Azure Stack HCI 和 Windows Server 群集中的容错和存储效率
适用于:Azure Stack HCI 版本 22H2 和 21H2;Windows Server 2022、Windows Server 2019
重要
Azure Stack HCI 现在是 Azure 本地的一部分。 产品文档重命名正在进行中。 但是,旧版 Azure Stack HCI(例如 22H2)将继续引用 Azure Stack HCI,不会反映名称更改。 了解详细信息。
本文介绍可用的复原选项,并概述其规模要求、存储效率以及每个选项的一般优势和弊端。
概述
存储空间直通为数据提供容错,通常称为“复原”。 其实现方式类似于 RAID,但分布在不同的服务器中,并在软件中实现。
如同 RAID,存储空间可通过多种不同的方法实现其功能,这些方法在容错、存储效率和计算复杂性方面各有利弊。 概括而言,这些方法分为两大类别:“镜像”和“奇偶校验”,后者有时称为“擦除编码”。
镜像
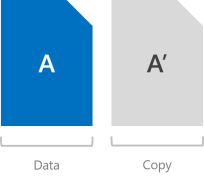
镜像功能通过保存所有数据的多个副本来提供容错。 它非常类似于 RAID-1。 该数据的条带化和放置方式非常重要(请参阅此博客以了解详细信息),但可以肯定的是,使用镜像存储的任何数据都是以其完整形式多次写入的。 每个副本将写入不同的物理硬件(位于不同服务器中的不同驱动器),假设每个硬盘各自都有可能发生故障。
可选择两种形式的镜像 -“双向”和“三向”。
双向镜像
双向镜像写入所有内容的两个副本。 其存储效率为 50% – 若要写入 1 TB 的数据,至少需要 2 TB 物理存储容量。 同理,至少需要两个硬件“容错域”– 使用存储空间直通时,这意味着需要两台服务器。
警告
如果你有两台以上的服务器,我们建议改用三向镜像。
三向镜像
三向镜像写入所有内容的三个副本。 其存储效率为 33.3% – 若要写入 1 TB 的数据,至少需要 3 TB 物理存储容量。 同理,至少需要三个硬件容错域 – 使用存储空间直通时,这意味着需要三台服务器。
三向镜像可以安全承受至少两个硬件(驱动器或服务器)同时出现问题。 例如,如果你正在重新启动一台服务器,此时另一个驱动器或服务器突然发生故障,在这种情况下,所有数据将保持安全,可供持续访问。

奇偶校验
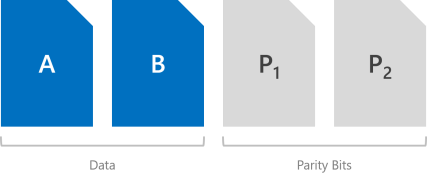
奇偶校验编码(通常称为“擦除编码”)提供使用按位算术的容错,它可能会变得相当复杂。 相比于镜像,此方法的工作原理较为隐晦,但有许多极佳的在线资源(例如,此第三方擦除编码入门指南)可帮助你了解其思路。 简单而言,它可以提供更好的存储效率,且不影响容错能力。
存储空间提供两种形式的奇偶校验 – “单一”奇偶校验和“双重”奇偶校验,后者大规模运用称作“局部重建代码”的先进技术。
重要
我们建议对大多数性能敏感型工作负荷使用镜像。 有关如何根据工作负荷均衡性能和容量的详细信息,请参阅规划卷。
单一奇偶校验
单一奇偶校验只保留一个按位奇偶校验符号,每次只能针对一次故障提供容错。 此方法非常类似于 RAID-5。 若要使用单一奇偶校验,至少需要三个硬件容错域 – 使用存储空间直通时,这意味着需要三台服务器。 由于三向镜像能够以相同的规模提供更高的容错,因此我们不建议使用单一奇偶校验。 但如果坚持使用它,它是完全受支持的。
警告
我们之所以不建议使用单一奇偶校验,是因为它每次只能安全承受一次硬件故障:如果另一驱动器或服务器突然发生故障时重新启动某一台服务器,则会遇到停机。 如果你只有三台服务器,我们建议使用三向镜像。 如果你有四台或更多服务器,请参阅下一部分。
双重奇偶校验
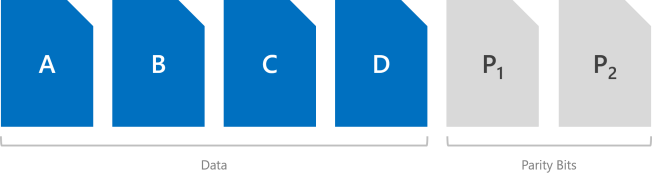
双重奇偶校验运行 Reed-Solomon 纠错代码,以保留两个按位奇偶校验符号,因此提供与三向镜像相同的容错(即,每次最多可以承受两次故障),但其存储效率更高。 此方法非常类似于 RAID-6。 若要使用双重奇偶校验,至少需要四个硬件容错域 – 使用存储空间直通时,这意味着需要四台服务器。 在这种规模下,存储效率为 50% – 若要存储 2 TB 数据,需要 4 TB 物理存储容量。
双重奇偶校验的存储效率随着硬件容错域数的增加而提高,可从 50% 提高到 80%。 例如,使用七个容错域时(使用存储空间直通时,这意味着需要七台服务器),效率将激增到 66.7% – 若要存储 4 TB 数据,只需要 6 TB 物理存储容量。
请参阅摘要部分,了解每种规模下的双重奇偶校验效率和局部重建代码。
局部重建代码
存储空间引入了由 Microsoft Research 开发的先进技术“局部重建代码”(LRC)。 规模较大时,双重奇偶校验会使用 LRC 将其编码/解码拆分成一些较小的组,以降低进行写入或从故障中恢复所需的开销。
使用机械硬盘 (HDD) 时,组的大小为四个符号;使用固态硬盘 (SSD) 时,组的大小为六个符号。 例如,下面是使用机械硬盘和 12 个硬件容错域(即 12 台服务器)时的布局外观 – 有两个组,每个组为四个数据符号。 此配置可实现 72.7% 的存储效率。

我们推荐这篇由 Claus Joergensen 编写的深入但非常易读的操作演练本地重建代码如何处理各种失败方案,并且它们为什么具有吸引力。
镜像加速奇偶校验
存储空间直通卷可以是部分镜像和部分奇偶校验。 写入内容先进入镜像部分,然后逐渐移入奇偶校验部分。 实际上,这是使用镜像来加速擦除编码。
若要混合使用三向镜像和双重奇偶校验,至少需要四个容错域,即四台服务器。
镜像加速奇偶校验的存储效率介于全镜像或全奇偶校验的效率之间,并取决于所选的比例。
重要
我们建议对大多数性能敏感型工作负荷使用镜像。 有关如何根据工作负荷均衡性能和容量的详细信息,请参阅规划卷。
摘要
本部分汇总了存储空间直通中提供的复原类型、使用每种类型所要满足的最低规模要求、每个类型可承受的故障次数,以及相应的存储效率。
复原类型
| 复原能力 | 容错 | 存储效率 |
|---|---|---|
| 双向镜像 | 1 | 50.0% |
| 三向镜像 | 2 | 33.3% |
| 双重奇偶校验 | 2 | 50.0% - 80.0% |
| Mixed | 2 | 33.3% - 80.0% |
最低规模要求
| 复原能力 | 所需的最小容错域数 |
|---|---|
| 双向镜像 | 2 |
| 三向镜像 | 3 |
| 双重奇偶校验 | 4 |
| Mixed | 4 |
提示
除非使用机箱或机架容错,否则容错域数目是指服务器数目。 只要符合存储空间直通的最低要求,每台服务器中的驱动器数目就不会影响可用的复原类型。
混合部署的双重奇偶校验效率
下表显示了混合部署在每个规模下双重奇偶校验和局部重建代码的存储效率,这同时包含硬盘驱动器 (HDD) 和固态硬盘 (SSD)。
| 容错域 | 布局 | 效率 |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50.0% |
| 5 | RS 2+2 | 50.0% |
| 6 | RS 2+2 | 50.0% |
| 7 | RS 4+2 | 66.7% |
| 8 | RS 4+2 | 66.7% |
| 9 | RS 4+2 | 66.7% |
| 10 | RS 4+2 | 66.7% |
| 11 | RS 4+2 | 66.7% |
| 12 | LRC (8, 2, 1) | 72.7% |
| 13 | LRC (8, 2, 1) | 72.7% |
| 14 | LRC (8, 2, 1) | 72.7% |
| 15 | LRC (8, 2, 1) | 72.7% |
| 16 | LRC (8, 2, 1) | 72.7% |
全闪存部署的双重奇偶校验效率
下表显示了全闪存部署在每个规模下双重奇偶校验和局部重建代码的存储效率,这仅包含固态硬盘 (SSD)。 奇偶校验布局可以使用较大的组大小,并在全闪存配置中实现更好的存储效率。
| 容错域 | 布局 | 效率 |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50.0% |
| 5 | RS 2+2 | 50.0% |
| 6 | RS 2+2 | 50.0% |
| 7 | RS 4+2 | 66.7% |
| 8 | RS 4+2 | 66.7% |
| 9 | RS 6+2 | 75.0% |
| 10 | RS 6+2 | 75.0% |
| 11 | RS 6+2 | 75.0% |
| 12 | RS 6+2 | 75.0% |
| 13 | RS 6+2 | 75.0% |
| 14 | RS 6+2 | 75.0% |
| 15 | RS 6+2 | 75.0% |
| 16 | LRC (12, 2, 1) | 80.0% |
示例
除非只有两台服务器,否则我们建议使用三向镜像和/或双重奇偶校验,因为它们提供更好的容错。 具体而言,即使两个容错域(使用存储空间直通时,这意味着需要两台服务器)由于同时发生的故障而受到影响,这些方法也能确保所有数据保持安全且持续可供访问。
所有组件保持联机的示例
这六个示例演示了三向镜像和/或双重奇偶校验可以承受的故障。
- 1. 一个驱动器丢失(包括缓存驱动器)
- 2. 一台服务器丢失
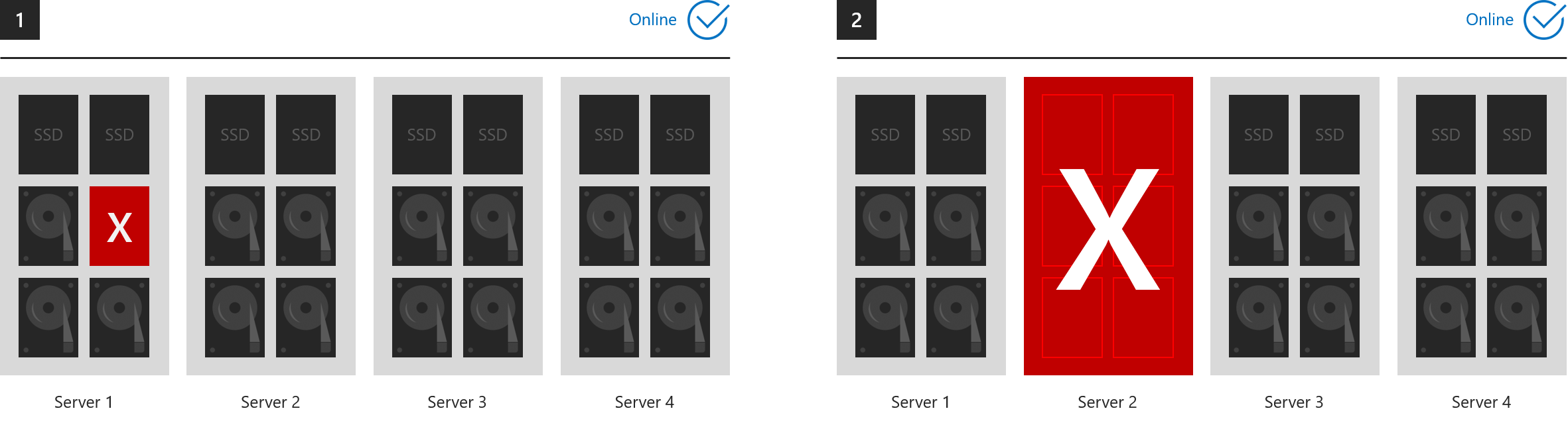
- 3. 一个服务器和一个驱动器丢失
- 4. 不同服务器中的两个驱动器丢失

- 5. 两个以上的驱动器丢失,但最多两台服务器受影响
- 6. 两台服务器丢失
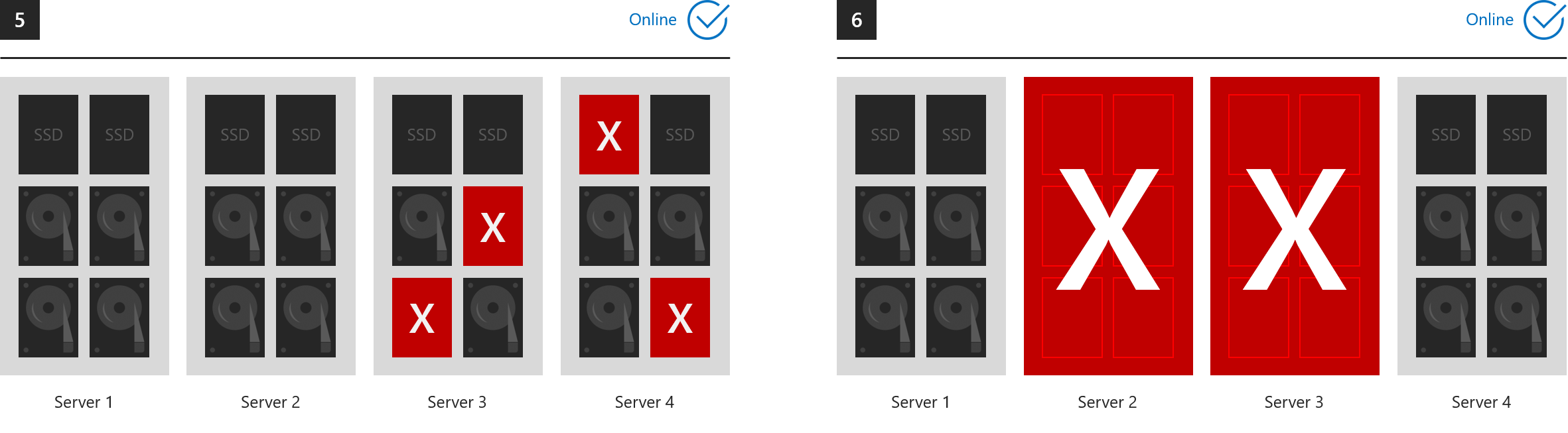
...在每种情况下,所有卷都保持联机状态。 (请确保群集中保留了仲裁。)
所有组件脱机的示例
在其生存期内,存储空间可以承受任意次数的故障,因为在时间足够的情况下,它在每次故障后能够完全复原。 但是,在任意给定时刻,最多只能有两个容错域能够受到故障影响而安全无虞。 下面是三向镜像和/或双重奇偶校验不能承受的故障示例。
- 7. 三台或更多服务器中的驱动器同时丢失
- 8. 三台或更多服务器同时丢失
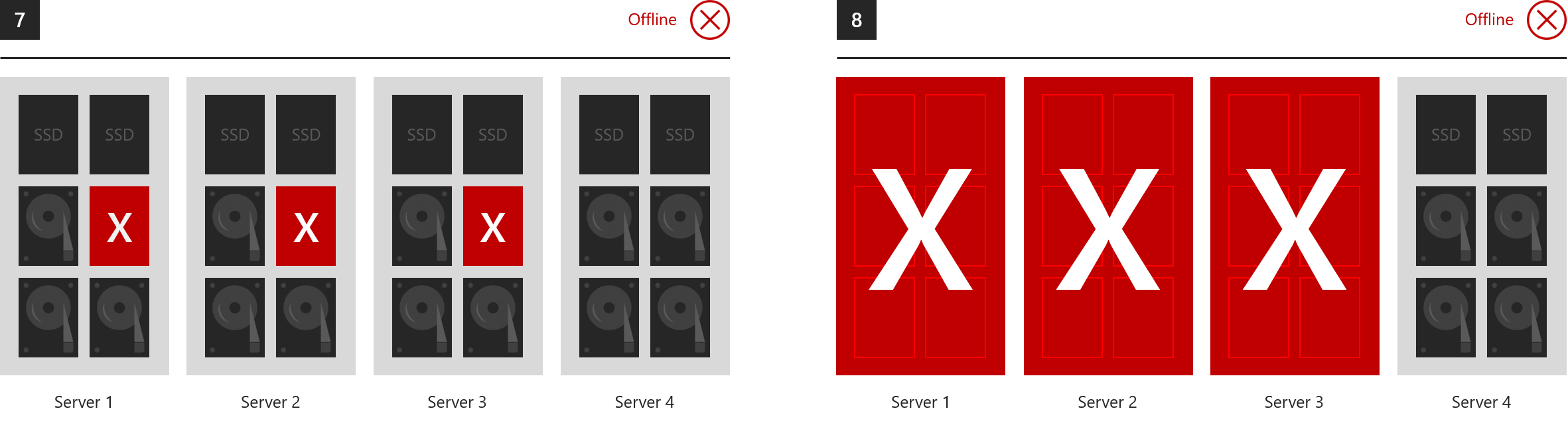
使用情况
查看创建卷。
后续步骤
有关本文中提到的主题的进一步阅读,请参阅以下内容: