你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
通过跨区域复制 Log Analytics 工作区来增强复原能力(预览版)
通过让你切换到复制的工作区并在发生区域性故障时继续操作,跨区域复制 Log Analytics 工作区可增强复原能力。 本文介绍了 Log Analytics 工作区复制的工作原理、如何复制工作区、如何切换和切回,以及如何决定何时在复制的工作区之间切换。
以下视频简要概述了 Log Analytics 工作区复制的工作原理:
重要
虽然我们有时使用术语“故障转移”,例如在 API 调用中,但故障转移也通常用于描述自动过程。 因此,本文使用术语“切换”来强调切换到复制的工作区是手动触发的操作。
Log Analytics 工作区复制的工作原理
原始工作区和区域称为主要。 复制的工作区和备用区域称为次要。
工作区复制过程会在次要区域中创建工作区的实例。 此过程将会创建与主工作区具有相同配置的次要工作区,Azure Monitor 会使用你将来对主工作区配置所做的任何更改来自动更新次要工作区。
次要工作区是一个“影子”工作区,仅用于复原目的。 你无法在 Microsoft Azure 门户中看到次要工作区,并且无法直接管理或访问它。
如果启用工作区复制,则 Azure Monitor 还会将引入到主工作区的新日志发送到次要区域。 在启用工作区复制之前,不会复制引入到工作区的日志。
如果服务中断对主要区域造成了影响,则可以切换并将所有引入和查询请求重新路由到次要区域。 在 Azure 缓解服务中断并且主工作区再次正常运行后,可以切换回主要区域。
切换时,次要工作区将变为活动状态,而主工作区则变为非活动状态。 然后,Azure Monitor 将通过次要区域(而不是主要区域)中的引入管道来引入新数据。 切换到次要区域时,Azure Monitor 会将从次要区域引入的所有数据复制到主要区域。 此过程是异步的,不会影响引入延迟。
注意
切换到次要区域后,如果主要区域无法处理传入的日志数据,则 Azure Monitor 会将次要区域中的数据缓冲长达 11 天。 在前 4 天,Azure Monitor 会自动重新尝试定期复制数据。

防止区域性故障期间传输中的数据丢失
Azure Monitor 具有多种机制,可确保在主要区域中发生故障时,正在传输的数据不会丢失。
当主要区域的管道无法处理数据时,Azure Monitor 会保护到达主要区域引入终结点的数据。 当管道可用时,它会继续处理传输中的数据,Azure Monitor 会引入数据并将其复制到次要区域。
如果主要区域的引入终结点不可用,Azure Monitor 代理会定期重试向终结点发送日志数据。 触发切换后几分钟,次要区域中的数据引入终结点会开始从代理接收数据。
如果编写自己的客户端以将日志数据发送到 Log Analytics 工作区,请确保客户端会处理失败的引入请求。
部署注意事项
目前不支持复制链接到专用群集的 Log Analytics 工作区。
用于从工作区中删除记录的清除操作,可从主工作区和次要工作区中删除相关记录。 如果其中一个工作区实例不可用,则清除操作将失败。
Azure Monitor 支持查询非活动区域。 当在区域之间切换时,基于查询的警报将继续工作,除非活动区域中的警报服务无法正常工作或警报规则不可用。 目前不支持跨区域复制警报规则。
为与 Sentinel 交互的工作区启用复制时,最多可能需要 12 天时间才能将监视列表和威胁情报数据完全复制到次要工作区。
在切换期间无法启动工作区管理作,包括:
- 更改工作区保留期、定价层、每日上限等
- 更改网络设置
- 通过新的自定义日志更改架构或从新的资源提供程序连接平台日志,例如从新资源类型发送诊断日志
切换期间不支持旧版 Log Analytics 代理的解决方案目标功能。 在切换期间,解决方案数据将从所有代理引入。
故障转移过程将更新域名系统 (DNS) 记录,以将所有引入请求重新路由到次要区域进行处理。 某些 HTTP 客户端具有“粘性连接”,可能需要更长的时间才能获取 DNS 更新的 DNS。 在切换过程中,这些客户端可能会尝试在一段时间内通过主要区域引入日志。 可以使用各种客户端,包括旧版 Log Analytics 代理、Azure Monitor 代理、代码(使用日志引入 API 或旧版 HTTP 数据收集 API)和其他服务(如 Microsoft Sentinel),将日志引入到主工作区。
这些功能当前不受支持或仅部分受支持:
功能 支持 辅助表计划 不支持。 Azure Monitor 不会将设置了辅助日志计划的表中的数据复制到辅助工作区。 因此,如果发生区域性故障,这些数据将无法得到保护,可能会丢失,即时切换到辅助工作区,这些数据也无法访问。 搜索作业,还原 部分支持 - 搜索作业和还原操作创建表,并使用搜索结果或还原的数据来填充表。 启用工作区复制后,为这些操作创建的新表将复制到次要工作区。 在启用复制之前填充的表不会复制。 如果在切换时正在进行这些操作,则会出现意外结果。 它可能会成功完成但无法复制,也可能会失败,具体取决于工作区运行状况和确切时间。 通过 Log Analytics 工作区使用 Application Insights 不支持 VM Insights 不支持 容器见解 不支持 专用链接 故障转移期间不受支持
支持的区域
工作区复制目前支持有限区域中的工作区,这些区域按区域组(地理上相邻的区域组)进行了分类。 启用复制时,请从与工作区主要位置位于同一区域组中的受支持区域列表中选择次要位置。 例如,位于欧洲西部的工作区可以在欧洲北部进行复制,但不能在美国西部 2 进行复制,因为这些区域位于不同的区域组中。
目前支持以下区域组和区域:
| 区域组 | 区域 | 备注 | ||
|---|---|---|---|---|
| 北美 | 美国东部 | 美国东部不能与美国东部 2 和美国中南部区域进行相互复制操作。 | ||
| 美国东部 2 | 美国东部 2 不能与美国东部和美国中南部区域进行相互复制操作。 | |||
| 美国西部 | ||||
| 美国西部 2 | ||||
| 美国中部 | ||||
| 美国中南部 | 美国中南部不能与美国东部和美国东部 2 区域进行相互复制操作。 | |||
| 加拿大中部 | ||||
| 欧洲 | 西欧 | |||
| 北欧 | ||||
| 英国南部 | ||||
| 英国西部 | ||||
| 德国中西部 | ||||
| 法国中部 |
数据驻留要求
不同的客户有不同的数据驻留要求,因此请务必控制数据的存储位置。 Azure Monitor 在你选择的主要区域和次要区域中处理和存储日志。 有关详细信息,请参阅支持的区域。
支持 Microsoft Sentinel 和其他服务
使用 Log Analytics 工作区的各种服务和功能都与工作区复制和切换兼容。 切换到次要工作区时,这些服务和功能将继续工作。
例如,导致日志引入延迟的区域网络问题可能会影响 Microsoft Sentinel 客户。 使用复制工作区的客户可以切换到次要区域,以继续使用其 Log Analytics 工作区和 Sentinel。 但是,如果网络问题影响 Sentinel 服务运行状况,则切换到另一个区域无法缓解此问题。
某些 Azure Monitor 体验(包括 Application Insights 和 VM Insights)目前仅与工作区复制和切换部分兼容。 有关完整列表,请参阅部署注意事项。
定价模型
启用工作区复制时,需要为所有引入到工作区的数据的复制付费。
重要
如果使用 Azure Monitor 代理、日志引入 API、Azure 事件中心或其他使用数据收集规则的数据源将数据发送到工作区,请确保将数据收集规则与工作区的数据收集终结点相关联。 此关联可确保引入的数据会复制到辅助工作区。 如果不将数据收集规则与工作区数据收集终结点相关联,即使数据未复制,仍会为引入工作区的所有数据付费。
所需的权限
| 操作 | 所需的权限 |
|---|---|
| 启用工作区复制 |
Microsoft.OperationalInsights/workspaces/write 和 Microsoft.Insights/dataCollectionEndpoints/write 权限,例如,监视参与者内置角色所提供的权限 |
| 切换和切回(触发故障转移和故障回复) |
Microsoft.OperationalInsights/locations/workspaces/failover、Microsoft.OperationalInsights/workspaces/failback、Microsoft.Insights/dataCollectionEndpoints/triggerFailover/action 和 Microsoft.Insights/dataCollectionEndpoints/triggerFailback/action 权限,例如,监视参与者内置角色所提供的权限 |
| 检查工作区状态 | 对 Log Analytics 工作区具有 Microsoft.OperationalInsights/workspaces/read 权限,例如,监视参与者内置角色所提供的权限 |
启用和禁用工作区复制
可以使用 REST 命令来启用和禁用工作区复制。 该命令会触发长时间运行的操作,这意味着应用新设置可能需要几分钟时间。 启用复制后,所有表(数据类型)最多可能需要一小时才能开始复制,而某些数据类型可能会在其他类型之前开始复制。 启用工作区复制后对表架构所做的更改(例如,你创建的新自定义日志表或自定义字段,或为新资源类型设置的诊断日志)可能需要长达一小时才能开始复制。
启用工作区复制
若要在 Log Analytics 工作区上启用复制,请使用以下 PUT 命令:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": true,
"location": "<secondary_region>"
}
},
"location": "<primary_region>"
}
其中:
-
<subscription_id>:与工作区相关的订阅 ID。 -
<resourcegroup_name>:包含 Log Analytics 工作区资源的资源组。 -
<workspace_name>:工作区的名称。 -
<primary_region>:Log Analytics 工作区的主要区域。 -
<secondary_region>:Azure Monitor 在其中创建次要工作区的区域。
有关支持的 location 值,请参阅支持的区域。
PUT 命令是一项长时间运行的操作,可能需要一些时间才能完成。 成功的调用将返回 200 状态代码。 可以跟踪请求的预配状态,如检查请求预配状态中所述。
检查请求预配状态
若要检查请求的预配状态,请运行以下 GET 命令:
GET
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
其中:
-
<subscription_id>:与工作区相关的订阅 ID。 -
<resourcegroup_name>:包含 Log Analytics 工作区资源的资源组。 -
<workspace_name>:Log Analytics 工作区的名称。
使用 GET 命令验证工作区预配状态是否从 Updating 更改为 Succeeded,以及次要区域是否已按预期进行设置。
注意
为与 Sentinel 交互的工作区启用复制时,最多可能需要 12 天时间才能将监视列表和威胁情报数据完全复制到次要工作区。
将数据收集规则与工作区数据收集终结点相关联
Azure Monitor 代理、日志引入 API 和 Azure 事件中心收集数据,并将其发送到你根据设置数据收集规则 (DCR) 的方式指定的目标。
如果你有将数据发送到主工作区的数据收集规则,则需要将该规则与系统数据收集终结点 (DCE) 相关联,Azure Monitor 会在你启用工作区复制时创建该终结点。 工作起数据收集终结点的名称与工作区 ID 相同。 只有与工作区数据收集终结点关联的数据收集规则才能启用复制和切换。 此行为允许你指定要复制的日志流集,这有助于控制复制成本。
若要使用数据收集规则复制收集的数据,请将数据收集规则关联到工作区数据收集终结点:
在 Microsoft Azure 门户中,选择“数据收集规则”。
从“数据收集规则”屏幕中,选择用于将数据发送到主 Log Analytics 工作区的数据收集规则。
在数据收集规则“概述”页上,选择“配置 DCE”并从可用列表中选择工作区数据收集终结点:
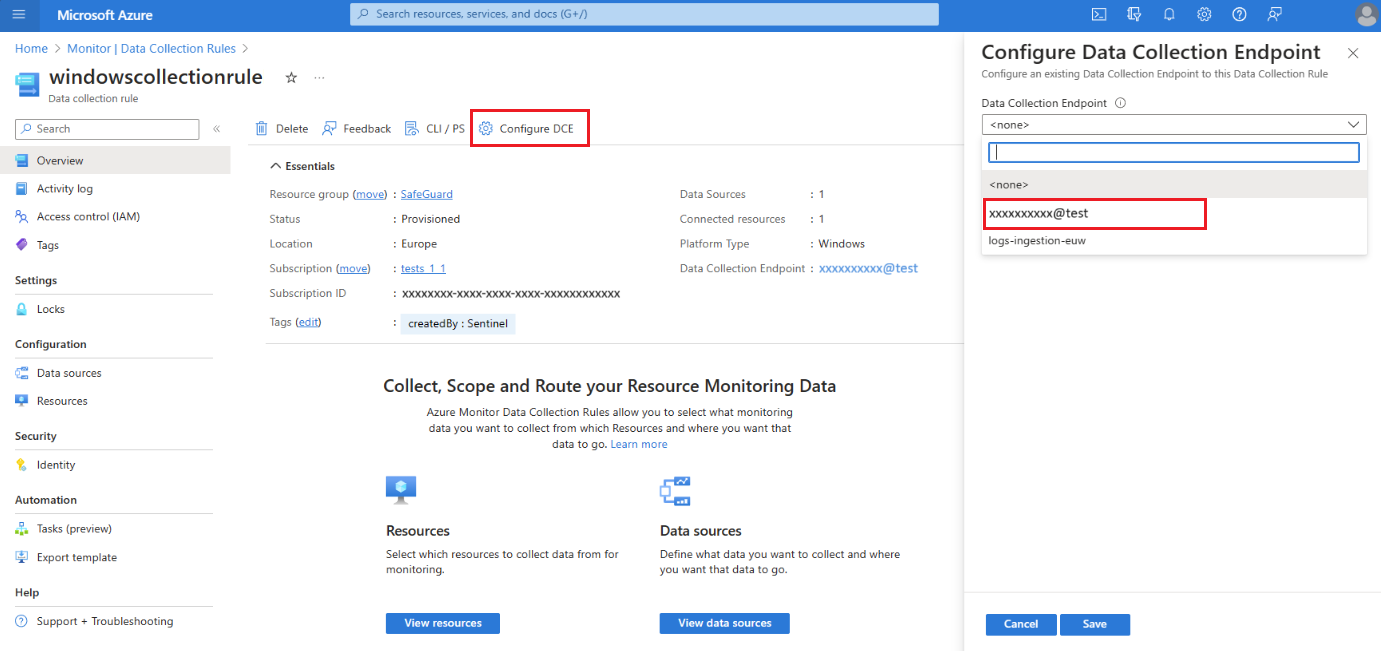 有关系统 DCE 的详细信息,请查看工作区对象属性。
有关系统 DCE 的详细信息,请查看工作区对象属性。

重要
连接到工作区数据收集终结点的数据收集规则只针对该特定工作区。 该数据收集规则不能针对其他目标,例如其他工作区或 Azure 存储帐户。
禁用工作区复制
若要禁用工作区复制,请使用以下 PUT 命令:
PUT
https://management.azure.com/subscriptions/<subscription_id>/resourcegroups/<resourcegroup_name>/providers/microsoft.operationalinsights/workspaces/<workspace_name>?api-version=2023-01-01-preview
body:
{
"properties": {
"replication": {
"enabled": false
}
},
"location": "<primary_region>"
}
其中:
-
<subscription_id>:与工作区相关的订阅 ID。 -
<resourcegroup_name>- 包含工作区资源的资源组。 -
<workspace_name>:工作区的名称。 -
<primary_region>:工作区的主要区域。
PUT 命令是一项长时间运行的操作,可能需要一些时间才能完成。 成功的调用将返回 200 状态代码。 可以跟踪请求的预配状态,如检查请求预配状态中所述。
监视工作区和服务运行状况
问题示例包括引入延迟或查询失败,通常可以通过故障转移到次要区域来处理这些问题。 可以使用服务运行状况通知和日志查询来检测此类问题。
服务运行状况通知对于解决与服务相关的问题非常有用。 若要确定影响特定工作区(可能不是整个服务)的问题,可以使用其他措施:
- 基于工作区资源运行状况创建警报
- 为工作区运行状况指标设置自己的阈值
- 创建自己的监视查询以用作工作区的自定义运行状况指示器,如使用查询监视工作区性能中所述:
- 测量每个表的引入延迟
- 确定延迟的来源是收集代理还是引入管道
- 监视每个表和资源的引入量异常
- 监视每个表、用户或资源的查询成功率
- 基于查询创建警报
注意
你还可以使用日志查询监视次要工作区,但请记住,日志复制是在批处理操作中完成的。 测量的延迟可能会波动,并且无法指示次要工作区存在任何运行状况问题。 有关详细信息,请参阅审核非活动工作区。
切换到次要工作区
在切换期间,大多数操作的工作方式与使用主工作区和区域时相同。 但是,有些操作的行为略有不同,或者会被阻止。 有关详细信息,请参阅部署注意事项。
何时应该切换?
可以根据正在进行的性能和运行状况监视以及你的系统标准和要求,决定何时切换到次要工作区和切换回主工作区。
如以下小节所述,在切换计划中有几点需要考虑。
问题类型和范围
切换过程会将引入和查询请求路由到次要区域,这通常会绕过导致主要区域出现延迟或失败的任何故障组件。 因此,如果出现以下情况,切换可能无济于事:
- 基础资源存在跨区域问题。 例如,如果相同的资源类型在主要区域和次要区域中都失败。
- 遇到与工作区管理相关的问题,例如更改工作区保留期。 工作区管理操作始终在主要区域中进行处理。 在切换期间,工作区管理操作将被阻止。
问题持续时间
切换不是即时的。 重新路由请求的过程依赖于 DNS 更新,某些客户端在几分钟内会获取这些更新,而其他客户端则可能需要更多时间。 因此,了解问题是否可以在几分钟内解决很有帮助。 如果观察到的问题是一致或持续存在的问题,请不要等待切换。 以下是一些示例:
引入:主要区域中引入管道的问题可能会影响向次要工作区的数据复制。 在切换期间,日志将改为发送到次要区域中的引入管道。
查询:如果主工作区中的查询失败或超时,则日志搜索警报可能会受到影响。 在这种情况,切换到次要工作区以确保正确触发所有警报。
次要工作区数据
在启用复制之前引入到主工作区的日志不会复制到次要工作区。 如果在三小时前启用了工作区复制,并且现在切换到次要工作区,则查询只能返回过去三个小时的数据。
在切换期间切换区域之前,次要工作区需要包含有用的日志量。 建议在启用复制后至少等待一周,然后再触发切换。 这七天可以在次要区域中提供足够的数据。
触发切换
在切换之前,确认工作区复制操作已成功完成。 仅当正确配置次要工作区时,切换才会成功。
若要切换到次要工作区,请使用以下 POST 命令:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/locations/<secondary_region>/workspaces/<workspace_name>/failover?api-version=2023-01-01-preview
其中:
-
<subscription_id>:与工作区相关的订阅 ID。 -
<resourcegroup_name>- 包含工作区资源的资源组。 -
<secondary_region>:切换期间要切换到的区域。 -
<workspace_name>:切换期间要切换到的工作区的名称。
POST 命令是一项长时间运行的操作,可能需要一些时间才能完成。 成功的调用将返回 202 状态代码。 可以跟踪请求的预配状态,如检查请求预配状态中所述。
切回主工作区
切回过程会取消将查询和日志引入请求重新路由到次要工作区。 切回时,Azure Monitor 会重新将查询和日志引入请求路由到主工作区。
切换到次要区域时,Azure Monitor 会将日志从次要工作区复制到主工作区。 如果服务中断对主要区域中的日志引入过程造成了影响,则 Azure Monitor 可能需要一段时间才能完成将复制的日志引入到主工作区。
何时应该切回?
如以下小节所述,在切回计划中有几点需要考虑。
日志复制状态
切回之前,请验证 Azure Monitor 是否已完成复制在切换到主要区域期间引入的所有日志。 如果在所有日志复制到主工作区之前切回,则查询可能只会返回部分结果,直到日志引入完成。
可以在 Microsoft Azure 门户中查询非活动区域的主工作区,如审核非活动工作区中所述。
主工作区运行状况
需要检查两个重要的运行状况项,以便准备切换回主工作区:
- 确认主工作区和区域没有未处理的服务运行状况通知。
- 确认主工作区正在按预期引入日志和处理查询。
有关如何在次要工作区处于活动状态时查询主工作区并绕过将请求重新路由到次要工作区的示例,请参阅审核非活动工作区。
触发切回
切回过程将会更新 DNS 记录。 当 DNS 记录更新后,所有客户端可能需要一段时间才能接收更新的 DNS 设置并恢复路由到主工作区。
若要切换回次要工作区,请使用以下 POST 命令:
POST
https://management.azure.com/subscriptions/<subscription_id>/resourceGroups/<resourcegroup_name>/providers/Microsoft.OperationalInsights/workspaces/<workspace_name>/failback?api-version=2023-01-01-preview
其中:
-
<subscription_id>:与工作区相关的订阅 ID。 -
<resourcegroup_name>- 包含工作区资源的资源组。 -
<workspace_name>:切回期间要切换到的工作区的名称。
POST 命令是一项长时间运行的操作,可能需要一些时间才能完成。 成功的调用将返回 202 状态代码。 可以跟踪请求的预配状态,如检查请求预配状态中所述。
审核非活动工作区
默认情况下,工作区的活动区域是指在其中创建工作区的位置,非活动区域是次要区域,其中 Azure Monitor 会创建复制的工作区。
触发故障转移时,它会切换,即次要区域会被激活,主要区域变为非活动状态。 假设它处于非活动状态,因为它不是日志引入和查询请求的直接目标。
在区域之间切换之前,查询非活动区域非常有用,这可以验证非活动区域中的工作区是否具有希望在那里看到的日志。
查询非活动区域
若要查询非活动区域中的日志数据,请使用以下 GET 命令:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=<query>×pan=<timespan-in-ISO8601-format>&overrideWorkspaceRegion=<primary|secondary>
例如,若要在次要区域中运行简单的查询,例如过去一天的 Perf | count,请使用:
GET
api.loganalytics.azure.com/v1/workspaces/<workspace id>/query?query=Perf%20|%20count×pan=P1D&overrideWorkspaceRegion=secondary
可以通过检查 LAQueryLogs 表中的这些字段来确认 Azure Monitor 在预期区域中运行查询,该表是在你在 Log Analytics 工作区中启用查询审核时创建的:
-
isWorkspaceInFailover:指示工作区在查询期间是否处于切换模式。 数据类型为布尔值(True、False)。 -
workspaceRegion:查询针对的工作区区域。 数据类型为字符串。
使用查询监视工作区性能
建议使用本部分中的查询来创建警报规则,以通知你可能出现的工作区运行状况或性能问题。 但是,你应该慎重作出切换的决定,它不应自动完成。
在查询规则中,可以定义一个条件,以便在达到指定的违规次数之后切换到次要工作区。 有关详细信息,请参阅创建或编辑日志搜索警报规则。
工作区性能的两个重要衡量指标为引入延迟和引入量。 以下部分将探讨这些监视选项。
监视端到端引入延迟
引入延迟测量将日志引入工作区所需的时间。 时间测量从最初记录的事件发生时开始,到日志存储在工作区时结束。 总引入延迟由两个部分组成:
- 代理延迟:代理报告事件所需的时间。
- 引入管道(后端)延迟:引入管道处理日志并将其写入工作区所需的时间。
不同的数据类型具有不同的引入延迟。 可以单独测量每种数据类型的引入,也可以为所有类型创建一个通用查询,并针对更为重要的特定类型进行更精细的查询。 建议测量引入延迟的第 90 百分位数,这比平均值或第 50 百分位数(中位数)更敏感。
以下部分演示如何使用查询来检查工作区的引入延迟。
评估特定表的基线引入延迟
首先,确定特定表在几天内的基线延迟。
此示例查询将在性能表上创建引入延迟的第 90 百分位数的图表:
// Assess the ingestion latency baseline for a specific data type
Perf
| where TimeGenerated > ago(3d)
| project TimeGenerated,
IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize LatencyIngestion90Percentile=percentile(IngestionDurationSeconds, 90) by bin(TimeGenerated, 1h)
| render timechart
运行查询后,请查看结果和呈现的图表,以确定该表的预期延迟。
监视和警报当前引入延迟
为特定表建立基线引入延迟后,根据短时间内延迟的变化为该表创建日志搜索警报规则。
此查询计算过去 20 分钟内的引入延迟:
// Track the recent ingestion latency (in seconds) of a specific table
Perf
| where TimeGenerated > ago(20m)
| extend IngestionDurationSeconds = (ingestion_time()-TimeGenerated)/1s
| summarize Ingestion90Percent_seconds=percentile(IngestionDurationSeconds, 90)
由于预期会出现一些波动,因此请创建警报规则条件来检查查询返回的值是否明显大于基线。
确定引入延迟的来源
如果你注意到总引入延迟正在上升,则可以使用查询来确定延迟的来源是代理还是引入管道。
此查询分别绘制代理和管道的第 90 百分位数延迟:
// Assess agent and pipeline (backend) latency
Perf
| where TimeGenerated > ago(1h)
| extend AgentLatencySeconds = (_TimeReceived-TimeGenerated)/1s,
PipelineLatencySeconds=(ingestion_time()-_TimeReceived)/1s
| summarize percentile(AgentLatencySeconds,90), percentile(PipelineLatencySeconds,90) by bin(TimeGenerated,5m)
| render columnchart
注意
尽管图表将第 90 百分位数据显示为堆积柱形图,但两个图表中的数据总和不等于总引入的第 90 百分位数。
监视引入量
引入量测量有助于识别工作区的总引入量或特定于表的引入量的意外更改。 查询量测量可帮助识别日志引入的性能问题。 一些有用的引入量测量包括:
- 每个表的总引入量
- 恒定引入量(停止)
- 引入异常 - 引入量中的峰值和谷值
以下部分演示如何使用查询来检查工作区的引入量。
监视每个表的总引入量
可以定义一个查询来监视工作区中每个表的引入量。 查询可以包含一个警报,用于检查总引入量或特定于表的引入量的意外更改。
此查询计算过去一小时内每个表的总引入量,单位为兆字节每秒 (MBs):
// Calculate total ingestion volume over the past hour per table
Usage
| where TimeGenerated > ago(1h)
| summarize BillableDataMB = sum(_BilledSize)/1.E6 by bin(TimeGenerated,1h), DataType
检查引入是否停止
如果通过代理引入日志,则可以使用代理程序检测信号来检测连接。 静止的检测信号可以显示日志停止引入到工作区。 当查询数据显示引入停止时,可以定义触发所需响应的条件。
以下查询检查代理程序检测信号以检测连接问题:
// Count agent heartbeats in the last ten minutes
Heartbeat
| where TimeGenerated>ago(10m)
| count
监视引入异常
可以通过各种方式识别工作区引入量数据的峰值和谷值。 使用 series_decompose_anomalies() 函数从在工作区中监视的引入量中提取异常,或创建自己的异常检测器来支持独特的工作区方案。
使用 series_decompose_anomalies 识别异常
series_decompose_anomalies() 函数可识别一系列数据值中的异常。 此查询计算 Log Analytics 工作区中每个表的每小时引入量,并使用 series_decompose_anomalies() 来识别异常:
// Calculate hourly ingestion volume per table and identify anomalies
Usage
| where TimeGenerated > ago(24h)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| summarize
Timestamp=make_list(TimeGenerated),
IngestionVolumeMB=make_list(IngestionVolumeMB)
by DataType
| extend series_decompose_anomalies(IngestionVolumeMB)
| mv-expand
Timestamp,
IngestionVolumeMB,
series_decompose_anomalies_IngestionVolumeMB_ad_flag,
series_decompose_anomalies_IngestionVolumeMB_ad_score,
series_decompose_anomalies_IngestionVolumeMB_baseline
| where series_decompose_anomalies_IngestionVolumeMB_ad_flag != 0
有关如何使用 series_decompose_anomalies() 来检测日志数据中的异常的详细信息,请参阅使用 Azure Monitor 中的 KQL 机器学习功能检测和分析异常。
创建自己的异常检测器
可以创建自定义异常检测器以支持工作区配置的方案要求。 本部分提供了一个演示此过程的示例。
以下查询计算:
- 预期引入量:每小时,按表(基于中位数,但你可以自定义逻辑)
- 实际引入量:每小时,按表
为了过滤掉预期引入量和实际引入量之间的微小差异,查询将应用两个筛选器:
- 变化率:超出预期引入量 150% 或低于预期引入量 66%,每个表
- 变化量:指示增加或减少的引入量是否超过该表每月引入量的 0.1%
// Calculate expected vs actual hourly ingestion per table
let TimeRange=24h;
let MonthlyIngestionByType=
Usage
| where TimeGenerated > ago(30d)
| summarize MonthlyIngestionMB=sum(Quantity) by DataType;
// Calculate the expected ingestion volume by median of hourly medians
let ExpectedIngestionVolumeByType=
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionMedian=percentile(Quantity, 50) by bin(TimeGenerated, 1h), DataType
| summarize ExpectedIngestionVolumeMB=percentile(IngestionMedian, 50) by DataType;
Usage
| where TimeGenerated > ago(TimeRange)
| project TimeGenerated, DataType, Quantity
| summarize IngestionVolumeMB=sum(Quantity) by bin(TimeGenerated, 1h), DataType
| join kind=inner (ExpectedIngestionVolumeByType) on DataType
| extend GapVolumeMB = round(IngestionVolumeMB-ExpectedIngestionVolumeMB,2)
| where GapVolumeMB != 0
| extend Trend=iff(GapVolumeMB > 0, "Up", "Down")
| extend IngestedVsExpectedAsPercent = round(IngestionVolumeMB * 100 / ExpectedIngestionVolumeMB, 2)
| join kind=inner (MonthlyIngestionByType) on DataType
| extend GapAsPercentOfMonthlyIngestion = round(abs(GapVolumeMB) * 100 / MonthlyIngestionMB, 2)
| project-away DataType1, DataType2
// Determine whether the spike/deep is substantial: over 150% or under 66% of the expected volume for this data type
| where IngestedVsExpectedAsPercent > 150 or IngestedVsExpectedAsPercent < 66
// Determine whether the gap volume is significant: over 0.1% of the total monthly ingestion volume to this workspace
| where GapAsPercentOfMonthlyIngestion > 0.1
| project
Timestamp=format_datetime(todatetime(TimeGenerated), 'yyyy-MM-dd HH:mm:ss'),
Trend,
IngestionVolumeMB,
ExpectedIngestionVolumeMB,
IngestedVsExpectedAsPercent,
GapAsPercentOfMonthlyIngestion
监视查询成功和失败
每个查询都会返回指示成功或失败的响应代码。 查询失败时,响应还包括错误类型。 大量错误可能表明工作区可用性或服务性能存在问题。
此查询计算返回服务器错误代码的查询数:
// Count query errors
LAQueryLogs
| where ResponseCode>=500 and ResponseCode<600
| count