本文介绍使用 Azure Synapse 构建安全的数据湖屋解决方案的设计过程、原则和技术选择。 我们重点介绍安全注意事项和关键技术决策。
Apache®、Apache Spark® 和火焰徽标是 Apache Software Foundation 在美国和/或其他国家/地区的商标或注册商标。 使用这些标记并不暗示获得 Apache Software Foundation 的认可。
体系结构
下图显示了数据湖屋解决方案的体系结构。 它旨在控制服务之间的交互,以缓解安全威胁。 解决方案因功能和安全要求而异。

下载此体系结构的 Visio 文件。
数据流
解决方案的数据流如下图所示:

- 数据从数据源上传到数据登陆区域,或者上传到 Azure Blob 存储,或者上传到 Azure 文件存储提供的文件共享。 数据由批量上传程序或系统上传。 使用 Azure 事件中心的捕获功能来捕获流式处理数据,并将其存储在 Azure Blob 存储中。 可以有多个数据源。 例如,多个不同的工厂可以上传其操作数据。 有关保护对 Blob 存储、文件共享和其他存储资源的访问权限的信息,请参阅 Blob 存储的安全建议和计划 Azure 文件存储部署。
- 数据文件的到达会触发 Azure 数据工厂对数据进行处理并将其存储在核心数据区域中的数据湖中。 将数据上传到 Azure Data Lake 中的核心数据区域可防止数据外泄。
- Azure Data Lake 存储从不同源获取的原始数据。 它受到防火墙规则和虚拟网络的保护。 它阻止所有来自公共 Internet 的连接尝试。
- 数据到达数据湖会触发 Azure Synapse 管道,或者定时触发器会运行数据处理作业。 Azure Synapse 中的 Apache Spark 已激活并运行 Spark 作业或笔记本。 它还协调数据湖屋中的数据流。 Azure Synapse 管道将数据从青铜区域转转换到白银区域,然后再转换到黄金区域。
- Spark 作业或笔记本运行数据处理作业。 数据特选或机器学习训练作业也可以在 Spark 中运行。 黄金区域的结构化数据以 Delta Lake 格式存储。
- 无服务器 SQL 池创建外部表,这些表使用存储在 Delta Lake 中的数据。 无服务器 SQL 池提供强大高效的 SQL 查询引擎,可以支持传统的 SQL 用户帐户或 Microsoft Entra 用户帐户。
- Power BI 连接到无服务器 SQL 池以可视化数据。 它使用数据湖屋中的数据创建报表或仪表板。
- 数据分析师或科学家可以登录 Azure Synapse Studio,以执行以下操作:
- 进一步增强数据。
- 通过分析获得业务见解。
- 训练机器学习模型。
- 业务应用程序连接到无服务器 SQL 池,并使用数据来支持其他业务操作需求。
- Azure Pipelines 运行可自动生成、测试和部署解决方案的 CI/CD 进程。 它旨在最大程度减少部署过程中的人工干预。
组件
以下是此数据湖屋解决方案的关键组件:
- Azure Synapse
- Azure 文件
- 事件中心
- Blob 存储
- Azure Data Lake 存储
- Azure DevOps
- Power BI
- 数据工厂
- Azure Bastion
- Azure Monitor
- Microsoft Defender for Cloud
- Azure Key Vault
备选方法
- 如果需要实时数据处理,可以使用 Apache 结构化流式处理从事件中心接收并处理数据流,而不是将单个文件存储在数据登陆区域。
- 如果数据结构复杂,需要复杂的 SQL 查询,请考虑将其存储在专用 SQL 池而不是无服务器 SQL 池中。
- 如果数据包含许多分层数据结构(例如,它具有大型 JSON 结构),则可能需要将其存储在 Azure Synapse 数据资源管理器中。
方案详细信息
Azure Synapse Analytics 是一种通用数据平台,支持企业数据仓库、实时数据分析、管道、时序数据处理、机器学习和数据治理。 为了支持这些功能,它集成了多种不同的技术,例如:
- 企业数据仓库
- 无服务器 SQL 池
- Apache Spark
- 管道
- 数据资源管理器
- 机器学习功能
- Microsoft Purview 统一数据治理
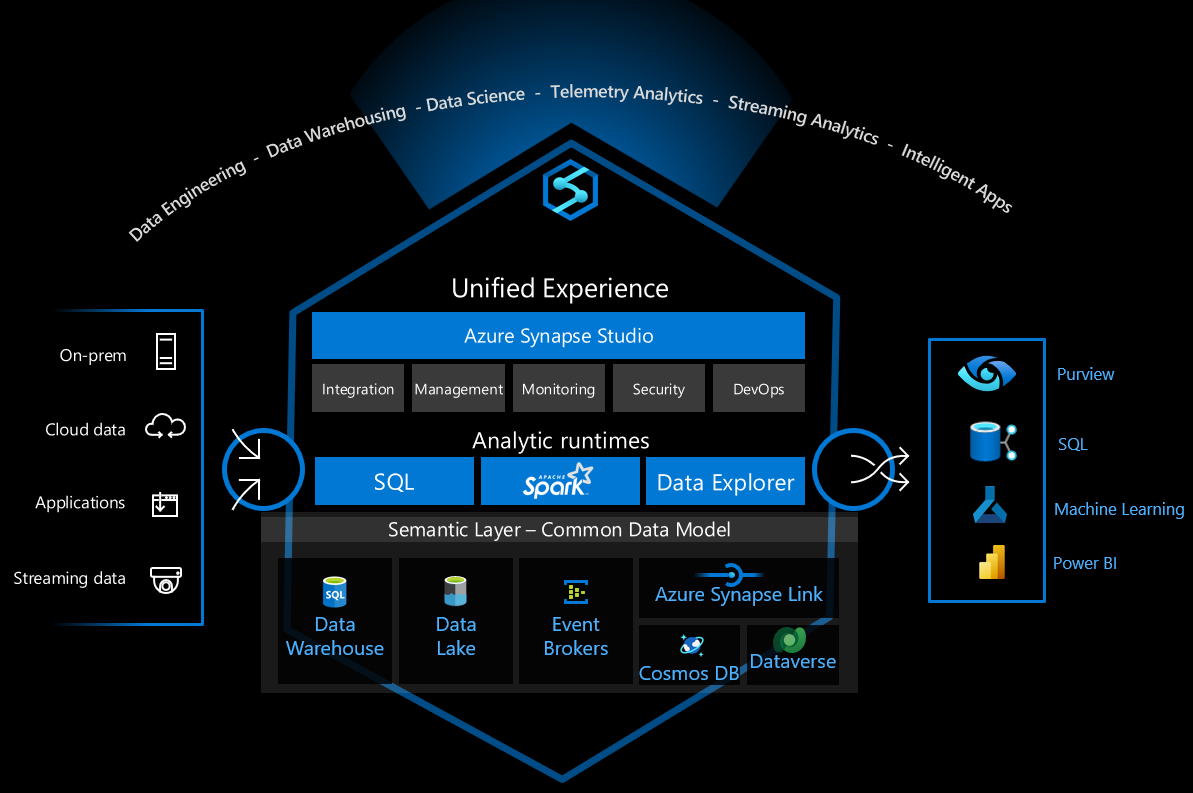
这些功能提供了许多可能性,但要安全地配置基础结构以供安全使用,还需要做出许多技术选择。
本文介绍使用 Azure Synapse 构建安全的数据湖屋解决方案的设计过程、原则和技术选择。 我们重点介绍安全注意事项和关键技术决策。 该解决方案使用以下 Azure 服务:
- Azure Synapse
- Azure Synapse 无服务器 SQL 池
- Azure Synapse Analytics 中的 Apache Spark
- Azure Synapse 管道
- Azure 数据湖
- Azure DevOps。
目标是为企业构建安全且经济高效的数据湖屋平台提供指导,并使这些技术无缝且安全地协同工作。
可能的用例
数据湖屋是一种新式数据管理体系结构,它结合了数据湖的成本效率、缩放和灵活性功能以及数据仓库的数据和事务管理功能。 数据湖屋可以处理海量数据,并支持商业智能和机器学习场景。 它还可以处理来自不同数据结构和数据源的数据。 有关详细信息,请参阅什么是 Databricks 数据湖屋?。
这里介绍的解决方案的一些常见用例如下:
- 物联网 (IoT) 遥测分析
- 智能工厂自动化(制造)
- 跟踪使用者的活动和行为(零售)
- 管理安全事件
- 监视应用程序日志和应用程序行为
- 半结构化数据的处理和业务分析
大致设计
此解决方案侧重于体系结构中的安全设计和实现做法。 无服务器 SQL 池、Azure Synapse 中的 Apache Spark、Azure Synapse 管道、Data Lake Storage 和 Power BI 是用于实现数据湖屋模式的关键服务。
下面是大致的解决方案设计体系结构:

选择安全重点
我们使用威胁建模工具开始安全设计。 该工具帮助我们:
- 与系统利益干系人就潜在风险进行沟通。
- 定义系统中的信任边界。
根据威胁建模结果,我们将以下安全领域列为首要任务:
- 标识和访问控制
- 网络保护
- DevOps 安全性
我们设计了安全功能和基础结构更改,通过降低这些首要任务识别的关键安全风险来保护系统。
有关应检查和考虑的详细信息,请参阅:
网络和资产保护计划
云采用框架中的关键安全原则之一是零信任原则:在为任何组件或系统设计安全性时,请假设组织中的其他资源遭到入侵,从而降低攻击者扩展其访问权限的风险。
根据威胁建模结果,该解决方案采用零信任中的微分段部署建议,并定义多个安全边界。 Azure 虚拟网络和 Azure Synapse 数据外泄防护是用于实现安全边界的关键技术,以保护数据资产和关键组件。
由于 Azure Synapse 由多种不同的技术组成,因此我们需要:
识别项目中使用的 Synapse 组件和相关服务。
Azure Synapse 是一种通用数据平台,可以处理许多不同的数据处理需求。 首先,我们需要确定在项目中使用 Azure Synapse 中的哪些组件,这样我们就可以计划如何保护它们。 还需要确定与这些 Azure Synapse 组件通信的其他服务。
在数据湖屋体系结构中,关键组件包括:
- Azure Synapse 无服务器 SQL
- Azure Synapse 中的 Apache Spark
- Azure Synapse 管道
- Data Lake Storage
- Azure DevOps
定义组件之间的合法通信行为。
我们需要定义组件之间允许的通信行为。 例如,我们是希望 Spark 引擎直接与专用 SQL 实例通信,还是希望它通过 Azure Synapse 数据集成管道或 Data Lake Storage 等代理进行通信?
根据零信任原则,如果没有业务上的交互需要,我们会阻止通信。 例如,我们阻止未知租户中的 Spark 引擎直接与 Data Lake Storage 进行通信。
选择适当的安全解决方案来强制实施已定义的通信行为。
在 Azure 中,多种安全技术可以强制实施已定义的服务通信行为。 例如,在 Data Lake Storage 中,可以使用 IP 地址允许列表来控制对数据湖的访问,但也可以选择允许哪些虚拟网络、Azure 服务和资源实例。 每种保护方法都提供有不同的安全保护。 可根据业务需求和环境限制进行选择。 下一部分将介绍此解决方案中使用的配置。
为关键资源实现威胁检测和高级防御。
对于关键资源,最好实现威胁检测和高级防御。 这些服务有助于识别威胁并触发警报,因此系统可以通知用户安全漏洞。
请考虑以下技术来更好地保护网络和资产:
部署外围网络,为数据管道提供安全区域
当数据管道工作负载需要访问外部数据和数据登陆区域时,最好实现外围网络并将其与提取、转换、加载 (ETL) 管道分开。
为所有存储帐户启用 Defender for Cloud
在检测到访问或利用存储帐户的异常和潜在有害尝试时,Defender for Cloud 会触发安全警报。 有关详细信息,请参阅配置适用于存储的 Microsoft Defender。
锁定存储帐户以防止恶意删除或配置更改
有关详细信息,请参阅将 Azure 资源管理器锁定应用于存储帐户。
具有网络和资产保护的体系结构
下表描述了为此解决方案选择的已定义的通信行为和安全技术。 这些选择基于网络和资产保护计划中所讨论的方法。
| 从(客户端) | 到(服务) | 行为 | 配置 | 备注 | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | 全部拒绝 | 防火墙规则 - 默认拒绝 | 默认值:“拒绝” | 防火墙规则 - 默认拒绝 |
| Azure Synapse 管道/Spark | Data Lake Storage | 允许(实例) | 虚拟网络 - 托管专用终结点 (Data Lake Storage) | ||
| Synapse SQL | Data Lake Storage | 允许(实例) | 防火墙规则 - 资源实例 (Synapse SQL) | Synapse SQL 需要使用托管标识访问 Data Lake Storage | |
| Azure Pipelines 代理 | Data Lake Storage | 允许(实例) | 防火墙规则 - 所选虚拟网络 服务终结点 - 存储 |
对于集成测试 绕过:“AzureServices”(防火墙规则) |
|
| Internet | Synapse 工作区 | 全部拒绝 | 防火墙规则 | ||
| Azure Pipelines 代理 | Synapse 工作区 | 允许(实例) | 虚拟网络 - 专用终结点 | 需要三个专用终结点(开发、无服务器 SQL 和专用 SQL) | |
| Synapse 托管虚拟网络 | Internet 或未经授权的 Azure 租户 | 全部拒绝 | 虚拟网络 - Synapse 数据外泄防护 | ||
| Synapse 管道/Spark | 密钥保管库 | 允许(实例) | 虚拟网络 - 托管专用终结点 (Key Vault) | 默认值:“拒绝” | |
| Azure Pipelines 代理 | 密钥保管库 | 允许(实例) | 防火墙规则 - 所选虚拟网络 * 服务终结点 - Key Vault |
绕过:“AzureServices”(防火墙规则) | |
| Azure Functions | Synapse 无服务器 SQL | 允许(实例) | 虚拟网络 - 专用终结点(Synapse 无服务器 SQL) | ||
| Synapse 管道/Spark | Azure Monitor | 允许(实例) | 虚拟网络 - 专用终结点 (Azure Monitor) |
例如,在计划中我们想要:
- 创建包含托管虚拟网络的 Azure Synapse 工作区。
- 使用 Azure Synapse 工作区数据外泄防护来保护从 Azure Synapse 工作区流出的数据。
- 管理 Azure Synapse工作区的已批准 Microsoft Entra 租户列表。
- 配置网络规则,向来自所选虚拟网络的流量仅授予对存储帐户的访问权限,并禁用公用网络访问权限。
- 使用托管专用终结点将 Azure Synapse 管理的虚拟网络连接到数据湖。
- 使用资源实例安全地将 Azure Synapse SQL 连接到数据湖。
注意事项
这些注意事项实施 Azure 架构良好的框架的支柱原则,即一套可用于改进工作负荷质量的指导原则。 有关详细信息,请参阅 Microsoft Azure 架构良好的框架。
安全性
有关架构良好框架的安全支柱的信息,请参阅安全性。
标识和访问控制
系统中有多个组件。 每个组件都需要不同的标识和访问管理 (IAM) 配置。 这些配置需要协作以提供简化的用户体验。 因此,我们在实现标识和访问控制时使用以下设计指南。
为不同的访问控制层选择标识解决方案
- 系统中有四种不同的标识解决方案。
- SQL 帐户 (SQL Server)
- 服务主体 (Microsoft Entra ID)
- 托管标识 (Microsoft Entra ID)
- 用户帐户 (Microsoft Entra ID)
- 系统中有四个不同的访问控制层。
- 应用程序访问层:选择 AP 角色的标识解决方案。
- Azure Synapse DB/表访问层:为数据库中的角色选择标识解决方案。
- Azure Synapse 访问外部资源层:选择访问外部资源的标识解决方案。
- Data Lake Storage 访问层:选择标识解决方案来控制存储中的文件访问。

标识和访问控制的关键部分是为每个访问控制层选择正确的标识解决方案。 Azure 架构良好的框架的安全设计原则建议使用本机控件并推动简单性。 因此,此解决方案在应用程序和 Azure Synapse DB 访问层中使用最终用户的 Microsoft Entra 用户帐户。 它使用本机第一方 IAM 解决方案并提供精细的访问控制。 Azure Synapse 访问外部资源层和 Data Lake 访问层使用 Azure Synapse 中的托管标识来简化授权过程。
- 系统中有四种不同的标识解决方案。
考虑最低特权访问
零信任指导原则建议提供对关键资源的及时和足够的访问权限。 请参阅 Microsoft Entra Privileged Identity Management (PIM),以增强将来的安全性。
保护链接服务
链接服务定义服务连接到外部资源所需的连接信息。 确保链接服务配置的安全是非常重要的。
- 使用专用链接创建 Azure Data Lake 链接服务。
- 使用托管标识作为链接服务中的身份验证方法。
- 使用 Azure Key Vault 保护用于访问链接服务的凭据。

安全分数评估和威胁检测
为了解系统的安全状态,解决方案使用 Microsoft Defender for Cloud 来评估基础结构的安全性并检测安全问题。 Microsoft Defender for Cloud 是用于进行安全态势管理和威胁防护的工具。 它可以保护在 Azure、混合和其他云平台中运行的工作负载。

首次在 Azure 门户中访问 Defender for Cloud 页面时,将自动在所有 Azure 订阅上启用 Defender for Cloud 的免费计划。 强烈建议启用它来获得云安全状况评估和建议。 Microsoft Defender for Cloud 将为订阅提供安全分数和一些安全性强化指南。
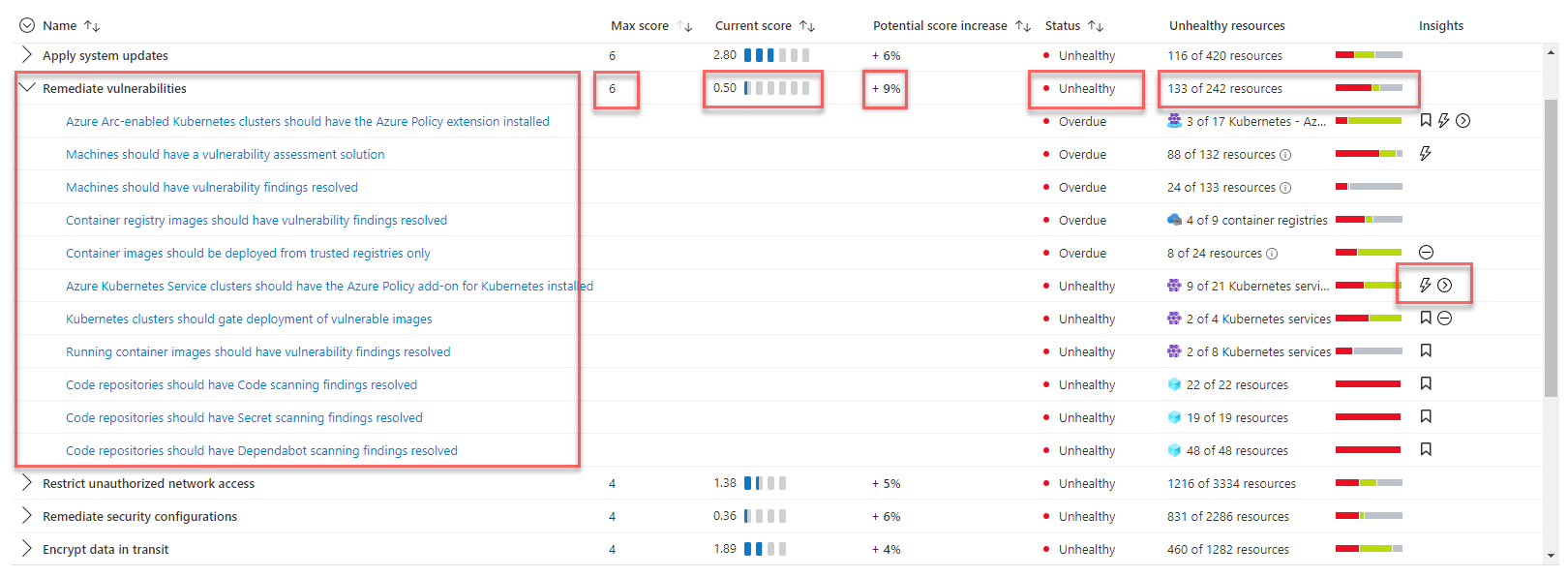
如果解决方案需要高级的安全管理和威胁检测功能,例如可疑活动的检测和警报,则可以针对不同的资源分别启用云工作负载保护。
成本优化
有关架构良好的框架的成本优化支柱的信息,请参阅成本优化。
数据湖屋解决方案的主要优点是其成本效益和可缩放的体系结构。 解决方案中的大多数组件都使用基于消耗的计费,并将自动缩放。 在此解决方案中,所有数据都存储在 Data Lake Storage 中。 只有在不运行任何查询或处理数据的情况下,才需要为存储数据付费。
此解决方案的定价取决于以下关键资源的使用情况:
- Azure Synapse 无服务器 SQL:使用基于消耗的计费,只需为使用的资源付费。
- Azure Synapse 中的 Apache Spark:使用基于消耗的计费,只需为使用的资源付费。
- Azure Synapse 管道:使用基于消耗的计费,只需为使用的资源付费。
- Azure Data Lake:使用基于消耗的计费,只需为使用的资源付费。
- Power BI:成本取决于购买的许可证。
- 专用链接:使用基于消耗的计费,只需为使用的资源付费。
不同的安全保护解决方案具有不同的成本模式。 应根据业务需求和解决方案成本选择安全解决方案。
使用 Azure 定价计算器来估算解决方案的成本。
卓越运营
有关架构良好的框架的卓越运营支柱的信息,请参阅卓越运营。
对 CI/CD 服务使用启用了虚拟网络的自托管管道代理
默认 Azure DevOps 管道代理不支持虚拟网络通信,因为它使用非常广泛的 IP 地址范围。 此解决方案在虚拟网络中实现 Azure DevOps 自托管代理,以便 DevOps 进程可以与解决方案中的其他服务顺利通信。 用于运行 CI/CD 服务的连接字符串和机密存储在独立的密钥保管库中。 在部署过程中,自托管代理访问核心数据区域中的密钥保管库,更新资源配置和机密。 有关详细信息,请参阅使用单独的密钥保管库文档。 此解决方案还使用 VM 规模集来确保 DevOps 引擎可以根据工作负载自动纵向扩展和缩减。

在 CI/CD 管道中实现基础结构安全扫描和安全冒烟测试
用于扫描基础结构即代码 (IaC) 文件的静态分析工具可以帮助检测和防止可能导致安全性或合规性问题的错误配置。 安全冒烟测试可确保成功启用重要的系统安全措施,防止部署失败。
- 使用静态分析工具扫描基础结构即代码 (IaC) 模板,可以检测和防止可能导致安全性或合规性问题的错误配置。 使用 Checkov 或 Terrascan 等工具检测和防范安全风险。
- 确保 CD 管道正确处理部署失败。 任何与安全功能相关的部署失败都应被视为严重失败。 管道应重试失败的操作或暂停部署。
- 通过运行安全冒烟测试,验证部署管道中的安全措施。 安全冒烟测试(例如验证已部署资源的配置状态或检查安全场景的测试用例)可以确保安全设计按预期工作。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- Herman Wu | 高级软件工程师
其他参与者:
- Ian Chen | 首席软件工程师
- Jose Contreras | 首席软件工程师
- Roy Chan | 首席软件工程师经理
后续步骤
- Azure 产品文档
- 其他文章
- 什么是 Azure Synapse Analytics?
- Azure Synapse Analytics 中的无服务器 SQL 池
- Azure Synapse Analytics 中的 Apache Spark
- Azure 数据工厂和 Azure Synapse Analytics 中的管道和活动
- 什么是 Azure Synapse 数据资源管理器? (预览版)
- Azure Synapse Analytics 中的机器学习功能
- 什么是 Microsoft Purview?
- Azure Synapse Analytics 和 Azure Purview 更好地合作
- Azure Data Lake Storage Gen2 简介
- 什么是 Azure 数据工厂?
- 当前数据模式博客系列:数据湖屋
- 什么是 Microsoft Defender for Cloud?
- 数据湖屋、数据仓库和新式数据平台体系结构
- 组织 Azure Synapse 工作区和湖屋的最佳做法
- 了解 Azure Synapse 专用终结点
- Azure Synapse Analytics - 数据安全新见解
- Azure Synapse 专用 SQL 池(以前称为 SQL DW)的 Azure 安全基线
- 云网络安全 101:Azure 服务终结点与专用终结点
- 如何为 Azure Synapse 工作区设置访问控制
- 使用 Azure 专用链接中心连接到 Azure Synapse Studio
- 如何将 Azure Synapse 工作区项目部署到托管的虚拟网络 Azure Synapse 工作区
- Azure Synapse Analytics 工作区的持续集成和持续交付
- Microsoft Defender for Cloud 中的安全分数
- 使用 Azure 密钥保管库的最佳做法
- 用于 Azure 中数据管理和分析的 Adatum Corporation 方案