你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
RAG 生成嵌入阶段
在检索增强生成 (RAG) 解决方案的前面步骤中,将文档划分为区块并扩充了区块。 在此步骤中,将为这些区块和计划对其执行矢量搜索的任何元数据字段生成嵌入内容。
本文是系列文章的一部分。 阅读简介。
嵌入是对象的数学表示形式,如文本。 训练神经网络时,会创建对象的许多表示形式。 每个表示形式都与网络中的其他对象建立连接。 嵌入很重要,因为它捕获对象的语义含义。
一个对象的表示形式与其他对象的表示形式有连接,因此你可以以数学方式比较对象。 以下示例演示嵌入如何捕捉语义及其相互之间的关系:
embedding (king) - embedding (man) + embedding (woman) = embedding (queen)
嵌入会使用相似性和距离的概念来相互比较。 以下网格显示了嵌入的比较。
展示矢量比较的 
在 RAG 解决方案中,通常使用与区块相同的嵌入模型来嵌入用户查询。 然后,在数据库中搜索相关向量,以返回与语义上最相关的区块。 相关区块的原始文本作为基础数据传递到语言模型。
注意
矢量以允许数学比较的方式表示文本的语义含义。 必须清理区块,以便矢量之间的数学邻近度准确反映其语义相关性。
嵌入模型的重要性
所选的嵌入模型可能会显著影响矢量搜索结果的相关性。 你必须考虑嵌入模型的词汇。 每个嵌入模型都使用特定的词汇进行训练。 例如,BERT 模型 的词汇大小约为 30,000 个单词。
嵌入模型的词汇非常重要,因为它以独特的方式处理不在词汇中的字词。 如果某个单词不在模型的词汇中,它仍会为其计算向量。 为此,许多模型将单词分解为子词。 它们将子词视为不同的标记,或者聚合子词的向量以创建单个嵌入。
例如,他明 一词可能不在嵌入模型的词汇中。 非他明 一词具有语义意义,作为身体释放的化学物质,导致过敏症状。 嵌入模型不包含 histamine。 因此,它可以将单词分为词汇中的子词,例如 他的、ta,以及 我的。

这些子词的语义意义远非 安非他明的含义。 与模型词汇中 histamine 的情况相比,子词的单个或组合矢量值导致矢量匹配较差。
选择嵌入模型
确定用例的正确嵌入模型。 在选择嵌入模型时,请考虑嵌入模型的词汇和数据字词之间的重叠。

首先,确定你是否具有专门领域的内容。 例如,文档是否特定于用例、组织或行业? 确定域特定性的一个好方法是检查是否可以在 Internet 上找到内容中的实体和关键字。 如果你能做到,那么一个普通的嵌入模型也可能可以做到。
常规内容或非特定领域的内容
选择常规嵌入模型时,请从 Hugging Face 排行榜开始。 获取最新的嵌入模型排名。 评估模型处理数据的方式,并从排名靠前的模型开始。
特定于域的内容
对于特定于域的内容,请确定是否可以使用特定于域的模型。 例如,数据可能位于生物医学领域,因此可以使用 BioGPT 模型。 这种语言模型是在大量生物医学文献上进行预训练的。 你可以使用它进行生物医学文本挖掘和生成。 如果特定于域的模型可用,请评估这些模型如何处理数据。
如果您没有领域特定模型,或者领域模型性能不佳,您可以使用您的领域特定词汇微调通用嵌入模型。
重要
对于你选择的任何模型,需要验证许可证是否适合你的需求,并且该模型提供必要的语言支持。
评估嵌入模型
若要评估嵌入模型,请可视化嵌入内容并评估问题与区块向量之间的距离。
可视化嵌入内容
可以使用库(如 t-SNE)在 X-Y 图上绘制区块和问题的向量。 然后,就可以确定各区块之间以及与问题之间的距离。 下图显示了绘制的区块向量。 彼此附近的两个箭头表示两个区块向量。 另一个箭头表示问题向量。 可以使用此可视化效果来了解问题与区块的距离。
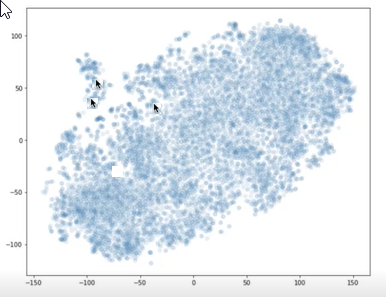
两个箭头指向彼此附近的绘图点,另一个箭头显示一个远离其他两个的绘图点。
计算嵌入距离
可以使用编程方法来评估嵌入模型处理问题和区块的方式。 计算问题向量与区块向量之间的距离。 可以使用尤克里德距离或曼哈顿距离。
嵌入式经济学
选择嵌入模型时,必须在性能和成本之间进行权衡。 大型嵌入模型通常对基准数据集具有更好的性能。 但是,性能的提高增加了成本。 大型向量在向量数据库中需要更多的空间。 它们还需要更多计算资源和时间来比较嵌入内容。 小型嵌入模型通常在同一基准上具有较低的性能。 它们在矢量数据库中占用更少的空间,并且在比较嵌入时需要更少的计算量和时间。
设计系统时,应考虑在存储、计算和性能要求方面嵌入的成本。 必须通过试验来验证模型的性能。 公开提供的基准主要是学术数据集,可能不会直接应用于业务数据和用例。 根据要求,你可以注重性能而非成本,或者接受够用的性能以降低成本。