你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是异步对话听录多声道分割聚类? (预览)
注意
此功能目前处于公开预览状态。 此预览版没有附带服务级别协议,建议不要用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
对话听录多声道分割聚类是一种语音转文本解决方案解决方案,可提供任何会议的实时或异步听录。 此功能结合了语音识别、说话人识别以及句子归因,以确定谁在会议中在什么时候说了什么。
重要
对话听录多声道分割聚类(预览版)将于 2025 年 3 月 28 日停用。 有关迁移到其他语音转文本功能的详细信息,请参阅从对话听录多声道分割聚类迁出。
从对话听录多声道分割聚类迁移
对话听录多声道分割聚类(预览版)将于 2025 年 3 月 28 日停用。
若要继续使用语音转文本进行分割聚类,请改用以下功能:
这些语音转文本功能仅支持单声道音频的分割聚类。 不支持用于对话听录多通道分割聚类的多声道音频。
关键功能
你可能会发现对话听录的以下功能很有用:
- 时间戳:每个说话人言语都具有一个时间戳,以便可以轻松地找到说出短语的时间。
- 可读口述文本:口述文本会自动添加格式设置和标点符号,以确保文本与所说的内容紧密匹配。
- 用户配置文件:通过收集用户语音样本并发送到签名生成服务来生成用户配置文件。
- 说话人识别:使用用户配置文件识别说话人,并向每个说话人分配说话人标识符。
- 多说话人分割聚类:通过使用每个说话人标识符合成音频流来确定谁说了些什么。
- 实时听录:在会议进行期间,提供谁在说什么以及说话时间的实时口述文本。
- 异步听录:使用多声道音频流提供准确度更高的口述文本。
备注
虽然对话听录不会对房间中的说话人数量施加限制,但是它针对每个会话 2-10 个说话人进行了优化。
用例
若要使会议对每个人(例如失聪和有听力障碍的参与者)都具有包容性,进行实时听录非常重要。 实时模式下的对话听录采用会议音频,并确定谁在说些什么,这使所有会议参与者都可按照口述文本参与会议而不会出现延迟。
会议参与者可以将精力集中在会议上,让对话听录来做笔记。 参与者可以使用口述文本积极参与会议并迅速跟进后续步骤,而无需在会议期间做笔记并可能遗漏某些内容。
工作原理
下图高度概括了该功能的工作原理。
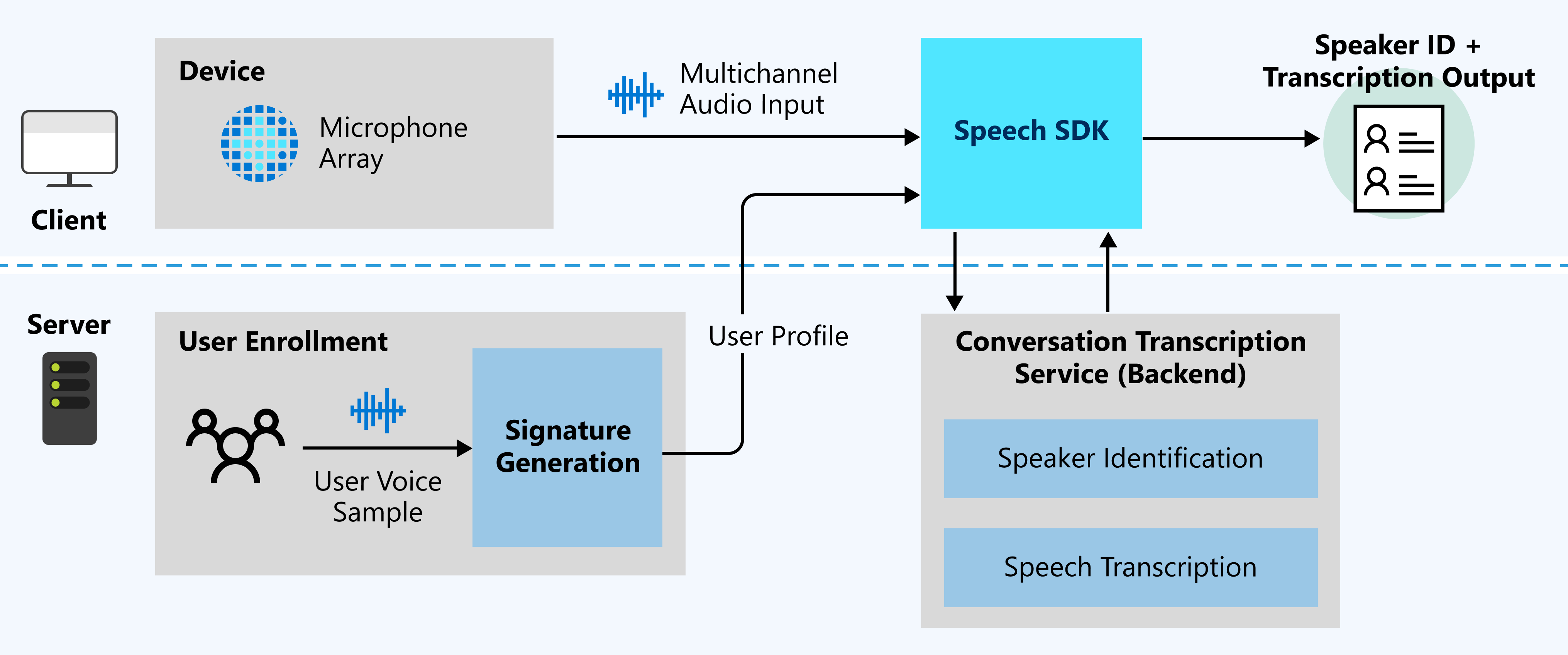
预期输入
对话听录使用两种类型的输入:
- 多声道音频流:有关规范和设计详细信息,请参阅麦克风阵列建议。
- 用户语音样本:对话听录需要在对话之前提供用户配置文件,以进行说话人识别。 从每个用户收集音频录制内容,然后将录制内容发送到签名生成服务,以验证音频并生成用户配置文件。
为实现说话人识别,需要提供用户语音样本进行语音签名。 没有语音样本的说话人会识别为“未识别”。 启用 DifferentiateGuestSpeakers 属性后,仍可以对无法识别的说话人进行区分(请参阅下面的示例)。 听录输出随后将说话人显示为,例如 Guest_0和 Guest_1,而不是将它们识别为预先注册的特定说话人姓名。
config.SetProperty("DifferentiateGuestSpeakers", "true");
实时或异步
以下部分提供有关可以选择的听录模式的更多详细信息。
实时
音频数据进行实时处理以返回说话人标识符和口述文本。 如果听录解决方案要求是向会议参与者提供正在进行的会议的实时口述文本视图,请选择此模式。 例如,生成应用程序以使失聪和有听力障碍的参与者更容易访问会议是实时听录的理想用例。
异步
音频数据进行批处理以返回说话人标识符和口述文本。 如果听录解决方案要求是提供更高准确度,而无需实时口述文本视图,请选择此模式。 例如,如果你要生成应用程序以使会议参与者可以轻松地弥补错过的会议,则使用异步听录模式获取高准确度的听录结果。
实时加异步
音频数据进行实时处理以返回说话人标识符和口述文本,此外通过异步处理请求高准确度口述文本。 如果应用程序需要实时听录,并且也需要更高准确度的口述文本以便在进行会议之后使用,请选择此模式。
语言和区域支持
目前,对话听录在以下区域中支持所有语音转文本语言:centralus、eastasia、eastus、westeurope。