你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:通过对话语言理解识别意向
参考文档 | 包 (NuGet) | GitHub 上的其他示例
在此快速入门中,你将使用语音和语言服务来识别从麦克风获取的音频数据中的意向。 具体而言,你将使用语音服务来识别语音,并使用对话语言理解 (CLU) 模型来识别意向。
重要
对话语言理解 (CLU) 适用于具有语音 SDK 1.25 或更高版本的 C# 和 C++。
先决条件
设置环境
语音 SDK 以 NuGet 包的形式提供并实现了 .NET Standard 2.0。 本指南的后面部分会安装语音 SDK,但先请查看 SDK 安装指南以了解更多要求。
设置环境变量。
此示例需要名为 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 的环境变量。
必须对应用程序进行身份验证才能访问 Azure AI 服务资源。 本文介绍如何使用环境变量来存储凭据。 然后,你可以从代码访问环境变量来验证应用程序。 对于生产环境,请使用更安全的方式来存储和访问凭据。
重要
我们建议使用 Azure 资源的托管标识进行 Microsoft Entra ID 身份验证,以避免将凭据随云中运行的应用程序一起存储。
如果使用 API 密钥,请将其安全地存储在其他某个位置,例如 Azure 密钥保管库中。 请不要直接在代码中包含 API 密钥,并且切勿公开发布该密钥。
有关 Azure AI 服务安全性的详细信息,请参阅对 Azure AI 服务的请求进行身份验证。
若要设置环境变量,请打开控制台窗口,按照操作系统和开发环境的说明进行操作。
- 若要设置
LANGUAGE_KEY环境变量,请将your-language-key替换为资源的其中一个密钥。 - 若要设置
LANGUAGE_ENDPOINT环境变量,请将your-language-endpoint替换为你的资源的其中一个区域。 - 若要设置
SPEECH_KEY环境变量,请将your-speech-key替换为资源的其中一个密钥。 - 若要设置
SPEECH_REGION环境变量,请将your-speech-region替换为你的资源的其中一个区域。
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
注意
如果只需要访问当前正在运行的控制台中的环境变量,则可以使用 set(而不是 setx)设置环境变量。
添加环境变量后,可能需要重启任何正在运行的、需要读取环境变量的程序(包括控制台窗口)。 例如,如果使用 Visual Studio 作为编辑器,请在运行示例之前重启 Visual Studio。
创建对话语言理解项目
创建语言资源后,请在 Language Studio 中创建对话语言理解项目。 项目是一个基于数据构建自定义 ML 模型的工作区。 只有你和对所使用的语言资源具有访问权限的其他人才能访问你的项目。
转到 Language Studio,然后使用 Azure 帐户登录。
创建对话语言理解项目
对于本快速入门,可以下载这个示例家庭自动化项目并将其导入。 此项目可以通过用户输入预测预期命令,例如开灯和关灯。
在 Language Studio 的“理解问题和对话语言”部分下,选择“对话语言理解”。
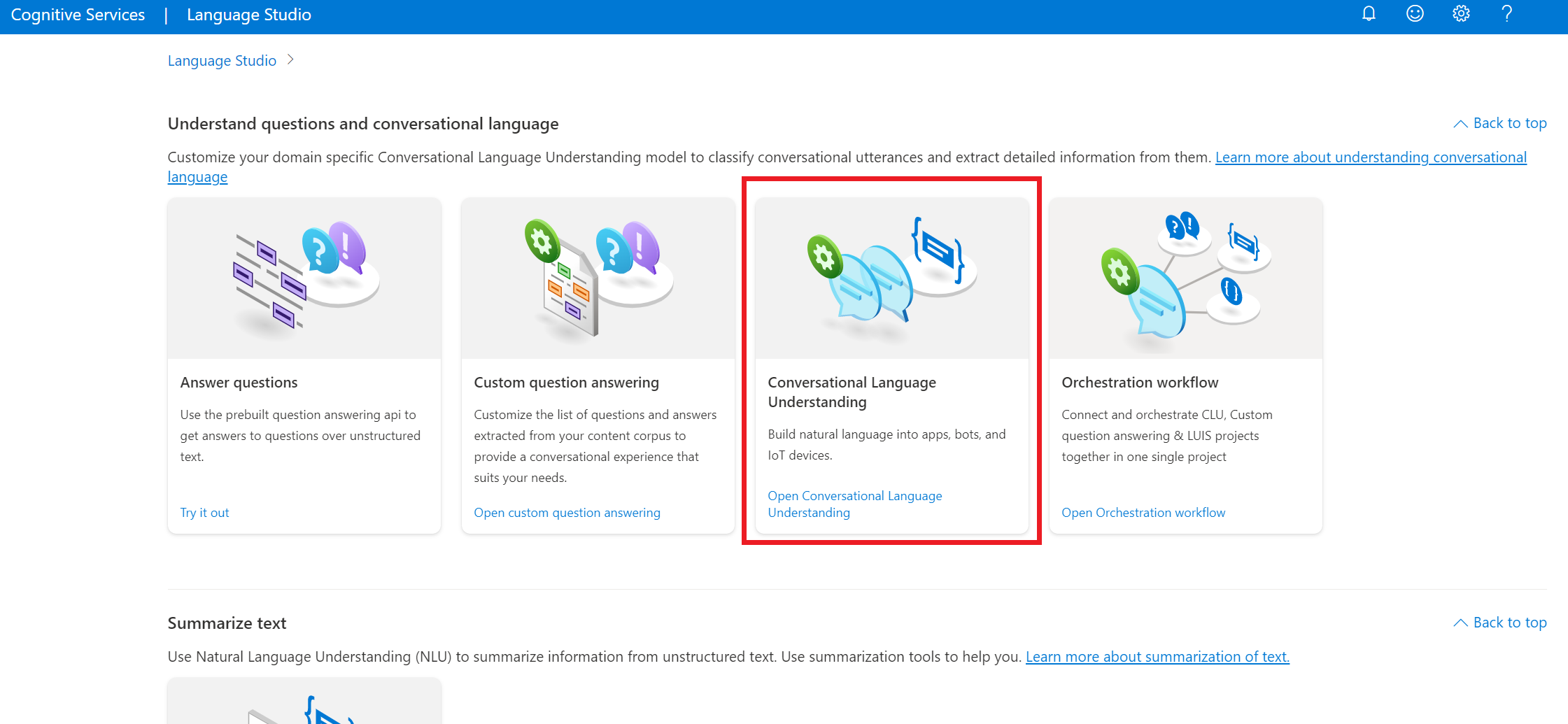
随后你会转到“对话语言理解项目”页。 在“新建项目”按钮旁边,选择“导入”。
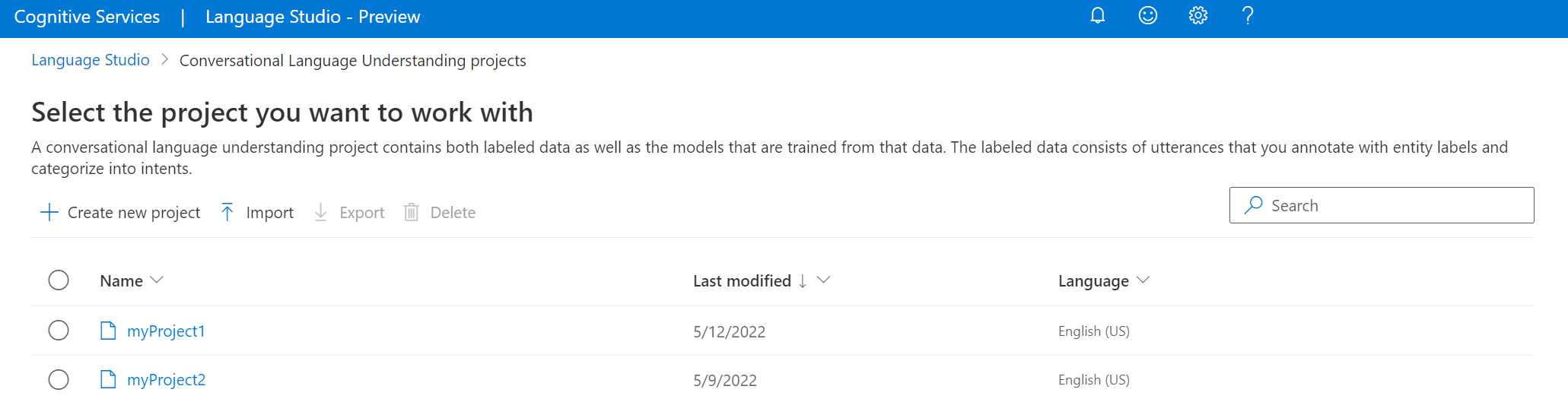
在显示的窗口中,上传要导入的 JSON 文件。 请确保该文件遵循受支持的 JSON 格式。


上传完成后,你将进入“架构定义”页。 对于本快速入门,架构已经生成,并且语句已标有意向和实体。
训练模型
通常,在创建项目后,你应该生成架构并标记语句。 对于本快速入门,我们已导入一个生成了架构和标记了语句的现成项目。
若要训练模型,需要启动训练作业。 成功训练作业的输出是已训练的模型。
若要在 Language Studio 中开始训练模型,请执行以下操作:
在左侧菜单中,选择“训练模型”。
从顶部菜单中选择“启动训练作业”。
选择“训练新模型”,然后在文本框中输入新模型名称。 但要将现有模型替换为已针对新数据训练的模型,请选择“覆盖现有模型”,然后选择现有模型。 覆盖已训练的模型是不可逆的,但这在部署新模型之前不会影响已部署的模型。
选择训练模式。 可以选择“标准训练”以加快训练速度,但此模式仅适用于英语。 或者,可以选择其他语言和多语言项目支持的“高级训练”,但此模式需要更长的训练时间。 详细了解训练模式。
选择一种数据拆分方法。 可以选择“从训练数据中自动拆分测试集”,系统将根据指定的百分比在训练集和测试集之间拆分语句。 或者,可以选择“使用手动拆分训练和测试数据”,仅当在标记语句期间已将语句添加到测试集时才会启用此选项。
选择“训练”按钮。

从列表中选择训练作业 ID。 出现一个面板,在该面板中可以检查此作业的训练进度、作业状态和其他详细信息。
注意
- 只有成功完成的训练作业才会生成模型。
- 训练时间从几分钟到几个小时不等,具体取决于语句数量。
- 一次只能运行一个训练作业。 在运行的作业完成之前,无法在同一项目中启动其他训练作业。
- 用于训练模型的机器学习会定期更新。 如果要在以前的配置版本上进行训练,请在“启动训练作业”页中单击“单击此处进行更改”,然后选择以前的版本。

部署模型
一般情况下,在训练模型后,你会查看其评估详细信息。 在本快速入门中,你只需部署模型,使其在 Language Studio 中可供试用,你也可以调用预测 API。
若要要从 Language Studio 中部署模型,请执行以下操作:
在左侧菜单中,选择“部署模型”。
选择“添加部署”以启动“添加部署”向导。
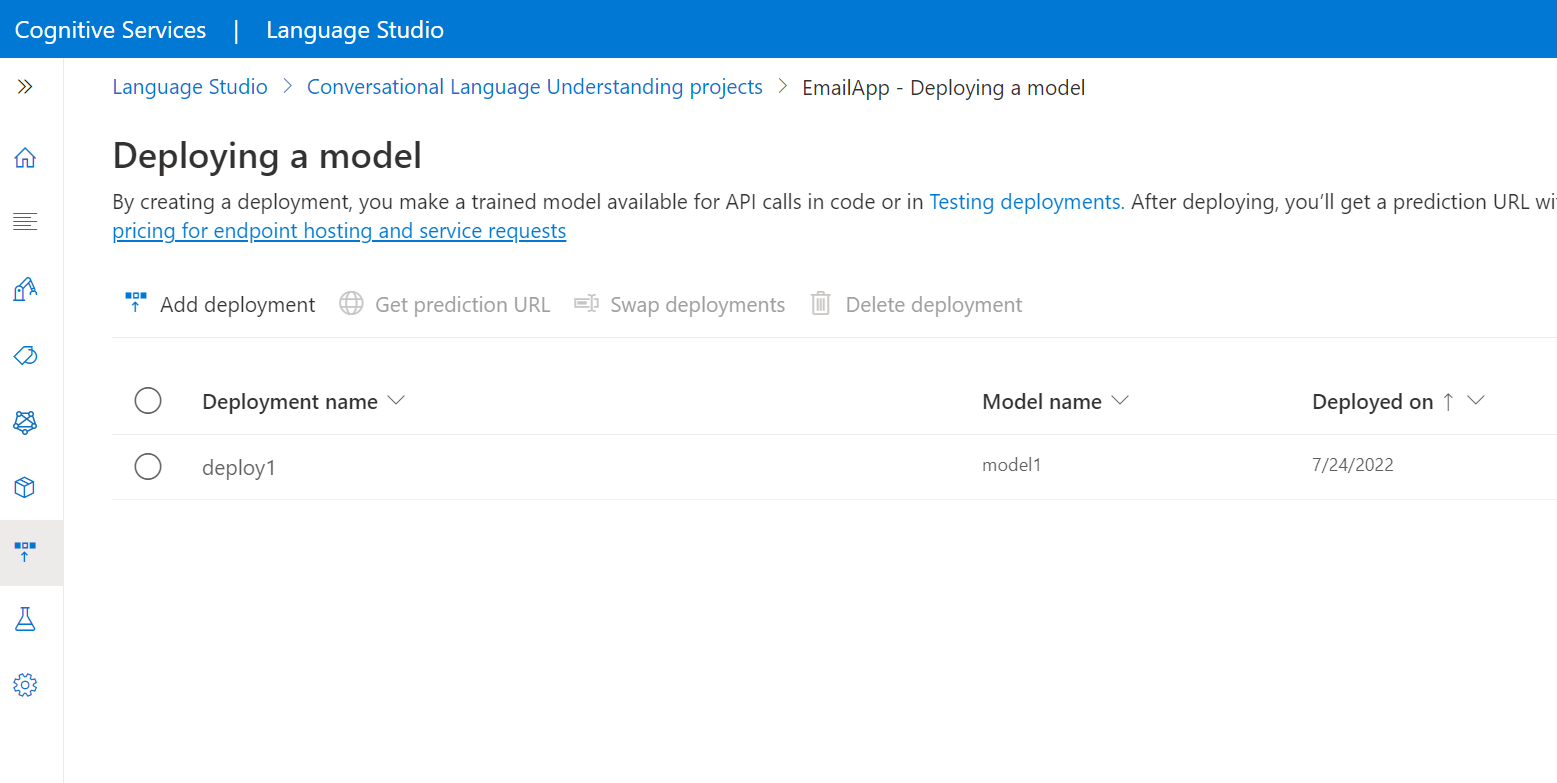
选择“创建新部署名称”以创建新的部署,并从下面的下拉列表中分配一个已训练的模型。 还可选择“覆盖现有部署名称”,有效地替换现有部署使用的模型。
注意
覆盖现有部署不需要更改预测 API 调用,但产生的结果将基于新分配的模型。

从“模型”下拉列表中选择已训练的模型。
选择“部署”以启动部署作业。
部署成功后,旁边将显示到期日期。 部署到期是指已部署的模型将无法用于预测,这通常发生在训练配置到期后的 12 个月内。


你将在下一节中使用该项目名称和部署名称。
识别来自麦克风的意向
按照以下步骤创建新的控制台应用程序并安装语音 SDK。
在需要新项目的地方打开命令提示符,然后使用 .NET CLI 创建控制台应用程序。 应在项目目录中创建
Program.cs文件。dotnet new console使用 .NET CLI 在新项目中安装语音 SDK。
dotnet add package Microsoft.CognitiveServices.Speech将
Program.cs的内容替换为以下代码。using Microsoft.CognitiveServices.Speech; using Microsoft.CognitiveServices.Speech.Audio; using Microsoft.CognitiveServices.Speech.Intent; class Program { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" static string languageKey = Environment.GetEnvironmentVariable("LANGUAGE_KEY"); static string languageEndpoint = Environment.GetEnvironmentVariable("LANGUAGE_ENDPOINT"); static string speechKey = Environment.GetEnvironmentVariable("SPEECH_KEY"); static string speechRegion = Environment.GetEnvironmentVariable("SPEECH_REGION"); // Your CLU project name and deployment name. static string cluProjectName = "YourProjectNameGoesHere"; static string cluDeploymentName = "YourDeploymentNameGoesHere"; async static Task Main(string[] args) { var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion); speechConfig.SpeechRecognitionLanguage = "en-US"; using var audioConfig = AudioConfig.FromDefaultMicrophoneInput(); // Creates an intent recognizer in the specified language using microphone as audio input. using (var intentRecognizer = new IntentRecognizer(speechConfig, audioConfig)) { var cluModel = new ConversationalLanguageUnderstandingModel( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); var collection = new LanguageUnderstandingModelCollection(); collection.Add(cluModel); intentRecognizer.ApplyLanguageModels(collection); Console.WriteLine("Speak into your microphone."); var recognitionResult = await intentRecognizer.RecognizeOnceAsync().ConfigureAwait(false); // Checks result. if (recognitionResult.Reason == ResultReason.RecognizedIntent) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent Id: {recognitionResult.IntentId}."); Console.WriteLine($" Language Understanding JSON: {recognitionResult.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult)}."); } else if (recognitionResult.Reason == ResultReason.RecognizedSpeech) { Console.WriteLine($"RECOGNIZED: Text={recognitionResult.Text}"); Console.WriteLine($" Intent not recognized."); } else if (recognitionResult.Reason == ResultReason.NoMatch) { Console.WriteLine($"NOMATCH: Speech could not be recognized."); } else if (recognitionResult.Reason == ResultReason.Canceled) { var cancellation = CancellationDetails.FromResult(recognitionResult); Console.WriteLine($"CANCELED: Reason={cancellation.Reason}"); if (cancellation.Reason == CancellationReason.Error) { Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}"); Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}"); Console.WriteLine($"CANCELED: Did you update the subscription info?"); } } } } }在
Program.cs中,将cluProjectName和cluDeploymentName变量设置为项目和部署的名称。 有关如何创建 CLU 项目和部署的信息,请参阅创建对话语言理解项目。若要更改语音识别语言,请将
en-US替换为其他支持的语言。 例如,es-ES代表西班牙语(西班牙)。 如果未指定语言,则默认语言为en-US。 若要详细了解如何从多种使用的语言中进行识别,请参阅语言识别。
运行新的控制台应用程序,从麦克风开始进行语音识别:
dotnet run
重要
请确保按照上文所述设置 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 环境变量。 如果未设置这些变量,示例将失败并显示错误消息。
当系统提示时,对着麦克风说话。 你说话的内容应该以文本的形式输出:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
注意
语音 SDK 版本 1.26 中新增了通过 LanguageUnderstandingServiceResponse_JsonResult 属性对 CLU 的 JSON 响应的支持。
意向将按照从最有可能到最不可能的概率顺序返回。 下面是 JSON 输出经过格式设置的版本,其中 topIntent 是 HomeAutomation.TurnOn,置信度分数为 0.97712576 (97.71%)。 第二个最有可能的意向可能是置信度分数为 0.8985081 (84.31%) 的 HomeAutomation.TurnOff。
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
注解
你现已完成快速入门,下面是一些其他注意事项:
- 此示例使用
RecognizeOnceAsync操作听录 30 秒以内的语音,或直到检测到静音。 如要详细了解长音频的持续识别(包括多语言对话),请参阅如何识别语音。 - 若要从音频文件中识别语音,请使用
FromWavFileInput,不要使用FromDefaultMicrophoneInput:using var audioConfig = AudioConfig.FromWavFileInput("YourAudioFile.wav"); - 对于压缩的音频文件(如 MP4),请安装 GStreamer 并使用
PullAudioInputStream或PushAudioInputStream。 有关详细信息,请参阅如何使用压缩的输入音频。
清理资源
可以使用 Azure 门户或 Azure 命令行接口 (CLI) 删除所创建的语言和语音资源。
参考文档 | 包 (NuGet) | GitHub 上的其他示例
在此快速入门中,你将使用语音和语言服务来识别从麦克风获取的音频数据中的意向。 具体而言,你将使用语音服务来识别语音,并使用对话语言理解 (CLU) 模型来识别意向。
重要
对话语言理解 (CLU) 适用于具有语音 SDK 1.25 或更高版本的 C# 和 C++。
先决条件
设置环境
语音 SDK 以 NuGet 包的形式提供并实现了 .NET Standard 2.0。 本指南的后面部分会安装语音 SDK,但先请查看 SDK 安装指南以了解更多要求。
设置环境变量。
此示例需要名为 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 的环境变量。
必须对应用程序进行身份验证才能访问 Azure AI 服务资源。 本文介绍如何使用环境变量来存储凭据。 然后,你可以从代码访问环境变量来验证应用程序。 对于生产环境,请使用更安全的方式来存储和访问凭据。
重要
我们建议使用 Azure 资源的托管标识进行 Microsoft Entra ID 身份验证,以避免将凭据随云中运行的应用程序一起存储。
如果使用 API 密钥,请将其安全地存储在其他某个位置,例如 Azure 密钥保管库中。 请不要直接在代码中包含 API 密钥,并且切勿公开发布该密钥。
有关 Azure AI 服务安全性的详细信息,请参阅对 Azure AI 服务的请求进行身份验证。
若要设置环境变量,请打开控制台窗口,按照操作系统和开发环境的说明进行操作。
- 若要设置
LANGUAGE_KEY环境变量,请将your-language-key替换为资源的其中一个密钥。 - 若要设置
LANGUAGE_ENDPOINT环境变量,请将your-language-endpoint替换为你的资源的其中一个区域。 - 若要设置
SPEECH_KEY环境变量,请将your-speech-key替换为资源的其中一个密钥。 - 若要设置
SPEECH_REGION环境变量,请将your-speech-region替换为你的资源的其中一个区域。
setx LANGUAGE_KEY your-language-key
setx LANGUAGE_ENDPOINT your-language-endpoint
setx SPEECH_KEY your-speech-key
setx SPEECH_REGION your-speech-region
注意
如果只需要访问当前正在运行的控制台中的环境变量,则可以使用 set(而不是 setx)设置环境变量。
添加环境变量后,可能需要重启任何正在运行的、需要读取环境变量的程序(包括控制台窗口)。 例如,如果使用 Visual Studio 作为编辑器,请在运行示例之前重启 Visual Studio。
创建对话语言理解项目
创建语言资源后,请在 Language Studio 中创建对话语言理解项目。 项目是一个基于数据构建自定义 ML 模型的工作区。 只有你和对所使用的语言资源具有访问权限的其他人才能访问你的项目。
转到 Language Studio,然后使用 Azure 帐户登录。
创建对话语言理解项目
对于本快速入门,可以下载这个示例家庭自动化项目并将其导入。 此项目可以通过用户输入预测预期命令,例如开灯和关灯。
在 Language Studio 的“理解问题和对话语言”部分下,选择“对话语言理解”。
随后你会转到“对话语言理解项目”页。 在“新建项目”按钮旁边,选择“导入”。
在显示的窗口中,上传要导入的 JSON 文件。 请确保该文件遵循受支持的 JSON 格式。
上传完成后,你将进入“架构定义”页。 对于本快速入门,架构已经生成,并且语句已标有意向和实体。
训练模型
通常,在创建项目后,你应该生成架构并标记语句。 对于本快速入门,我们已导入一个生成了架构和标记了语句的现成项目。
若要训练模型,需要启动训练作业。 成功训练作业的输出是已训练的模型。
若要在 Language Studio 中开始训练模型,请执行以下操作:
在左侧菜单中,选择“训练模型”。
从顶部菜单中选择“启动训练作业”。
选择“训练新模型”,然后在文本框中输入新模型名称。 但要将现有模型替换为已针对新数据训练的模型,请选择“覆盖现有模型”,然后选择现有模型。 覆盖已训练的模型是不可逆的,但这在部署新模型之前不会影响已部署的模型。
选择训练模式。 可以选择“标准训练”以加快训练速度,但此模式仅适用于英语。 或者,可以选择其他语言和多语言项目支持的“高级训练”,但此模式需要更长的训练时间。 详细了解训练模式。
选择一种数据拆分方法。 可以选择“从训练数据中自动拆分测试集”,系统将根据指定的百分比在训练集和测试集之间拆分语句。 或者,可以选择“使用手动拆分训练和测试数据”,仅当在标记语句期间已将语句添加到测试集时才会启用此选项。
选择“训练”按钮。
从列表中选择训练作业 ID。 出现一个面板,在该面板中可以检查此作业的训练进度、作业状态和其他详细信息。
注意
- 只有成功完成的训练作业才会生成模型。
- 训练时间从几分钟到几个小时不等,具体取决于语句数量。
- 一次只能运行一个训练作业。 在运行的作业完成之前,无法在同一项目中启动其他训练作业。
- 用于训练模型的机器学习会定期更新。 如果要在以前的配置版本上进行训练,请在“启动训练作业”页中单击“单击此处进行更改”,然后选择以前的版本。
部署模型
一般情况下,在训练模型后,你会查看其评估详细信息。 在本快速入门中,你只需部署模型,使其在 Language Studio 中可供试用,你也可以调用预测 API。
若要要从 Language Studio 中部署模型,请执行以下操作:
在左侧菜单中,选择“部署模型”。
选择“添加部署”以启动“添加部署”向导。
选择“创建新部署名称”以创建新的部署,并从下面的下拉列表中分配一个已训练的模型。 还可选择“覆盖现有部署名称”,有效地替换现有部署使用的模型。
注意
覆盖现有部署不需要更改预测 API 调用,但产生的结果将基于新分配的模型。
从“模型”下拉列表中选择已训练的模型。
选择“部署”以启动部署作业。
部署成功后,旁边将显示到期日期。 部署到期是指已部署的模型将无法用于预测,这通常发生在训练配置到期后的 12 个月内。
你将在下一节中使用该项目名称和部署名称。
识别来自麦克风的意向
按照以下步骤创建新的控制台应用程序并安装语音 SDK。
在 Visual Studio Community 2022 中创建一个名为
SpeechRecognition的新 C++ 控制台项目。使用 NuGet 包管理器在新项目中安装语音 SDK。
Install-Package Microsoft.CognitiveServices.Speech将
SpeechRecognition.cpp的内容替换为以下代码:#include <iostream> #include <stdlib.h> #include <speechapi_cxx.h> using namespace Microsoft::CognitiveServices::Speech; using namespace Microsoft::CognitiveServices::Speech::Audio; using namespace Microsoft::CognitiveServices::Speech::Intent; std::string GetEnvironmentVariable(const char* name); int main() { // This example requires environment variables named: // "LANGUAGE_KEY", "LANGUAGE_ENDPOINT", "SPEECH_KEY", and "SPEECH_REGION" auto languageKey = GetEnvironmentVariable("LANGUAGE_KEY"); auto languageEndpoint = GetEnvironmentVariable("LANGUAGE_ENDPOINT"); auto speechKey = GetEnvironmentVariable("SPEECH_KEY"); auto speechRegion = GetEnvironmentVariable("SPEECH_REGION"); auto cluProjectName = "YourProjectNameGoesHere"; auto cluDeploymentName = "YourDeploymentNameGoesHere"; if ((size(languageKey) == 0) || (size(languageEndpoint) == 0) || (size(speechKey) == 0) || (size(speechRegion) == 0)) { std::cout << "Please set LANGUAGE_KEY, LANGUAGE_ENDPOINT, SPEECH_KEY, and SPEECH_REGION environment variables." << std::endl; return -1; } auto speechConfig = SpeechConfig::FromSubscription(speechKey, speechRegion); speechConfig->SetSpeechRecognitionLanguage("en-US"); auto audioConfig = AudioConfig::FromDefaultMicrophoneInput(); auto intentRecognizer = IntentRecognizer::FromConfig(speechConfig, audioConfig); std::vector<std::shared_ptr<LanguageUnderstandingModel>> models; auto cluModel = ConversationalLanguageUnderstandingModel::FromResource( languageKey, languageEndpoint, cluProjectName, cluDeploymentName); models.push_back(cluModel); intentRecognizer->ApplyLanguageModels(models); std::cout << "Speak into your microphone.\n"; auto result = intentRecognizer->RecognizeOnceAsync().get(); if (result->Reason == ResultReason::RecognizedIntent) { std::cout << "RECOGNIZED: Text=" << result->Text << std::endl; std::cout << " Intent Id: " << result->IntentId << std::endl; std::cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl; } else if (result->Reason == ResultReason::RecognizedSpeech) { std::cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl; } else if (result->Reason == ResultReason::NoMatch) { std::cout << "NOMATCH: Speech could not be recognized." << std::endl; } else if (result->Reason == ResultReason::Canceled) { auto cancellation = CancellationDetails::FromResult(result); std::cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl; if (cancellation->Reason == CancellationReason::Error) { std::cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl; std::cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl; std::cout << "CANCELED: Did you update the subscription info?" << std::endl; } } } std::string GetEnvironmentVariable(const char* name) { #if defined(_MSC_VER) size_t requiredSize = 0; (void)getenv_s(&requiredSize, nullptr, 0, name); if (requiredSize == 0) { return ""; } auto buffer = std::make_unique<char[]>(requiredSize); (void)getenv_s(&requiredSize, buffer.get(), requiredSize, name); return buffer.get(); #else auto value = getenv(name); return value ? value : ""; #endif }在
SpeechRecognition.cpp中,将cluProjectName和cluDeploymentName变量设置为项目和部署的名称。 有关如何创建 CLU 项目和部署的信息,请参阅创建对话语言理解项目。若要更改语音识别语言,请将
en-US替换为其他支持的语言。 例如,es-ES代表西班牙语(西班牙)。 如果未指定语言,则默认语言为en-US。 若要详细了解如何从多种使用的语言中进行识别,请参阅语言识别。
生成并运行新的控制台应用程序,从麦克风开始进行语音识别。
重要
请确保按照上文所述设置 LANGUAGE_KEY、LANGUAGE_ENDPOINT、SPEECH_KEY 和 SPEECH_REGION 环境变量。 如果未设置这些变量,示例将失败并显示错误消息。
当系统提示时,对着麦克风说话。 你说话的内容应该以文本的形式输出:
Speak into your microphone.
RECOGNIZED: Text=Turn on the lights.
Intent Id: HomeAutomation.TurnOn.
Language Understanding JSON: {"kind":"ConversationResult","result":{"query":"turn on the lights","prediction":{"topIntent":"HomeAutomation.TurnOn","projectKind":"Conversation","intents":[{"category":"HomeAutomation.TurnOn","confidenceScore":0.97712576},{"category":"HomeAutomation.TurnOff","confidenceScore":0.8431633},{"category":"None","confidenceScore":0.782861}],"entities":[{"category":"HomeAutomation.DeviceType","text":"lights","offset":12,"length":6,"confidenceScore":1,"extraInformation":[{"extraInformationKind":"ListKey","key":"light"}]}]}}}.
注意
语音 SDK 版本 1.26 中新增了通过 LanguageUnderstandingServiceResponse_JsonResult 属性对 CLU 的 JSON 响应的支持。
意向将按照从最有可能到最不可能的概率顺序返回。 下面是 JSON 输出经过格式设置的版本,其中 topIntent 是 HomeAutomation.TurnOn,置信度分数为 0.97712576 (97.71%)。 第二个最有可能的意向可能是置信度分数为 0.8985081 (84.31%) 的 HomeAutomation.TurnOff。
{
"kind": "ConversationResult",
"result": {
"query": "turn on the lights",
"prediction": {
"topIntent": "HomeAutomation.TurnOn",
"projectKind": "Conversation",
"intents": [
{
"category": "HomeAutomation.TurnOn",
"confidenceScore": 0.97712576
},
{
"category": "HomeAutomation.TurnOff",
"confidenceScore": 0.8431633
},
{
"category": "None",
"confidenceScore": 0.782861
}
],
"entities": [
{
"category": "HomeAutomation.DeviceType",
"text": "lights",
"offset": 12,
"length": 6,
"confidenceScore": 1,
"extraInformation": [
{
"extraInformationKind": "ListKey",
"key": "light"
}
]
}
]
}
}
}
注解
你现已完成快速入门,下面是一些其他注意事项:
- 此示例使用
RecognizeOnceAsync操作听录 30 秒以内的语音,或直到检测到静音。 如要详细了解长音频的持续识别(包括多语言对话),请参阅如何识别语音。 - 若要从音频文件中识别语音,请使用
FromWavFileInput,不要使用FromDefaultMicrophoneInput:auto audioInput = AudioConfig::FromWavFileInput("YourAudioFile.wav"); - 对于压缩的音频文件(如 MP4),请安装 GStreamer 并使用
PullAudioInputStream或PushAudioInputStream。 有关详细信息,请参阅如何使用压缩的输入音频。
清理资源
可以使用 Azure 门户或 Azure 命令行接口 (CLI) 删除所创建的语言和语音资源。
适用于 Java 的语音 SDK 不支持通过对话语言理解 (CLU) 来识别意向。 请选择其他编程语言,或从本文开头链接的 Java 引用和示例。