你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
了解 Azure NetApp 文件中的卷语言
Azure NetApp 文件卷上的卷语言(类似于客户端操作系统上的系统区域设置)控制使用 NFS 和 SMB 协议时支持的语言和字符集。 Azure NetApp 文件使用默认卷语言 C.UTF-8,它为字符集提供符合 POSIX 的 UTF-8 编码。 C.UTF-8 语言本身支持大小为 0-3 字节的字符,其中包括基本多语言平面 (BMP) 上的大多数世界语言(包括日语、德语和大多数希伯来语和西里尔语)。 有关 BMP 的详细信息,请参阅 Unicode。
BMP 之外的字符有时会超过 Azure NetApp 文件支持的 3 字节大小。 因此,它们需要使用代理项对逻辑,将多个字符字节集组合起来形成新字符。 例如,表情符号就属于此类别,并且在不强制执行 UTF-8 的情况下(例如使用 UTF-16 编码的 Windows 客户端或不强制执行 UTF-8 的 NFSv3)在 Azure NetApp 文件中受支持。 NFSv4.x 确实会强制执行 UTF-8,这意味着使用 NFSv4.x 时,代理项对字符不会正确显示。
当 Azure NetApp 文件中强制使用 UTF-8 时,非标准编码(例如 Shift-JIS 和不太常见的 CJK 字符)也不会正确显示。
提示
应该使用 UTF-8 发送和接收文本,以避免无法正确翻译字符的情况,这种情况可能会导致文件创建/重命名或复制错误方案。
当前无法在 Azure NetApp 文件中修改卷语言设置。 有关详细信息,请参阅特殊字符集的协议行为。
有关最佳做法,请参阅字符集最佳做法。
Azure NetApp 文件 NFS 和 SMB 卷中的字符编码
在 Azure NetApp 文件文件共享环境中,文件和文件夹名称由最终用户读取和解释的一系列字符表示。 这些字符的显示方式取决于客户端如何发送和接收这些字符的编码。 例如,如果客户端在访问 Azure NetApp 文件卷时将旧版 ASCII (American Standard Code for Information Interchange) 编码发送到该卷,则只能显示 ASCII 格式支持的字符。
例如,日语中的数据字符是“資”。 由于该字符无法用 ASCII 表示,因此使用 ASCII 编码的客户端会显示“?” 而不是“資”。
ASCII 仅支持 95 个可打印字符,主要是英语中的字符。 其中每个字符使用 1 个字节,该字节计入 Azure NetApp 文件卷上的总文件路径长度。 这限制了数据集的国际化,因为文件名可能包含 ASCII 无法识别的各种字符,从日语到西里尔字母再到表情符号。 一项国际标准 (ISO/IEC 8859) 试图支持更多国际字符,但也有其局限性。 大多数现代客户端使用某种形式的 Unicode 发送和接收字符。
Unicode
由于 ASCII 和 ISO/IEC 8859 编码的限制,我们制定了 Unicode 标准,以便任何人都可以从自己的设备查看其所在地区的语言。
- 与较旧的编码(例如 ASCII)相比,Unicode 通过增加文件路径中允许的每个字符的字节数(最多 4 个字节)和允许的字节总数来支持超过一百万个字符集。
- Unicode 通过为 ASCII 保留前 128 个字符来支持向后兼容性,同时还确保前 256 个代码点与 ISO/IEC 8859 标准相同。
- 在 Unicode 标准中,字符集被分解为多个平面。 一个平面是连续的 65,536 个码位。 Unicode 标准中总共有 17 个平面 (0-16)。 由于 UTF-16 的限制,该限制为 17。
- 平面 0 是基本多语言平面 (BMP)。 该平面包含多种语言中最常用的字符。
- 截至 Unicode 版本 15.1,这 17 个平面中目前只有 5 个已指定字符集。
- 平面 1-17 称为补充多语言平面 (SMP),包含较少使用的字符集,例如楔形文字和象形文字等古代书写系统,以及特殊的中文/日文/韩文 (CJK)
- 有关查看字符长度和路径大小以及控制发送到系统的编码的方法,请参阅将文件转换为不同的编码。
Unicode 使用 Unicode 转换格式作为其标准,其中 UTF-8 和 UTF-16 是两种主要格式。
Unicode 平面
Unicode 利用 17 个包含 65,536 个字符的平面(256 个码位乘以平面中的 256 个框),其中平面 0 作为基本多语言平面 (BMP)。 该平面包含多种语言中最常用的字符。 由于世界上的语言和字符集超过 65536 个字符,因此需要更多的平面来支持不太常用的字符集。
例如,平面 1(补充多语言平面 (SMP))包括楔形文字和埃及象形文字等历史文字以及一些 Osage、Warang Citi、Adlam、Wancho 和 Toto。 平面 1 还包含一些符号和表情符号字符。
平面 2 – 补充象形文字平面 (SIP) – 包含中文/日文/韩文 (CJK) 统一象形文字。 平面 1 和平面 2 中的字符大小通常为 4 字节。
例如:
- 平面 1 中的“大眼睛笑脸”表情符号“😃”的大小为 4 字节。
- 平面 1 中的埃及象形文字“𓀀”大小为 4 字节。
- 平面 1 中的 Osage字符“𐒸”大小为 4 字节。
- 平面 2 中的 CJK 字符“𫝁” 大小为 4 字节。
由于这些字符的大小均为 >3 字节,因此它们需要使用代理项对才能正常工作。 Azure NetApp 文件本身支持代理项对,但字符的显示会根据所使用的协议、客户端的区域设置以及远程客户端访问应用程序的设置而有所不同。
UTF-8
UTF-8 使用 8 位编码,最多可以有 1,112,064 个代码点(或字符)。 UTF-8 是基于 Linux 的操作系统中所有语言的标准编码。 由于 UTF-8 使用 8 位编码,因此可能的最大无符号整数为 255 (2^8 – 1),这也是该编码的最大文件名长度。 Internet 上 98% 以上的页面都使用 UTF-8,使其成为迄今为止最普遍的编码标准。 Web 超文本应用程序技术工作组 (WHATWG) 认为 UTF-8 是“所有[文本]的强制编码”,并且出于安全原因,浏览器应用程序不应使用 UTF-16。
UTF-8 格式中的每个字符使用 1-4 个字节,但几乎所有语言中的所有字符都使用 1-3 个字节。 例如:
- 拉丁字母“A”使用 1 个字节。 (128 个保留 ASCII 字符之一)
- 版权符号“©”使用 2 个字节。
- 字符“ä”使用 2 个字节。 (1 个字节用于“a”+ 1 个字节用于变音符号)
- 数据的日语汉字符号 (資) 使用 3 个字节。
- 笑脸表情符号 (😃) 使用 4 个字节。
语言区域设置可以使用计算机标准 UTF-8 (C.UTF-8) 或更特定于区域的格式,例如 en_US.UTF-8、ja.UTF-8 等。访问 Azure NetApp 文件时,应尽可能对 Linux 客户端使用 UTF-8 编码。 从 OS X 开始,macOS 客户端也使用 UTF-8 作为默认编码,不应进行调整。
Windows 客户端使用 UTF-16。 在大多数情况下,此设置应保留为操作系统区域设置的默认设置,但较新的客户端通过复选框提供对 UTF-8 字符的测试版支持。 还可以根据需要调整 Windows 中的终端客户端,以在 PowerShell 或 CMD 中使用 UTF-8。 有关详细信息,请参阅具有特殊字符集的双协议行为。
UTF-16
UTF-16 使用 16 位编码,能够对 Unicode 的所有 1,112,064 个代码点进行编码。 UTF-16 的编码可以使用 1 个或两个 16 位代码单元,每个代码单元大小为 2 字节。 UTF-16 中的所有字符都使用 2 字节或 4 字节大小。 使用 4 字节的 UTF-16 字符利用代理项对,将两个单独的 2 字节字符组合起来创建一个新字符。 这些补充字符落在标准 BMP 平面之外并进入其他多语言平面之一。
UTF-16 用于 Windows 操作系统和 API、Java 和 JavaScript。 由于它不支持向后兼容 ASCII 格式,因此从未在 Web 上获得普及。 UTF-16 仅占互联网上所有页面的 0.002% 左右。 Web 超文本应用程序技术工作组 (WHATWG) 认为 UTF-8 是“所有文本的强制编码”,并建议应用程序不要使用 UTF-16 来确保浏览器安全。
Azure NetApp 文件支持大多数 UTF-16 字符,包括代理项对。 如果不支持该字符,Windows 客户端会报告“指定的文件名无效或太长”的错误。
通过远程客户端进行的字符集处理
可将与装载 Azure NetApp 文件卷的客户端的远程连接(例如与 Linux 客户端的 SSH 连接以访问 NFS 装载)配置为发送和接收特定卷语言编码。 通过远程连接实用程序发送到客户端的语言编码控制如何创建和查看字符集。 因此,在 Azure NetApp 文件卷中列出文件和文件夹名称时,使用与一个远程连接不同的语言编码的另一个远程连接(例如两个不同的 PuTTY 窗口)可能会显示不同的字符结果。 在大多数情况下,这不会产生差异(例如拉丁/英语字符),但在特殊字符(例如表情符号)中,结果可能会有所不同。
例如,使用 UTF-8 编码进行远程连接会显示 Azure NetApp 文件卷中字符的可预测结果,因为 C.UTF-8 是卷语言。 根据终端发送的编码,“数据”的日语字符 (資) 以不同的方式显示。
PuTTY 中的字符编码
当 PuTTY 窗口使用 UTF-8(可在 Windows 的翻译设置中找到)时,对于 Azure NetApp 文件中的 NFSv3 装载卷,该字符会正确表示:

如果 PuTTY 窗口使用不同的编码,例如 ISO-8859-1:1998(拉丁语-1,西欧),即使文件名相同,同一字符也会显示不同的内容。

默认情况下,PuTTY 不包含 CJK 编码。 有可用的补丁可将这些语言集添加到 PuTTY。
Bastion 中的字符编码
Microsoft Azure 建议使用 Bastion 远程连接到 Azure 中的虚拟机 (VM)。 使用 Bastion 时,发送和接收的语言编码不会在配置中公开,而是利用标准 UTF-8 编码。 因此,在使用 UTF-8 的 PuTTY 中看到的大多数字符集在 Bastion 中也应该可见,前提是所使用的协议支持这些字符集。

提示
可以使用其他 SSH 终端,例如 TeraTerm。 TeraTerm 默认提供更广泛的支持字符集,包括 CJK 编码和 Shift-JIS 等非标准编码。
具有特殊字符集的协议行为
Azure NetApp 文件卷使用 UTF-8 编码,并且本身支持不超过 3 个字节的字符。 ASCII 和 UTF-8 集中的所有字符都可以正确显示,因为它们在 1-3 个字节的范围内。 例如:
- 拉丁字母字符“A”使用 1 个字节(128 个保留 ASCII 字符之一)。
- 版权符号 © 使用 2 个字节。
- 字符“ä”使用 2 个字节(1 个字节用于“a”,1 个字节用于变音符号)。
- 数据的日语汉字符号 (資) 使用 3 个字节。
Azure NetApp 文件还通过代理项对逻辑支持某些超过 3 个字节的字符(例如表情符号),前提是客户端编码和协议版本支持它们。 有关协议行为的更多信息,请参阅:
SMB 行为
在 SMB 卷中,Azure NetApp 文件为可从 SMB 客户端访问的任何目录中的文件或目录创建并维护两个名称:原始长名称和 8.3 格式的名称。
SMB 中的文件名与 Azure NetApp 文件
当文件或目录名称超出允许的字符字节或使用不受支持的字符时,Azure NetApp 文件会生成 8.3 格式的名称,如下所示:
- 它截断原始文件或目录名。
- 它将波形符 (~) 和数字 (1-5) 附加到截断后不再唯一的文件或目录名。 如果有五个以上具有非唯一名称的文件,Azure NetApp 文件将创建一个与原始名称无关的唯一名称。 对于文件,Azure NetApp 文件会将文件扩展名截断为三个字符。
例如,如果 NFS 客户端创建名为 specifications.html 的文件,Azure NetApp 文件将按照 8.3 格式创建文件名 specif~1.htm。 如果此名称已存在,Azure NetApp 文件将在文件名末尾使用不同的数字。 例如,如果 NFS 客户端随后创建另一个名为 specifications\_new.html 的文件,则 specifications\_new.html 的 8.3 格式为 specif~2.htm。
带有 Azure NetApp 文件的 SMB 中的特殊字符
将 SMB 与 Azure NetApp 文件卷结合使用时,由于代理项对支持,可以在文件和文件夹名称(包括表情符号)中使用超过 3 个字节的字符。 以下是使用默认 UTF-16 编码的英语时,Windows 资源管理器在从 Windows 客户端创建的文件夹中看到的 BMP 之外的字符。
注意
Windows 资源管理器中的默认字体是 Segoe UI。 字体更改可能会影响某些字符在客户端上的显示方式。

字符在客户端上的显示方式取决于系统字体以及语言和区域设置。 一般来说,所有协议都支持属于 BMP 的字符,无论编码是 UTF-8 还是 UTF-16。
使用 CMD 或 PowerShell 时,字符集的显示方式将取决于字体设置。 默认情况下,这些实用程序的字体选择有限。 CMD 使用 Consolas 作为默认字体。
文件名可能无法按预期显示,具体取决于所使用的字体,因为某些控制台本身不支持 Segoe UI 或正确呈现特殊字符的其他字体。
在 Windows 客户端上,可以使用 PowerShell ISE 解决此问题,它能提供更强大的字体支持。 例如,将 PowerShell ISE 设置为 Segoe UI 会正确显示包含受支持字符的文件名。

但是,PowerShell ISE 是为脚本编写而不是管理共享设计的。 较新的 Windows 版本提供了 Windows 终端,它允许控制字体和编码值。

如果卷启用了双协议(NFS 和 SMB),则可能会观察到不同的行为。 有关详细信息,请参阅具有特殊字符集的双协议行为。
NFS 行为
NFS 显示特殊字符的方式取决于所使用的 NFS 版本、客户端的区域设置、安装的字体以及所使用的远程连接客户端的设置。 例如,使用 Bastion 访问 Ubuntu 客户端时处理字符显示的方式将与同一 VM 上设置为不同区域设置的 PuTTY 客户端不同。 接下来的 NFS 示例依赖于 Ubuntu VM 的以下区域设置:
~$ locale
LANG=C.UTF-8
LANGUAGE=
LC\_CTYPE="C.UTF-8"
LC\_NUMERIC="C.UTF-8"
LC\_TIME="C.UTF-8"
LC\_COLLATE="C.UTF-8"
LC\_MONETARY="C.UTF-8"
LC\_MESSAGES="C.UTF-8"
LC\_PAPER="C.UTF-8"
LC\_NAME="C.UTF-8"
LC\_ADDRESS="C.UTF-8"
LC\_TELEPHONE="C.UTF-8"
LC\_MEASUREMENT="C.UTF-8"
LC\_IDENTIFICATION="C.UTF-8"
LC\_ALL=
NFSv3 行为
NFSv3 不对文件和文件夹强制执行 UTF 编码。 在大多数情况下,特殊字符集应该不存在问题。 但是,所使用的连接客户端可能会影响字符的发送和接收方式。 例如,由于客户端编码的工作方式,在 Azure 连接客户端 Bastion 中使用 BMP 之外的 Unicode 字符作为文件夹名称可能会导致一些意外行为。
在下面的屏幕截图中,当通过 NFSv3 命名目录时,Bastion 无法从浏览器外部将值复制并粘贴到 CLI 提示符。 尝试复制并粘贴 NFSv3Bastion𓀀𫝁😃𐒸 的值时,特殊字符在输入中显示为引号。

NFSv3 允许复制粘贴命令,但字符被创建为其数值,从而影响其显示:
NFSv3Bastion'$'\262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355
此显示是由于 Bastion 在复制和粘贴时发送文本值所使用的编码造成的。
当使用 PuTTY 通过 NFSv3 创建具有相同字符的文件夹时,Bastion 中的文件夹名称与使用 Bastion 创建时不同。 表情符号按预期显示(由于安装的字体和区域设置),但其他字符(例如 Osage“𐒸”)没有显示。

在 PuTTY 窗口中,字符显示正确:

NFSv4.x 行为
NFSv4.x 根据 RFC-8881 国际化规范强制在文件和文件夹名称中使用 UTF-8 编码。
因此,如果使用非 UTF-8 编码发送特殊字符,NFSv4.x 可能不允许该值。
在某些情况下,可能允许命令使用基本多语言平面 (BMP) 之外的字符,但该值在创建后可能不会显示。
例如,在 NFSv4.x 中,似乎使用包含字符“𓀀𫝁😃𐒸”(补充多语言平面 (SMP) 和补充象形文字平面 (SIP) 中的字符)的文件夹名称成功发出了 mkdir。 运行 ls 命令时,该文件夹不可见。
root@ubuntu:/NFSv4/NFS$ mkdir "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS$ ls -la
total 8
drwxrwxr-x 3 nobody 4294967294 4096 Jan 10 17:15 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
root@ubuntu:/NFSv4/NFS$
该文件夹存在于卷中。 可以从 PuTTY 客户端更改该隐藏目录名称,并且可以在该目录内创建文件。
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃𐒸"
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ sudo touch Unicode.txt
root@ubuntu:/NFSv4/NFS/NFSv4 Putty 𓀀𫝁😃𐒸$ ls -la
-rw-r--r-- 1 root root 0 Jan 10 17:31 Unicode.txt
PuTTY 的 stat 命令也确认该文件夹存在:
root@ubuntu:/NFSv4/NFS$ stat "NFSv4 Putty 𓀀𫝁😃𐒸"
**File: NFSv4 Putty** **𓀀**** 𫝁 ****😃**** 𐒸**
Size: 4096 Blocks: 8 IO Block: 262144 **directory**
Device: 3ch/60d Inode: 101 Links: 2
Access: (0775/drwxrwxr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2024-01-10 17:15:44.860775000 +0000
Modify: 2024-01-10 17:31:35.049770000 +0000
Change: 2024-01-10 17:31:35.049770000 +0000
Birth: -
即使确认该文件夹存在,通配符命令也不起作用,因为客户端无法在显示中正式“看到”该文件夹。
root@ubuntu:/NFSv4/NFS$ cp \* /NFSv3/
cp: can't stat '\*': No such file or directory
当 NFSv4.1 遇到不依赖 UTF-8 编码的字符时,它会向客户端发送错误。
例如,当使用 Bastion 尝试访问我们使用 PuTTY 通过 NFSv4.1 创建的同一目录时,结果如下:
root@ubuntu:/NFSv4/NFS$ cd "NFSv4 Putty 𓀀𫝁😃�"
-bash: cd: $'NFSv4 Putty \262\270\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355': Invalid argument
The "invalid argument" error message doesn't help diagnose the root cause, but a packet capture shines a light on the problem:
78 1.704856 y.y.y.y x.x.x.x NFS 346 V4 Call (Reply In 79) LOOKUP DH: 0x44caa451/NFSv4 Putty ��������
79 1.705058 x.x.x.x y.y.y.y NFS 166 V4 Reply (Call In 25) OPEN Status: NFS4ERR\_INVAL
RFC-8881 中介绍了 NFS4ERR_INVAL。
由于可以从 PuTTY 访问该文件夹(由于发送和接收的编码),因此如果指定名称,则可以复制该文件夹。 将该文件夹从 NFSv4.1 Azure NetApp 文件卷复制到 NFSv3 Azure NetApp 文件卷后,文件夹名称显示:
root@ubuntu:/NFSv4/NFS$ cp -r /NFSv4/NFS/"NFSv4 Putty 𓀀𫝁😃𐒸" /NFSv3/NFSv3/
root@ubuntu:/NFSv4/NFS$ ls -la /NFSv3/NFSv3 | grep v4
drwxrwxr-x 2 root root 4096 Jan 10 17:49 NFSv4 Putty 𓀀𫝁😃𐒸
如果尝试将文件转换(使用“iconv”)到非 UTF-8 格式(例如 Shift-JIS),则会出现相同的 NFS4ERR\_INVAL 错误。
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
有关详细信息,请参阅将文件转换为不同的编码。
双协议行为
Azure NetApp 文件允许 NFS 和 SMB 通过双协议访问来访问卷。 由于 NFS (UTF-8) 和 SMB (UTF-16) 使用的语言编码存在巨大差异,因此不同协议的字符集、文件和文件夹名称以及路径长度可能具有截然不同的行为。
从 SMB 查看 NFS 创建的文件和文件夹
当 Azure NetApp 文件用于双协议访问(SMB 和 NFS)时,通过 NFS 使用 UTF-8 创建的文件名中可能会使用 UTF-16 不支持的字符集。 在这些情况下,当 SMB 访问包含不受支持的字符的文件时,SMB 中的名称会使用 8.3 短文件名约定截断。
NFSv3 创建的文件和具有字符集的 SMB 行为
NFSv3 不强制执行 UTF-8 编码。 使用 NFSv3 时,使用非标准语言编码(例如 Shift-JIS)的字符可与 Azure NetApp 文件一起使用。
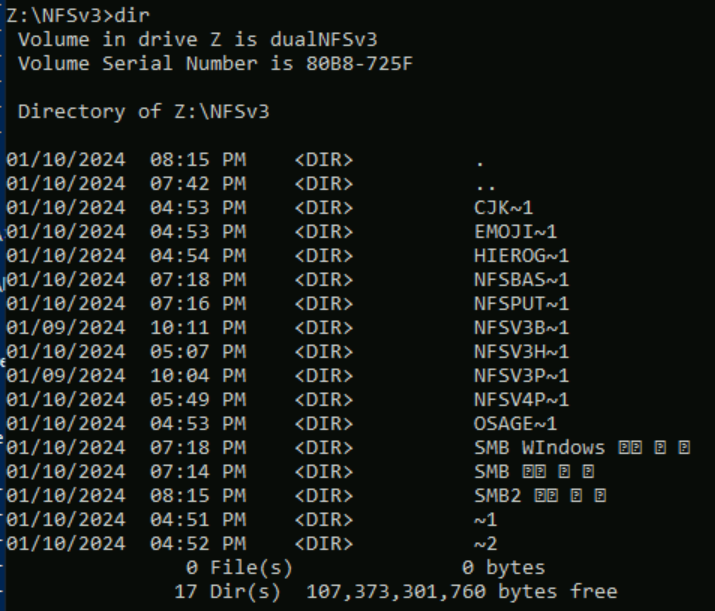
在以下示例中,使用 NFSv3 在 Azure NetApp 文件卷中创建了一系列使用来自 Unicode 不同平面的不同字符集的文件夹名称。 从 NFSv3 查看时,这些内容会正确显示。
root@ubuntu:/NFSv3/dual$ ls -la
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-English
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-Japanese-German-資ä
drwxrwxr-x 2 root root 4096 Jan 10 19:43 NFSv3-BMP-copyright-©
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-CJK-plane2-𫝁
drwxrwxr-x 2 root root 4096 Jan 10 19:44 NFSv3-emoji-plane1-😃
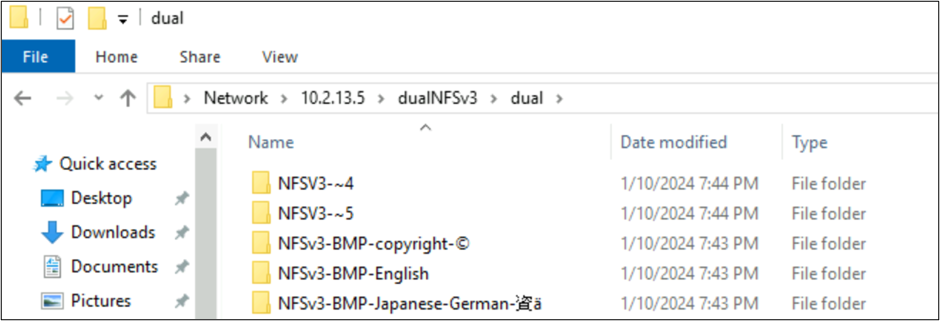
从 Windows SMB 中,包含 BMP 中找到的字符的文件夹可以正常显示,但该平面之外的字符会以 8.3 名称格式显示,因为 UTF-8/UTF-16 转换与这些字符不兼容。
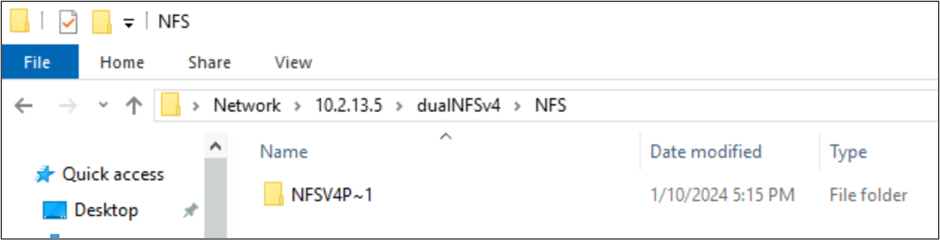
NFSv4.1 创建的文件和具有字符集的 SMB 行为
在前面的示例中,通过 NFSv4.1 在 Azure NetApp 文件卷上创建了名为 NFSv4 Putty 𓀀𫝁😃𐒸 的文件夹,但无法使用 NFSv4.1 查看该文件夹。 不过,可以使用 SMB 查看。 由于从 NFS 客户端创建的字符集不受支持以及不同 Unicode 平面中字符的 UTF-8/UTF-16 转换不兼容,名称在 SMB 中被截断为受支持的 8.3 格式。
当文件夹名称使用 BMP 中的标准 UTF-8 字符(英语或其他语言)时,SMB 会正确翻译该名称。
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-English
root@ubuntu:/NFSv4/NFS$ mkdir NFS-created-資ä
root@ubuntu:/NFSv4/NFS$ ls -la
total 16
drwxrwxr-x 5 nobody 4294967294 4096 Jan 10 18:26 .
drwxrwxrwx 4 root root 4096 Jan 10 17:15 ..
**drwxrwxr-x 2 root root 4096 Jan 10 18:21 NFS-created-English**
**drwxrwxr-x 2 root root 4096 Jan 10 18:26 NFS-created-**** 資 ****ä**
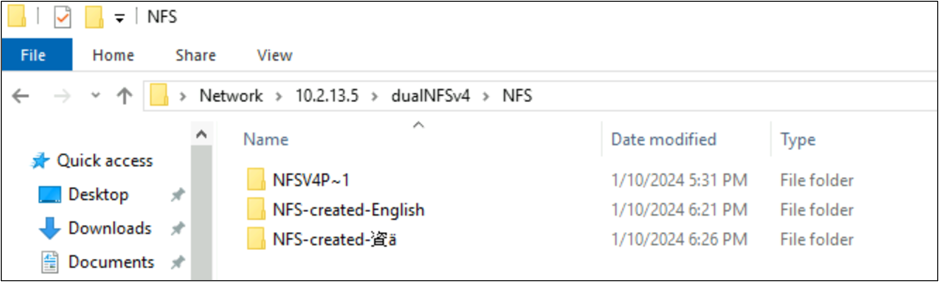
SMB 通过 NFS 创建的文件和文件夹
Windows 客户端是用于访问 SMB 共享的主要客户端类型。 这些客户端默认使用 UTF-16 编码。 通过在区域设置中启用它,可以在 Windows 中支持某些 UTF-8 编码字符:
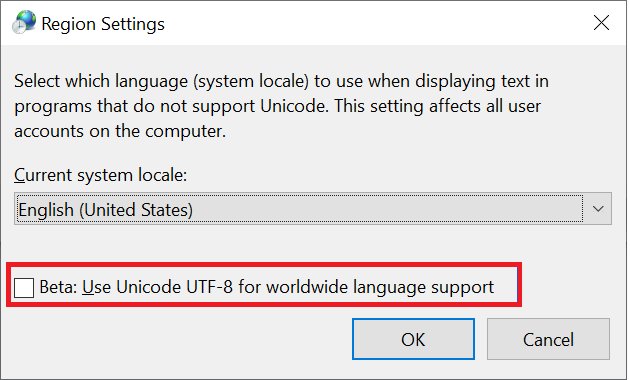
通过 Azure NetApp 文件中的 SMB 共享创建文件或文件夹时,字符集将使用 UTF-16 编码方式。 因此,使用 UTF-8 编码的客户端(例如基于 Linux 的 NFS 客户端)可能无法正确转换某些字符集,尤其是不在基本多语言平面 (BMP) 范围内的字符。
不支持的角色行为
在这些情况下,当 NFS 客户端访问使用 SMB 创建的包含不支持字符的文件时,名称将显示为一系列表示该字符的 Unicode 值的数值。
例如,该文件夹是使用 BMP 之外的字符在 Windows 资源管理器中创建的。
PS Z:\SMB\> dir
Directory: Z:\SMB
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/9/2024 9:53 PM SMB𓀀𫝁😃𐒸
通过 NFSv3,SMB 创建的文件夹显示:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 9 21:53 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
通过 NFSv4.1,SMB 创建的文件夹显示如下:
$ ls -la
drwxrwxrwx 2 root daemon 4096 Jan 4 17:09 'SMB'$'\355\240\214\355\260\200\355\241\255\355\275\201\355\240\275\355\270\203\355\240\201\355\262\270'
支持的角色行为
当字符位于 BMP 中时,SMB 和 NFS 协议及其版本之间不存在问题。
例如,在 Azure NetApp 文件卷上使用 SMB 创建的文件夹名称,以及在多种语言(英语、德语、西里尔语、北欧古字碑文)的 BMP 中找到的字符,在所有协议和版本中都可以正常显示。
- 基本拉丁语“SMB”
- 希腊语“ͶΘΩ”
- 西里尔语“ЁЄЊ”
- 北欧古字碑文“ᚠᚱᛯ”
- CJK 兼容性象形字“豈滑虜”
该名称在 SMB 中的显示方式如下:
PS Z:\SMB\> mkdir SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
Mode LastWriteTime Length Name
---- ------------- ------ ----
d----- 1/11/2024 8:00 PM SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
该名称在 NFSv3 中的显示方式如下:
$ ls | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
该名称在 NFSv4.1 中的显示方式如下:
$ ls /NFSv4/SMB | grep SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
SMBͶΘΩЁЄЊᚠᚱᛯ豈滑虜
将文件转换为不同的编码
文件和文件夹名称并不是文件系统对象中使用语言编码的唯一部分。 文件内容(例如文本文件中的特殊字符)也可以发挥作用。 例如,如果尝试以不兼容的格式保存带有特殊字符的文件,则可能会看到错误消息。 在这种情况下,带有片假名字符的文件无法以 ANSI 保存,因为这些字符在该编码中不存在。
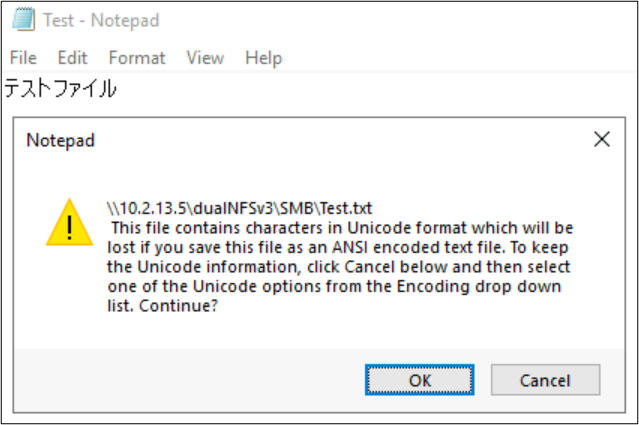
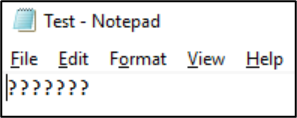
以该格式保存该文件后,字符将转换为问号:
可以从 NAS 客户端查看文件编码。 在 Windows 客户端上,可以使用 Notepad 或 Notepad++ 等应用程序来查看文件的编码。 如果客户端上安装了适用于 Linux 的 Windows 子系统 (WSL) 或 Git,则可以使用 file 命令。
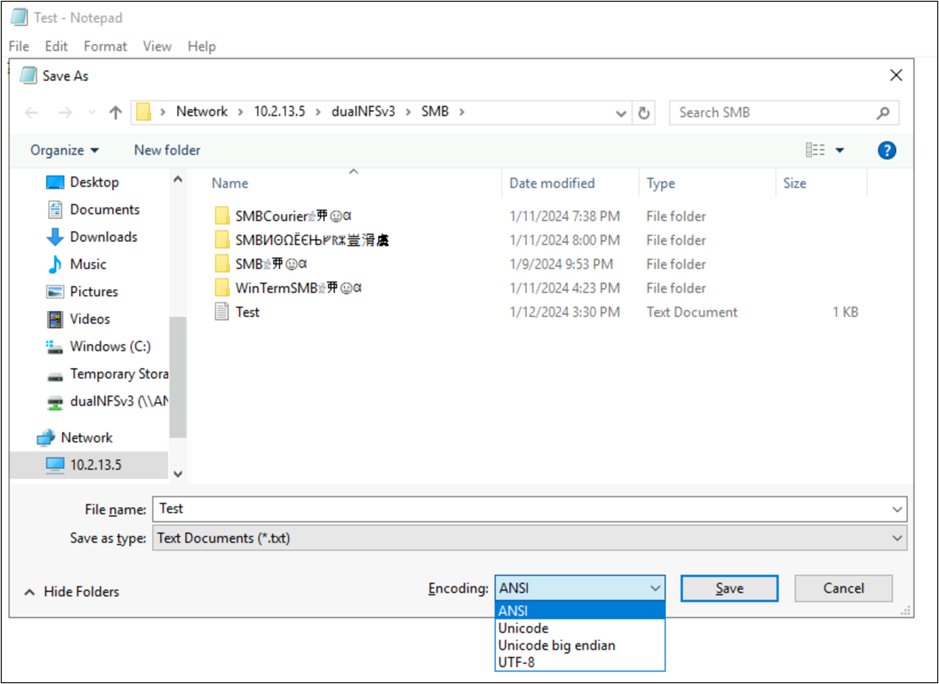
这些应用程序还可以将文件的编码另存为不同的编码类型,从而更改编码。 此外,PowerShell 可用于通过 Get-Content 和 Set-Content cmdlet 转换文件编码。
例如,文件 utf8-text.txt 编码为 UTF-8 并且包含 BMP 之外的字符。 由于使用 UTF-8,因此字符可以正常显示。
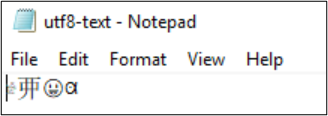
如果将编码转换为 UTF-32,字符将无法正常显示。
PS Z:\SMB\> Get-Content .\utf8-text.txt |Set-Content -Encoding UTF32 -Path utf32-text.txt
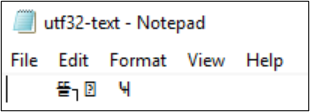
Get-Content 还可用于显示文件内容。 默认情况下,PowerShell 使用 UTF-16 编码(代码页 437),控制台的字体选择受到限制,因此带有特殊字符的 UTF-8 格式文件无法正常显示:

Linux 客户端可以使用 file 命令查看文件的编码。 在双协议环境下,如果使用 SMB 创建文件,则使用 NFS 的 Linux 客户端可以检查文件编码。
$ file -i utf8-text.txt
utf8-text.txt: text/plain; charset=utf-8
$ file -i utf32-text.txt
utf32-text.txt: text/plain; charset=utf-32le
可以使用 iconv 命令在 Linux 客户端上执行文件编码转换。 若要查看支持的编码格式列表,请使用 iconv -l。
例如,UTF-8 编码的文件可以转换为 UTF-16。
$ iconv -t UTF16 utf8-text.txt \> utf16-text.txt
$ file -i utf8-text.txt
utf8-text.txt: text/plain; **charset=utf-8**
$ file -i utf16-text.txt
utf16-text.txt: text/plain; **charset=utf-16le**
如果目标编码不支持文件名或文件内容中的字符集,则不允许转换。 例如,Shift-JIS 无法支持文件内容中的字符。
$ iconv -t SJIS utf8-text.txt SJIS-text.txt
iconv: illegal input sequence at position 0
如果文件包含编码支持的字符,则转换将会成功。 例如,如果文件包含片假名字符测试文件,则将通过 NFS 成功实现 Shift-JIS 转换。 此处使用的 NFS 客户端由于区域设置而无法识别 Shift-JIS,因此编码显示“unknown-8bit”。
$ cat SJIS.txt
テストファイル
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
$ iconv -t SJIS SJIS.txt \> SJIS2.txt
$ file -i SJIS.txt
SJIS.txt: text/plain; **charset=utf-8**
$ file -i SJIS2.txt
SJIS2.txt: text/plain; **charset=unknown-8bit**
由于 Azure NetApp 文件卷仅支持 UTF-8 兼容格式,因此片假名字符会转换为不可读的格式。
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
使用 NFSv4.x 时,当文件内容中存在不兼容的字符时,即使 NFSv4.x 强制执行 UTF-8 编码,也允许进行转换。 在此示例中,位于 Azure NetApp 文件卷上的带有片假名字符的 UTF-8 编码文件正确显示文件内容。
$ file -i SJIS.txt
SJIS.txt: text/plain; charset=utf-8
S$ cat SJIS.txt
テストファイル
但转换后,由于编码不兼容,文件中的字符显示不正常。
$ cat SJIS2.txt
▒e▒X▒g▒t▒@▒C▒▒
如果文件名包含 UTF-8 不支持的字符,则转换会在 NFSv3 上成功,但由于协议版本的 UTF-8 强制执行而在 NFSv4.x 上失败。
# echo "Test file with SJIS encoded filename" \> "$(echo 'テストファイル.txt' | iconv -t SJIS)"
-bash: $(echo 'テストファイル.txt' | iconv -t SJIS): Invalid argument
字符集最佳做法
在 Azure NetApp 文件卷上使用特殊字符或标准基本多语言平面 (BMP) 之外的字符时,应考虑一些最佳做法。
- 由于 Azure NetApp 文件卷使用 UTF-8 卷语言,因此 NFS 客户端的文件编码也应使用 UTF-8 编码以获得一致的结果。
- 文件名中或文件内容中包含的字符集应与 UTF-8 兼容,以便正确显示和发挥作用。
- 由于 SMB 使用 UTF-16 字符编码,因此 BMP 之外的字符可能无法在双协议卷中的 NFS 上正确显示。 尽可能减少文件内容中特殊字符的使用。
- 避免在文件名中使用 BMP 之外的特殊字符,尤其是在使用 NFSv4.1 或双协议卷时。
- 对于不在 BMP 中的字符集,UTF-8 编码应允许在使用单个文件协议(仅限 SMB 或仅限 NFS)时显示 Azure NetApp 文件中的字符。 但是,在大多数情况下,双协议卷无法容纳这些字符集。
- Azure NetApp 文件卷不支持非标准编码(例如 Shift-JIS)。
- Azure NetApp 文件卷支持代理项对字符(例如表情符号)。