使用 DISKSPD 测试工作负荷存储性能
适用于:Azure Stack HCI 版本 22H2 和 21H2;Windows Server 2022、Windows Server 2019
重要
Azure Stack HCI 现在是 Azure 本地的一部分。 产品文档重命名正在进行中。 但是,旧版 Azure Stack HCI(例如 22H2)将继续引用 Azure Stack HCI,不会反映名称更改。 了解详细信息。
本主题提供有关如何使用 DISKSPD 测试工作负荷存储性能的指导。 你已设置 Azure Stack HCI 群集,一切都准备就绪。 很好,但你如何知道你得到的是不是所承诺的性能指标(不管它是延迟、吞吐量还是 IOPS)? 这种情况下,你可能需要使用 DISKSPD。 阅读本主题后,你就会知道如何运行 DISKSPD、了解参数子集、解释输出,并大致了解影响工作负荷存储性能的变量。
什么是 DISKSPD?
DISKSPD 是一个可生成 I/O 的命令行工具,用于微基准测试。 很好,那么,所有这些术语的含义是什么呢? 任何人设置 Azure Stack HCI 群集或物理服务器都有一个理由, 例如设置 Web 托管环境,或为员工运行虚拟桌面。 不管实际用例是什么,都很可能需要在部署实际应用程序之前进行模拟测试。 但是,在实际方案中测试应用程序通常很困难,这就需要用到 DISKSPD。
DISKSPD 是一种可自定义的工具,用于创建你自己的合成工作负荷,以及在部署前测试应用程序。 此工具很棒的一项功能是允许你自由地配置和调整参数,以创建类似于实际工作负荷的特定方案。 DISKSPD 可让你在部署之前大致了解系统的功能。 DISKSPD 的核心功能就是发出一系列读写操作。
现在你知道什么是 DISKSPD 了,但你应何时使用它呢? DISKSPD 难以模拟复杂的工作负荷, 但当单线程文件复制不能近似地模拟你的工作负荷,而你需要一种简单的、能够产生可接受基线结果的工具时,DISKSPD 就很有用。
快速入门:安装并运行 DISKSPD
要安装和运行 DISKSPD,请在管理电脑上以管理员身份打开 PowerShell,然后执行以下步骤:
要下载并展开 DISKSPD 工具的 ZIP 文件,请运行以下命令:
# Define the ZIP URL and the full path to save the file, including the filename $zipName = "DiskSpd.zip" $zipPath = "C:\DISKSPD" $zipFullName = Join-Path $zipPath $zipName $zipUrl = "https://github.com/microsoft/diskspd/releases/latest/download/" +$zipName # Ensure the target directory exists, if not then create if (-Not (Test-Path $zipPath)) { New-Item -Path $zipPath -ItemType Directory | Out-Null } # Download and expand the ZIP file Invoke-RestMethod -Uri $zipUrl -OutFile $zipFullName Expand-Archive -Path $zipFullName -DestinationPath $zipPath要将 DISKSPD 目录添加到
$PATH环境变量,请运行以下命令:$diskspdPath = Join-Path $zipPath $env:PROCESSOR_ARCHITECTURE if ($env:path -split ';' -notcontains $diskspdPath) { $env:path += ";" + $diskspdPath }使用以下 PowerShell 命令运行 DISKSPD。 将方括号替换为相应的设置。
diskspd [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]以下是你可以运行的示例命令:
diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txt注意
如果没有测试文件,请使用 -c 参数创建一个。 如果使用此参数,请确保在定义路径时包含测试文件名, 例如 [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat。 在示例命令中,IO.dat 是测试文件的名称,test01.txt 是 DISKSPD 输出文件名。
指定密钥参数
上面的操作很简单,是不是? 不幸的是,事情远不止于此。 让我们分析一下刚才的操作。 首先,有多个可以调整的参数,你可以将这些参数具体化。 但是,我们使用了以下基准参数集:
注意
DISKSPD 参数区分大小写。
-t2:表示每个目标/测试文件的线程数。 此数字通常基于 CPU 核心数。 在此示例中,使用了两个线程对所有 CPU 核心施加压力。
-o32:表示每个线程的每个目标的未完成 I/O 请求数, 也称为队列深度。在此示例中,使用了 32 对 CPU 施加压力。
-b4K:表示块大小(以字节、KiB、MiB 或 GiB为单位)。 在此示例中,使用了 4K 块大小来模拟随机 I/O 测试。
-r4K:表示与指定大小(以字节、KiB、MiB、Gib 或块为单位)对应的随机 I/O(替代 -s 参数)。 使用常用的 4K 字节大小以便与块大小正确对应。
-w0:指定属于写入请求的操作的百分比(-w0 等效于 100% 读取)。 在此示例中,我们使用了 0% 的写入,以便简化测试。
-d120:指定测试的持续时间,不包括冷却或预热。 默认值为 10 秒,但对于任何繁重的工作负荷,建议至少使用 60 秒。 在此示例中,我们使用了 120 秒来最大程度地减少离群值。
-Suw:禁用软件和硬件写入缓存(等效于 -Sh)。
-D:捕获 IOPS 统计信息(例如标准偏差),时间间隔为毫秒(单线程单目标)。
-L:度量延迟统计信息。
-c5g:设置测试中使用的示例文件大小。 可以按字节、KiB、MiB、GiB 或块进行设置。 在此示例中,我们使用了一个 5 GB 的目标文件。
如需参数的完整列表,请参阅 GitHub 存储库。
了解环境
性能严重依赖于环境。 那么,我们的环境是什么样的呢? 我们的规范涉及一个带有存储池和存储空间直通 (S2D) 的 Azure Stack HCI 群集。 更具体地说,有五个 VM:DC、node1、node2、node3 和管理节点。 群集本身是一个带有三向镜像复原结构的三节点群集。 因此,会保留三个数据副本。 群集中的每个“节点”都是一个Standard_B2ms VM,最大 IOPS 限制为 1920。 在每个节点中,有四个高级 P30 SSD 驱动器,其最大 IOPS 限制为 5000。 最后,每个 SSD 驱动器都有 1 TB 的内存。
你在群集共享卷 (CSV) 提供的统一命名空间 (C:\ClusteredStorage) 中生成测试文件,以便使用整个驱动器池。
注意
示例环境没有 Hyper-V 或嵌套虚拟化结构。
如你所见,在存在 VM 或驱动器限制的情况下单独地达到 IOPS 或带宽上限是完全可能的。 因此,了解你的 VM 大小和驱动器类型非常重要,因为两者都有最大 IOPS 限制和带宽上限。 知道这一点有助于找出瓶颈并了解性能结果。 若要详细了解适合你的工作负荷的大小,请参阅以下资源:
了解输出
了解参数和环境后,就可以解释输出了。 首先,之前的测试的目标是在不考虑延迟的情况下将 IOPS 最大化。 这样,就可以在 Azure 中直观地查看是否达到人工 IOPS 限制。 若要以图形方式直观显示总 IOPS,请使用 Windows Admin Center 或任务管理器。
下图显示了 DISKSPD 流程在我们的示例环境中的外观。 它显示了一个来自非协调器节点的 1 MiB 写入操作的示例。 三向复原结构加上非协调器节点的操作会导致两个网络跃点,降低性能。 如果想知道什么是协调器节点,别急! 我们会在注意事项部分介绍它。 红色方块表示 VM 和驱动器瓶颈。

现在,你已经有了直观的了解,接下来我们来看一下 .txt 文件输出的四个主要部分:
输入设置
此部分介绍你运行的命令、输入参数以及有关测试运行的其他详细信息。
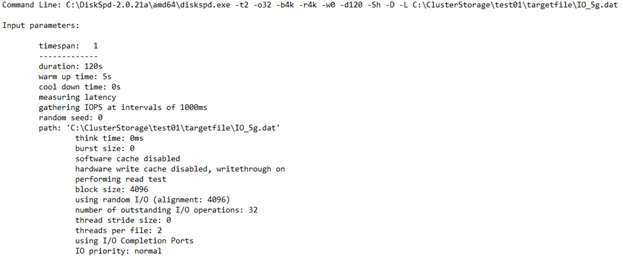
CPU 使用率详细信息
此部分重点介绍测试时间、线程数、可用处理器数,以及测试期间每个 CPU 核心的平均使用率等信息。 在此示例中,有两个 CPU 核心的平均使用率大约为 4.67%。
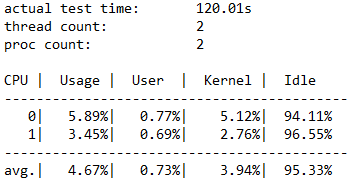
总 I/O
此部分有三个子部分。 第一部分重点介绍包括读取和写入操作在内的总体性能数据。 第二部分和第三部分将读取和写入操作拆分成单独的类别。
在此示例中,可以看到在 120 秒的持续时间内的总 I/O 计数为 234408。 因此,IOPS = 234408/120 = 1953.30。 平均延迟为 32.763 毫秒,吞吐量为 7.63 MiB/秒。 根据上面的叙述,我们知道,1953.30 IOPS 接近 Standard_B2ms VM 的 1920 IOPS 限制。 不相信? 如果使用不同的参数(例如增加队列深度的参数)重新运行此测试,你会发现结果的上限仍然是该数字。
最后三列显示 IOPS 的标准偏差(17.72,来自 -D 参数)、延迟的标准偏差(20.994 毫秒,来自 -L 参数)和文件路径。
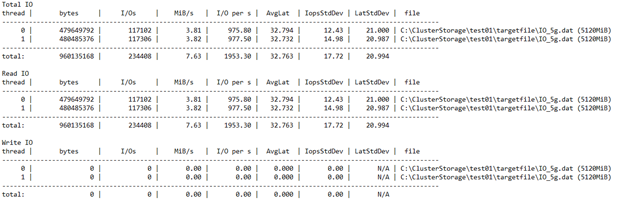
你可以根据结果快速确定群集配置是否适当。 你可以看到,它在达到 SSD 限制 5000 之前达到了 VM 限制 1920。 如果受到 SSD 而非 VM 的限制,则可在多个驱动器中跨测试文件利用最多 20000 IOPS(4 个驱动器 * 5000)。
最终,你需要确定哪些值对于你的特定工作负荷来说是可以接受的。 下图显示了一些重要的关系,在进行权衡时需要考虑到这些关系:
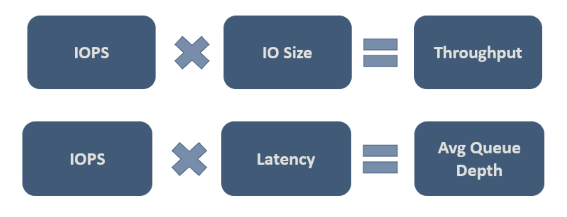
图中的第二个关系很重要,有时也称为利特尔法则。 此法则引入的理念是:可以通过三项特征来控制流程行为,只需更改其中一项特征即可影响另外两项特征,进而影响整个流程。 因此,如果你对系统性能不满意,则可通过三个自由维度来影响它。 利特尔法则规定,在我们的示例中,IOPS 是“吞吐量”(每秒输入输出操作数),延迟是“队列时间”,队列深度是“清单”。
延迟百分位分析
这最后一部分按操作类型对存储性能的百分位延迟从最小值到最大值进行了详细说明。
此部分很重要,因为它决定 IOPS 的“质量”。 它揭示了多少个 I/O 操作能够达到某个延迟值。 由你决定该百分位的可接受延迟。
另外,下图中的“个 9”指 9 的数目。 例如,“3 个 9”等效于 99.9% 百分位。 9 的数目揭示在该百分位运行的 I/O 操作数。 最终你会发现,当 9 的数目增加到一定程度时,其对延迟值的影响就没有什么不同了。 在此示例中,可以看到延迟值在“4 个 9”之后保持不变。 此时,延迟值仅基于 234408 个操作中的一个 I/O 操作。






注意事项
开始使用 DISKSPD 后,若要获取实际测试结果,还需要考虑几个事项。 其中包括密切关注所设置的参数、存储空间运行状况和变量、CSV 所有权,以及 DISKSPD 与文件复制之间的差异。
DISKSPD 与实际情况
DISKSPD 的人工测试为你的实际工作负载提供相对来说具有可比性的结果。 但是,你需要密切注意所设置的参数以及这些参数是否与实际情况相符。 必须明白,合成工作负载无法完美地代表部署期间应用程序的实际工作负载。
准备工作
在运行 DISKSPD 测试之前,建议执行一些操作。 其中包括:验证存储空间的运行状况、检查资源使用情况以确保其他程序不会影响测试,以及在需要收集其他数据的情况下准备好性能管理器。 但是,由于本主题的目标是让 DISKSPD 能够快速运行,因此不会深入探讨这些操作。 若要了解详细信息,请参阅在 Windows Server 中使用综合工作负载测试存储空间性能。
影响性能的变量
存储性能的调控很微妙。 换句话说,有许多因素会影响性能。 因此,你可能会遇到不合预期的值。 下面以列表形式重点介绍了一些影响性能的变量,尽管此列表并不详尽:
- 网络带宽
- 复原能力选择
- 存储磁盘配置:NVME、SSD、HDD
- I/O 缓冲区
- 缓存
- RAID 配置
- 网络跃点
- 硬盘驱动器主轴转速
CSV 所有权
节点称为卷所有者或协调器节点(非协调器节点是不拥有特定卷的节点)。 为每个标准卷分配一个节点,其他节点可以通过网络跃点访问此标准卷,这会导致性能下降(延迟增高)。
类似地,群集共享卷 (CSV) 也有一个“所有者”。 但是,之所以说 CSV 是“动态的”,是因为它会在每次重启系统 (RDP) 时尝试更改所有权。 因此,请务必确认 DISKSPD 是从拥有 CSV 的协调器节点运行的。 否则,可能需要手动更改 CSV 所有权。
若要确认 CSV 所有权,请执行以下操作:
通过运行以下 PowerShell 命令来检查所有权:
Get-ClusterSharedVolume如果 CSV 所有权不正确(例如,你在 Node1 上,但 Node2 拥有 CSV),则请运行以下 PowerShell 命令,将 CSV 移到正确的节点:
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
文件复制与DISKSPD
有些人认为,可以通过复制并粘贴一个超大的文件并度量该过程所花的时间来“测试存储性能”。 使用此方法的主要原因很可能是因为它简单快捷。 这种想法并没有错,因为它可以测试特定工作负载,但你很难将此方法归类为“测试存储性能”的方法。
如果你的实际目标是测试文件复制性能,那么你可以理所当然地使用此方法。 但是,如果你的目标是度量存储性能,建议你不要使用此方法。 你可以将文件复制过程视为使用一组特定于文件服务的不同“参数”(例如队列、并行化等)。
下面的简短摘要说明了为什么使用文件复制来度量存储性能可能无法提供你所期望的结果:
文件复制可能未经过优化。会出现两个级别的并行度,一个是内部的,另一个是外部的。 在内部,如果文件复制针对的是远程目标,则 CopyFileEx 引擎会应用某种程度的并行化。 在外部,可以通过不同的方式来调用 CopyFileEx 引擎。 例如,从文件资源管理器进行的复制是单线程的,而 Robocopy 是多线程的。 出于这些原因,请务必了解测试的影响是否是你所预期的。
每项复制都有两个端。 复制和粘贴文件时,你可能正在使用两个磁盘:源磁盘和目标磁盘。 如果一个磁盘的速度比另一个磁盘慢,你其实是度量速度较慢的磁盘的性能。 此外还有其他情况,在这些情况下,源、目标和复制引擎之间的通信可能会以独特方式影响性能。
若要了解详细信息,请参阅使用文件复制度量存储性能。
试验和常见工作负荷
此部分包含一些其他示例、试验和工作负荷类型。
确认协调器节点
如前所述,如果你当前正在测试的 VM 不拥有 CSV,那么与节点拥有 CSV 时进行测试相比,你将发现性能(IOPS、吞吐量和延迟)下降。 原因在于,每次你发出 I/O 操作时,系统都会创建一个针对协调器节点的网络跃点来执行该操作。
对于采用三节点和三向镜像的情况,写入操作始终会创建一个网络跃点,因为它需要在三个节点上的所有驱动器上存储数据。 因此,写入操作无论如何都会创建一个网络跃点。 但是,如果你使用另一复原结构,则可能会改变这种情况。
下面是一个示例:
- 在本地节点上运行: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
- 在非本地节点上运行: diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
在此示例中,你可以在下图的结果中清楚地看到:当协调器节点拥有 CSV 时,延迟降低、IOPS 增加且吞吐量增加。

联机事务处理 (OLTP) 工作负荷
联机事务处理 (OLTP) 工作负荷查询(更新、插入、删除)侧重于面向事务的任务。 与联机分析处理 (OLAP) 相比,OLTP 属于存储延迟依赖型。 由于每个操作发出的 I/O 很少,你所关心的是每秒可以承受的操作数。
可以设计一个 OLTP 工作负荷测试来重点关注随机的小规模 I/O 的性能。 对于这些测试,请重点关注你可以在多大程度上提高吞吐量,同时又能将延迟保持在可接受的程度。
此工作负荷测试的基本设计选择应该至少包括:
- 8 KB 块大小 => 类似于 SQL Server 用于其数据文件的页大小
- 70% 读取,30% 写入 => 类似于典型 OLTP 行为
联机分析处理 (OLAP) 工作负荷
OLAP 工作负荷着重于数据检索和分析,使用户能够执行复杂的查询来提取多维数据。 不同于 OLTP,这些工作负荷不会区分存储延迟。 它们着重于如何将多个操作排队,不太在意带宽。 因此,OLAP 工作负荷常常会导致处理时间延长。
可以设计一个 OLAP 工作负荷测试来重点关注按顺序的大规模 I/O 的性能。 对于这些测试,请重点关注每秒处理的数据量,而不是 IOPS 数。 延迟要求的重要性也降低了,但这带有主观性。
此工作负荷测试的基本设计选择应该至少包括:
512 KB 块大小 => 类似于当 SQL Server 使用预读技术为表扫描加载一个包含 64 个数据页面的批次时的 I/O 大小。
每个文件 1 个线程 => 当前需要将测试限制为每个文件一个线程,因为测试多个顺序线程时可能会在 DISKSPD 中出现问题。 如果使用多个线程(如两个)和 -s 参数,则线程会以不确定的方式开始在同一位置发出基于彼此的 I/O 操作。 这是因为它们各自跟踪自己的顺序偏移。
可通过两种“解决方案”来解决此问题:
第一种解决方案涉及使用 -si 参数。 在此参数中,两个线程共享单个互锁偏移,以便线程以协作方式向目标文件发出单一顺序模式的访问。 因此,不能对文件中的一个点多次进行操作。 不过,由于它们在向队列发出 I/O 操作时仍会相互争用以,因此这些操作可能不会按顺序到达。
如果一个线程变得受 CPU 限制,则此解决方案可正常工作。 你可能需要在另一个 CPU 核心上使用另一个线程向 CPU 系统提供更多的存储 I/O,进一步使其饱和。
第二种解决方案涉及使用 -T<offset>。 它允许你指定不同线程在同一目标文件上执行的 I/O 操作之间的偏移大小(I/O 之间的间隔)。 例如,线程一开始的偏移量通常为 0,但你可以按照此规范将两个线程分开一段距离,使它们不会相互重叠。 在任何多线程环境中,线程可能会位于工作目标的不同部分,这是模拟该情况的一种方法。
后续步骤
有关优化复原能力设置的详细信息和详细示例,另请参阅: