注意
本文依赖于 GitHub 上托管的开放源代码库:https://github.com/mspnp/spark-monitoring。
原始库支持 Azure Databricks Runtimes 10.x (Spark 3.2.x) 和更低版本。
Databricks 在 l4jv2 分支(参见 https://github.com/mspnp/spark-monitoring/tree/l4jv2)上贡献了一个更新版本来支持 Azure Databricks Runtimes 11.0 (Spark 3.3.x) 及更高版本。
请注意,由于 Databricks Runtimes 中使用的日志记录系统不同,11.0 版本不向后兼容。 请确保为 Databricks Runtime 使用正确的版本。 库和 GitHub 存储库处于维护模式。 没有进一步发布的计划,问题支持部门只会尽力而为。 如果对于此库或 Azure Databricks 环境的监视和日志记录路线图有任何其他问题,请联系 azure-spark-monitoring-help@databricks.com。
本解决方案演示如何通过可观测性模式和指标来改进使用 Azure Databricks 的大数据系统的处理性能。
体系结构

下载此体系结构的 Visio 文件。
工作流
解决方案涉及以下步骤:
服务器将按客户分组的大型 GZIP 文件发送到 Azure Data Lake Storage 的源文件夹。
然后,Data Lake Storage 将成功提取的客户文件发送到 Azure 事件网格,从而将客户文件数据转换为多条消息。
Azure 事件网格将消息发送到 Azure 队列存储服务,然后将消息存储在队列中。
Azure 队列存储将队列发送到 Azure Databricks 数据分析平台进行处理。
Azure Databricks 将队列数据解压缩并处理为发送回 Data Lake Storage 的已处理文件:
如果已处理文件有效,它将进入“登陆”文件夹。
否则,文件将进入“错误”文件夹树中。 最初,该文件进入重试子文件夹,Data Lake Storage 将再次尝试处理客户文件(步骤 2)。 如果经过两次重试尝试,Azure Databricks 仍返回无效的已处理文件,则已处理文件将进入“失败”子文件夹。
Azure Databricks 在上一步中解压缩并处理数据时,它还将应用程序日志和指标发送到 Azure Monitor 进行存储。
Azure Log Analytics 工作区对来自 Azure Monitor 的应用程序日志和指标应用 Kusto 查询,以进行故障排除和深度诊断。
组件
- Azure Data Lake Storage 是一组专用于大数据分析的功能。
- Azure 事件网格允许开发人员使用基于事件的体系结构轻松生成应用程序。
- Azure 队列存储是用于存储大量消息的服务。 可以使用 HTTP 或 HTTPS 通过经验证的调用从世界任何位置访问消息。 可以使用队列创建要异步处理的积压工作。
- Azure Databricks 是一个针对 Azure 云平台进行优化的数据分析平台。 Azure Databricks Workspace 是 Azure Databricks 为开发数据密集型应用程序提供的两个环境之一,这是一种基于 Apache Spark 的统一分析引擎,用于大规模数据处理。
- Azure Monitor 会收集和分析应用遥测数据,例如性能指标和活动日志。
- Azure Log Analytics 是一种用于编辑和运行数据日志查询的工具。
方案详细信息
开发团队可以使用可观测性模式和指标来查找瓶颈并提高大数据系统的性能。 团队必须在大规模应用程序上对大量指标流执行负载测试。
此方案提供了性能优化指南。 在该方案中,由于逐个客户记录存在性能挑战,因此采用能够可靠监视这些项的 Azure Databricks:
- 自定义应用程序指标
- 流式处理查询事件
- 应用程序日志消息
Azure Databricks 可以将此监视数据发送到不同的记录服务(例如 Azure Log Analytics)。
此方案概述了已按客户分组并存储在 GZIP 存档文件中的大型数据集引入。 由于无法在 Azure Databricks 的实时 Apache Spark™ 用户界面之外获取详细日志,因此,团队需要一种方法来为每个客户存储所有数据,然后进行基准测试和比较。 对于大型数据方案,必须找到最佳组合执行程序池和虚拟机 (VM) 大小,以加快处理速度。 对于此业务方案,整个应用程序依赖引入速度和查询要求,因此系统吞吐量不会随工作量的增加而意外降低。 该方案必须保证系统符合与客户建立的服务级别协议 (SLA)。
可能的用例
可以从此解决方案受益的方案包括:
- 系统运行状况监视。
- 性能维护。
- 监视日常系统使用情况。
- 发现如果不加以解决,可能导致将来出现问题的趋势。
注意事项
这些注意事项实施 Azure 架构良好的框架的支柱原则,即一套可用于改善工作负荷质量的指导原则。 有关详细信息,请参阅 Microsoft Azure 架构良好的框架。
考虑此体系结构时,请记住以下几点:
Azure Databricks 可以自动分配大型作业所需的计算资源,从而避免其他解决方案引入的问题。 例如,使用 Apache Spark 上针对 Databricks 优化的自动缩放功能,过度预配可能会导致资源使用欠佳。 或者,你可能不知道作业所需的执行程序数。
Azure 队列存储中的队列消息大小可高达 64 KB。 一个队列可能包含数百万条队列消息,直至达到存储帐户的总容量上限。
成本优化
成本优化是关于寻找减少不必要的费用和提高运营效率的方法。 有关详细信息,请参阅成本优化设计评审核对清单。
要估计此解决方案的实现成本,请使用 Azure 定价计算器。
部署此方案
注意
此处所述的部署步骤仅适用于 Azure Databricks、Azure Monitor 和 Azure Log Analytics。 本文未介绍其他组件的部署。
要获取该过程的所有日志和信息,请设置 Azure Log Analytics 和 Azure Databricks 监视库。 监视库将作业中的 Apache Spark 级别事件和 Spark Structured Streaming 指标从作业流式传输到 Azure Monitor。 对于这些事件和指标,无需对应用程序代码做出任何更改。
为大数据系统设置性能优化的步骤如下:
在 Azure 门户中创建 Azure Databricks 工作区。 复制并保存 Azure 订阅 ID(全局唯一标识符 (GUID))、资源组名称、Databricks 工作区名称和工作区门户 URL 以供将来使用。
在 Web 浏览器中,转到 Databricks 工作区 URL 并生成 Databricks 个人访问令牌。 复制并保存出现的令牌字符串(以
dapi开头,有 32 个字符的十六进制值)以供将来使用。将 mspnp/spark-monitoring GitHub 存储库克隆到本地计算机上。 此存储库包含以下组件的源代码:
- Azure 资源管理器模板(ARM 模板)用于创建 Azure Log Analytics 工作区,该模板还安装用于收集 Spark 指标的预生成查询
- Azure Databricks 监视库
- 用于将应用程序指标和应用程序日志从 Azure Databricks 发送到 Azure Monitor 的示例应用程序
使用 Azure CLI 命令部署 ARM 模板,使用预生成 Spark 指标查询创建 Azure Log Analytics 工作区。 在命令输出中,复制并保存新 Log Analytics 工作区的生成名称(按照 spark-monitoring-<randomized-string 格式>)。
在 Azure 门户,复制并保存 Log Analytics 工作区 ID 和密钥 供将来使用。
安装 IntelliJ IDEA 社区版,这是一个集成开发环境 (IDE),内置对 Java 开发工具包 (JDK) 和 Apache Maven 的支持。 添加 Scala 插件。
使用 IntelliJ IDEA 构建 Azure Databricks 监视库。 要执行实际构建步骤,请选择“视图”“工具窗口”>>“Maven”以显示 Maven 工具窗口,然后选择“执行 Maven 目标”>“mvn 包”。
使用 Python 包安装工具安装 Azure Databricks CLI,然后使用之前复制的 Databricks 个人访问令牌设置身份验证。
通过使用之前复制的 Databricks 和 Log Analytics 值修改 Databricks init 脚本,然后使用 Azure Databricks CLI 将 init 脚本和 Azure Databricks 监视库复制到 Databricks 工作区,从而配置 Azure Databricks 工作区。
在 Databricks 工作区门户中,创建并配置 Azure Databricks 群集。
在 IntelliJ IDEA 中,使用 Maven 构建示例应用程序。 然后在 Databricks 工作区门户中运行示例应用程序,生成 Azure Monitor 的示例日志和指标。
在 Azure Databricks 中运行示例作业时,请转到 Azure 门户,在 Log Analytics 接口中查看并查询事件类型(应用程序日志和指标):
- 选择“表”>“自定义日志”以查看 Spark 侦听器事件 (SparkListenerEvent_CL)、Spark 记录事件 (SparkLoggingEvent_CL) 和 Spark 指标 (SparkMetric_CL) 的表架构。
- 选择“查询资源管理器”“保存的查询”>>“Spark 指标”以查看并运行创建 Log Analytics 工作区时添加的查询。
阅读下一部分,详细了解如何查看和运行预构建和自定义查询。
在 Azure Log Analytics 中查询日志和指标
访问预创建查询
下面列出了用于检索 Spark 指标的预构建查询名称。
- 每个执行程序的 CPU 时间百分比
- 每个执行程序的反序列化时间百分比
- 每个执行程序的 JVM 时间百分比
- 每个执行程序的序列化时间百分比
- 已溢出的磁盘字节数
- 错误跟踪(错误记录或错误文件)
- 每个执行程序读取的文件系统字节数
- 每个执行程序写入的文件系统字节数
- 每个作业的作业错误数
- 每个作业的作业延迟(批处理持续时间)
- 作业吞吐量
- 正在运行的执行程序
- 读取的随机字节数
- 每个执行程序读取的随机字节数
- 每个执行程序读取到磁盘的随机字节数
- 随机客户端直接内存
- 每个执行程序的随机客户端内存
- 每个执行程序溢出的随机磁盘字节数
- 每个执行程序的随机堆内存
- 每个执行程序溢出的随机内存字节数
- 每个阶段的阶段延迟(阶段持续时间)
- 每个阶段的阶段吞吐量
- 每个流的流式处理错误
- 每个流的流式处理延迟
- 流式处理吞吐量输入行数/秒
- 流式处理吞吐量已处理行数/秒
- 每个主机的任务执行总和
- 任务反序列化时间
- 每个阶段的任务错误数
- 任务执行程序计算时间(数据倾斜时间)
- 读取的任务输入字节数
- 每个阶段的任务延迟(任务持续时间)
- 任务结果序列化时间
- 任务计划程序延迟
- 读取的任务随机字节数
- 写入的任务随机字节数
- 任务随机读取时间
- 任务随机写入时间
- 任务吞吐量(每个阶段的任务总和)
- 每个执行程序的任务(每个执行程序的任务总和)
- 每个阶段的任务数
编写自定义查询
你还可以用 Kusto 查询语言 (KQL) 编写自己的查询。 只需选择可编辑的顶部中间窗格,根据自己的需要自定义查询。
以下两个查询从 Spark 记录事件中拉取数据:
SparkLoggingEvent_CL | where logger_name_s contains "com.microsoft.pnp"
SparkLoggingEvent_CL
| where TimeGenerated > ago(7d)
| project TimeGenerated, clusterName_s, logger_name_s
| summarize Count=count() by clusterName_s, logger_name_s, bin(TimeGenerated, 1h)
这两个示例是有关 Spark 指标日志的查询:
SparkMetric_CL
| where name_s contains "executor.cpuTime"
| extend sname = split(name_s, ".")
| extend executor=strcat(sname[0], ".", sname[1])
| project TimeGenerated, cpuTime=count_d / 100000
SparkMetric_CL
| where name_s contains "driver.jvm.total."
| where executorId_s == "driver"
| extend memUsed_GB = value_d / 1000000000
| project TimeGenerated, name_s, memUsed_GB
| summarize max(memUsed_GB) by tostring(name_s), bin(TimeGenerated, 1m)
查询术语
下表说明了构造应用程序日志和指标查询时使用的一些术语。
| 术语 | ID | 备注 |
|---|---|---|
| Cluster_init | 应用程序 ID | |
| 队列 | 运行 ID | 一个运行 ID 等于多个批处理。 |
| 批处理 | 批处理 ID | 一个批处理等于两个作业。 |
| 作业 | 作业 ID | 一个作业等于两个阶段。 |
| 阶段 | 阶段 ID | 根据任务(读取、随机或写入),一个阶段具有 100-200 个任务 ID。 |
| 任务 | 任务 ID | 为一个执行程序分配一个任务。 为一个分区分配一个任务以执行 partitionBy。 对于大约 200 个客户,应该有 200 个任务。 |
以下部分包含此方案中用于监视系统吞吐量、Spark 作业运行状态和系统资源使用情况的典型指标。
系统吞吐量
| 名称 | 度量 | 单元 |
|---|---|---|
| 流吞吐量 | 每分钟平均处理速率的平均输入速率 | 每分钟行数 |
| 作业周期 | 每分钟平均已结束 Spark 作业持续时间 | 每分钟持续时间 |
| 作业计数 | 每分钟平均已结束 Spark 作业数量 | 每分钟作业数 |
| 阶段持续时间 | 平均已完成阶段持续时间 | 每分钟持续时间 |
| 阶段计数 | 每分钟平均已完成阶段数 | 每分钟阶段数 |
| 任务持续时间 | 每分钟平均已完成任务持续时间 | 每分钟持续时间 |
| 任务计数 | 每分钟平均完成任务数 | 每分钟任务数 |
Spark 作业运行状态
| 名称 | 度量 | 单元 |
|---|---|---|
| 计划程序池计数 | 每分钟计划程序池的非重复计数(运行队列数) | 计划程序池数 |
| 正在运行的执行程序数 | 每分钟正在运行的执行程序数 | 正在运行的执行程序数 |
| “错误”跟踪 | 具有 Error 级别的所有错误日志以及相应的任务/阶段 ID(如 thread_name_s 中所示) |
系统资源使用情况
| 名称 | 度量 | 单元 |
|---|---|---|
| 每个执行程序/总体的平均 CPU 使用率 | 每个执行程序每分钟使用的 CPU 百分比 | 每分钟百分比 |
| 每个主机的平均已使用直接内存 (MB) | 每个执行程序每分钟的平均已使用直接内存 | MB/分钟 |
| 每个主机溢出的内存 | 每个执行程序的平均溢出内存 | MB/分钟 |
| 监视数据倾斜对持续时间的影响 | 对任务持续时间的第 70 到 90 个百分位和 90 到 100 个百分位的范围和差额进行衡量 | 100%、90% 和 70% 之间的净差额;100%、90% 和 70% 之间的百分比差额 |
确定如何将合并到 GZIP 存档文件中的客户输入与特定 Azure Databricks 输出文件相关联,因为 Azure Databricks 会将整个批处理操作作为一个单元处理。 此处,你将粒度用于跟踪。 还可使用自定义指标来跟踪原始输入文件的一个输出文件。
有关每个指标的更详细定义,请参阅此网站上仪表板中的可视化效果,或参阅 Apache Spark 文档中的指标部分。
评估性能优化选项
基线定义
你和开发团队应建立基线,以便可以比较未来的应用程序状态。
以定量方式测量应用程序的性能。 在此方案中,关键指标是作业延迟,这是大多数数据预处理和引入的典型值。 尝试加快数据处理时间并侧重于测量延迟,如下图所示:

测量作业的执行延迟:粗略查看总体作业性能,以及作业从开始到完成(microbatch 时间)的执行持续时间。 在上图中,19:30 标记处大约需要 40 秒时间来处理作业。
如果进一步查看这 40 秒,会看到以下阶段的数据:
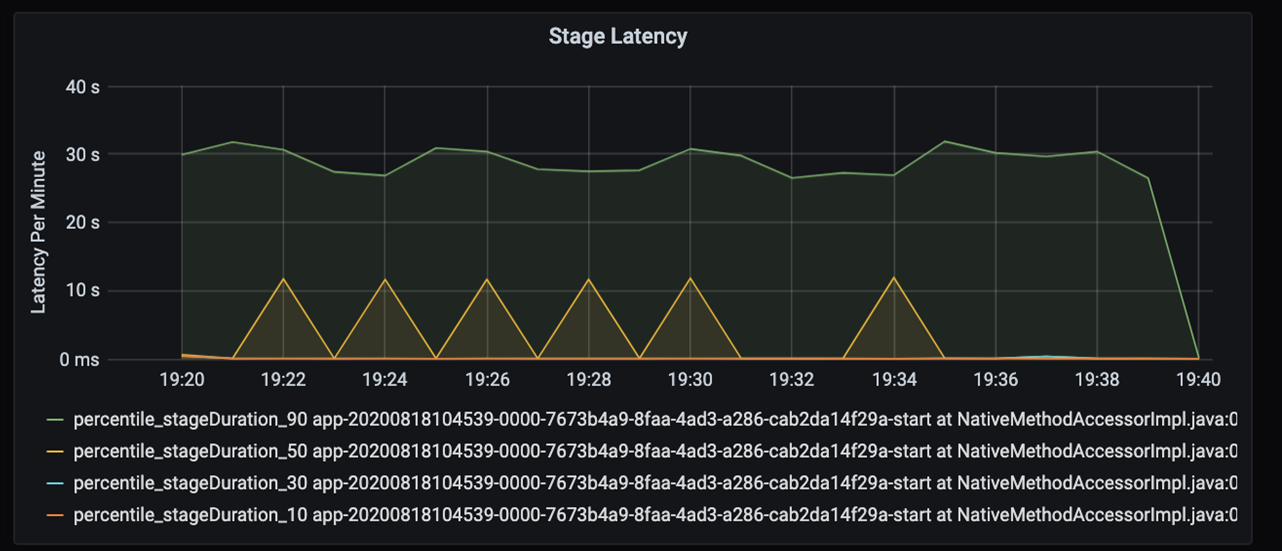
在 19:30 标记处有两个阶段:橙色阶段为 10 秒,绿色阶段为 30 秒。 监视阶段是否达到峰值,因为峰值指示阶段存在延迟。
当特定阶段运行缓慢时开展调查。 在分区方案中,通常至少有两个阶段:一个阶段读取文件,另一个阶段是随机、分区和写入文件。 如果在写入阶段的阶段延迟较高,则在分区过程中可能会出现瓶颈问题。
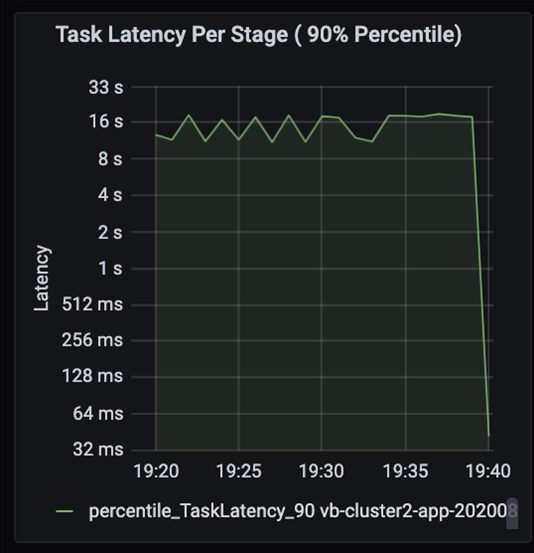
观察任务,因为作业的各个阶段按顺序执行,早期阶段会阻止后期阶段。 在一个阶段内,如果一个任务执行的随机分区比其他任务慢,则群集中的所有任务都必须等待较慢的任务完成后才能完成此阶段。 然后,我们的任务是一种监视数据倾斜和可能瓶颈的方法。 可以在上图中看到,所有任务都均匀分布。
现在监视处理时间。 由于有流式处理方案,因此请看流式处理吞吐量。
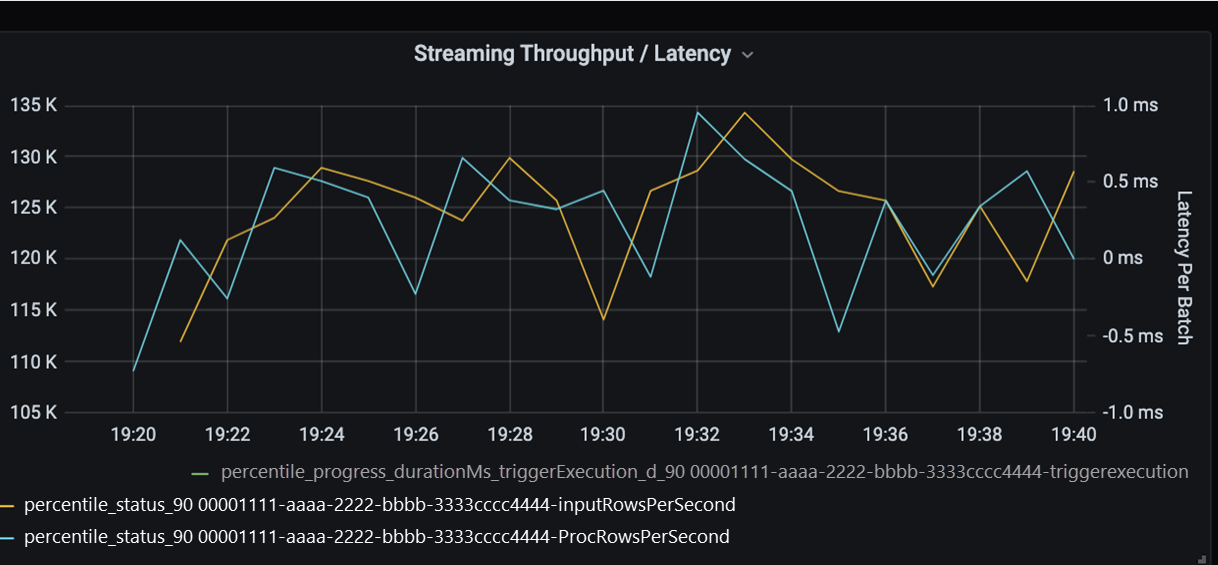
在以上“流式处理吞吐量/批处理延迟”图表中,橙色线表示输入速率(每秒输入行数)。 蓝色线表示处理速率(每秒处理的行数)。 在某些时候,处理速率赶不上输入速率。 这就导致输入文件在队列中堆积的潜在问题。
由于图中的处理速率与输入速率不匹配,因此,请考虑提高处理速率以完全涵盖输入速率。 一个可能的原因是,每个分区键中的客户数据不平衡会导致瓶颈。 在下一步和潜在解决方案中,请利用 Azure Databricks 的可伸缩性。
分区调查
首先,进一步确定 Azure Databricks 所需的缩放执行程序的正确数目。 应用在运行执行程序中将每个分区分配给专用 CPU 的经验法则。 例如,如果有 200 个分区键,则 CPU 数量乘以执行程序数量应等于 200。 (例如,8 个 CPU 与 25 个执行程序的组合是一种很好的搭配。)使用 200 个分区键时,每个执行程序只能处理一个任务,这可以减少出现瓶颈的机会。
由于此方案中有一些慢速分区,因此请调查任务持续时间中的高差异。 检查任务持续时间中是否有峰值。 一个任务处理一个分区。 如果任务需要更多时间,则分区可能太大,导致瓶颈。
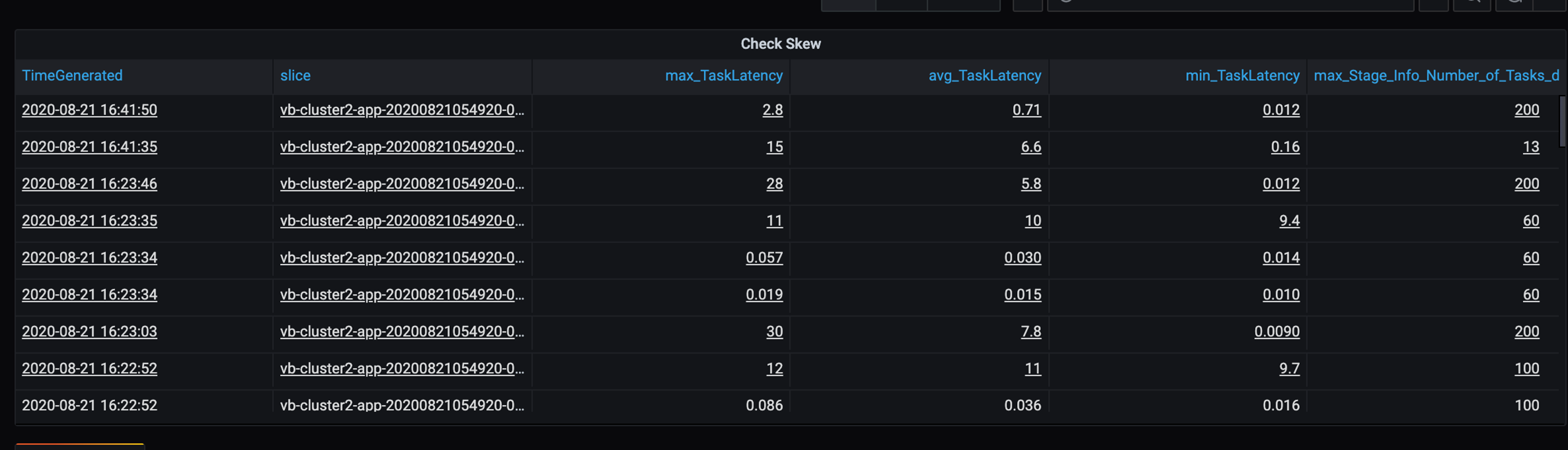
错误跟踪
添加错误跟踪仪表板,以便发现特定于客户的数据失败。 在数据预处理中,有时文件已损坏,并且文件内的记录与数据架构不匹配。 以下仪表板捕获了许多错误文件和错误记录。

此仪表板显示有待调试的错误计数、错误消息和任务 ID。 在消息中,可以轻松地将错误回溯至错误文件。 读取时发现几个文件出错。 查看顶部时间线,并调查图形中的特定点(16:20 和 16:40)。
其他瓶颈
有关更多示例和指南,请参阅对 Azure Databricks 中的性能瓶颈进行故障排除。
性能优化评估摘要
对于此方案,这些指标确定了以下观察结果:
- 在阶段延迟图表中,写入阶段耗费了大部分处理时间。
- 在任务延迟图表中,任务延迟稳定。
- 在流式处理吞吐量图表中,某些点的输出速率低于输入速率。
- 在任务的持续时间表中,由于客户数据不平衡,任务存在差异。
- 要在分区阶段获得优化的性能,缩放执行程序的数量应匹配分区数。
- 存在跟踪错误,例如文件错误和记录错误。
为了诊断这些问题,你使用了以下指标:
- 作业延迟
- 阶段延迟
- 任务延迟
- 流式处理吞吐量
- 每个阶段的任务持续时间(最大值、平均值、最小值)
- 错误跟踪(计数、消息、任务 ID)
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- David McGhee | 首席项目经理
要查看非公开的 LinkedIn 个人资料,请登录到 LinkedIn。
后续步骤
- 请阅读 Log Analytics 教程。
- 监视 Azure Log Analytics 工作区中的 Azure Databricks
- 部署具有 Spark 指标的 Azure Log Analytics
- 可观测性模式