你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure OpenAI 存储的补全和蒸馏(预览版)
存储的补全使你可以从聊天补全会话中捕获会话历史记录,用作评估和微调的数据集。
存储的补全支持
API 支持
支持首先添加到 2024-10-01-preview
模型和区域可用性
| 区域 | o1-preview,2024-09-12 | o1-mini,2024-09-12 | gpt-4o,2024-08-06 | gpt-4o,2024-05-13 | gpt-4o-mini,2024-07-18 |
|---|---|---|---|---|---|
| 瑞典中部 | ✅ | ✅ | ✅ | ✅ | ✅ |
| 美国中北部 | - | - | ✅ | - | - |
| 美国东部 2 | - | - | ✅ | - | - |
配置存储的补全
若要为 Azure OpenAI 部署启用存储的补全,请将 store 参数设置为 True。 使用 metadata 参数通过其他信息来丰富存储的补全数据集。
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-01-preview"
)
completion = client.chat.completions.create(
model="gpt-4o", # replace with model deployment name
store= True,
metadata = {
"user": "admin",
"category": "docs-test",
},
messages=[
{"role": "system", "content": "Provide a clear and concise summary of the technical content, highlighting key concepts and their relationships. Focus on the main ideas and practical implications."},
{"role": "user", "content": "Ensemble methods combine multiple machine learning models to create a more robust and accurate predictor. Common techniques include bagging (training models on random subsets of data), boosting (sequentially training models to correct previous errors), and stacking (using a meta-model to combine base model predictions). Random Forests, a popular bagging method, create multiple decision trees using random feature subsets. Gradient Boosting builds trees sequentially, with each tree focusing on correcting the errors of previous trees. These methods often achieve better performance than single models by reducing overfitting and variance while capturing different aspects of the data."}
]
)
print(completion.choices[0].message)
为 Azure OpenAI 部署启用存储的补全后,它们将开始在 Azure AI Foundry 门户的“存储的补全”窗格中显示。

蒸馏
蒸馏使你可以将存储的补全转变为微调数据集。 常见的用例是将存储的补全与更强大的较大模型配合使用以完成特定任务,然后使用存储的补全以模型交互的高质量示例来训练较小的模型。
蒸馏至少需要 10 个存储的补全,但建议提供数百到数千个存储的补全,以获得最佳结果。
在 Azure AI Foundry 门户的“存储的补全”窗格中,使用“筛选器”选项来选择训练模型所要使用的补全。
若要开始蒸馏,请选择“蒸馏”
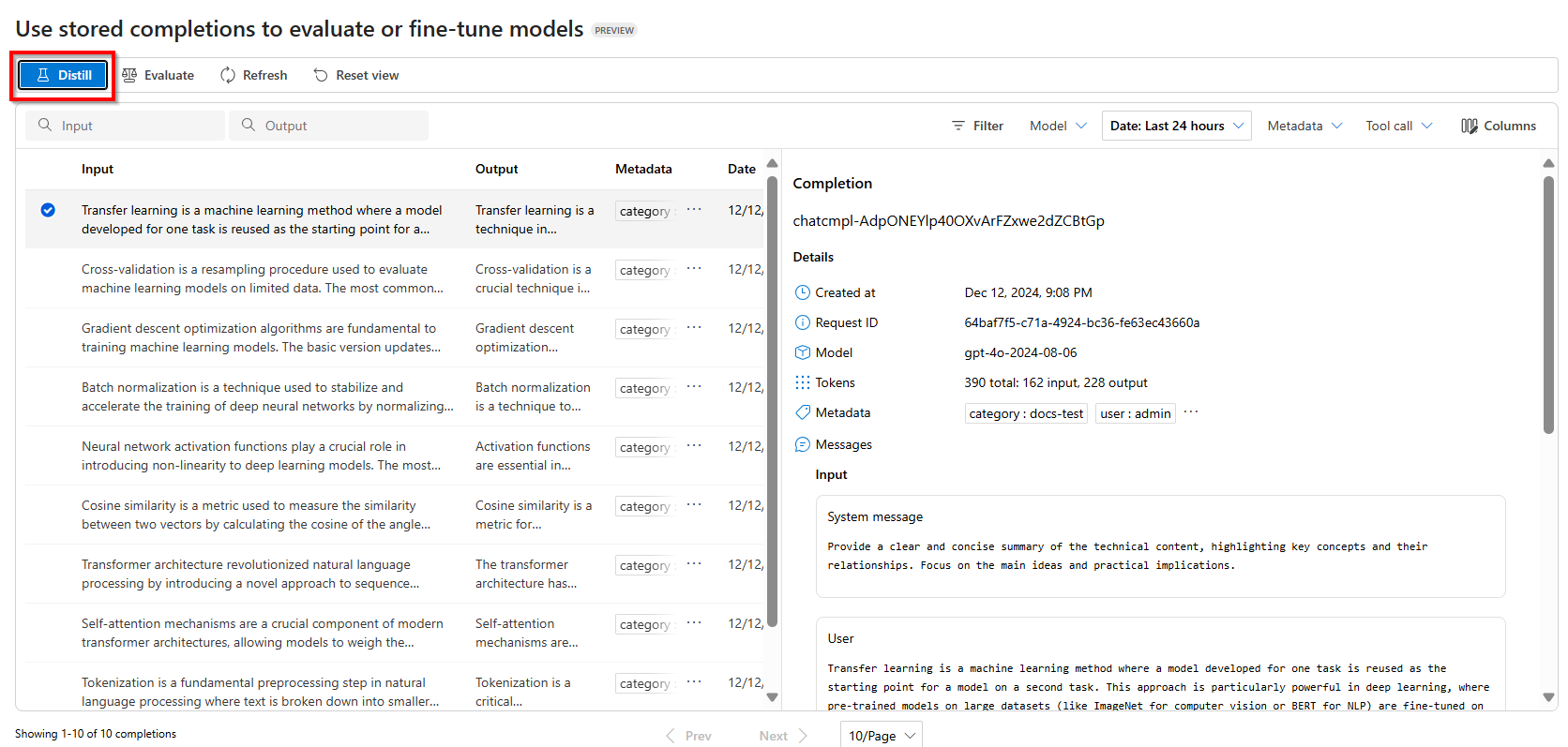
选择要使用存储的补全数据集微调的模型。
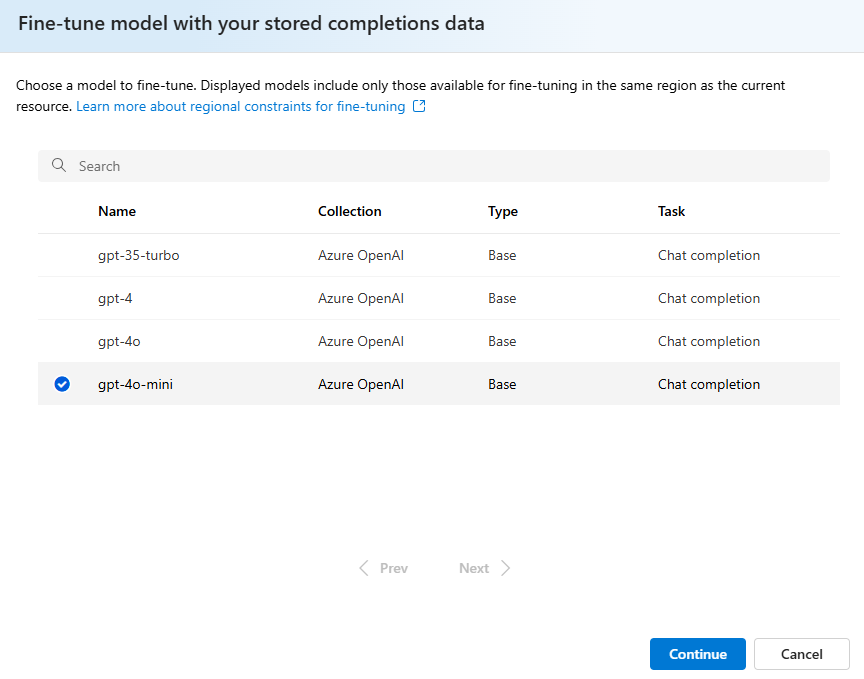
确认要微调的模型版本:
将根据存储的补全创建一个
.jsonl文件作为训练数据集,该文件的名称随机生成。 选择该文件 >“下一步”。注意
存储的补全蒸馏训练文件无法直接访问,也无法从外部导出/下载。
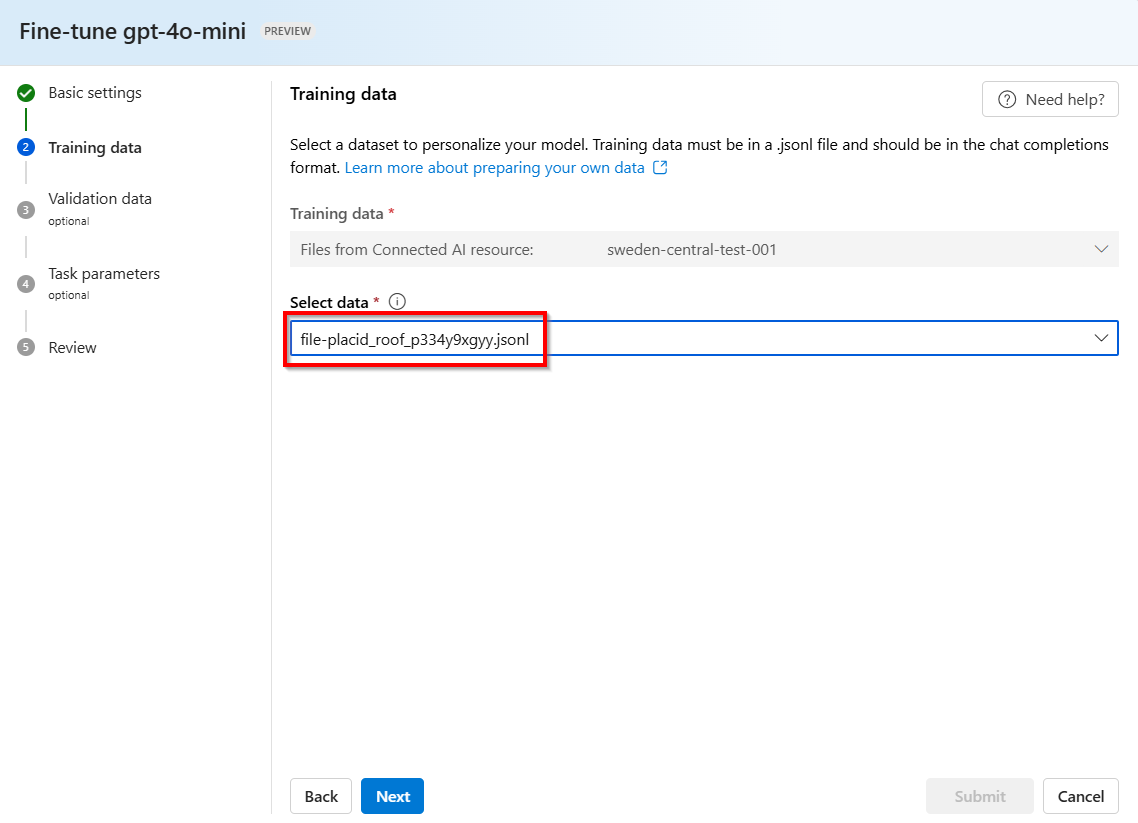




其余步骤与典型的 Azure OpenAI 微调步骤一致。 若要了解详细信息,请参阅我们的微调入门指南。
计算
大语言模型的评估是衡量这些模型在不同任务和维度上的性能的关键步骤。 这对于微调的模型尤其重要,评估训练的性能提升(或损失)对于这类模型至关重要。 全面的评估有助于了解模型的不同版本如何影响应用程序或方案。
存储的补全可作为数据集用于运行评估。
在 Azure AI Foundry 门户的“存储的补全”窗格中,使用“筛选器”选项来选择要加入评估数据集的补全。
若要配置评估,请选择“评估”
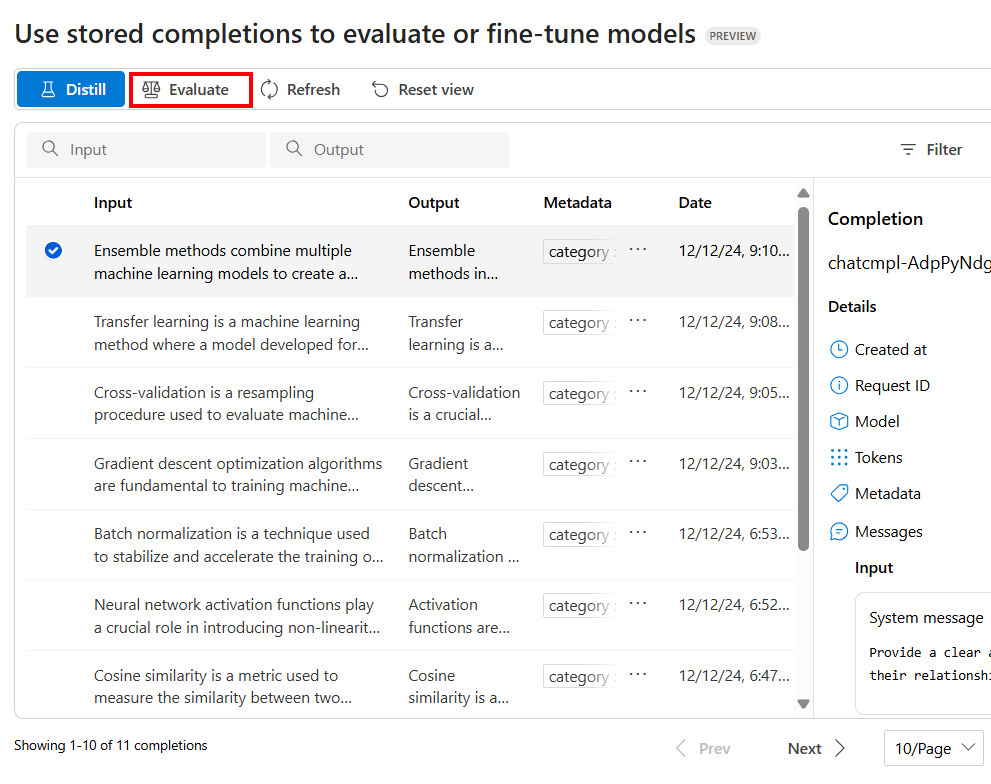
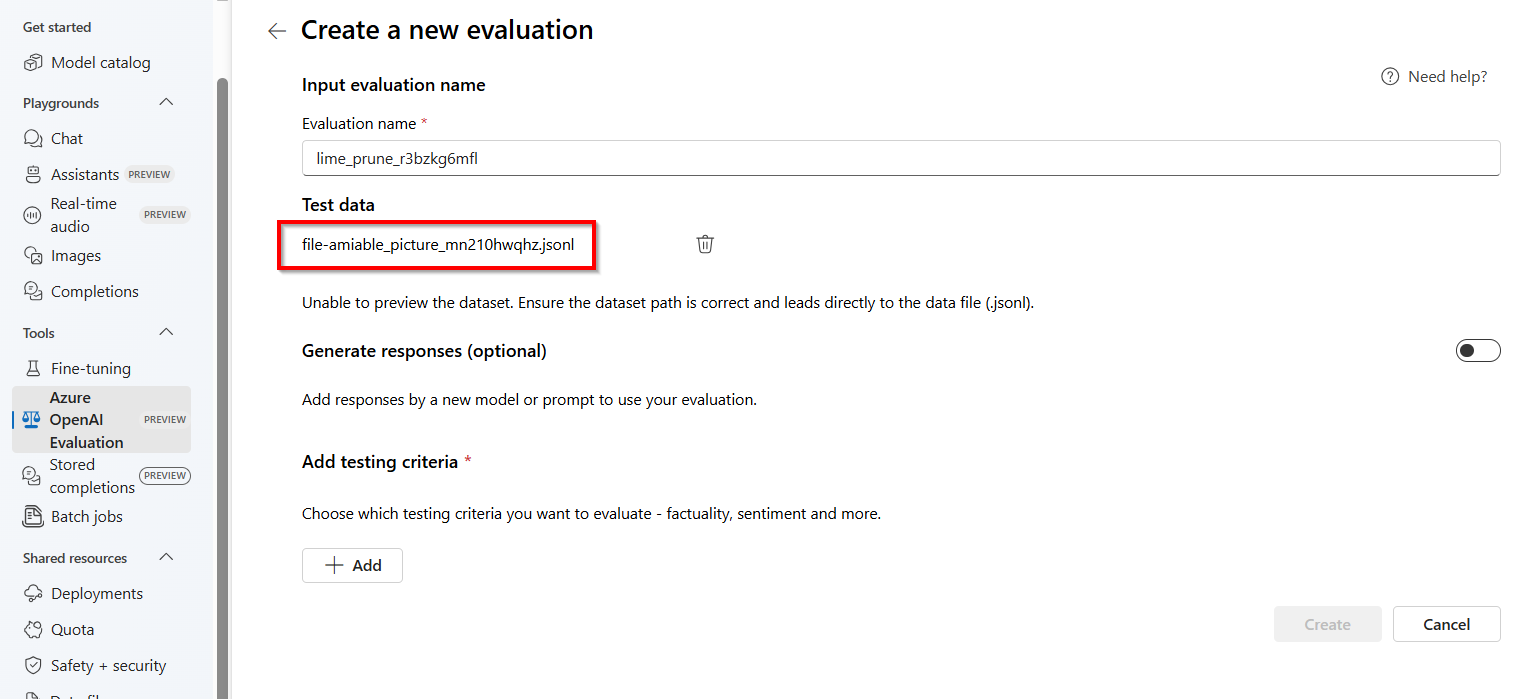
这会启动“评估”窗格,其中包含一个预填充的
.jsonl文件,文件名称随机生成,且该文件是根据存储的补全创建的,以用作评估数据集。注意
存储的补全评估数据文件无法直接访问,也无法从外部导出/下载。


若要了解有关评估的详细信息,请参阅评估入门
故障排除
是否需要特殊权限才能使用存储的补全?
存储的补全访问权限通过两个 DataAction 进行控制:
Microsoft.CognitiveServices/accounts/OpenAI/stored-completions/readMicrosoft.CognitiveServices/accounts/OpenAI/stored-completions/action
默认情况下,Cognitive Services OpenAI Contributor 可以获取这两个权限:

如何删除存储的数据?
通过删除关联的 Azure OpenAI 资源可以删除数据。 如果只想删除存储的补全数据,则必须向客户支持部门提出案例。
可以存储多少存储的补全数据?
最多可以存储 10 GB 的数据。
是否可以阻止在订阅上启用存储的补全?
需要向客户支持部门提出案例,才能在订阅级别禁用存储的补全。
TypeError:Completions.create() 获得了意外的参数“store”
运行较旧版本的 OpenAI 客户端库时,将发生此错误,该库早于发布的存储的补全功能。 运行 pip install openai --upgrade。