多租户系统在租户之间共享两个或更多资源。 由于租户使用相同的共享资源,一个租户的活动可能会对另一个租户使用系统产生负面影响。
问题描述
构建要由多个客户或租户共享的服务时,可将其构建为多租户服务。 多租户系统的优点是,可以在租户之间共用和共享资源。 这通常会降低成本并提高效率。 但是,如果单个租户使用的资源量与系统中可用的资源量不相称,系统的整体性能可能会降低。 当一个租户的性能由于另一个租户的活动而下降时,会出现“近邻干扰”问题。
假设有一个包含两个租户的示例多租户系统。 租户 A 的使用模式与租户 B 的使用模式一致。 在高峰时段,租户 A 使用系统的所有资源,这意味着租户 B 发出的任何请求都会失败。 换句话说,总资源使用量高于系统容量:
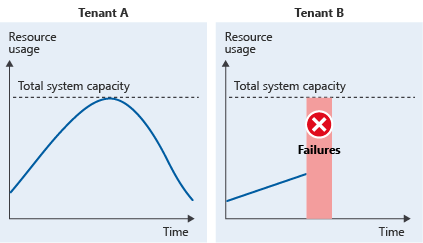
第一次收到的任何租户的请求都有可处于优先位置。 然后,另一个租户会遇到干扰性的邻居问题。 或者,这两个租户都可能会发现他们的性能受到影响。
即使每个租户消耗相对较少的系统容量,但许多租户的集体资源使用导致总体使用高峰,也会出现近邻干扰问题:
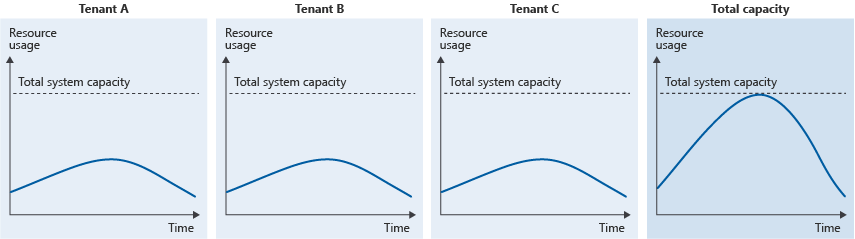
当你有多个租户,它们都具有类似的使用模式,或没有为系统上的总体负载预配足够的容量时,就可能发生这种情况。
如何解决问题
共享单一资源时,近邻干扰问题是多租户系统中的固有风险,无法完全消除受近邻干扰影响的可能。 但是,客户端和服务提供商都可以执行一些步骤以降低出现近邻干扰问题的可能性,或者在观察到这些问题时减轻其影响。
客户端可以执行的操作
- 确保应用程序处理 服务限制,从而减少对服务发出不必要的请求。 确保应用程序遵循良好做法以 重试收到暂时性故障响应的请求。
- 购买预留容量(如果可用)。 例如,使用 Azure Cosmos DB 时,购买预留吞吐量,使用 ExpressRoute 时,为对性能敏感的环境预配单独的线路。
- 迁移到服务的单租户实例,或迁移到具有更强隔离保证的服务层。 例如,使用服务总线时,迁移到高级层,使用 Azure Cache for Redis 时,预配标准或高级层缓存。
服务提供商可以执行的操作
- 监视系统的资源使用情况。 监视总体资源使用情况和每个租户使用的资源。 配置警报以检测资源使用高峰,如果可能,配置自动化以便通过纵向扩展和缩减来自动缓解已知问题。
- 应用资源治理。 考虑应用策略以避免单个租户耗尽系统资源,并考虑减少他人的可用容量。 这一步可以采用配额强制执行的形式(通过限制模式或速率限制模式)。
- 预配更多基础结构。 这一过程可能涉及到通过升级某些解决方案组件来进行纵向扩展,也可能涉及到通过预配额外的分片(按照对模式进行分片操作)或缩放单元(按照部署缩放单元模式)来进行横向扩展。
- 使租户能够购买预配或预留容量。 此容量可以让租户更确信你的解决方案可以妥善处理其工作负载。
- 拉平租户的资源使用情况。 例如,可以试用以下方法之一:
- 如果托管解决方案的多个实例,请考虑在实例或缩放单元之间重新平衡租户。 例如,考虑将具有可预测的类似使用模式的租户置于多个缩放单元中,从而拉平使用情况高峰。
- 考虑是否具有对时间不敏感的后台进程或资源密集型工作负载。 在非高峰时间异步运行这些工作负载,从而为时间敏感型工作负载保留高峰资源容量。
- 检查下游服务是否提供可缓解近邻干扰问题的控件。 例如,使用 Kubernetes 时,请考虑使用 pod 限制,使用 Service Fabric 时,请考虑使用内置的治理功能。
- 限制租户可执行的操作。 例如,限制租户执行将运行非常大的数据库查询的操作,例如通过指定查询的最大可返回记录计数或时间限制。 此操作可以降低租户采取可能对其他租户产生负面影响的操作的风险。
- 提供服务质量(QoS)系统。 应用 QoS 时,会优先处理某些进程或工作负载。 通过将 QoS 纳入设计和体系结构,可以确保在资源面临压力时优先处理高优先级操作。
注意事项
在大多数情况下,单个租户并非有意造成近邻干扰问题。 单个租户甚至可能不会意识到其工作负载会给他人带来近邻干扰问题。 但是,一些租户也可能利用共享组件中的漏洞攻击服务,单独或通过执行分布式拒绝服务 (DDoS) 攻击来实现这一点。
无论原因是什么,都应将这些问题视为资源调控问题,并应用使用配额、限制和治理控制措施来缓解问题。
注意
请确保将你应用的任何限制或服务的任何使用配额告知客户端。 确保它们可靠地处理失败的请求,而不会对你应用的任何限制或配额感到惊讶,这一点很重要。
如何检测问题
从客户端的角度来看,近邻干扰问题通常表现为服务请求失败或需要很长时间才能完成请求。 尤其是,如果相同的请求在其他时间成功且似乎随机失败,可能存在近邻干扰问题。 客户端应用程序应记录遥测以跟踪服务请求的成功率和性能,并且应用程序还应记录基线性能指标以用于比较。
从服务的角度看,近邻干扰问题可能以几种方式出现:
- 资源使用高峰。 务必清楚地了解常规的基线资源使用量,并配置监视和警报来检测资源使用高峰。 务必考虑可能影响服务性能或可用性的所有资源。 这些资源包括服务器 CPU 和内存使用量、磁盘 IO、数据库使用情况、网络流量等指标,以及由托管服务公开的指标(例如请求数),以及综合和抽象性能指标(例如 Azure Cosmos DB 请求单位数)。
- 为租户执行操作时失败。 具体来说,查找租户未使用大部分系统资源时发生的故障。 此类模式可能表示租户是近邻干扰问题的受害者。 考虑按租户跟踪资源使用情况。 例如,使用 Azure Cosmos DB 时,请考虑记录用于每个请求的请求单位,并将租户的标识符作为维度添加到遥测,以便可以聚合每个租户的请求单位使用情况。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- John Downs | 首席软件工程师
其他参与者:
- Chad Kittel | 首席软件工程师
- Paolo Salvatori | FastTrack for Azure 首席客户工程师
- 丹尼尔·斯科特-伦斯福德|高级合作伙伴技术解决方案顾问
- 阿森·弗拉基米尔斯基|首席工程师,FastTrack for Azure
要查看非公开的 LinkedIn 个人资料,请登录到 LinkedIn。