你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何创建自定义文本转语音虚拟形象
开始使用自定义文本转语音虚拟形象是一个简单的过程。 只需参与者的几段视频即可。 如果你要为同一参与者训练定制声音,可以单独执行此操作。
注意
自定义虚拟形象的访问权限根据资格和使用标准受到限制。 在引入表单上请求访问。
先决条件
需要在一个支持自定义虚拟形象训练的区域中拥有语音资源。 自定义虚拟形象仅支持标准 (S0) 语音资源。
你需要录制一段发音人阅读同意声明的视频,承认使用其形象和声音。 请在设置虚拟形象发音人时上传此视频。 有关详细信息,请参阅“添加虚拟形象发音人同意”。
你需要将虚拟形象发音人的视频录制用作训练数据。 请在准备训练数据时上传这些视频。 有关详细信息,请参阅“添加训练数据”。
步骤 1:创建自定义虚拟形象项目
若要创建自定义虚拟形象项目,请执行以下步骤:
登录到 Speech Studio 并选择订阅和语音资源。
选择自定义虚拟形象(预览版)。
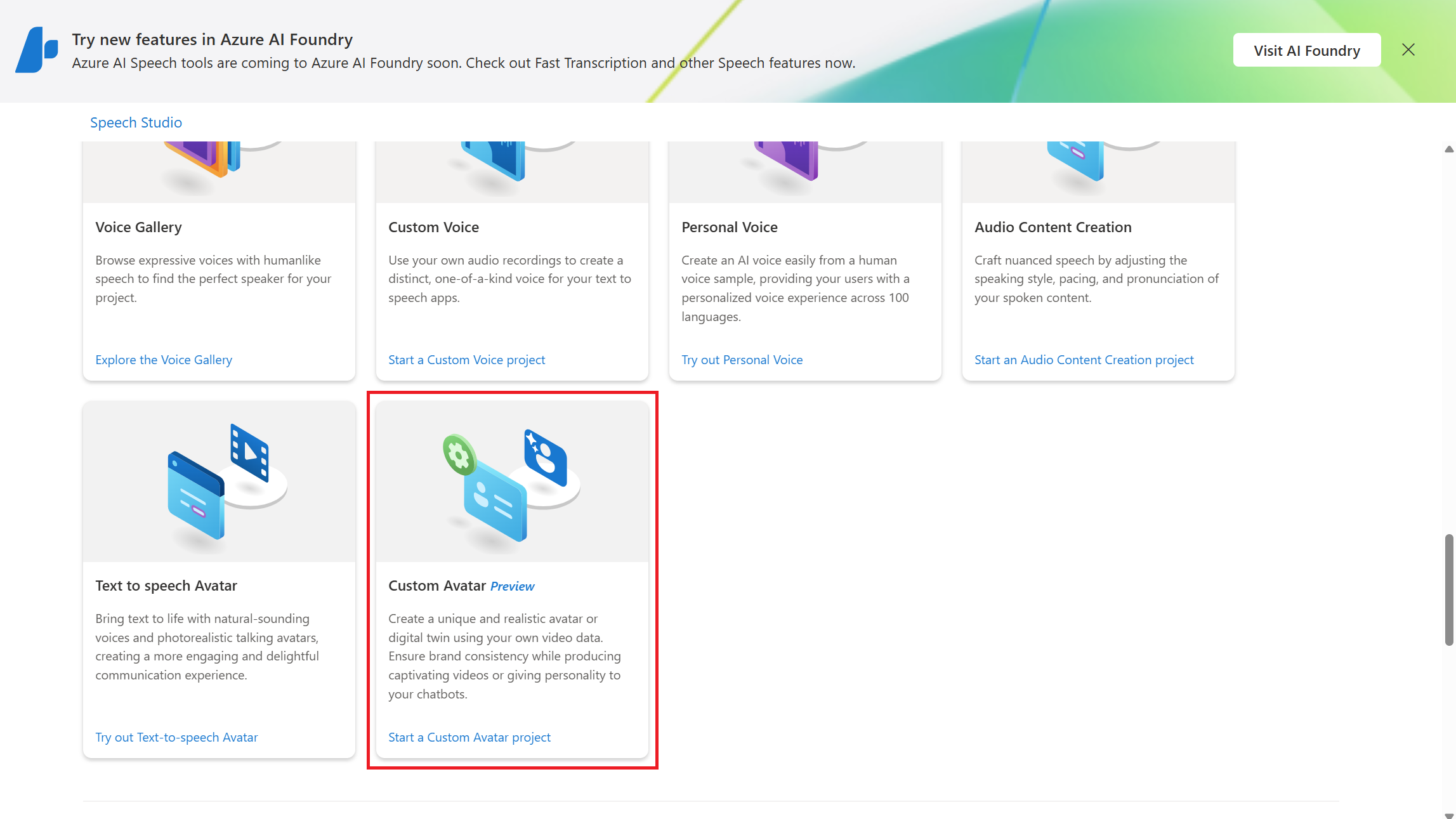
选择“+创建项目”。
遵照向导中的说明创建项目。
提示
不要在一个项目中混合不同虚拟形象的数据。 始终为新虚拟形象创建新项目。
按名称选择新项目。 然后,你会在左侧面板中看到以下菜单项:“设置虚拟形象发音人”、“准备训练数据”、“训练模型”和“部署模型”。

步骤 2:添加虚拟形象发音人同意
虚拟形象配音员是个人或目标参与者,其讲话视频将被录制并用于创建神经网络虚拟形象模型。 你必须根据所有相关法律和法规获得虚拟形象配音员的全面同意,才能使用他们的视频创建自定义文本转语音虚拟形象。
你必须提供一个视频文件,其中包含虚拟形象配音员的录制声明,承认你使用了他们的图像和声音。 Microsoft 将验证录制内容是否与 Microsoft 提供的预定义脚本匹配。 Microsoft 会将录制的视频声明文件中的虚拟形象配音员的脸部与训练数据集中的随机视频进行比较,以确保视频录制中的虚拟形象配音员和声明视频文件中的虚拟形象配音员来自同一个人。
可以通过 Azure-Samples/cognitive-services-speech-sdk GitHub 存储库查找多种语言的口头同意声明。 口头陈述的语言必须与录制内容相同。 另请参阅针对发音人的披露内容。
有关录制同意视频的详细信息,请参阅如何录制视频示例。
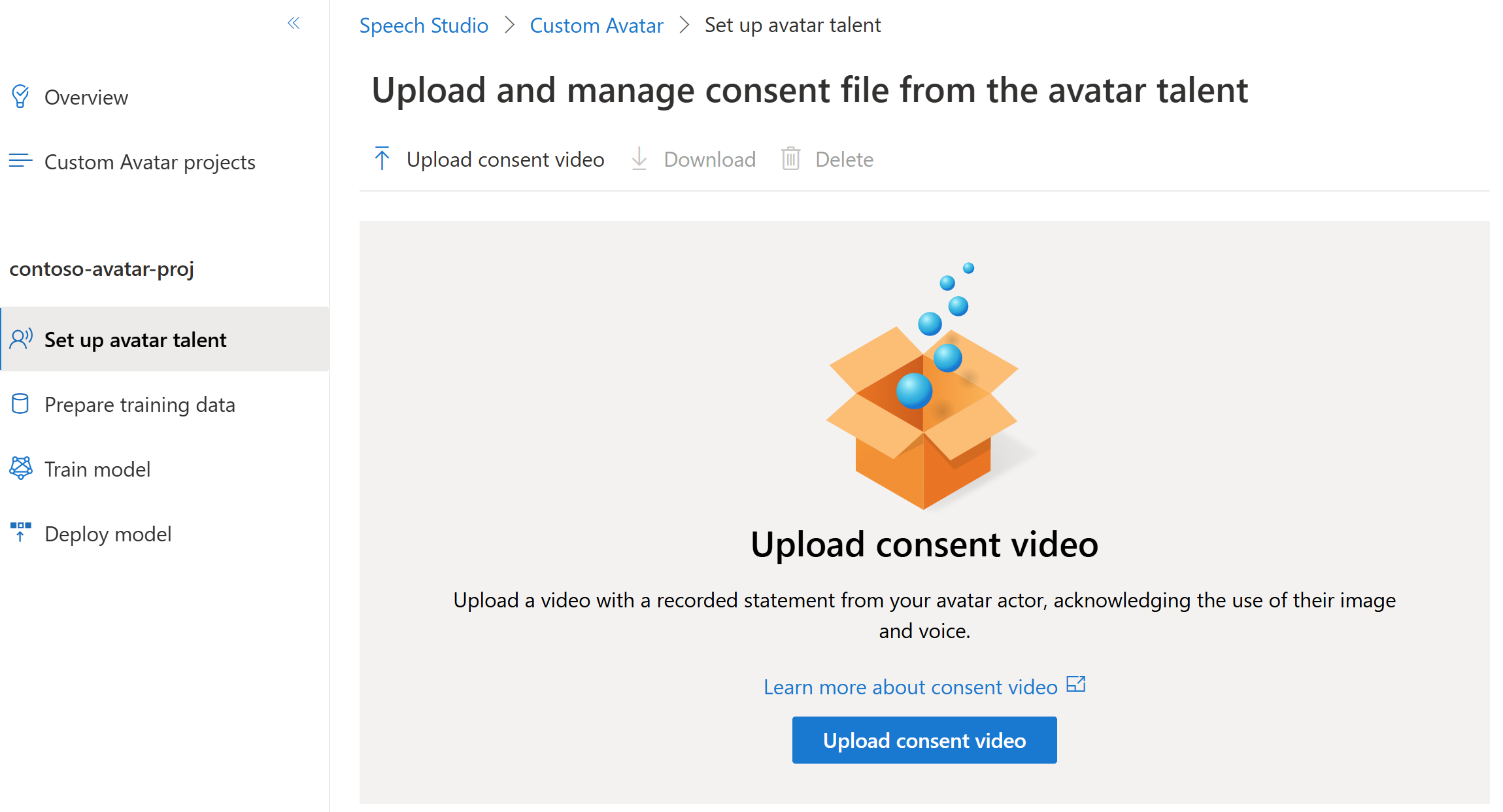
若要添加虚拟形象发音人配置文件并在项目中上传其同意声明,请执行以下步骤:
登录 Speech Studio。
选择“自定义虚拟形象”>你的项目名称>“设置虚拟形象发音人”>“上传同意视频”。
在“上传同意视频”页面上,按照说明上传事先录制的虚拟形象发音人同意视频。
- 选择虚拟形象发音人录制的口头同意声明所用的语言。
- 用录制声明中的语言输入虚拟形象发音人的姓名和你的公司名称。
- 虚拟形象发音人姓名必须是录制同意声明的人员的姓名。
- 公司名称必须与录制的声明中说出的公司名称匹配。
- 可以选择从本地文件或从 Azure Blob 的共享存储上传数据。
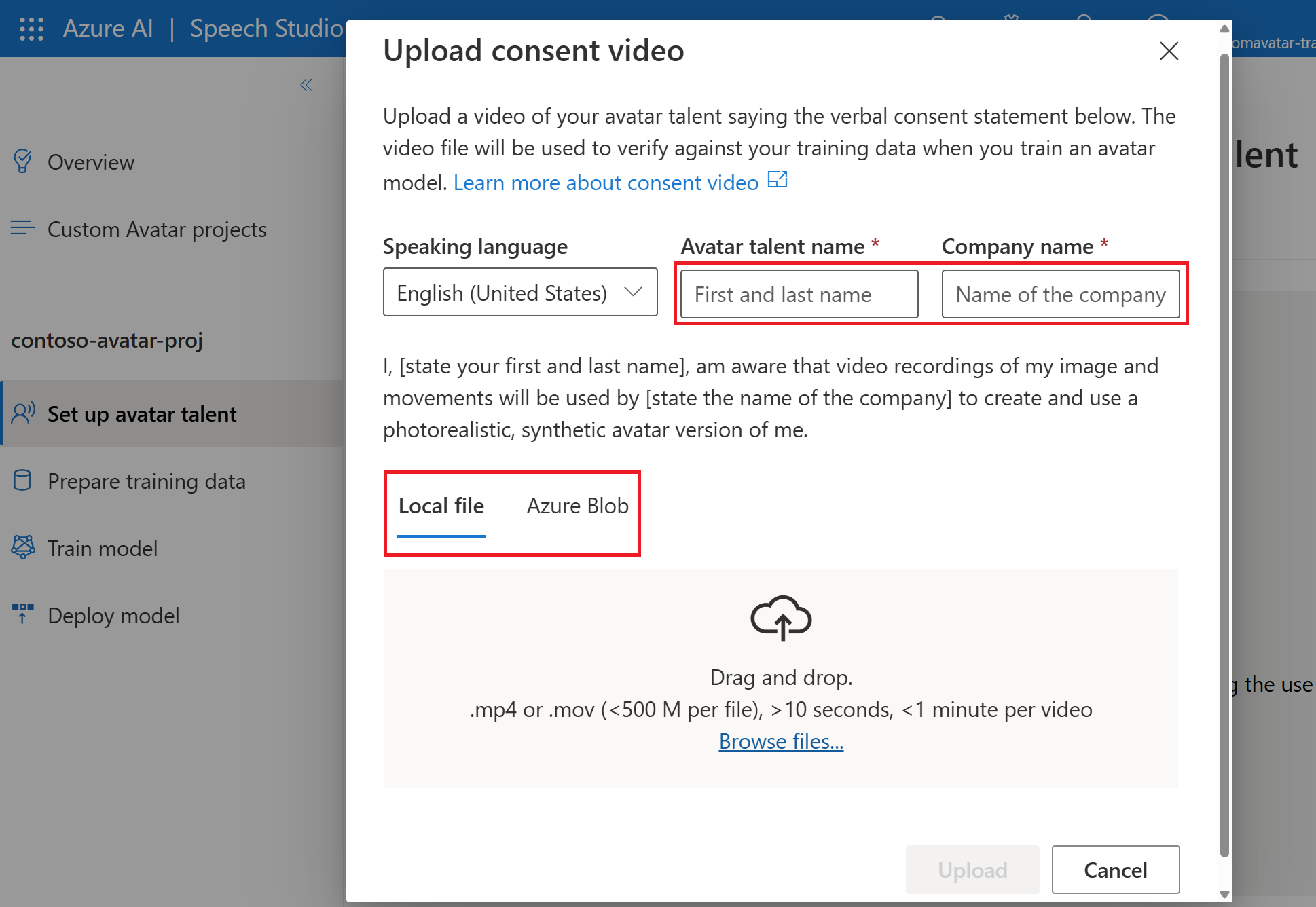
选择“上传”。

在虚拟形象发音人的同意声明上传成功后,可以继续训练自定义虚拟形象模型。
步骤 3:添加训练数据
语音服务会根据录制中人员的外貌进行微调,使用训练数据创建独特的虚拟形象。 训练虚拟形象模型后,可以开始合成虚拟形象视频,或将其用于应用程序中的实时聊天。
上传的所有数据都必须符合所选数据类型的要求。 若要确保语音服务准确处理数据,请务必在上传之前正确设置数据格式。 若要确认已正确设置数据格式,请参阅数据要求。
上传数据
准备好上传数据后,请转到“准备训练数据”选项卡添加数据。
若要上传训练数据,请执行以下步骤:
登录 Speech Studio。
选择“自定义虚拟形象”>“你的项目名称”>“准备训练数据”>“上传数据”。
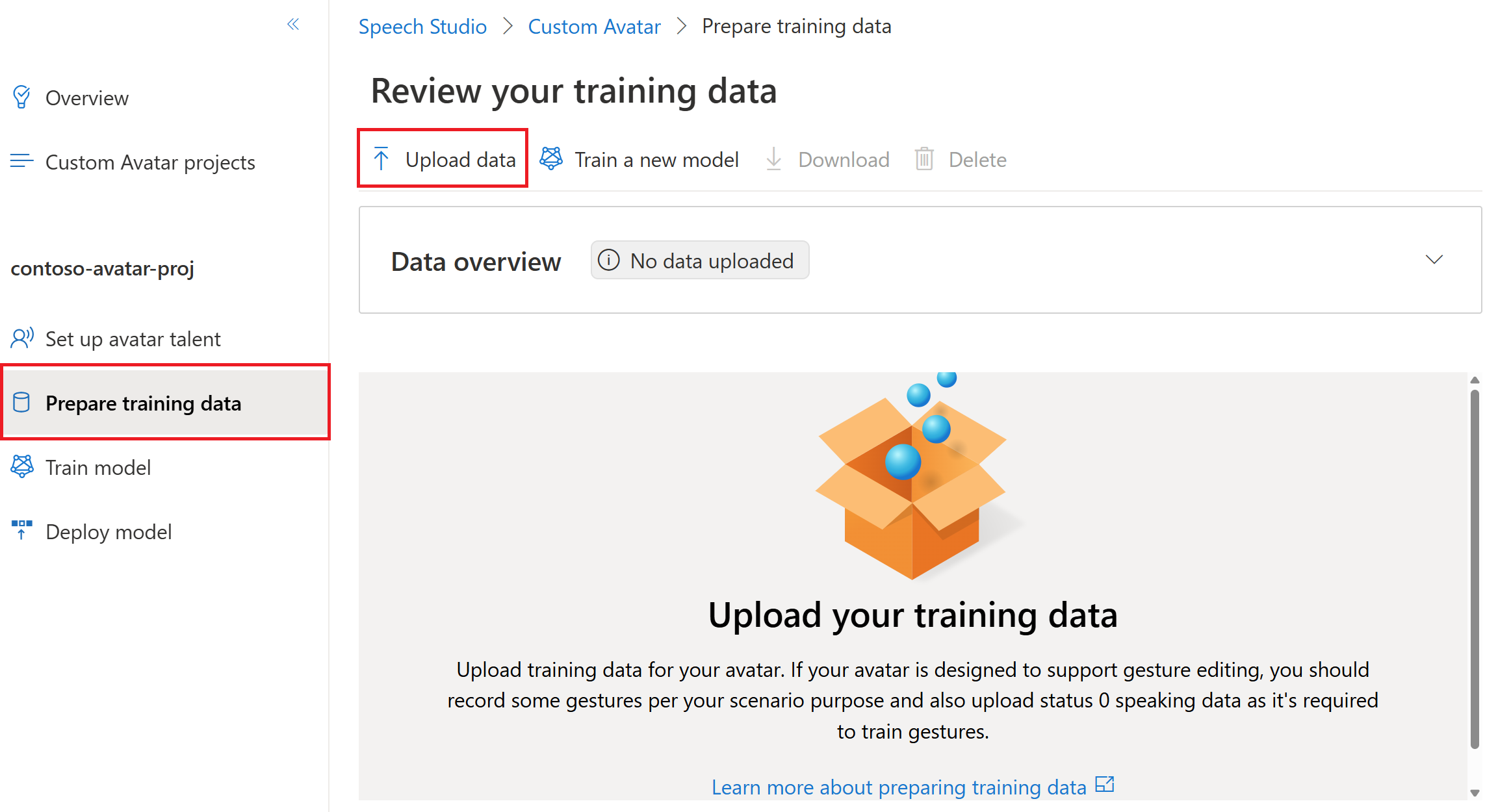
在“上传数据”向导中,选择数据类型,然后选择“下一步”。 有关数据类型的详细信息(包括“自然地说话”、“沉默”、“手势”和“状态 0 说话”),请参阅要录制的视频。
从计算机中选择本地文件或输入存储数据的 Azure Blob 存储 URL。
选择下一步。
查看上传详细信息,然后选择“提交”。

选择“提交”时,会自动验证数据文件。 数据验证包括针对视频文件执行一系列检查以验证文件格式、大小和总量。 如果有任何错误,请修复它们并再次提交。
上传数据后,可以检查数据概述,该概述指示是否提供了足够的数据来开始训练。 此屏幕截图中的示例添加了足以训练虚拟形象的数据,其中没有其他手势。

步骤 4:训练虚拟形象模型
重要
项目中的所有训练数据都包含在训练中。 模型质量高度依赖于你提供的数据,并且你为视频质量负责。 请确保根据如何录制视频示例指南来录制训练视频。
若要在 Speech Studio 中创建自定义虚拟形象,请根据以下方法之一执行相应的步骤:
登录 Speech Studio。
选择“自定义虚拟形象”>项目名称>“训练模型”>“训练模型”。
输入名称以帮助识别模型。 请谨慎选择名称。 模型名称将通过 SDK 和 SSML 输入用作合成请求中的虚拟形象名称。 只能包含字母、数字、连字符和下划线。 请为每个模型使用唯一的名称。
重要
虚拟形象模型名称必须在同一语音或 AI 服务资源中是唯一的。
选择训练开始训练模型。
训练持续时间因使用的数据量而异。 训练自定义虚拟形象通常需要 20-40 个计算小时。 查看定价说明,了解训练的收费方式。
将自定义虚拟形象模型复制到另一个项目(可选)
自定义虚拟形象训练目前仅在部分区域可用。 在受支持区域中训练虚拟形象模型后,可以根据需要将其复制到另一个区域中的语音资源。 有关详细信息,请参阅区域表中的脚注。
若要将自定义虚拟形象模型复制到另一个项目,请执行以下操作:
- 在“训练模型”选项卡上,选择要复制的虚拟形象模型,然后选择“复制到项目”。
- 选择要将模型复制到的订阅、区域、语音资源和项目。 必须在目标区域具有语音资源和项目,否则需要先创建它们。
- 选择“提交”以复制模型。
复制模型后,会在 Speech Studio 中看到通知。
导航到在其中复制了模型的项目以部署模型副本。
步骤 5:部署和使用虚拟形象模型
成功创建并训练虚拟形象模型后,即可将其部署到终结点。
要部署虚拟形象,请执行以下操作:
- 登录 Speech Studio。
- 选择“自定义虚拟形象”>你的项目名称>“部署模型”。
- 选择“部署模型”,然后选择要部署的模型。
- 选择“部署”以启动部署。
重要
部署模型后,无论与该终结点产生了什么交互,你都会为终结点的持续运行时间付费。 查看定价说明,了解模型部署的计费方式。 当不使用模型时,可以删除部署以减少支出并节省资源。
部署自定义虚拟形象后,可在 Speech Studio 中或通过 API 使用:
- 虚拟形象显示在 Speech Studio 上的文本转语音虚拟形象列表中。
- 虚拟形象显示在 Speech Studio 上的实时聊天虚拟形象列表中。
- 可以通过指定虚拟形象模型名称从 SDK 和 SSML 输入调用虚拟形象。 有关详细信息,请参阅虚拟形象属性。
删除部署
若要删除部署,请执行以下步骤:
- 登录 Speech Studio。
- 导航到“自定义虚拟形象”>项目名称>“训练模型”。
- 在“部署模型”页上选择该部署。 如果状态为“成功”,则该模型已主动托管。
- 可以选择“删除部署”按钮,并确认删除托管。
提示
删除部署后,就不再为其托管付费。 删除部署不会导致你的模型被删除。 如果想要再次使用该模型,请创建新的部署。
使用自定义语音(可选)
如果还正在为参与者创建神经网络定制声音 (CNV),则虚拟形象可能非常逼真。 有关详细信息,请参阅什么是自定义文本转语音虚拟形象。
自定义语音和自定义文本转语音虚拟形象是单独的功能。 可以独立使用它们,也可以一起使用。
如果已经创建了一个定制声音,并希望将其与自定义虚拟形象一起使用,请注意以下几点:
- 请确保在与自定义虚拟形象终结点相同的语音资源中创建定制声音终结点。 根据需要,请参阅训练专业语音模型,将自定义语音模型复制到自定义虚拟形象终结点所在的语音资源。
- 可以在虚拟形象内容生成页面和实时聊天语音设置的语音列表中看到定制声音选项。
- 如果使用虚拟形象 API 的批处理合成,请添加
"customVoices"属性,将自定义语音模型的部署 ID 与请求中的语音名称相关联。 有关详细信息,请参阅文本转语音属性。 - 如果使用虚拟形象 API 的实时合成,请参阅 GitHub 上的示例代码设置定制声音。