自然语言处理(NLP)有许多应用程序,例如情绪分析、主题检测、语言检测、关键短语提取和文档分类。
具体而言,NLP 可用于:
- 例如,将文档分类为敏感或垃圾邮件。
- 使用 NLP 输出执行后续处理或搜索。
- 通过标识文档中的实体来汇总文本。
- 使用关键字标记文档,并利用标识的实体。
- 通过标记进行基于内容的搜索和检索。
- 使用标识的实体汇总文档的关键主题。
- 使用检测到的主题对文档进行分类,以便导航。
- 根据选定的主题枚举相关文档。
- 评估文本情绪以了解其积极或消极的语气。
通过技术的进步,NLP 不仅可以用于对文本数据进行分类和分析,还可以增强跨不同领域可解释的 AI 功能。 大型语言模型(LLM)的集成极大地增强了 NLP 的功能。 GPT 和 BERT 等 LLM 可以生成类似人、上下文感知的文本,使它们对复杂的语言处理任务非常有效。 它们通过处理更广泛的认知任务来补充现有的 NLP 技术,这些任务可改善聊天系统和客户参与度,尤其是与 Databricks 的 Dolly 2.0等模型配合使用。
语言模型与 NLP 之间的关系和差异
NLP 是一个综合领域,包含处理人类语言的各种技术。 相比之下,语言模型是 NLP 中的特定子集,侧重于深度学习来执行高级语言任务。 虽然语言模型通过提供高级文本生成和理解功能来增强 NLP,但它们与 NLP 不同义。 相反,它们充当更广泛的 NLP 域中的强大工具,可实现更复杂的语言处理。
注意
本文重点介绍 NLP。 NLP 与语言模型之间的关系表明,语言模型通过语言理解和生成功能增强 NLP 过程。
Apache®、Apache Spark 和火焰徽标是 Apache Software Foundation 在美国和/或其他国家/地区的商标或注册商标。 使用这些标记并不暗示获得 Apache Software Foundation 的认可。
可能的用例
可从自定义 NLP 中受益的业务方案包括:
- 为金融、医疗保健、零售、政府和其他部门的手写或机器创建的文档提供文档智能。
- 用于文本处理的与行业无关的 NLP 任务,例如命名实体识别 (NER)、分类、摘要和关系提取。 这些任务使检索、标识和分析文档信息(如文本和非结构化数据)的过程自动化。 这些任务的示例包括风险分层模型、本体分类和零售摘要。
- 用于语义搜索的信息检索和知识图创建。 借助此功能,可以创建支持药物发现和临床试验的医学知识图。
- 在零售、金融、旅游和其他行业面向客户的应用程序中,为对话式 AI 系统提供文本翻译。
- 分析中的情绪和增强的情感智能,特别是用于监视品牌感知和客户反馈分析。
- 自动生成报表。 从结构化数据输入合成和生成全面的文本报告,帮助财务和合规性等部门提供彻底的文档。
- 通过集成 NLP 进行语音识别和自然对话功能,通过语音激活接口增强 IoT 和智能设备应用程序中的用户交互。
- 适应语言模型,动态调整语言输出以适应各种受众理解级别,这对教育内容和辅助功能改进至关重要。
- 网络安全文本分析,实时分析通信模式和语言使用情况,以识别数字通信中的潜在安全威胁,从而改进网络钓鱼尝试或错误信息的检测。
作为自定义 NLP 框架的 Apache Spark
Apache Spark 是一个功能强大的并行处理框架,通过内存中处理来增强大数据分析应用程序的性能。 Azure Synapse Analytics、Azure HDInsight,Azure Databricks 继续提供对 Spark 的处理功能的可靠访问,确保大规模数据操作的无缝执行。
对于自定义的 NLP 工作负载,Spark NLP 仍然是能够处理大量文本的有效框架。 此开源库通过 Python、Java 和 Scala 库提供广泛的功能,这些库提供在著名的 NLP 库(如 spaCy 和 NLTK)中找到的复杂度。 Spark NLP 包括高级功能,如拼写检查、情绪分析和文档分类,一致地确保最先进的准确性和可伸缩性。
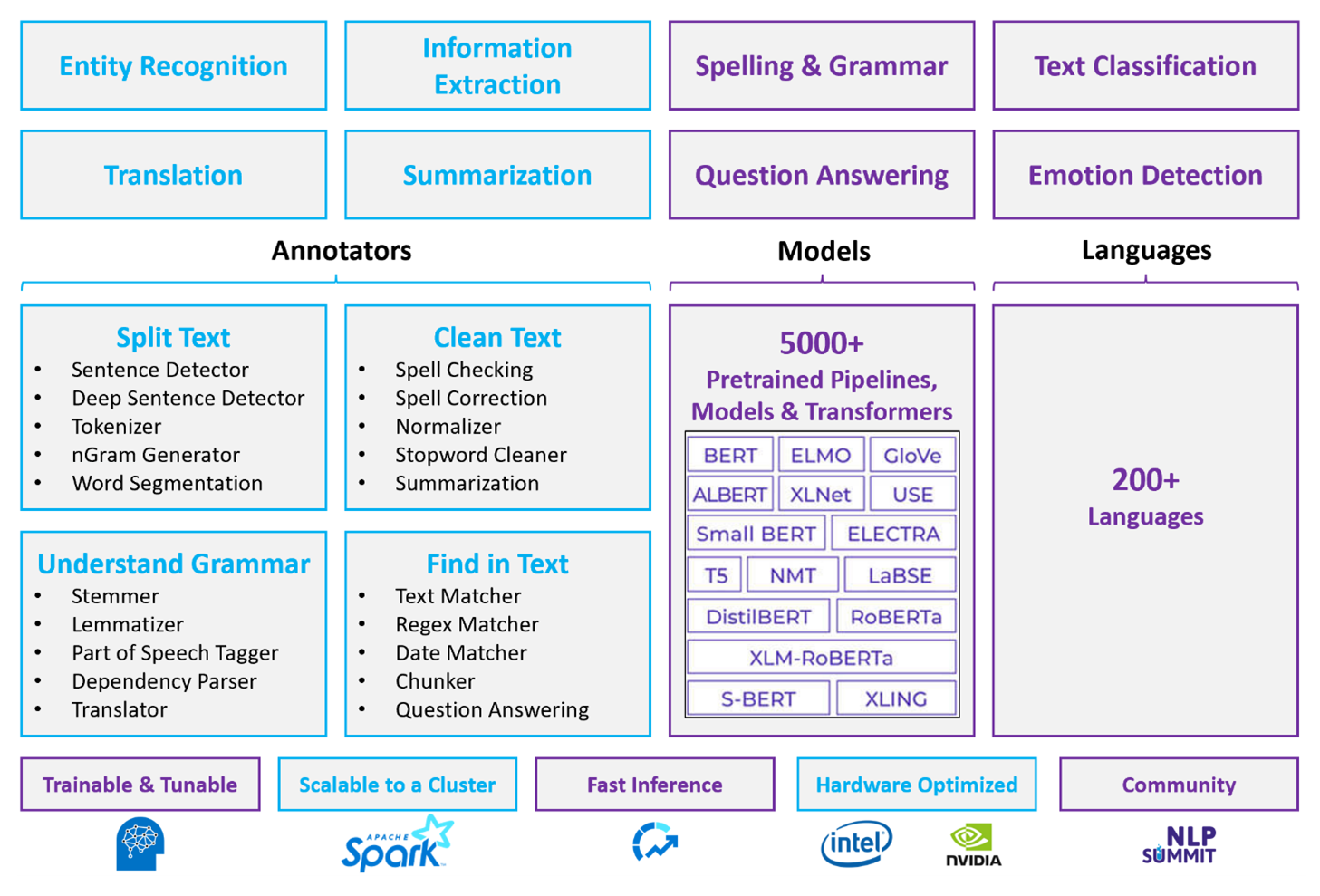
最近的公共基准测试突出了 Spark NLP 的性能,显示其他库的显著速度改进,同时保持了训练自定义模型的可比准确性。 值得注意的是,Llama-2 模型与 OpenAI Whisper 的集成增强了对话界面和多语言语音识别,这标志着优化处理功能的重大进展。
唯一的是,Spark NLP 有效地利用分布式 Spark 群集,充当直接在数据帧上运行的 Spark ML 的本机扩展。 此集成支持增强群集的性能提升,有助于为文档分类和风险预测等任务创建统一的 NLP 和机器学习管道。 引入 MPNet 嵌入和广泛的 ONNX 支持进一步丰富了这些功能,从而实现精确和上下文感知的处理。
除了性能优势之外,Spark NLP 在扩展的 NLP 任务数组中提供最先进的准确性。 该库附带预生成的深度学习模型,用于命名实体识别、文档分类、情绪检测等。 其功能丰富的设计包括预先训练的语言模型,支持单词、区块、句子和文档嵌入。
借助针对 CPU、GPU 和最新 Intel Xeon 芯片的优化版本,Spark NLP 的基础结构旨在实现可伸缩性,使训练和推理过程能够充分利用 Spark 群集。 这可确保跨各种环境和应用程序高效处理 NLP 任务,保持其在 NLP 创新前沿的地位。
挑战
处理资源: 处理自由格式文本文档的集合需要大量的计算资源,并且处理也非常耗时。 此类处理通常涉及 GPU 计算部署。 最近的改进(例如支持量化的 Llama-2 等 Spark NLP 体系结构中的优化),有助于简化这些密集型任务,使资源分配更高效。
标准化问题: 没有标准化文档格式,使用自由格式文本处理从文档中提取特定事实时,很难实现一致准确的结果。 例如,从各种发票中提取发票编号和日期会带来挑战。 可适应的 NLP 模型(如 M2M100)的集成改进了多种语言和格式的处理准确性,从而提高了结果的一致性。
数据多样性和复杂性: 解决各种文档结构和语言细微差别仍然很复杂。 MPNet 嵌入等创新提供了增强的上下文理解,提供对各种文本格式的更直观的处理,并提高整体数据处理可靠性。
关键选择条件
在 Azure 中,Spark 服务(如 Azure Databricks、Microsoft Fabric 和 Azure HDInsight)在与 Spark NLP 一起使用时提供 NLP 功能。 Azure AI 服务是 NLP 功能的另一个选项。 要确定要使用的服务,请考虑以下问题:
是否要使用预生成或预训练的模型? 如果是,请考虑使用 Azure AI 服务提供的 API,或通过 Spark NLP 下载所选模型,它现在包括高级模型(如 Llama-2 和 MPNet)以提高功能。
是否需要针对大型文本数据语料库训练自定义模型? 如果是,请考虑将 Azure Databricks、Microsoft Fabric 或 Azure HDInsight 与 Spark NLP 配合使用。 这些平台提供广泛的模型训练所需的计算能力和灵活性。
是否需要低级别 NLP 功能,如词汇切分、词干分解、词形还原和词频/逆文档频率 (TF/IDF)? 如果是,请考虑将 Azure Databricks、Microsoft Fabric 或 Azure HDInsight 与 Spark NLP 配合使用。 或者,在所选的处理工具中使用开源软件库。
是否需要简单的高级别 NLP 功能,如实体和意图识别、主题检测、拼写检查或情绪分析? 如果是,请考虑使用 Azure AI 服务提供的 API。 或者通过 Spark NLP 下载所选模型,以利用预生成函数执行这些任务。
功能矩阵
以下各表汇总了 NLP 服务功能上的关键差异。
常规功能
| 功能 | Spark 服务 (Azure Databricks, Microsoft Fabric, Azure HDInsight) 与 Spark NLP | Azure AI 服务 |
|---|---|---|
| 提供预先训练的模型作为服务 | 是 | 是 |
| REST API | 是 | 是 |
| 可编程性 | Python、Scala | 有关支持的语言,请参阅其他资源 |
| 支持处理大型数据集和大型文档 | 是 | 否 |
低级 NLP 功能
批注器的功能
| 功能 | Spark 服务 (Azure Databricks, Microsoft Fabric, Azure HDInsight) 与 Spark NLP | Azure AI 服务 |
|---|---|---|
| 句子检测程序 | 是 | 否 |
| 深度句子检测程序 | 是 | 是 |
| 分词器 | 是 | 是 |
| N-gram 生成器 | 是 | 否 |
| 字分段 | 是 | 是 |
| 词干分析器 | 是 | 否 |
| 词形还原工具 | 是 | 否 |
| 词性标记 | 是 | 否 |
| 依赖项分析程序 | 是 | 否 |
| 翻译 | 是 | 否 |
| 非索引字清理器 | 是 | 否 |
| 拼写更正 | 是 | 否 |
| 标准化程序 | 是 | 是 |
| 文本匹配程序 | 是 | 否 |
| TF/IDF | 是 | 否 |
| 正则表达式匹配程序 | 是 | 嵌入对话语言理解 (CLU) |
| 日期匹配程序 | 是 | 可通过 DateTime 识别器在 CLU 中实现 |
| Chunker | 是 | 否 |
注意
Microsoft语言理解(LUIS)将于 2025 年 10 月 1 日停用。 鼓励现有 LUIS 应用程序迁移到对话语言理解(CLU),这是 Azure AI Services for Language 的功能,可增强语言理解功能并提供新功能。
高级 NLP 功能
| 功能 | Spark 服务 (Azure Databricks, Microsoft Fabric, Azure HDInsight) 与 Spark NLP | Azure AI 服务 |
|---|---|---|
| 拼写检查 | 是 | 否 |
| 汇总 | 是 | 是 |
| 问答 | 是 | 是 |
| 情绪检测 | 是 | 是 |
| 情感检测 | 是 | 支持观点挖掘 |
| 标记分类 | 是 | 是,通过自定义模型 |
| 文本分类 | 是 | 是,通过自定义模型 |
| 文本表示形式 | 是 | 否 |
| NER | 是 | 是 - 文本分析提供一组 NER,自定义模型用于实体识别 |
| 实体识别 | 是 | 是,通过自定义模型 |
| 语言检测 | 是 | 是 |
| 支持除英语以外的语言 | 是,支持 200 多种语言 | 是,支持的语言超过 97 种 |
在 Azure 中设置 Spark NLP
要安装 Spark NLP,请使用以下代码,但将 <version> 替换为最新版本号。 有关详细信息,请参阅 Spark NLP 文档。
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
开发 NLP 管道
对于 NLP 管道的执行顺序,Spark NLP 遵循与传统 Spark ML 机器学习模型相同的开发概念,并应用专门的 NLP 技术。
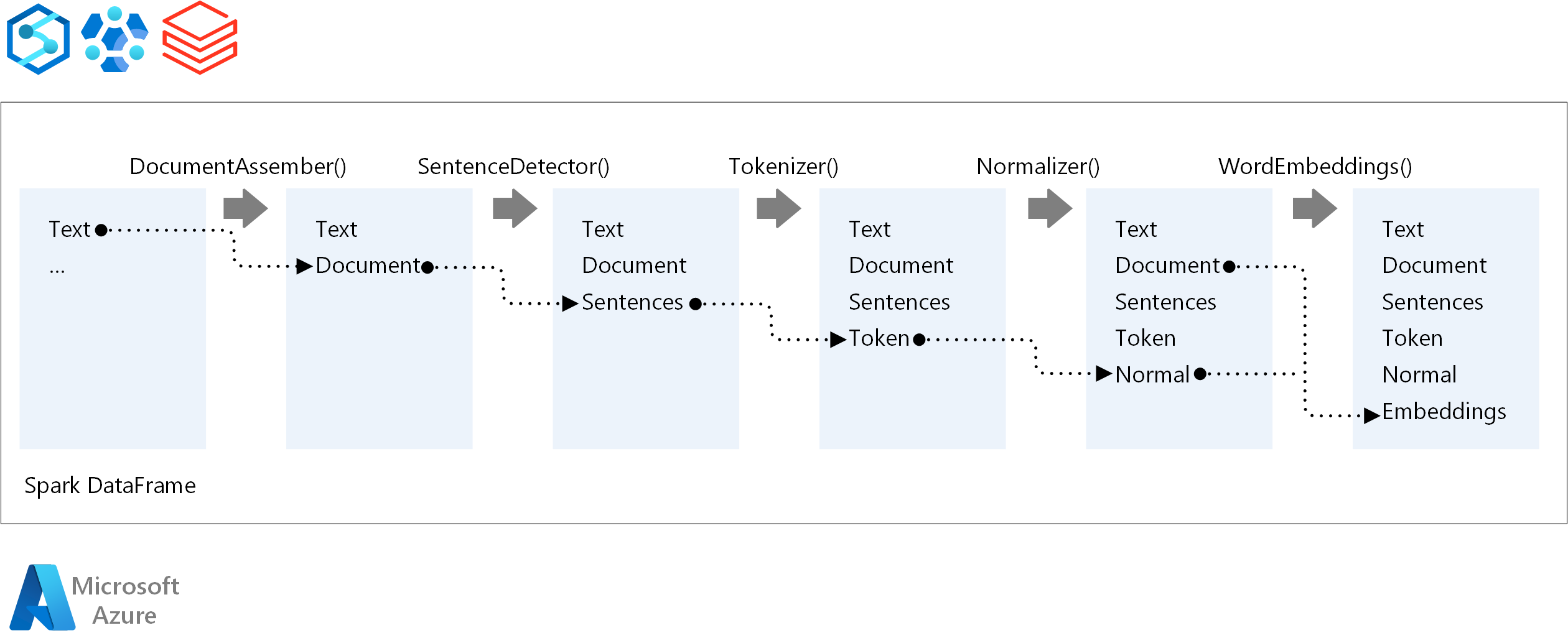
Spark NLP 管道的核心组件是:
DocumentAssembler:将数据转换为 Spark NLP 可以处理的格式来准备数据的转换器。 此阶段是每个 Spark NLP 管道的入口点。 DocumentAssembler 读取
String列或Array[String],其中包含使用默认关闭setCleanupMode预处理文本的选项。SentenceDetector:使用预定义方法标识句子边界的批注器。 当
Array设置为 true 时,它可以返回explodeSentences中检测到的每个句子,也可以在单独的行中返回。Tokenizer:将原始文本划分为离散标记(单词、数字和符号)的批注器,将其作为
TokenizedSentence。 Tokenizer 是非拟合的,并使用RuleFactory中的输入配置来创建标记规则。 当默认值不足时,可以添加自定义规则。Normalizer:一个使用优化令牌任务的批注器。 Normalizer 将正则表达式和字典转换应用于清理文本并删除多余的字符。
WordEmbeddings:将令牌映射到矢量的查找批注器,从而促进语义处理。 可以使用
setStoragePath指定自定义嵌入字典,其中每行都包含一个标记及其向量,用空格分隔。 未解析的令牌默认为零向量。
Spark NLP 利用 Spark MLlib 管道,MLflow提供本机支持,这是一个开源平台,用于管理机器学习生命周期。 MLflow 的关键组件包括:
MLflow 跟踪:记录实验性运行,并提供可靠的查询功能来分析结果。
MLflow 项目:支持在各种平台上执行数据科学代码,从而提高可移植性和可重现性。
MLflow 模型:通过一致的框架支持跨不同环境的通用模型部署。
模型注册表:提供全面的模型管理,集中存储版本以简化访问和部署,促进生产就绪。
MLflow 与 Azure Databricks 等平台集成,但也可安装在其他基于 Spark 的环境中来管理和跟踪试验。 此集成允许使用 MLflow 模型注册表使模型可用于生产目的,从而简化部署过程和维护模型治理。
通过将 MLflow 与 Spark NLP 结合使用,可以确保高效管理和部署 NLP 管道,同时满足可伸缩性和集成的新式要求,同时支持单词嵌入和大型语言模型适应等高级技术。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- 弗雷迪·阿亚拉 |云解决方案架构师
- Moritz Steller | 高级云解决方案架构师
后续步骤
Spark NLP 文档:
Azure 组件:
fabric Microsoft - Azure HDInsight
- Azure Databricks
- 认知服务
学习资源: