你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure OpenAI Web 应用
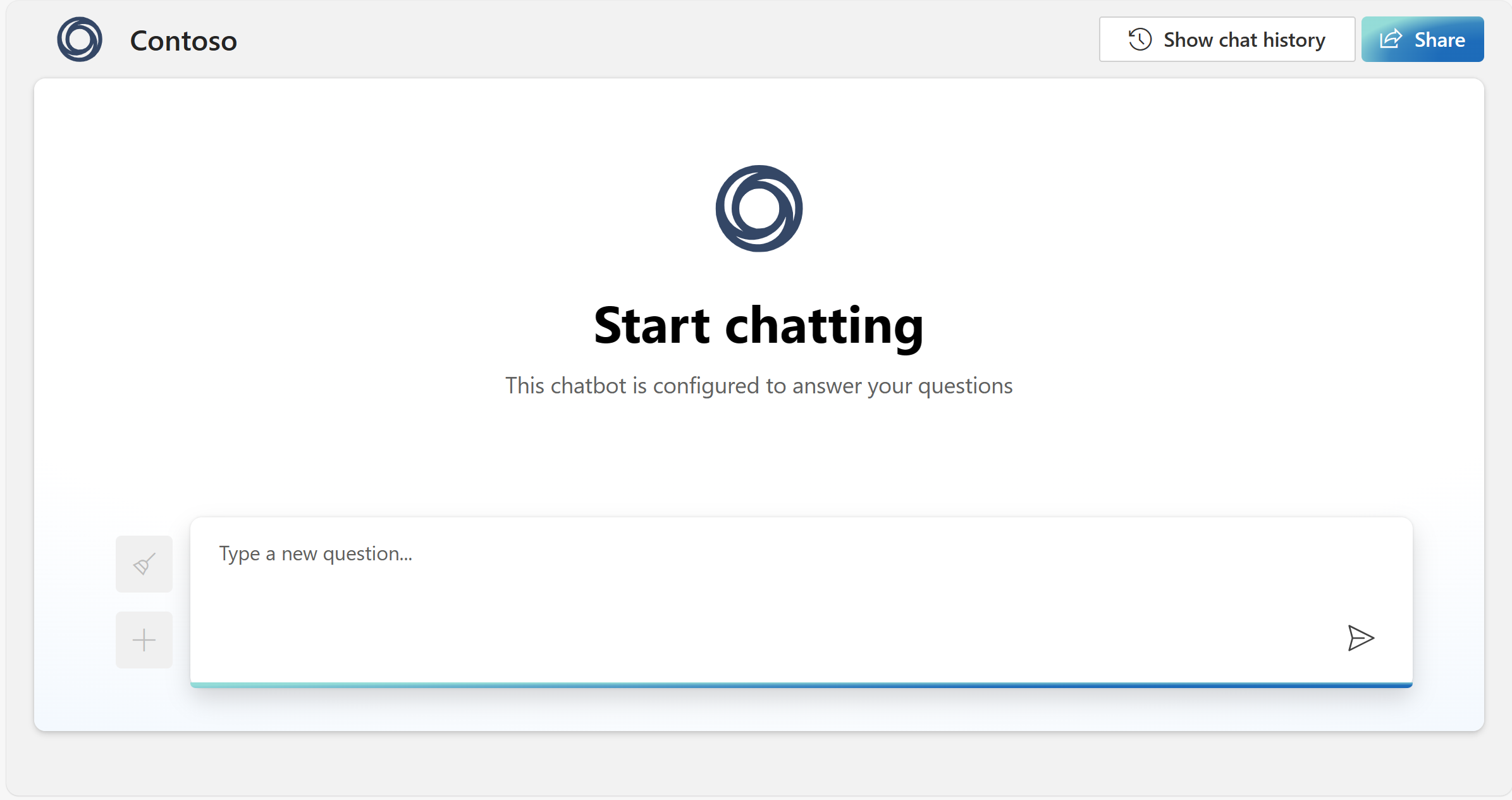
除了 Azure AI Foundry 门户、API 和 SDK 之外,你还可以使用可自定义的独立 Web 应用,通过图形用户界面与 Azure OpenAI 模型进行交互。 主要功能包括:
- 与多个数据源建立连接,以支持丰富的查询和检索扩充生成,包括 Azure AI 搜索、提示流等。
- 通过 Cosmos DB 收集对话历史记录和用户反馈收集。
- 通过 Microsoft Entra ID 进行基于角色的访问控制身份验证。
- 使用环境变量自定义用户界面、数据源和功能(通过 Azure 门户无需代码)。
可以通过 Azure AI Foundry 门户、Azure 门户或通过本地计算机的 Azure Developer CLI 部署该应用(请参阅此处的存储库,获取说明)。 根据部署通道,你可以预加载数据源以通过 Web 应用程序聊天,但在部署后可以更改。
对于希望通过 Web 应用程序与其数据交互的 Azure OpenAI 初学者来说,Azure AI Foundry 门户是进行初始部署和数据源配置的推荐媒介。
重要注意事项
- 此 Web 应用程序及其许多功能均处于预览状态,这意味着可能会出现错误,并且并非所有功能都是完整的。 如果发现 bug 或需要帮助,可在关联的 GitHub 存储库中提出问题。
- 发布 Web 应用会在你的订阅中创建 Azure 应用服务实例。 它可能会产生成本,具体取决于你选择的定价计划。 使用完应用后,可以从 Azure 门户中删除该应用以及任何相关资源。
- 目前不支持带有视觉模型的 GPT-4 Turbo。
- 默认情况下,应用部署时已配置 Microsoft 标识提供者。 标识提供者将对应用的访问限制到 Azure 租户的成员。 若要添加或修改身份验证,请执行以下操作:
转到 Azure 门户并搜索发布期间指定的应用名称。 选择该 Web 应用,然后在左侧菜单中选择“身份验证”。 然后选择“添加标识提供者”。

选择“Microsoft”作为标识提供者。 此页上的默认设置将应用限制为仅租户,因此无需在此处更改任何其他内容。 选择 添加 。

现在,系统将要求用户使用其 Microsoft Entra 帐户登录,以访问你的应用。 如果愿意,可以按照类似的过程添加另一个标识提供者。 除验证用户是否为租户成员以外,应用不会以任何方式使用用户的登录信息。 有关管理身份验证的详细信息,请查看有关 Azure 应用服务上 Web 应用身份验证的快速入门。
使用环境变量自定义应用程序
可自定义应用的前端和后端逻辑。 该应用为常见的自定义场景提供了多个环境变量,例如更改应用中的图标。
部署 Web 应用程序后,可以通过 Azure 门户修改这些环境变量。
- 在 Azure 门户中,搜索并选择“应用服务”页面。
- 选择刚刚部署的 Web 应用。
- 在应用的左侧菜单中,选择“设置”>“环境变量”。
- 若要修改现有环境变量,请单击其名称。
- 若要添加单个新的环境变量,请单击面板顶部菜单栏中的“添加”。
- 若要使用基于 JSON 的编辑器管理环境变量,请单击“高级编辑”。
自定义应用时,建议:
清楚地传达你实现的每个设置如何影响用户体验。
轮换 Azure OpenAI 或 Azure AI 搜索资源的密钥后,更新每个已部署应用的应用设置以使用新 API 密钥。
修改应用程序用户界面
与用户界面自定义相关的环境变量包括:
-
UI_CHAT_DESCRIPTION:这是加载后位于页面中心UI_CHAT_TITLE下方的较小的段落文本。- 数据类型: 文本
-
UI_CHAT_LOGO:这是加载后页面中心中显示的大型图像。- 数据类型:图像的 URL
-
UI_CHAT_TITLE:这是加载后页面中心中显示的大型文本。- 数据类型: 文本
-
UI_FAVICON:这是浏览器窗口/选项卡上显示的网站图标。- 数据类型:图像的 URL
-
UI_LOGO:这是出现在页面的左上角和标题左侧的徽标。- 数据类型:图像的 URL
-
UI_TITLE:这是浏览器窗口/选项卡上显示的标题。它还会出现在页面左上角的徽标旁边。- 数据类型: 文本
-
UI_SHOW_SHARE_BUTTON:此按钮显示在页面的右上角,允许用户分享链接到 Web 应用的 URL。- 数据类型:布尔值,必须输入 True 或 False,如果留空或未指定,则默认值为 True。
-
UI_SHOW_CHAT_HISTORY_BUTTON:这显示在页面右上角和 UI_SHOW_SHARE_BUTTON 左侧。- 数据类型:布尔值,必须输入 True 或 False,如果留空或未指定,则默认值为 True。
若要修改应用程序用户界面,请按照上一步骤中的说明打开 Web 应用的环境变量页。 然后,使用“高级编辑”打开基于 JSON 的编辑器。 在 JSON 的顶部([ 字符之后),粘贴以下代码块并根据情况自定义值:
{
"name": "UI_CHAT_DESCRIPTION",
"value": "This is an example of a UI Chat Description. Chatbots can make mistakes. Check important info and sensitive info.",
"slotSetting": false
},
{
"name": "UI_CHAT_LOGO",
"value": "https://learn-bot.azurewebsites.net/assets/Contoso-ff70ad88.svg",
"slotSetting": false
},
{
"name": "UI_CHAT_TITLE",
"value": "This is an example of a UI Chat Title. Start chatting",
"slotSetting": false
},
{
"name": "UI_FAVICON",
"value": "https://learn-bot.azurewebsites.net/assets/Contoso-ff70ad88.svg",
"slotSetting": false
},
{
"name": "UI_LOGO",
"value": "https://learn-bot.azurewebsites.net/assets/Contoso-ff70ad88.svg",
"slotSetting": false
},
{
"name": "UI_TITLE",
"value": "This is an example of a UI Title",
"slotSetting": false
},
使用 Cosmos DB 启用聊天历史记录
可为 Web 应用的用户启用历史聊天记录。 启用该功能后,用户有权访问之前的各个查询和响应。
若要启用聊天历史记录,请使用 Azure AI Foundry 门户将模型部署或重新部署为 Web 应用,然后选择“在 Web 应用中启用聊天历史记录和用户反馈”。

重要
启用历史聊天记录会在资源组中创建 Azure Cosmos DB 实例,并且会对超出任何免费套餐的存储收取额外费用。
启用历史聊天记录后,用户可在应用的右上角显示和隐藏它。 当用户显示历史聊天记录时,他们可重命名或删除对话。 可以使用上一节中指定的环境变量 UI_SHOW_CHAT_HISTORY_BUTTON 修改用户是否可以访问此函数。 由于用户已登录到应用,因此对话会自动从最新到最早进行排序。 对话根据对话中的第一个查询进行命名。
注意
热门的 Azure 区域(例如美国东部)可能会经历高需求时期,在此期间可能无法部署新的 Cosmos DB 实例。 在这种情况下,选择部署到备用区域(例如美国东部 2),或重试部署,直到部署成功。 如果 Cosmos DB 的部署失败,你的应用将在其指定的 URL 处可用,但聊天历史记录将不可用。 启用对话历史记录还将启用右上角的“查看对话历史记录”按钮。
在选中“聊天历史记录”选项的情况下进行部署时,系统将自动填充以下环境变量,因此除非你希望切换 Cosmos DB 实例,否则无需修改它们。 它们是:
-
AZURE_COSMOSDB_ACCOUNT:这是随 Web 应用一起部署的 Cosmos DB 帐户的名称。- 数据类型: 文本
-
AZURE_COSMOSDB_ACCOUNT_KEY:这是一个替代环境变量,仅当未通过 Microsoft Entra ID 授予权限而是使用基于密钥的身份验证时才会用到。- 数据类型:文本。 通常不存在或未填充。
-
AZURE_COSMOSDB_DATABASE:这是 Cosmos DB 中随 Web 应用一起部署的数据库对象的名称。- 数据类型:文本,应为
db_conversation_history
- 数据类型:文本,应为
-
AZURE_COSMOSDB_CONTAINER:这是 Cosmos DB 中随 Web 应用一起部署的数据库容器对象的名称。- 数据类型:文本,应为
conversations
- 数据类型:文本,应为
-
AZURE_COSMOSDB_ACCOUNT:这是随 Web 应用一起部署的 Cosmos DB 帐户的名称。- 数据类型: 文本

收集用户反馈
若要收集用户反馈,可以启用一组显示在聊天机器人响应中的“竖起拇指”和“拇指向下”图标。 用户可借此评估响应的质量,并使用“提供负面反馈”模式窗口指示错误发生的位置。
若要启用此功能,请将以下环境变量设置为 True:
-
AZURE_COSMOSDB_ENABLE_FEEDBACK:这是随 Web 应用一起部署的 Cosmos DB 帐户的名称。- 数据类型:布尔值,必须输入 True 或 False
可以使用高级编辑或简单的“编辑”选项来完成此操作,如前所述。 要粘贴到高级编辑 JSON 编辑器中的 JSON 为:
{
"name": "AZURE_COSMOSDB_ENABLE_FEEDBACK",
"value": "True",
"slotSetting": false
},
连接到 Azure AI 搜索并上传文件作为数据源
使用 Azure AI Foundry 门户
按照将 Azure AI 搜索与 Azure AI Foundry 集成的教程或快速入门操作并重新部署应用程序。
使用环境变量
若要在不重新部署应用的情况下连接到 Azure AI 搜索,可以使用前面所述的任何编辑选项修改以下必填环境变量。
-
DATASOURCE_TYPE:这将确定在回答用户查询时要使用的数据源。- 数据类型:文本。 应设置为
AzureCognitiveSearch(Azure AI 搜索的旧称)
- 数据类型:文本。 应设置为
-
AZURE_SEARCH_SERVICE:这是 Azure AI 搜索实例的名称。- 数据类型: 文本
-
AZURE_SEARCH_INDEX:这是 Azure AI 搜索实例的索引名称的名称。- 数据类型: 文本
-
AZURE_SEARCH_KEY:这是 Azure AI 搜索实例的身份验证密钥。 如果使用建议的 Microsoft Entra ID 进行身份验证,则为可选项。- 数据类型: 文本
使用环境变量进一步自定义方案
-
AZURE_SEARCH_USE_SEMANTIC_SEARCH:指示是否在 Azure AI 搜索中使用语义搜索。- 数据类型:布尔值,如果不使用语义搜索,则应设置为
False。
- 数据类型:布尔值,如果不使用语义搜索,则应设置为
-
AZURE_SEARCH_SEMANTIC_SEARCH_CONFIG:指定启用语义搜索时要使用的语义搜索配置的名称。- 数据类型:文本,默认值为
azureml-default。
- 数据类型:文本,默认值为
-
AZURE_SEARCH_INDEX_TOP_K:定义要从 Azure AI 搜索检索的最相关的文档数。- 数据类型:整数,应设置为
5。
- 数据类型:整数,应设置为
-
AZURE_SEARCH_ENABLE_IN_DOMAIN:将响应限制为仅与数据相关的查询。- 数据类型:布尔值,应设置为
True。
- 数据类型:布尔值,应设置为
-
AZURE_SEARCH_CONTENT_COLUMNS:指定 Azure AI 搜索索引中包含文档文本内容的字段列表,用于制定机器人响应。- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
content,
- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
-
AZURE_SEARCH_FILENAME_COLUMN:指定 Azure AI 搜索索引中的字段,该字段提供要在 UI 中显示的源数据的唯一标识符。- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
filepath,
- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
-
AZURE_SEARCH_TITLE_COLUMN:指定 Azure AI 搜索索引中的字段,该字段为要在 UI 中显示的数据内容提供相关的标题或标头。- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
title,
- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
-
AZURE_SEARCH_URL_COLUMN:指定 Azure AI 搜索索引中包含文档 URL 的字段。- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
url,
- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
-
AZURE_SEARCH_VECTOR_COLUMNS:指定 Azure AI 搜索索引中包含文档向量嵌入的字段列表,用于制定机器人响应。- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
contentVector,
- 数据类型:文本,如果从 Azure AI Foundry 门户部署,则默认为
-
AZURE_SEARCH_QUERY_TYPE:指定要使用的查询类型:simple、semantic、vector、vectorSimpleHybrid或vectorSemanticHybrid。 此设置优先于AZURE_SEARCH_USE_SEMANTIC_SEARCH。- 数据类型:文本,建议使用
vectorSemanticHybrid测试。
- 数据类型:文本,建议使用
-
AZURE_SEARCH_PERMITTED_GROUPS_COLUMN:指定 Azure AI 搜索索引中包含 Microsoft Entra 组 ID 的字段,用于确定文档级别的访问控制。- 数据类型: 文本
-
AZURE_SEARCH_STRICTNESS:指定模型限制对数据的响应的严格程度。- 数据类型:整数,应设置在
1至5之间,建议设置为3。
- 数据类型:整数,应设置在
-
AZURE_OPENAI_EMBEDDING_NAME:如果使用矢量搜索,则指定嵌入模型部署的名称。- 数据类型: 文本
要粘贴到高级编辑 JSON 编辑器中的 JSON 为:
{
"name": "AZURE_SEARCH_CONTENT_COLUMNS",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_ENABLE_IN_DOMAIN",
"value": "true",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_FILENAME_COLUMN",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_INDEX",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_KEY",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_PERMITTED_GROUPS_COLUMN",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_QUERY_TYPE",
"value": "vectorSemanticHybrid",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_SEMANTIC_SEARCH_CONFIG",
"value": "azureml-default",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_SERVICE",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_STRICTNESS",
"value": "3",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_TITLE_COLUMN",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_TOP_K",
"value": "5",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_URL_COLUMN",
"value": "",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_USE_SEMANTIC_SEARCH",
"value": "true",
"slotSetting": false
},
{
"name": "AZURE_SEARCH_VECTOR_COLUMNS",
"value": "contentVector",
"slotSetting": false
},
连接到提示流作为数据源
提示流允许你根据用户查询定义高度可定制的 RAG 和处理逻辑。
在 Azure AI Foundry 门户中创建和部署提示流
按照本教程,在 Azure AI Foundry 门户中为提示流创建、测试和部署推理终结点。
通过提示流启用基础引文
将提示流配置为在集成此 Web 应用程序时显示引文时,它必须返回两个关键输出:一个称为 documents(你的引文),另一个称为 reply(你的自然语言答案)。
-
documents是一个 JSON 对象,该对象应包含以下元素。citations是一个列表,其中包含多个遵循同一架构的项。 应根据所选 RAG 模式生成并填充documents对象。
{
"citations": [
{
"content": "string",
"id": 12345,
"title": "string",
"filepath": "string",
"url": "string",
"metadata": "string",
"chunk_id": None,
"reindex_id": None,
"part_index": None
}
],
"intent": "Your_string_here"
}
-
reply由返回的字符串组成,该字符串代表给定用户查询的最终自然语言。reply必须包含对每个文档(来源)的引用,格式如下:[doc1], [doc2]等。Web 应用程序将解析reply并处理引用,用直接链接到返回的有序documents的小上标数字指示符替换[doc1]的所有实例。 因此,必须提示生成最终自然语言的 LLM 包含这些引用,也应在 LLM 调用中传递这些引用以确保它们准确无误并按正确的顺序排列。 例如:
system:
You are a helpful chat assistant that answers a user's question based on the information retrieved from a data source.
YOU MUST ALWAYS USE CITATIONS FOR ALL FACTUAL RESPONSES. YOU MUST INCLUDE CITATIONS IN YOUR ANSWER IN THE FORMAT [doc1], [doc2], ... AND SO FORTH WHEN YOU ARE USING INFORMATION RELATING TO SAID SOURCE. THIS MUST BE RETURNED IN YOUR ANSWER.
Provide sort and concise answers with details directly related to the query.
## Conversation history for context
{% for item in chat_history %}
user:
{{item.inputs.query}}
assistant:
{{item.outputs.reply}}
{% endfor %}
## Current question
user:
### HERE ARE SOME CITED SOURCE INFORMATION FROM A MOCKED API TO ASSIST WITH ANSWERING THE QUESTION BELOW. ANSWER ONLY BASED ON THE TRUTHS PRESENTED HERE.
{{your_input_name_for_documents}}
FOR EACH OF THE CITATIONS ABOVE, YOU MUST INCLUDE IN YOUR ANSWER [doc1], [doc2], ... AND SO FORTH WHEN YOU ARE USING INFORMATION RELATING TO SAID SOURCE. THIS MUST BE RETURNED IN YOUR ANSWER.
### HERE IS THE QUESTION TO ANSWER.
{{question}}
配置环境变量以集成提示流
要修改的环境变量包括:
-
AZURE_OPENAI_STREAM:这将确定是否以流式处理(增量加载)格式加载答案。 提示流不支持此功能,因此,若要使用此功能,必须设置为False。- 数据类型:布尔值,如果不使用提示流则设置为
True,如果使用提示流则设置为False
- 数据类型:布尔值,如果不使用提示流则设置为
-
USE_PROMPTFLOW:指示是否使用部署的现有提示流终结点。 如果设置为True,则必须同时设置PROMPTFLOW_ENDPOINT和PROMPTFLOW_API_KEY。- 数据类型:布尔值,如果不使用提示流,应设置为
False。
- 数据类型:布尔值,如果不使用提示流,应设置为
-
PROMPTFLOW_ENDPOINT:指定已部署的提示流终结点的 URL。- 数据类型:文本,例如
https://pf-deployment-name.region.inference.ml.azure.com/score
- 数据类型:文本,例如
-
PROMPTFLOW_API_KEY:已部署的提示流终结点的身份验证密钥。 注意:仅支持基于密钥的身份验证。- 数据类型: 文本
-
PROMPTFLOW_RESPONSE_TIMEOUT:定义提示流终结点响应的超时值(以秒为单位)。- 数据类型:整数,应设置为
120。
- 数据类型:整数,应设置为
-
PROMPTFLOW_REQUEST_FIELD_NAME:用于构造提示流请求的默认字段名称。 注意:系统会根据交互自动构建chat_history。 如果 API 需要其他必填字段,则需要更改promptflow_request函数下的请求参数。- 数据类型:文本,应设置为
query。
- 数据类型:文本,应设置为
-
PROMPTFLOW_RESPONSE_FIELD_NAME:用于处理来自提示流请求的响应的默认字段名称。- 数据类型:文本,应设置为
reply。
- 数据类型:文本,应设置为
-
PROMPTFLOW_CITATIONS_FIELD_NAME:用于处理来自提示流请求的引文输出的默认字段名称。- 数据类型:文本,应设置为
documents。
- 数据类型:文本,应设置为
连接到其他数据源
支持其他数据源,包括:
- Azure Cosmos DB
- Elasticsearch
- Azure SQL Server
- Pinecone
- Azure 机器学习索引
有关启用这些数据源的更多说明,请参阅 GitHub 存储库。
更新 Web 应用以包含最新更改
注意
自 2024 年 2 月 1 日起,Web 应用要求将应用启动命令设置为 python3 -m gunicorn app:app。 更新在 2024 年 2 月 1 日之前发布的应用时,需要从“应用服务配置”页手动添加启动命令。
建议经常从 Web 应用源代码的 main 分支中拉取更改,以确保获得最新的 bug 修复、API 版本和改进。 此外,每当所使用的 API 版本停用时,都必须同步 Web 应用。 考虑选择 Web 应用的 GitHub 存储库上的“监视”或星型按钮,以接收有关源代码更改和更新的通知。
如果尚未自定义 Web 应用,可使用以下步骤来同步它:
在 Azure 门户中转到 Web 应用。
在左侧菜单上的“部署”下,选择“部署中心”。
选择窗格顶部的“同步”,并确认将要重新部署该应用。


如果自定义或更改了应用的源代码,则需要手动更新应用的源代码并重新部署它:
- 如果应用托管在 GitHub 上,请将代码更改推送到存储库,然后使用前面的同步步骤。
- 如果要手动(例如通过使用 Azure CLI)重新部署该应用,请遵循你的部署策略的步骤操作。
删除 Cosmos DB 实例
删除 Web 应用不会自动删除 Cosmos DB 实例。 若要删除 Cosmos DB 实例以及所有存储的聊天,需要转到 Azure 门户中的关联资源并将其删除。 如果删除 Cosmos DB 资源但在 Azure AI Foundry 门户提供的后续更新中始终选中聊天历史记录选项,则应用程序会通知用户所发生的连接错误。 但是,用户可以继续使用 Web 应用,不过无法访问聊天历史记录。
启用在服务之间进行的 Microsoft Entra ID 身份验证
对于 Web 应用,若要启用 Microsoft Entra ID 以进行服务内身份验证,请按照以下步骤操作。
在 Azure OpenAI 资源和 Azure 应用服务上启用托管标识
可以通过导航到“标识”并在 Azure 门户中为每个资源启用系统分配的托管标识,来为 Azure OpenAI 资源和 Azure 应用服务启用托管标识。

注意
如果使用一个部署到用于推理的资源的嵌入模型,则只需在一个 Azure OpenAI 资源上启用托管标识。 如果使用一个部署到的资源不同于用于推理的资源的嵌入模型,则还需要在用于部署嵌入模型的 Azure OpenAI 资源上启用托管标识。
在 Azure 搜索资源上启用基于角色的访问控制 (RBAC)(可选)
如果将 On Your Data 与 Azure 搜索结合使用,则应按照此步骤操作。
为了使 Azure OpenAI 资源能够访问 Azure 搜索资源,需要在 Azure 搜索资源上启用基于角色的访问控制。 详细了解如何为资源启用 RBAC 角色。
分配 RBAC 角色以启用服务内通信
下表汇总了与应用程序关联的所有 Azure 资源所需的 RBAC 角色分配。
| 角色 | 被分派人 | 资源 |
|---|---|---|
Search Index Data Reader |
Azure OpenAI(推理) | Azure AI 搜索 |
Search Service Contributor |
Azure OpenAI(推理) | Azure AI 搜索 |
Cognitive Services OpenAI User |
Web 应用 | Azure OpenAI(推理) |
Cognitive Services OpenAI User |
Azure OpenAI(推理) | Azure OpenAI(嵌入) |
若要分配这些角色,请按照这些说明创建所需的角色分配。
应用设置更改
在 webapp 应用程序设置中,导航到“环境变量”并进行以下更改:
- 删除环境变量
AZURE_OPENAI_KEY,因为不再需要它。 - 如果将 On Your Data 与 Azure 搜索结合使用,并在 Azure OpenAI 和 Azure 搜索之间使用 Microsoft Entra ID 身份验证,则还应删除数据源访问密钥的
AZURE_SEARCH_KEY环境变量。
如果使用的嵌入模型部署到模型用于推理的资源,则无需进行其他设置更改。
但是,如果使用的嵌入模型部署到其他资源,请对应用的环境变量进行以下额外更改:
- 将
AZURE_OPENAI_EMBEDDING_ENDPOINT变量设置为用于嵌入的资源的嵌入 API 的完整 API 路径,例如https://<your Azure OpenAI Service resource name>.openai.azure.com/openai/deployments/<your embedding deployment name>/embeddings - 删除
AZURE_OPENAI_EMBEDDING_KEY变量以使用 Microsoft Entra ID 身份验证。
完成所有环境变量更改后,重启 webapp 以开始在 webapp 中的服务之间使用 Microsoft Entra ID 身份验证。 重启后,任何设置更改都需要几分钟才能生效。