你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Docker 的自定义语音转文本容器
自定义语音转文本容器会听录实时语音或批量音频录制内容,并生成中间结果。 可以使用在自定义语音门户中创建的自定义模型。 本文介绍如何下载、安装以及运行自定义语音转文本容器。
有关先决条件、验证容器是否正在运行、在同一主机上运行多个容器以及运行断开连接的容器的详细信息,请参阅使用 Docker 安装和运行语音容器。
容器映像
可在 Microsoft 容器注册表 (MCR) 联合中找到所有受支持版本和区域设置的自定义语音转文本容器映像。 该映像驻留在 azure-cognitive-services/speechservices/ 存储库中,名为 custom-speech-to-text。

完全限定的容器映像名称为 mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text。 追加特定版本或追加 :latest 以获取最新版本。
| 版本 | 路径 |
|---|---|
| 最晚 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.10.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.10.0-amd64 |
除 latest 以外的所有标记均采用以下格式并区分大小写:
<major>.<minor>.<patch>-<platform>-<prerelease>
注意
自定义语音转文本容器的 locale 和 voice 由容器引入的自定义模型确定。
为方便起见,这些标记也以 JSON 格式提供。 正文包括容器路径和标记列表。 标记不按版本排序,但 "latest" 始终包含在列表末尾,如以下代码片段所示:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
<--redacted for brevity-->
"4.4.0-amd64",
"4.5.0-amd64",
"4.6.0-amd64",
"4.7.0-amd64",
"4.8.0-amd64",
"4.9.0-amd64",
"4.10.0-amd64",
"latest"
]
}
使用 docker pull 获取容器映像
需要满足先决条件,包括所需的硬件。 另请参阅为每个语音容器建议的资源分配。
使用 docker pull 命令从 Microsoft Container Registry 下载容器映像:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
注意
自定义语音识别容器的 locale 和 voice 由容器引入的自定义模型确定。
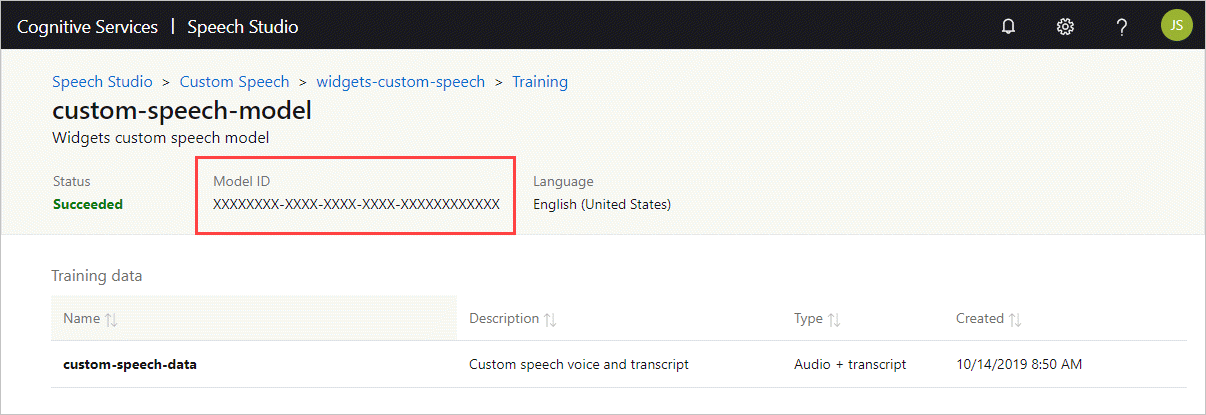
获取模型 ID
在运行容器之前,需要知道自定义模型的模型 ID 或基础模型 ID。 运行容器时,指定要下载和使用的某个模型 ID。
必须使用 Speech Studio 训练自定义模型。 若要了解如何获取模型 ID,请参阅自定义语音模型生命周期。
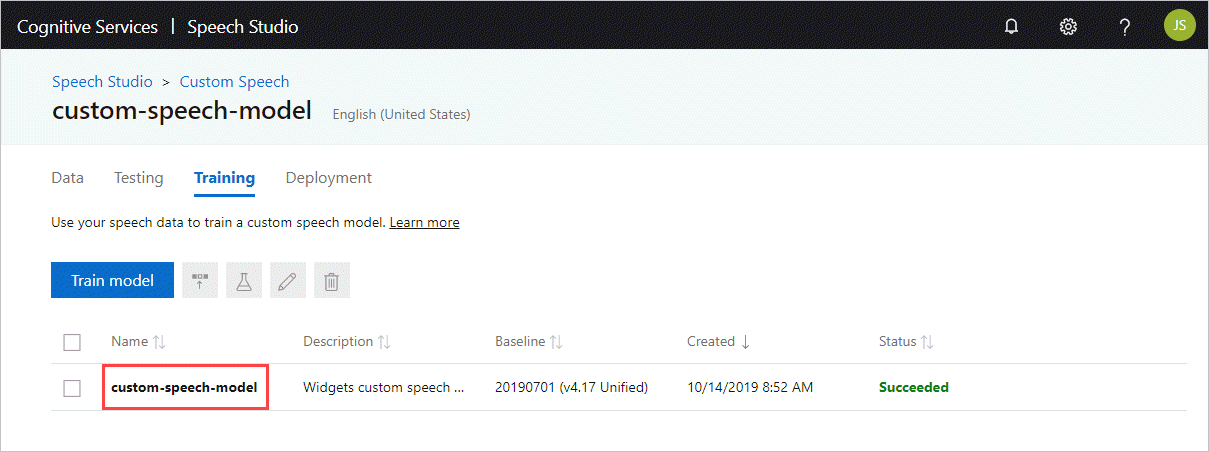
获取模型 ID,用作 docker run 命令的 ModelId 参数的自变量。
显示模型下载
运行容器前,可选择获取可用的显示模型信息,并选择将这些模型下载到你的语音转文本容器,以获得高度改进的最终显示输出。 自定义语音转文本容器版本 3.1.0 及更高版本提供显示模型下载。
注意
尽管使用 docker run 命令,但不会为服务启动容器。
你可以查询或下载以下任意或所有显示模型类型:重新评分 (Rescore)、标点 (Punct)、再分割 (Resegment) 和 wfstitn (Wfstitn)。 否则,你可以使用 FullDisplay 选项(同时使用或不使用其他类型)来查询或下载所有类型的显示模型。
设置 BaseModelLocale 可查询目标区域设置中最新可用的显示模型。 如果你包括了多个显示模型类型,则此命令会返回每种类型的最新可用显示模型。 例如:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
设置 DisplayLocale 可下载目标区域设置中最新可用的显示模型。 设置 DisplayLocale 时,还必须指定 FullDisplay 或指定以空格分隔的显示模型子集。 此命令会为每个指定的类型下载最新的可用显示模型。 例如:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
设置一个模型 ID 参数来下载特定的显示模型:重新评分 (RescoreId)、标点 (PunctId)、再分割 (ResegmentId) 或 wfstitn (WfstitnId)。 这类似于通过 ModelId 参数下载基本模型的方式。 例如,若要下载某个重新评分显示模型,可以将以下命令与 RescoreId 参数一起使用:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
注意
如果你设置了多个查询或下载参数,则此命令将按以下顺序排定优先级:BaseModelLocale、模型 ID,然后是 DisplayLocale(仅适用于显示模型)。
通过 docker run 运行容器
使用 docker run 命令为服务运行容器。
下表列出了各个 docker run 参数及其对应的说明:
| 参数 | 说明 |
|---|---|
{VOLUME_MOUNT} |
主计算机的卷装载点,Docker 使用它来持久保存自定义模型。 例如 c:\CustomSpeech,其中的 c:\ 驱动器位于主机上。 |
{MODEL_ID} |
自定义语音或基础模型 ID。 有关详细信息,请参阅获取模型 ID。 |
{ENDPOINT_URI} |
必须使用该终结点进行计量和计费。 有关详细信息,请参阅计费参数。 |
{API_KEY} |
API 密钥是必需的。 有关详细信息,请参阅计费参数。 |
运行自定义语音转文本容器时,请根据自定义语音转文本容器的要求和建议配置端口、内存和 CPU。
下面是一个示例 docker run 命令以及占位符值。 必须指定 VOLUME_MOUNT、MODEL_ID、ENDPOINT_URI、API_KEY 的值:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
此命令:
- 运行容器映像中的某个自定义语音转文本容器。
- 分配 4 个 CPU 核心和 8 GB 内存。
- 从卷输入装载点(例如 C:\CustomSpeech)加载自定义语音转文本模型。
- 公开 TCP 端口 5000,并为容器分配伪 TTY。
- 根据给定的
ModelId来下载模型(如果在卷装载中找不到)。 - 如果先前已下载自定义模型,则会忽略
ModelId。 - 退出后自动删除容器。 容器映像在主计算机上仍然可用。
有关 docker run 和语音容器的详细信息,请参阅使用 Docker 安装和运行语音容器。
使用容器
语音容器提供通过语音 SDK 和语音 CLI 访问的基于 Websocket 的查询终结点 API。 默认情况下,语音 SDK 和语音 CLI 使用公共语音服务。 若要使用该容器,需要更改初始化方法。
重要
将语音服务与容器一起使用时,请务必使用主机身份验证。 如果配置密钥和区域,请求将发送到公共语音服务。 语音服务的结果可能不符合预期。 来自断开连接的容器的请求将失败。
不使用此 Azure 云初始化配置:
var config = SpeechConfig.FromSubscription(...);
将此配置用于容器主机:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
不使用此 Azure 云初始化配置:
auto speechConfig = SpeechConfig::FromSubscription(...);
将此配置用于容器主机:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
不使用此 Azure 云初始化配置:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
将此配置用于容器主机:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
不使用此 Azure 云初始化配置:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
将此配置用于容器主机:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
不使用此 Azure 云初始化配置:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
将此配置用于容器主机:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
不使用此 Azure 云初始化配置:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
将此配置用于容器主机:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
不使用此 Azure 云初始化配置:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
将此配置用于容器主机:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
不使用此 Azure 云初始化配置:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
将此配置用于容器终结点:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
在容器中使用语音 CLI 时,请包含 --host ws://localhost:5000/ 选项。 还必须指定 --key none 以确保 CLI 不会尝试使用语音密钥进行身份验证。 有关如何配置语音 CLI 的信息,请参阅 Azure AI 语音 CLI 入门。
尝试语音转文本快速入门,它使用主机身份验证而不是密钥和区域。
后续步骤
- 请参阅语音容器概述
- 查看配置容器了解配置设置。
- 使用更多 Azure AI 容器