经验
- 确保所涉及的各方都了解高可用性(HA)与灾难恢复(DR)之间的差异:常见的陷阱是混淆这两个概念,并不匹配与之关联的解决方案。
- 与业务利益干系人就定义恢复点目标 (RPO) 和恢复时间目标 (RTO) 的以下方面探讨相关期望:
- 他们可以容忍多少停机时间,请记住,通常,恢复速度越快,成本就越高。
- 他们希望在何种类型的事件中得到保护,同时要考虑到对应事件类型的相关可能性。 例如,服务器发生故障的概率高于影响整个区域的所有数据中心的自然灾害。
- 系统不可用对其业务有何影响?
- 解决方案的运营费用(OPEX)预算正在推进。
- 考虑最终用户可以接受哪些降级服务选项。 此类选项可能包括:
- 即使没有最新的数据(如果引入管道不起作用)也仍有权访问可视化仪表板,最终用户仍有权访问其数据。
- 具有读取访问权限,但没有写入访问权限。
- 目标 RTO 和 RPO 指标可以定义选择实现的灾难恢复策略:
- 活动/活动。
- 主动/被动。
- 灾难时主动/重新部署。
- 考虑自己的 复合服务级别目标(SLO), 以考虑可容忍的停机时间。
- 请务必了解可能影响系统可用性的所有组件,例如:
- 标识管理。
- 网络拓扑。
- 机密/密钥管理。
- 数据源。
- 自动化/作业计划程序。
- 源存储库和部署管道(GitHub、Azure DevOps)。
- 及早检测到中断也可以显著降低 RTO 和 RPO 值。 以下是应该考虑到的几个方面:
- 定义什么是中断及其与 Microsoft 的中断定义之间的对应关系。 Microsoft 定义可在产品或服务级别的 Azure 服务级别协议 (SLA) 页面获取。
- 使用负责任的团队高效监视和警报系统,及时查看这些指标和警报有助于实现目标。
- 根据订阅设计,用于灾难恢复的额外基础结构可以存储在原始订阅中。 平台即服务(PaaS)服务(如 Azure Data Lake Storage Gen2 或Azure 数据工厂通常具有本机功能,允许故障转移到其他区域中的辅助实例,同时保留在原始订阅中。 某些客户可能需要考虑为仅在 DR 方案中用于成本目的的资源创建专用资源组。
- 应注意的是,订阅限制可能会约束此方法。
- 其他约束可能包括设计复杂性和管理控制,以确保 DR 资源组不用于常规业务(BAU)工作流。
- 根据解决方案的重要性和依赖项设计 DR 工作流。 例如,不要尝试在数据仓库启动并运行之前重新生成Azure 分析服务实例,因为它触发错误。 稍后请离开开发实验室,首先恢复核心企业解决方案。
- 尝试确定可跨解决方案并行化的恢复任务,减少 RTO 总数。
- 如果在解决方案中使用 Azure 数据工厂,请记得在范围中包含自承载集成运行时。 Azure Site Recovery 非常适合这些计算机。
- 应尽可能地自动化人工操作,以避免人为错误,尤其是在承受压力的情况下。 建议:
- 通过 Bicep、ARM 模板或 PowerShell 脚本采用资源预配。
- 采用源代码和资源配置的版本控制。
- 使用 CI/CD 发布管道,而不是单击操作。
- 由于有故障转移计划,因此应考虑回退到主实例的过程。
- 定义明确的指示器和指标,以验证故障转移是否成功,解决方案已启动并运行,或者情况恢复正常(也称为主要功能)。
- 确定故障转移后,服务级别协议(SLA)是否应保持不变,或者是否允许降级服务。
- 此决策很大程度上取决于所支持的业务服务流程。 例如,房间预订系统的故障转移看起来与核心操作系统大相径庭。
- RTO/RPO 定义应基于特定的用户方案,而不是基于基础结构级别。 这样做可让你更精细地了解在发生中断或灾难时应首先恢复哪些进程和组件。
- 在继续执行故障转移之前,请确保在目标区域中包括容量检查:如果发生重大灾难,请注意,许多客户将尝试同时故障转移到同一配对区域,这可能会导致预配资源时出现延迟或争用。
- 如果这些风险不可接受,则应考虑主动/主动或主动/被动 DR 策略。
- 应创建和维护灾难恢复计划,以记录恢复过程和操作所有者。 另外,考虑到相关人员可能正在休假,所以请务必包括次要联系人。
- 应执行常规灾难恢复演练来验证 DR 计划工作流,使其满足所需的 RTO/RPO,并训练负责任的团队。
- 还应定期测试数据和配置备份,以确保其“适用”,能够支持任何恢复活动。
- 及早与负责网络、标识和资源预配的团队合作,可在关于以下方面的最佳解决方案上达成共识:
- 如何将用户和流量从主站点重定向到辅助站点。 可以评估 DNS 重定向等概念,或者使用特定工具(如Azure 流量管理器)。
- 如何及时安全地向辅助站点提供访问权限。
- 在灾难期间,参与方之间的有效沟通是计划高效快速执行的关键。 Teams 可能包括:
- 决策者。
- 事件响应团队。
- 受影响的内部用户和团队。
- 外部团队。
- 在正确的时间协调不同的资源将确保灾难恢复计划执行的效率。
注意事项
反模式
- 复制/粘贴本文系列 本系列旨在为客户提供指导,以查找特定于 Azure 的 DR 过程的下一级详细信息。 因此,文章基于通用的 Microsoft IP 和参考体系结构,而不是某一位客户特定的 Azure 实现。
虽然其中提供的详细内容能帮助大家扎实地理解基础信息,但客户必须先考虑自身的具体情况、实现和要求,然后才能获得“适用”的 DR 策略和流程。
将 DR 视为纯技术过程 业务利益干系人在定义 DR 要求和完成确认服务恢复所需的业务验证步骤方面发挥着关键作用。 确保业务利益干系人参与所有 DR 活动,可以建立“适用”、能展现业务价值且可执行的 DR 流程。
“一劳永逸”的 DR 计划 Azure 在不断发展变化,每位客户对各种组件和服务的使用也在不断变化。 “适用”的 DR 流程也必须随之发展。 无论是通过软件开发生命周期(SDLC)过程还是定期评审,客户都应定期重新审视其 DR 计划。 目标是确保服务恢复计划的有效性,并妥善处理各项组件、服务或解决方案间的所有变化。
基于理论的评估工作 虽然在现代数据生态系统中对 DR 事件进行端到端模拟会很困难,但应投入精力来尽可能地贴合涵盖受影响组件的完整模拟。 定期进行计划演练将建立组织所需的“肌肉记忆”,从而能够放心地执行 DR 计划。
依靠 Microsoft 来完成所有工作 在 Microsoft Azure 服务中,存在明确的责任划分,且由所用云服务层作为基础:
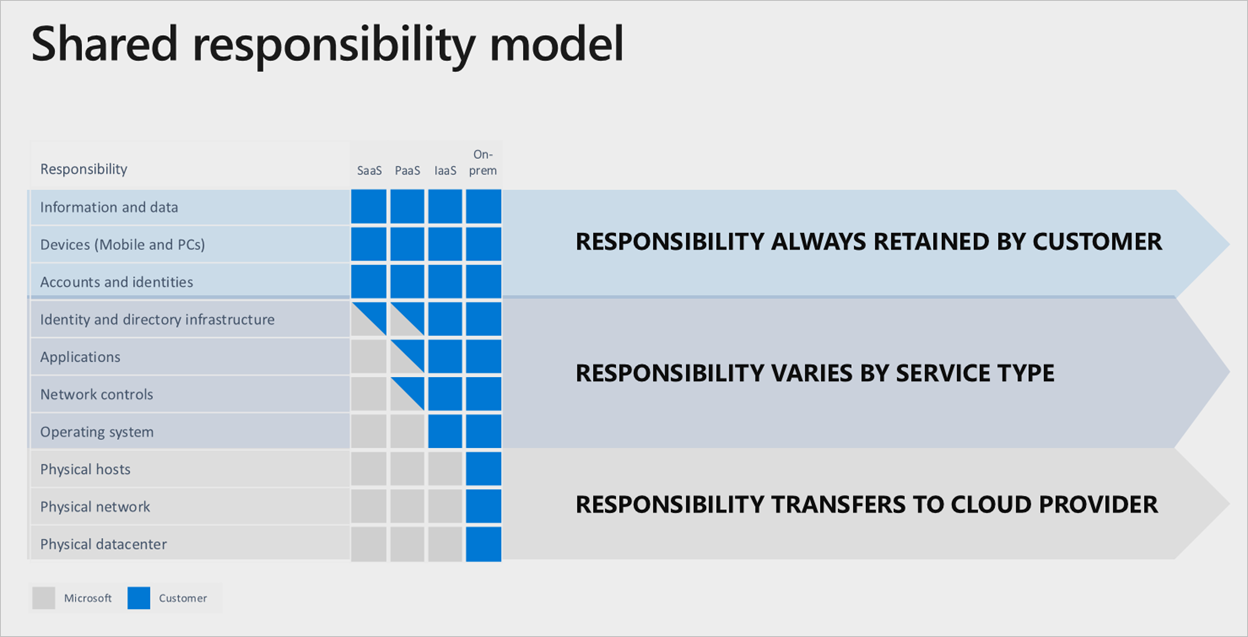 即使使用完整的软件即服务 (SaaS) 堆栈,客户仍会保留确保帐户、标识和数据以及用于与 Azure 服务交互的设备均正确/最新的责任。
即使使用完整的软件即服务 (SaaS) 堆栈,客户仍会保留确保帐户、标识和数据以及用于与 Azure 服务交互的设备均正确/最新的责任。
事件范围和策略
灾难事件范围
不同事件会产生不同的影响范围,因此应采用不同的响应措施。 下图对灾难事件的该方面进行了说明: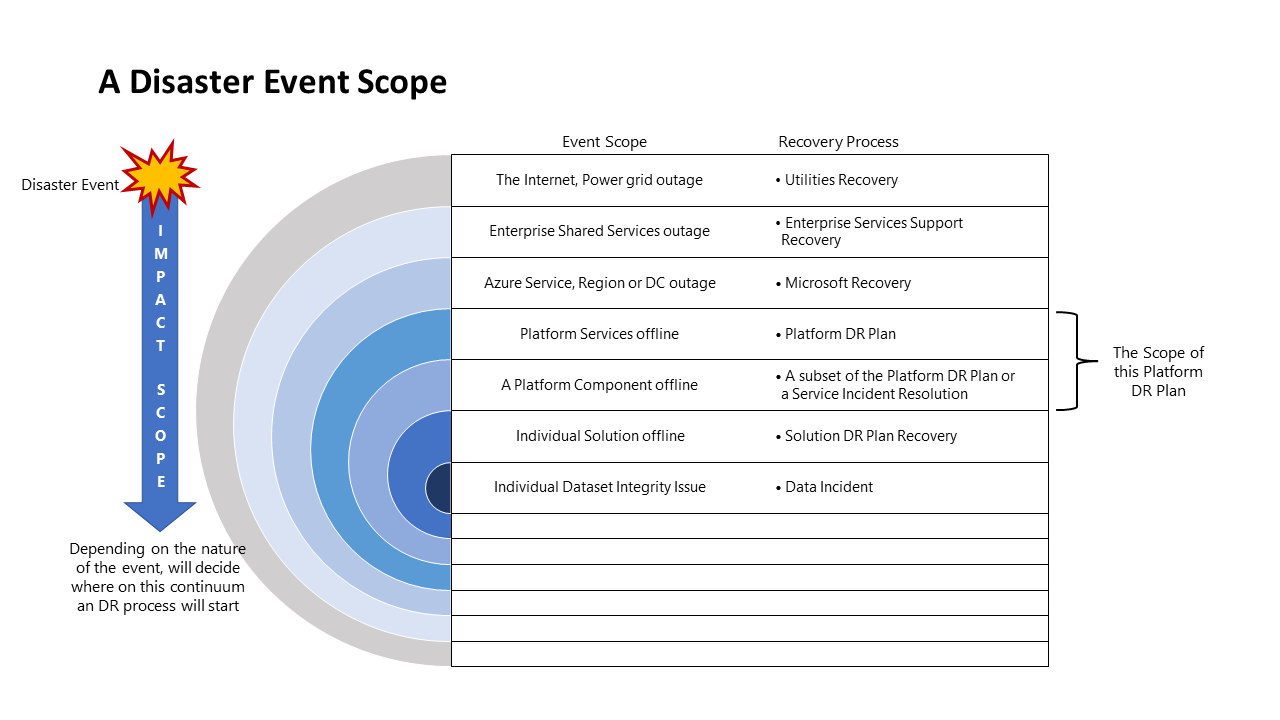
灾难策略选项
灾难恢复策略有四个高级选项:
- 等待 Microsoft 处理 - 顾名思义,在 Microsoft 完全恢复受影响区域的服务之前,该解决方案处于脱机状态。 恢复后,客户会验证解决方案,然后更新服务恢复。
- 在灾难 时重新部署 - 解决方案从头开始手动重新部署到可用区域中,发生灾难后事件。
- 暖备份(主动/被动) - 在备用区域创建辅助托管解决方案,并部署组件以保证最低容量(但组件不会接收生产流量)。 备用区域中的辅助服务可能会“关闭”或以较低的性能级别运行,直到发生 DR 事件等时间。
- 热备份(主动/主动) - 该解决方案托管在跨多个区域的主动/主动设置中。 辅助托管解决方案接收、处理数据并将其作为较大系统的一部分提供服务。
灾难恢复策略影响
虽然较高级别的服务复原能力所带来的运营成本通常是 DR 策略关键设计决策 (KDD) 的主导因素。 不过还有其他一些重要的考虑因素。
在此有效示例中,DR 方案涉及的是完整的 Azure 区域中断,会直接影响托管 Contoso 数据平台的主要区域。
在此中断中,对四种高级别 DR 策略的相对影响是: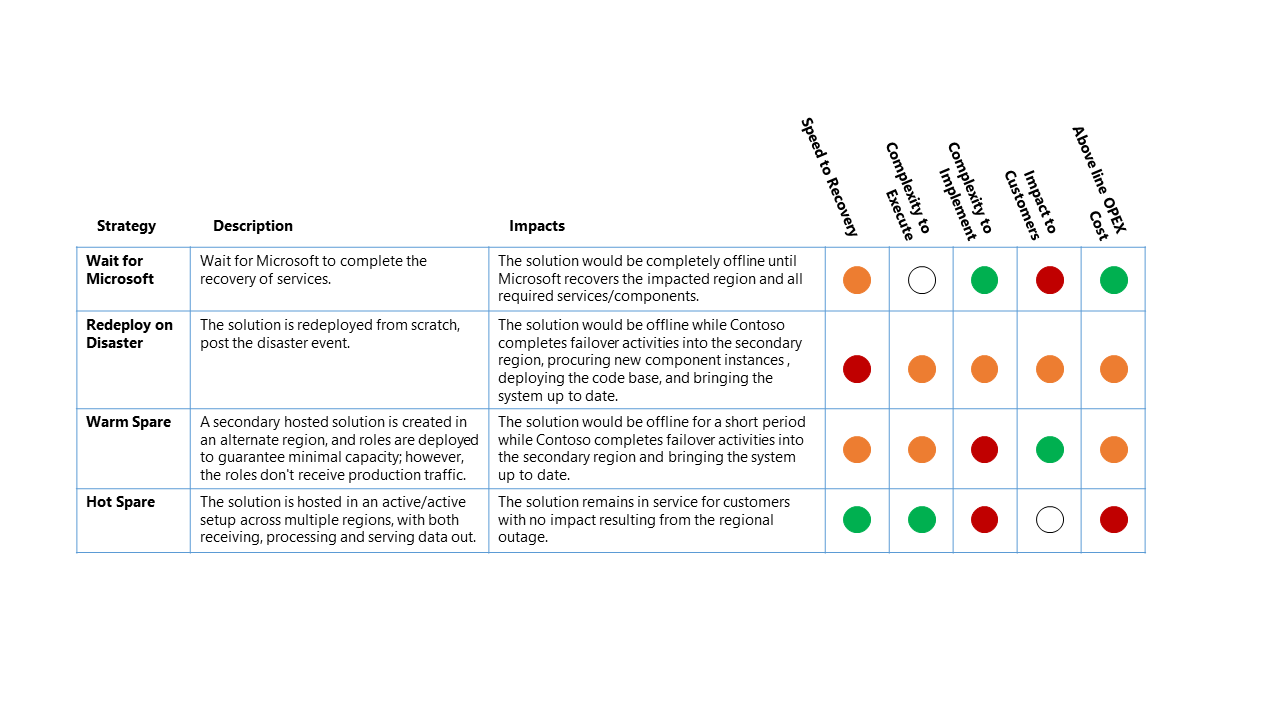
分类键
- 恢复时间目标(RTO): 从灾难事件到平台服务恢复的预期运行时间。
- 要执行的复杂性: 组织执行恢复活动的复杂性。
- 实现的复杂性: 组织实施 DR 策略的复杂性。
- 对客户的影响: 从 DR 策略对数据平台服务的客户产生直接影响。
- 上行 OPEX 成本:实施此策略所需的额外成本, 例如 Azure 的每月计费增加,用于支持所需的其他组件和额外资源。
注意
应将上表视为选项之间的比较 - 具有绿色指示器的策略比具有黄色或红色指示器的另一种策略更适合该分类。
后续步骤
现在你已了解与具体方案关联的建议,可以了解如何部署此方案