训练的模型数据,元数据除外。 你负责存储加密。
Azure Cosmos DB 包含元数据,包括运行历史记录信息,例如试验名称和试验提交日期和时间。 在大多数工作区中,Azure Cosmos DB 位于 Microsoft 订阅中,由 Microsoft 管理的密钥进行加密。
如果要使用自己的密钥加密元数据,可以使用客户管理的密钥工作区。 缺点是你的订阅中需要 Azure Cosmos DB 且你需要支付其费用。 有关详细信息,请参阅使用 Azure 机器学习进行数据加密。
有关 Azure 机器学习如何加密传输中的数据的信息,请参阅传输中加密。
监视
部署机器学习资源时,设置日志记录和审核控制以实现可观测性。 观察数据的动机可能因查看数据的人而异。 方案包括:
机器学习管理人员或运营团队想要监视机器学习管道运行状况。 这些观察者需要了解计划执行中的问题或数据质量或预期训练性能的问题。 可以生成 Azure 仪表板,用于监视Azure 机器学习数据或创建事件驱动的工作流。
容量管理员、机器学习管理人员或运营团队可能想要创建仪表板来观察计算和配额利用率。 若要管理具有多个 Azure 机器学习工作区的部署,请考虑创建一个中央仪表板以了解配额利用率。 配额在订阅级别进行管理,因此环境范围的视图对于推动优化非常重要。
IT 和运营团队可以设置诊断日志记录以在工作区中审核资源访问和更改事件。
考虑创建仪表板来监视机器学习和相关资源(如存储)的整体基础结构运行状况。 例如,将Azure 存储指标与管道执行数据相结合有助于优化基础结构以提高性能或发现问题的根本原因。
Azure 自动收集并存储平台指标和活动日志。 可以使用诊断设置将数据路由到其他位置。 将诊断日志记录设置为集中式 Log Analytics 工作区,以便跨多个工作区实例实现可观测性。 使用 Azure Policy 将新机器学习工作区的日志记录自动设置到此中央 Log Analytics 工作区中。
Azure Policy
可通过 Azure Policy 强制在工作区上使用安全功能并对此进行审核。 建议包括:
- 强制实施自定义管理的密钥加密。
- 强制实施 Azure 专用链接和专用终结点。
- 强制实施专用 DNS 区域。
- 禁用非 Azure AD 身份验证,例如安全外壳 (SSH)。
有关详细信息,请参阅 Azure 机器学习的内置策略定义。
你也可使用自定义策略定义以灵活的方式管理工作区安全性。
计算群集和实例
以下注意事项和建议适用于机器学习计算群集和实例。
磁盘加密
计算实例或计算群集节点的操作系统(OS)磁盘存储在Azure 存储中,并使用 Microsoft 管理的密钥进行加密。 每个节点还具有一个本地临时磁盘。 如果工作区是使用 hbi_workspace = True 参数创建的,则临时磁盘也会使用 Microsoft 管理的密钥进行加密。 有关详细信息,请参阅使用 Azure 机器学习进行数据加密。
托管的标识
计算群集支持使用托管标识对 Azure 资源进行身份验证。 对群集使用托管标识允许对资源进行身份验证,而无需在代码中公开凭据。 有关详细信息,请参阅创建 Azure 机器学习计算群集。
安装脚本
可以使用安装脚本在创建时自动执行计算实例的自定义和配置。 作为管理员,你可以编写一个自定义脚本,以便在工作区中创建所有计算实例时使用。 可以使用 Azure Policy 强制使用安装脚本来创建每个计算实例。 有关详细信息,请参阅创建和管理 Azure 机器学习计算实例。
代表他人创建
如果不希望数据科学家预配计算资源,可以代表他们创建计算实例并将其分配给数据科学家。 有关详细信息,请参阅创建和管理 Azure 机器学习计算实例。
启用了专用终结点的工作区
将计算实例与启用了专用终结点的工作区一起使用。 计算实例拒绝虚拟网络外部的所有公共访问。 此配置还会阻止数据包筛选。
Azure Policy 支持
使用 Azure 虚拟网络时,可以使用 Azure Policy 来确保在虚拟网络中创建每个计算群集或实例,并指定默认虚拟网络和子网。 使用 托管虚拟网络时不需要该策略,因为计算资源会自动在托管虚拟网络中创建。
你也可以使用策略来禁用非 Azure AD 身份验证,如 SSH。
后续步骤
详细了解机器学习安全配置:
基于机器学习模板的部署入门:
阅读有关部署机器学习的体系结构注意事项的更多文章:
了解团队结构、环境或区域限制如何影响工作区设置。
了解如何跨团队和用户管理计算成本和预算。
了解机器学习 DevOps (MLOps),它结合了人员、流程和技术,提供稳健可靠的自动化机器学习解决方案。