本文介绍开发团队如何使用指标来查找瓶颈并提高分布式系统的性能。 本文基于我们对示例应用程序执行的实际负载测试。
本文是一系列文章的其中一篇。 请在此处阅读第一部分。
方案:使用 Azure Functions 处理事件流。

在此方案中,一队无人机将位置数据实时发送到 Azure IoT 中心。 Functions 应用接收事件,将数据转换为 GeoJSON 格式,并将转换的数据写入 Azure Cosmos DB。 Azure Cosmos DB 对地理空间数据具有本机支持,可对 Azure Cosmos DB 集合编制索引,以便高效进行空间查询。 例如,客户端应用程序可以查询给定位置 1 公里内的所有无人机,或查找特定区域内的所有无人机。
这些处理要求非常简单,不需要成熟的流处理引擎。 具体而言,处理不会联接流、聚合数据或跨时间窗口进行处理。 根据这些要求,Azure Functions 非常适合处理消息。 Azure Cosmos DB 还可以缩放以支持非常高的写入吞吐量。
监视吞吐量
这种情况提出了一个有趣的性能挑战。 每个设备的数据速率已知,但设备数可能会波动。 对于此业务方案,延迟要求并不是特别严格。 无人机报告的位置只需在一分钟内准确。 也就是说,函数应用必须随时间更新平均引入率。
IoT 中心将消息存储在日志流中。 传入消息将追加到流的末尾。 流的读取器(在本例中为函数应用)控制其遍历流的速率。 读取和写入路径的分离使 IoT 中心非常高效,但也意味着速度缓慢的读取器可能会落后。 为了检测此情况,开发团队添加了一个自定义指标来度量消息延迟。 此指标记录消息到达 IoT 中心的时间与函数接收消息进行处理的时间之间的增量。
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
TrackMetric 方法将自定义指标写入 Application Insights。 有关在 Azure 函数中使用 TrackMetric 的信息,请参阅 C# 函数中的自定义遥测。
如果函数与消息量保持同步,此指标应保持低稳定状态。 某些延迟是不可避免的,因此该值永远不会为零。 但如果函数落后,排队时间和处理时间之间的增量将开始上升。
测试 1:基线
第一次负载测试显示了一个直接的问题:函数应用一直从 Azure Cosmos DB 收到 HTTP 429 错误,这指示 Azure Cosmos DB 正在限制写入请求。
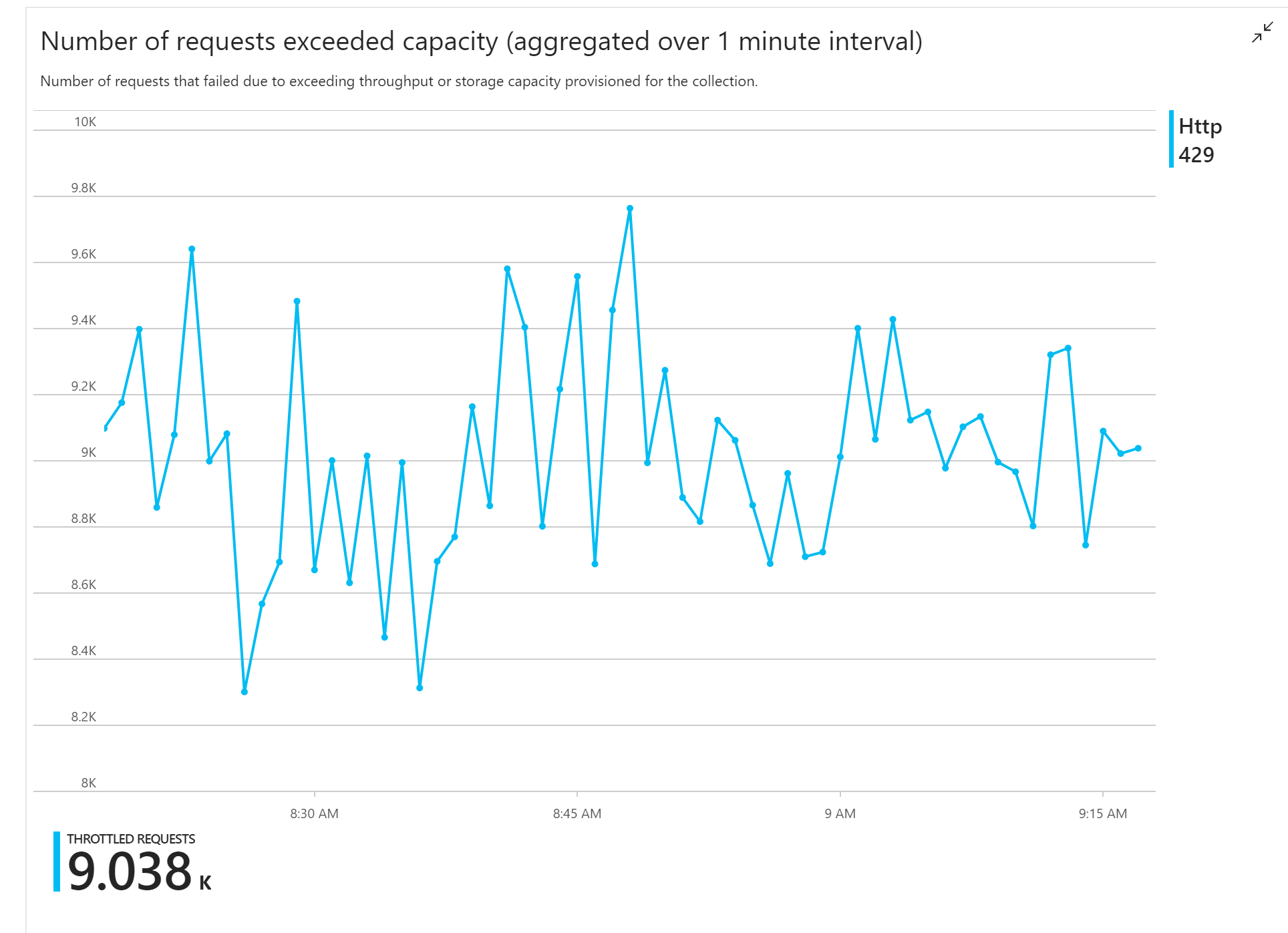
作为响应,团队通过增加为集合分配的 RU 数来缩放 Azure Cosmos DB,但错误仍然存在。 这看起来很奇怪,因为其粗略计算表明 Azure Cosmos DB 在与写入请求量保持同步方面应该没有问题。
当天晚些时候,其中一位开发人员向团队发送了以下电子邮件:
我查看了 Azure Cosmos DB 的暖路径。 有一件事我不明白。 分区键是 deliveryId,但我们不会将 deliveryId 发送到 Azure Cosmos DB。 我遗漏了什么吗?
这是线索。 查看分区热度地图,发现所有文档都登陆在同一分区上。
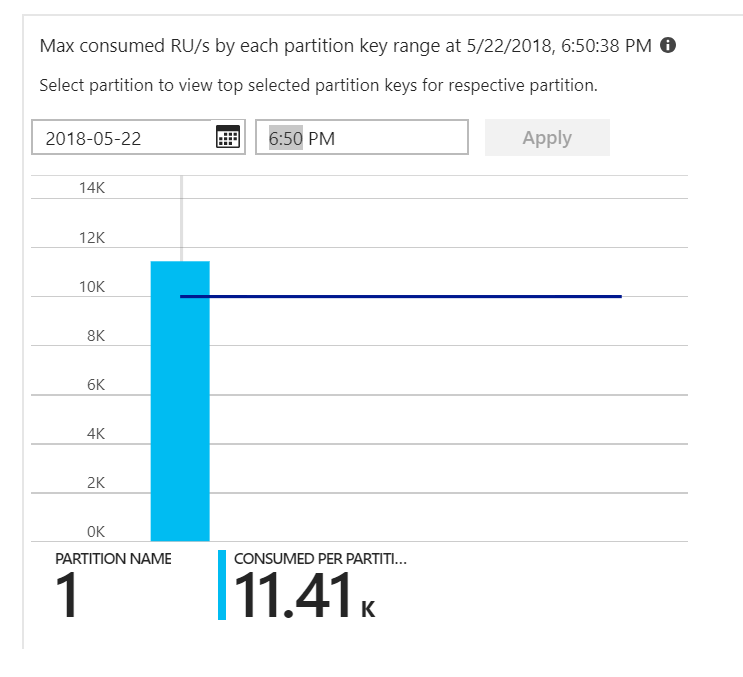
要在热度地图中看到的是跨所有分区的均匀分布。 在这种情况下,由于每个文档都写入到同一分区,因此添加 RU 没有帮助。 这个问题原来是代码中的 bug。 尽管 Azure Cosmos DB 集合具有分区键,但 Azure 函数实际上不包括文档中的分区键。 有关分区热度地图的详细信息,请参阅确定跨分区的吞吐量分布。
测试 2:修复分区问题
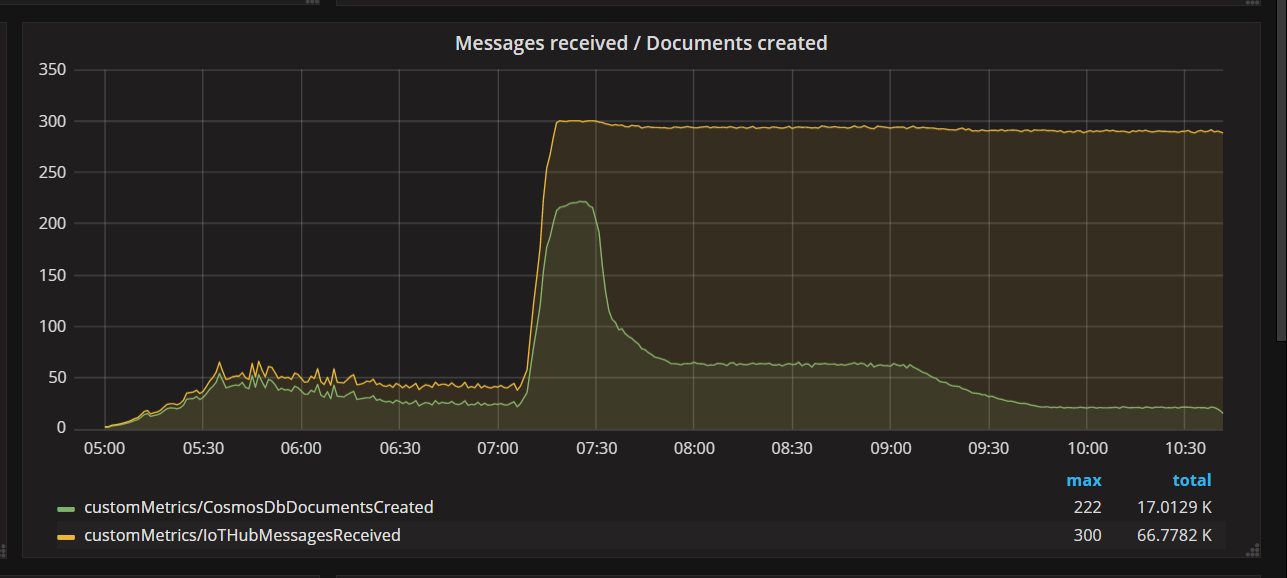
当团队部署代码修补程序并重新运行测试时,Azure Cosmos DB 停止了限制。 在一段时间内,一切看起来都正常运行。 但在一定负载下,遥测显示该函数写入的文档比它应该写入的少。 下图显示了从 IoT 中心接收的消息与写入 Azure Cosmos DB 的文档。 黄色行是每批接收的消息数,绿色是每批写入的文档数。 这些应成比例。 相反,每批数据库写入操作数量在大约 07:30 时明显下降。
下图显示了消息从设备到达 IoT 中心的时间与函数应用处理该消息的时间之间的延迟。 你可以看到,在同一时间点,延迟急剧上升,趋于平稳,然后下降。
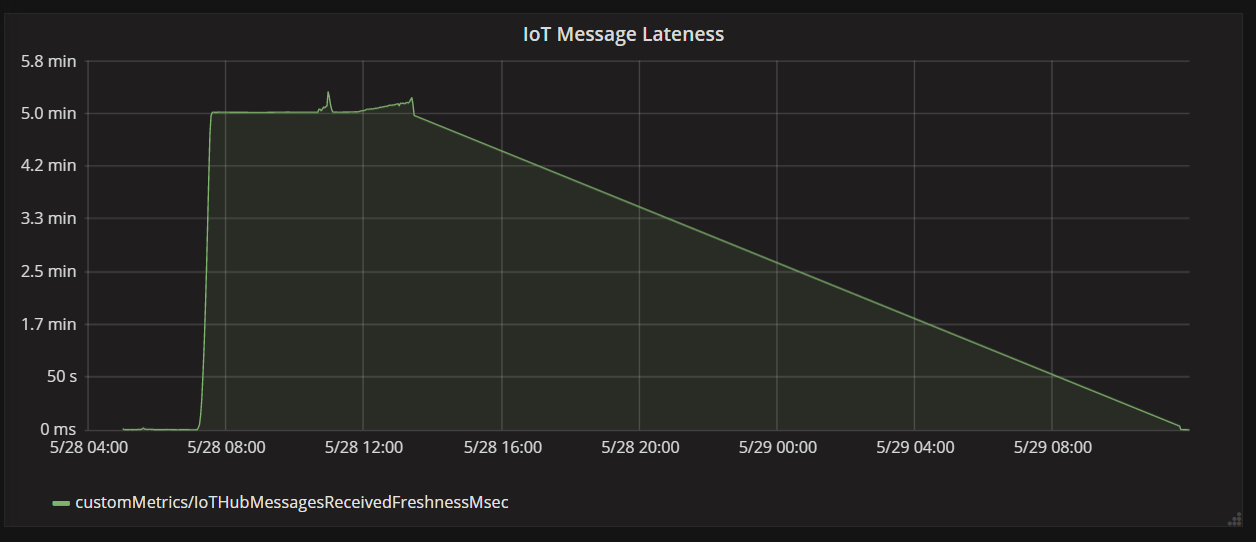
该值在 5 分钟达到峰值然后下降到零的原因是函数应用丢弃了延迟超过 5 分钟的消息:
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
当延迟指标回退到零时,可以在图中看到此情况。 同时,数据已丢失,因为函数正在丢弃消息。
发生了什么? 对于此特定负载测试,Azure Cosmos DB 集合具有备用 RU,因此瓶颈不在数据库中。 相反,问题出在消息处理循环中。 简单地说,该函数没有快速写入文档,因此无法与传入的消息量保持同步。 随着时间的推移,该函数越来越落后。
测试 3:并行写入
如果处理消息的时间是瓶颈,一个解决方案是并行处理更多消息。 在本方案中:
- 增加 IoT 中心分区数。 每个 IoT 中心分区一次分配一个函数实例,因此我们希望吞吐量随分区数线性缩放。
- 在函数中并行化文档写入。
为了探索第二个选项,团队修改了该函数以支持并行写入。 该函数的原始版本使用 Azure Cosmos DB 输出绑定。 优化版本直接调用 Azure Cosmos DB 客户端,并使用 Task.WhenAll 并行执行写入:
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
请注意,使用此方法可能会存在争用条件。 假设来自同一架无人机的两条消息碰巧在同一批消息中到达。 通过并行编写,较早的消息可能会覆盖后面的消息。 对于这种特殊情况,应用程序可以容忍偶尔丢失消息。 无人机每隔 5 秒发送一次新的位置数据,因此 Azure Cosmos DB 中的数据会不断更新。 但是,在其他方案中,严格按顺序处理消息可能很重要。
部署此代码更改后,应用程序可以使用具有 32 个分区的 IoT 中心引入超过 2500 个请求/秒。
客户端注意事项
服务器端的主动并行化可能会降低整体客户端体验。 请考虑使用 Azure Cosmos DB 批量执行工具库(此实现中未显示),这会显著减少使分配给 Azure Cosmos DB 容器的吞吐量达到饱和所需的客户端计算资源。 在客户端计算机的 CPU 已饱和的情况下,使用批量导入 API 来写入数据的单线程应用程序实现的写入吞吐量是以并行方式写入数据的多线程应用程序的近十倍。
摘要
对于此方案,已确定以下瓶颈:
- 热写入分区,由于正在写入的文档中缺少分区键值。
- 按 IoT 中心分区串行写入文档。
为了诊断这些问题,开发团队依赖于以下指标:
- Azure Cosmos DB 中受限制的请求。
- 分区热度地图 - 每个分区消耗的最大 RU 数。
- 收到的消息与创建的文档。
- 消息延迟。
后续步骤
查看性能对立模式