你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 托管 Redis(预览版)体系结构
Azure 托管 Redis(预览版)在 Redis Enterprise 堆栈上运行,它比 Redis 社区版提供显著优势。 以下信息更详细地说明了如何构建 Azure 托管 Redis,包括对高级用户有用的信息。
重要
Azure 托管 Redis 目前以预览版提供。 有关 beta 版本、预览版或尚未正式发布的版本的 Azure 功能所适用的法律条款,请参阅 Microsoft Azure 预览版的补充使用条款。
与 Azure Cache for Redis 的比较
Azure Cache for Redis 的基本层、标准层和高级层基于 Redis 社区版构建。 此版本的 Redis 存在几个明显的限制,包括在设计上采用单线程。 这会显著降低性能,并降低缩放效率,因为更多 vCPU 未被服务充分利用。 典型的 Azure Cache for Redis 实例使用如下体系结构:
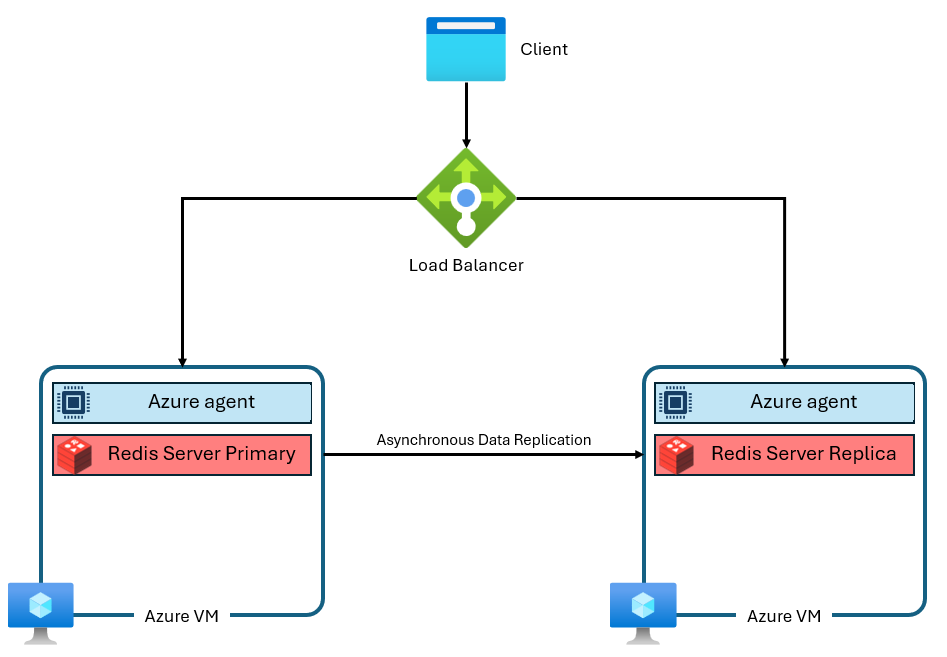
请注意,使用了两个 VM - 一个主 VM 和一个副本。 这些 VM 也称为“节点”。主节点包含主 Redis 进程并接受所有写入。 复制以异步方式执行到副本节点,以在维护、缩放或意外故障期间提供备份副本。 由于社区版 Redis 的单线程设计,每个节点只能运行单个 Redis 服务器进程。
Azure 托管 Redis 的体系结构改进
Azure 托管 Redis 使用更高级的体系结构,如下所示:
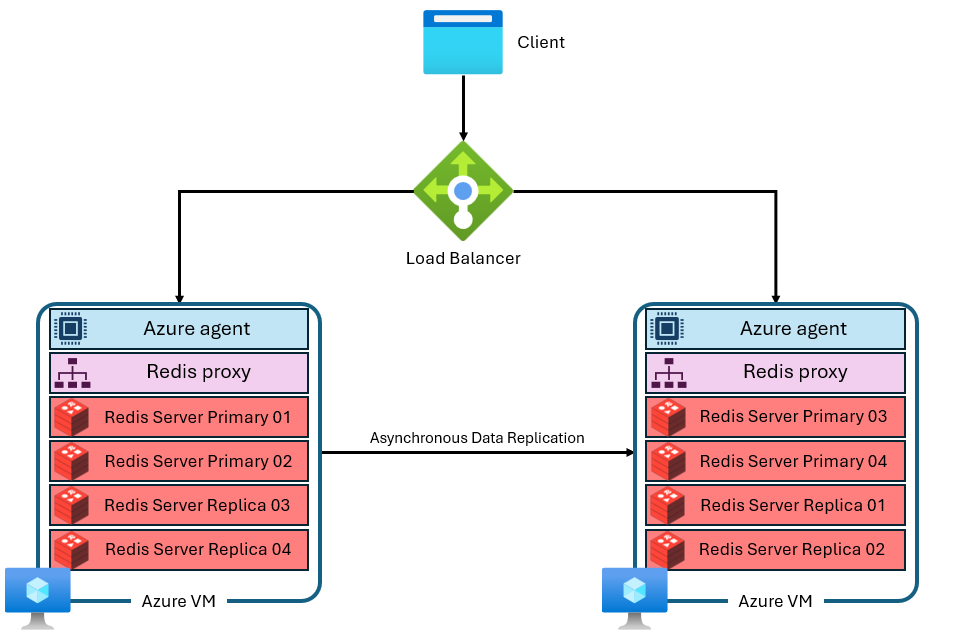
有几个区别:
- 每个虚拟机(或“节点”)并行运行多个 Redis 服务器进程(称为“分片”)。 多个分片可让系统可更高效地利用每个虚拟机上的 vCPU 并提高性能。
- 并非所有主要 Redis 分片都位于同一 VM/节点上。 相反,主分片和副本分片分布在这两种节点之间。 由于主分片使用的 CPU 资源比副本分片多,此方法使得更多的主分片可以并行运行。
- 每个节点都有一个高性能代理进程来管理分片、处理连接管理并触发自我修复。
此体系结构可实现更高的性能和高级功能,例如活动异地复制
群集
由于 Redis Enterprise 能够为每个节点使用多个分片,因此每个 Azure 托管 Redis 实例在内部配置为跨所有层和 SKU 使用聚类分析。 这包括仅设置为使用单个分片的较小实例。 聚类分析是跨多个 Redis 进程(也称为“分片”)划分 Redis 实例中的数据的一种方法。Azure 托管 Redis 提供两个群集策略,确定哪些协议可供 Redis 客户端用于连接到缓存实例。
群集策略
Azure 托管 Redis 提供两种群集策略选择:OSS 和 Enterprise。 对于大多数应用程序,建议使用 OSS 群集策略,因为它支持更高的最大吞吐量,但每个版本都有优缺点。
OSS 群集策略实现与社区版 Redis 相同的 Redis 群集 API。 Redis 群集 API 允许 Redis 客户端直接连接到每个 Redis 节点上的分片,最大限度地减少延迟并优化网络吞吐量,从而使吞吐量能够在分片和 vCPU 数量增加时以接近线性方式缩放。 OSS 群集策略通常提供最佳的延迟和吞吐量性能。 但是,OSS 群集策略要求客户端库支持 Redis 群集 API。 目前,几乎所有 Redis 客户端都支持 Redis 群集 API,但较旧客户端版本或专用库可能存在兼容性问题。 OSS 群集策略也不能与 RediSearch 模块一起使用。
Enterprise 群集策略是一种更简单的配置,它将单个终结点用于所有客户端连接。 使用 Enterprise 群集策略将所有请求路由到一个 Redis 节点,然后该节点用作代理,在内部将请求路由到群集中的正确节点。 这种方法的优点是,它使 Azure 托管 Redis 在用户看来不是群集。 这意味着 Redis 客户端库不需要支持 Redis 群集即可获得 Redis Enterprise 的一些性能优势,从而提升向后兼容性并简化连接。 缺点是单节点代理可能会成为影响计算利用率或网络吞吐量的瓶颈。 Enterprise 群集策略是唯一可与 RediSearch 模块一起使用的策略。 虽然 Enterprise 群集策略使 Azure 托管 Redis 实例在用户看来不是群集,但它在多键命令方面仍存在一些限制。
横向扩展或添加节点
核心 Redis Enterprise 软件能够纵向扩展(通过使用更大的 VM)或横向扩展(通过添加更多节点/VM)。 最终,缩放操作可实现相同的结果 - 添加更多内存、更多 vCPU 和更多分片。 由于这种冗余,Azure 托管 Redis 无法用于控制每个配置中使用的特定节点数。 此实现细节为用户进行了抽象化处理,以避免混淆、复杂性和配置欠佳。 相反,每个 SKU 都设计了一个节点配置,以最大化 vCPU 和内存。 Azure 托管 Redis 的一些 SKU 仅使用两个节点,而另一些则使用更多节点。
多键命令
由于 Azure 托管 Redis 实例设计了一个群集配置,因此你可能会在对多个键进行操作的命令上看到 CROSSSLOT 异常。 行为因使用的群集策略而异。 如果使用 OSS 群集策略,多键命令需要所有键都映射到同一个哈希槽。
你可能还会看到 Enterprise 群集策略的 CROSSSLOT 错误。 在具有 Enterprise 群集的槽中,仅允许使用以下多键命令:DEL、MSET、MGET、EXISTS、UNLINK 和 TOUCH。
在 Active-Active 数据库中,只能对同一槽中的键运行多键写入命令(DEL、MSET、UNLINK)。 但是,在 Active-Active 数据库中的各个槽之间允许使用以下多键命令:MGET、 EXISTS 和 TOUCH。 有关更多信息,请参阅数据库群集。
分片配置
Azure 托管 Redis 的每个 SKU 都配置为并行运行特定数量的 Redis 服务器进程(即“分片”)。 吞吐量性能、分片数量和每个实例上可用的 vCPU 数量之间的关系很复杂。 添加分片通常会提高性能,因为 Redis 操作可以并行运行。 但是,如果由于没有 vCPU 可用于执行命令,使分片无法运行命令,则性能实际上可能会下降。 下表显示了每个 Azure 托管 Redis SKU 的分片配置。 映射这些分片是为了优化每个 vCPU 的使用,同时保留 Redis Enterprise 代理、管理代理和 OS 系统任务的 vCPU 周期,这也会影响性能。
注意
每个 SKU 上使用的分片和 vCPU 数量可能会随时间变化,因为 Azure 托管 Redis 团队会优化性能。
| 层 | 闪存优化 | 内存优化 | Balanced | 计算优化 |
|---|---|---|---|---|
| 大小(GB) | vCPU/主分片 | vCPU/主分片 | vCPU/主分片 | vCPU/主分片 |
| 0.5 | - | - | 2/2 | - |
| 1 | - | - | 2/2 | - |
| 3 | - | - | 2/2 | 4/2 |
| 6 | - | - | 2/2 | 4/2 |
| 12 | - | 2/2 | 4/2 | 8/6 |
| 24 | - | 4/2 | 8/6 | 16/12 |
| 60 | - | 8/6 | 16/12 | 32/24 |
| 120 | - | 16/12 | 32/24 | 64/48 |
| 180 | - | 24/24 | 48/48 | 96/96 |
| 240 | 8/6 | 32/24 | 64/48 | 128/96 |
| 360 | - | 48/48 | 96/96 | 192/192 |
| 480 | 16/12 | 64/48 | 128/96 | 256/192 |
| 720 | 24/24 | 96/96 | 192/192 | 384/384 |
| 960 | 32/24 | 128/192 | 256/192 | - |
| 1440 | 48/48 | 192/192 | - | - |
| 1920 | 64/48 | 256/192 | - | - |
| 4500 | 144/96 | - | - | - |
在未启用高可用性模式的情况下运行
无需启用高可用性 (HA) 模式即可运行。 这意味着 Redis 实例未启用复制,并且无权访问可用性 SLA。 建议不要在开发/测试方案之外以非 HA 模式运行。 无法在已创建的实例中禁用高可用性。 但是,可以在没有高可用性的实例中启用高可用性。 在无高可用性的情况下运行的实例使用的 VM/节点更少,无法高效利用 vCPU,因此性能可能会降低。
保留内存
在每个 Azure 托管 Redis 实例上,大约 20% 的可用内存保留作为非缓存操作的缓冲区,例如在故障转移期间复制和活动异地复制缓冲区。 此缓冲区有助于提高缓存性能,并防止内存不足。
纵向缩减
Azure 托管 Redis 目前不支持纵向缩减。 有关详细信息,请参阅缩放 Azure 托管 Redis 的先决条件/限制。
闪存优化层
闪存优化层既使用 NVMe Flash 存储,又使用 RAM。 由于 Flash 存储成本更低,因此使用闪存优化层让你能够为了性价比牺牲一些性能。
在闪存优化实例上,20% 的缓存空间位于 RAM 上,其他 80% 则使用 Flash 存储。 所有密钥都存储在 RAM 上,而值可以存储在 Flash 存储或 RAM 中。 Redis 软件会智能地确定值的位置。 经常访问的热值存储在 RAM 上,而不太常用的冷值则保存在 Flash 上。 在读取或写入数据之前,必须将其移动到 RAM,成为热数据。
由于 Redis 将进行优化以实现最佳性能,因此在向 Flash 存储添加项之前,该实例将首先填满可用的 RAM。 先填充 RAM 会对性能产生一些影响:
- 在按低内存使用率进行测试时,可能会出现更好的性能和较低的延迟。 使用完整缓存实例进行测试可能会降低性能,因为在低内存使用率测试阶段仅使用 RAM。
- 向缓存写入更多数据时,与 Flash 存储相比,RAM 中的数据比例会降低,这通常也会降低延迟和吞吐量性能。
非常适合闪存优化层的工作负载
在闪存优化层上可能运行良好的工作负载通常具有以下特征:
- 读取量很大,读取命令与写入命令的比率较高。
- 访问侧重于一部分使用频率远高于数据集其他部分的键。
- 与键名相比,值相对较大。 (由于键名始终存储在 RAM 中,因此较大的值可能会成为内存增长的瓶颈。)
不太适合闪存优化层的工作负载
某些工作负载的访问特征针对闪存优化层设计进行的优化较少:
- 写入大量工作负载。
- 大多数数据集中的随机或统一数据访问模式。
- 长键名称的值大小相对较小。