你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
开始使用 Azure OpenAI 全局批处理部署
Azure OpenAI Batch API 设计用于高效处理大规模和大容量处理任务。 处理具有单独配额的异步请求组,目标周转时间为 24 小时,成本比全局标准低 50%。 使用批处理,你可以在单个文件中发送大量请求,而不是一次发送一个请求。 全局批处理请求具有单独的入队令牌配额,避免对你的在线工作负载造成任何中断。
关键用例包括:
大规模数据处理:并行快速分析广泛的数据集。
内容生成:创建大量文本,例如产品说明或文章。
文档审查和总结:自动执行对长篇文档的审查和总结。
客户支持自动化:同时处理大量查询,以提高响应速度。
数据提取和分析:从大量非结构化数据中提取和分析信息。
自然语言处理 (NLP) 任务:对大型数据集执行情绪分析或翻译等任务。
营销和个性化:大规模生成个性化内容和建议。
重要
我们的目标是在 24 小时内处理批量请求;我们不会让需要更长时间的作业过期。 你随时可以取消作业。 当你取消作业时,将取消任何剩余的工作,并返回任何已完成的工作。 你需要为任何已完成的工作付费。
静态存储的数据仍保留在指定的 Azure 地理位置中,而数据可能会被处理,以便在任何 Azure OpenAI 位置进行推理。 详细了解数据驻留。
全局批处理支持
区域和模型支持
目前以下区域支持全局批处理:
| 区域 | gpt-4o,2024-05-13 | gpt-4o,2024-08-06 | gpt-4o-mini,2024-07-18 | gpt-4,0613 | gpt-4,turbo-2024-04-09 | gpt-35-turbo,0613 | gpt-35-turbo,1106 | gpt-35-turbo,0125 |
|---|---|---|---|---|---|---|---|---|
| australiaeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 巴西南部 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| canadaeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| eastus2 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| francecentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| germanywestcentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 日本东部 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| koreacentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| northcentralus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| norwayeast | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| polandcentral | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southafricanorth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southcentralus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| southindia | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 瑞典中部 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 瑞士北部 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| uksouth | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westeurope | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| westus3 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
以下模型支持全局批处理:
| 模型 | 版本 | 输入格式 |
|---|---|---|
gpt-4o |
2024-08-06 | 文本 + 图像 |
gpt-4o-mini |
2024-07-18 | 文本 + 图像 |
gpt-4o |
2024-05-13 | 文本 + 图像 |
gpt-4 |
turbo-2024-04-09 | text |
gpt-4 |
0613 | text |
gpt-35-turbo |
0125 | text |
gpt-35-turbo |
1106 | text |
gpt-35-turbo |
0613 | text |
有关目前支持全局批处理的区域/模型的最新信息,请参阅模型页。
API 支持
| API 版本 | |
|---|---|
| 最新 GA API 版本: | 2024-10-21 |
| 最新预览版 API 版本: | 2024-10-01-preview |
支持首先添加到:2024-07-01-preview
功能支持
当前不支持以下项:
- 与 Assistants API 集成。
- 与“基于自有数据的 Azure OpenAI”功能集成
注意
全局批处理现已支持结构化输出。
全局批处理部署
在 Azure AI Foundry 门户中,部署类型将显示为 Global-Batch。

提示
建议为所有全局批处理模型部署启用动态配额,以帮助避免作业由于排队令牌配额不足而失败。 开启动态配额后,部署可在有额外容量时适时利用更多配额。 动态配额设为关闭时,部署能够处理的请求数最多达到在创建部署时定义的排队令牌上限。
先决条件
- Azure 订阅 - 免费创建订阅。
- 一个部署了部署类型为
Global-Batch的模型的 Azure OpenAI 资源。 有关此过程的帮助信息,可以参阅资源创建和模型部署指南。
准备批处理文件
与优化一样,全局批处理使用 JSON 行 (.jsonl) 格式的文件。 下面是一些包含不同类型的受支持内容的示例文件:
输入格式
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id 是必需的,用于识别哪个单独的批处理请求对应于给定的响应。 响应将不会按照 .jsonl 批处理文件中定义的顺序返回。
应将 model 属性设置为与你希望用作推理响应目标的全局批处理部署的名称相匹配。
重要
model 属性必须设置为与你希望用作推理响应目标的全局批处理部署的名称相匹配。 批处理文件的每一行上都必须存在相同的全局批处理模型部署名称。如果要以其他部署为目标,则必须在单独的批处理文件/作业中执行此操作。
为了获得最佳性能,建议提交大型文件进行批处理,而不是提交大量每个文件中只有几行内容小型文件。
创建输入文件
在本文中,我们将创建一个名为 test.jsonl 的文件,并将上面的标准输入代码块中的内容复制到该文件。 你需要修改该文件并将你的全局批处理部署名称添加到该文件的每一行。
上传批处理文件
准备好你的输入文件后,首先需要上传该文件,然后才能启动批处理作业。 文件上传可以通过编程方式或通过 Studio 完成。
登录到 Azure AI Foundry 门户。
选择其中有全局批处理模型部署可用的 Azure OpenAI 资源。
选择“Batch 作业”>“+创建批处理作业”。
从“批处理数据”>“上传文件”下的下拉列表中 > 选择“上传文件”,并提供在上一步骤中创建的
test.jsonl文件的路径 > 单击“下一步”。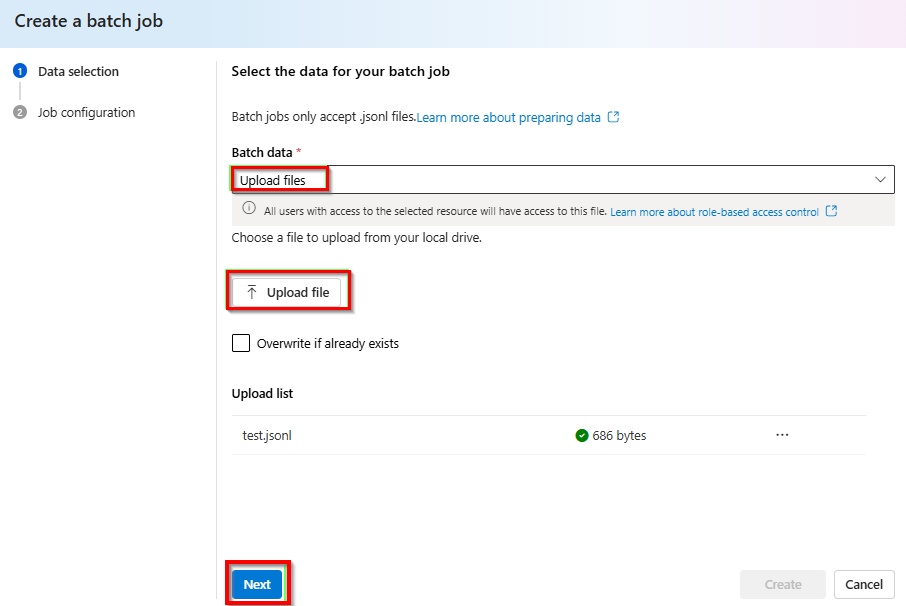


创建批处理作业
选择“创建”以启动你的批处理作业。

跟踪批处理作业进度
创建作业后,可以通过选择最近创建的作业的作业 ID 来监视作业的进度。 默认情况下,系统会将你带到最近创建的批处理作业的状态页。

可以在右侧窗格中跟踪作业的作业状态:

检索批处理作业输出文件
作业完成后或达到终端状态后,它将生成一个错误文件和一个输出文件,该文件可通过选择带有向下箭头图标的相应按钮进行审阅。

取消批处理
取消正在进行的批处理。 批处理将处于 cancelling 状态最长达 10 分钟,然后变为 cancelled 状态,在这种状态下,输出文件中将有部分结果可用(如果有)。

先决条件
- Azure 订阅 - 免费创建订阅。
- Python 3.8 或更高版本
- 以下 Python 库:
openai - Jupyter Notebook
- 一个部署了部署类型为
Global-Batch的模型的 Azure OpenAI 资源。 有关此过程的帮助信息,可以参阅资源创建和模型部署指南。
本文中的步骤计划在 Jupyter Notebook 中按顺序运行。 因此,我们将只在示例开头将 Azure OpenAI 客户端实例化一次。 如果你想无序运行某个步骤,你通常需要将 Azure OpenAI 客户端设置为该调用的一部分。
即使已安装 OpenAI Python 库,也可能需要将你的安装升级到最新版本:
!pip install openai --upgrade
准备批处理文件
与优化一样,全局批处理使用 JSON 行 (.jsonl) 格式的文件。 下面是一些包含不同类型的受支持内容的示例文件:
输入格式
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id 是必需的,用于识别哪个单独的批处理请求对应于给定的响应。 响应将不会按照 .jsonl 批处理文件中定义的顺序返回。
应将 model 属性设置为与你希望用作推理响应目标的全局批处理部署的名称相匹配。
重要
model 属性必须设置为与你希望用作推理响应目标的全局批处理部署的名称相匹配。 批处理文件的每一行上都必须存在相同的全局批处理模型部署名称。如果要以其他部署为目标,则必须在单独的批处理文件/作业中执行此操作。
为了获得最佳性能,建议提交大型文件进行批处理,而不是提交大量每个文件中只有几行内容小型文件。
创建输入文件
在本文中,我们将创建一个名为 test.jsonl 的文件,并将上面的标准输入代码块中的内容复制到该文件。 你需要修改该文件并将你的全局批处理部署名称添加到该文件的每一行。 将此文件保存到你在其中执行 Jupyter Notebook 的同一目录中。
上传批处理文件
准备好你的输入文件后,首先需要上传该文件,然后才能启动批处理作业。 文件上传可以通过编程方式或通过 Studio 完成。 此示例使用环境变量代替密钥值和终结点值。 如果你不熟悉通过 Python 使用环境变量,请参阅我们的快速入门之一,其中详细解释了设置环境变量的过程。
import os
from openai import AzureOpenAI
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
token_provider = get_bearer_token_provider(
DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default"
)
client = AzureOpenAI(
azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT"),
azure_ad_token_provider=token_provider,
api_version="2024-10-21"
)
# Upload a file with a purpose of "batch"
file = client.files.create(
file=open("test.jsonl", "rb"),
purpose="batch"
)
print(file.model_dump_json(indent=2))
file_id = file.id
输出:
{
"id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"bytes": 815,
"created_at": 1722476551,
"filename": "test.jsonl",
"object": "file",
"purpose": "batch",
"status": null,
"status_details": null
}
创建批处理作业
成功上传文件后,可以提交文件进行批处理。
# Submit a batch job with the file
batch_response = client.batches.create(
input_file_id=file_id,
endpoint="/chat/completions",
completion_window="24h",
)
# Save batch ID for later use
batch_id = batch_response.id
print(batch_response.model_dump_json(indent=2))
注意
目前,完成窗口必须设置为 24 小时。 如果设置为 24 小时以外的任何其他值,作业将失败。 花费时间超过 24 小时的作业将继续执行,直到被取消。
输出:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "validating",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"error_file_id": null,
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": null,
"in_progress_at": null,
"metadata": null,
"output_file_id": null,
"request_counts": {
"completed": 0,
"failed": 0,
"total": 0
}
}
跟踪批处理作业进度
成功创建批处理作业后,可以在 Studio 中或以编程方式监视其进度。 检查批处理作业进度时,建议在每个状态调用之间等待至少 60 秒。
import time
import datetime
status = "validating"
while status not in ("completed", "failed", "canceled"):
time.sleep(60)
batch_response = client.batches.retrieve(batch_id)
status = batch_response.status
print(f"{datetime.datetime.now()} Batch Id: {batch_id}, Status: {status}")
if batch_response.status == "failed":
for error in batch_response.errors.data:
print(f"Error code {error.code} Message {error.message}")
输出:
2024-07-31 21:48:32.556488 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: validating
2024-07-31 21:49:39.221560 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:50:53.383138 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:52:07.274570 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: in_progress
2024-07-31 21:53:21.149501 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:54:34.572508 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:55:35.304713 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:56:36.531816 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: finalizing
2024-07-31 21:57:37.414105 Batch Id: batch_6caaf24d-54a5-46be-b1b7-518884fcbdde, Status: completed
以下状态值是可能的:
| 状态 | 描述 |
|---|---|
validating |
在批处理开始之前,正在验证输入文件。 |
failed |
输入文件未能通过验证过程。 |
in_progress |
输入文件已成功验证,批处理当前正在运行。 |
finalizing |
批处理已完成,正在准备结果。 |
completed |
批处理已完成,结果已准备就绪。 |
expired |
批处理没能在 24 小时时间窗口内完成。 |
cancelling |
批处理正被cancelled(可能需要长达 10 分钟才能生效)。 |
cancelled |
批处理已被cancelled。 |
若要检查作业状态详细信息,可以运行:
print(batch_response.model_dump_json(indent=2))
输出:
{
"id": "batch_6caaf24d-54a5-46be-b1b7-518884fcbdde",
"completion_window": "24h",
"created_at": 1722476583,
"endpoint": null,
"input_file_id": "file-9f3a81d899b4442f98b640e4bc3535dd",
"object": "batch",
"status": "completed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1722477429,
"error_file_id": "file-c795ae52-3ba7-417d-86ec-07eebca57d0b",
"errors": null,
"expired_at": null,
"expires_at": 1722562983,
"failed_at": null,
"finalizing_at": 1722477177,
"in_progress_at": null,
"metadata": null,
"output_file_id": "file-3304e310-3b39-4e34-9f1c-e1c1504b2b2a",
"request_counts": {
"completed": 3,
"failed": 0,
"total": 3
}
}
请注意,那里同时存在 error_file_id 和一个单独的 output_file_id。 使用 error_file_id 来帮助调试批处理作业发生的任何问题。
检索批处理作业输出文件
import json
output_file_id = batch_response.output_file_id
if not output_file_id:
output_file_id = batch_response.error_file_id
if output_file_id:
file_response = client.files.content(output_file_id)
raw_responses = file_response.text.strip().split('\n')
for raw_response in raw_responses:
json_response = json.loads(raw_response)
formatted_json = json.dumps(json_response, indent=2)
print(formatted_json)
输出:
为了简洁起见,我们将仅包括输出中的单个聊天完成响应。 如果你遵循本文中的步骤,你应该有三个类似于以下内容的响应:
{
"custom_id": "task-0",
"response": {
"body": {
"choices": [
{
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
},
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"message": {
"content": "Microsoft was founded on April 4, 1975, by Bill Gates and Paul Allen in Albuquerque, New Mexico.",
"role": "assistant"
}
}
],
"created": 1722477079,
"id": "chatcmpl-9rFGJ9dh08Tw9WRKqaEHwrkqRa4DJ",
"model": "gpt-4o-2024-05-13",
"object": "chat.completion",
"prompt_filter_results": [
{
"prompt_index": 0,
"content_filter_results": {
"hate": {
"filtered": false,
"severity": "safe"
},
"jailbreak": {
"filtered": false,
"detected": false
},
"self_harm": {
"filtered": false,
"severity": "safe"
},
"sexual": {
"filtered": false,
"severity": "safe"
},
"violence": {
"filtered": false,
"severity": "safe"
}
}
}
],
"system_fingerprint": "fp_a9bfe9d51d",
"usage": {
"completion_tokens": 24,
"prompt_tokens": 27,
"total_tokens": 51
}
},
"request_id": "660b7424-b648-4b67-addc-862ba067d442",
"status_code": 200
},
"error": null
}
其他批处理命令
取消批处理
取消正在进行的批处理。 批处理将处于 cancelling 状态最长达 10 分钟,然后变为 cancelled 状态,在这种状态下,输出文件中将有部分结果可用(如果有)。
client.batches.cancel("batch_abc123") # set to your batch_id for the job you want to cancel
列出批处理
列出特定 Azure OpenAI 资源的批处理作业。
client.batches.list()
Python 库中的列表方法会分页。
要列出所有作业,请执行以下操作:
all_jobs = []
# Automatically fetches more pages as needed.
for job in client.batches.list(
limit=20,
):
# Do something with job here
all_jobs.append(job)
print(all_jobs)
列出批处理(预览版)
使用 REST API 列出具有其他排序/筛选选项的所有批处理作业。
在下面的示例中,我们提供了 generate_time_filter 函数来方便构造筛选器。 如果不想使用此函数,该筛选器字符串的格式将如下所示:created_at gt 1728860560 and status eq 'Completed'。
import requests
import json
from datetime import datetime, timedelta
from azure.identity import DefaultAzureCredential
token_credential = DefaultAzureCredential()
token = token_credential.get_token('https://cognitiveservices.azure.com/.default')
endpoint = "https://{YOUR_RESOURCE_NAME}.openai.azure.com/"
api_version = "2024-10-01-preview"
url = f"{endpoint}openai/batches"
order = "created_at asc"
time_filter = lambda: generate_time_filter("past 8 hours")
# Additional filter examples:
#time_filter = lambda: generate_time_filter("past 1 day")
#time_filter = lambda: generate_time_filter("past 3 days", status="Completed")
def generate_time_filter(time_range, status=None):
now = datetime.now()
if 'day' in time_range:
days = int(time_range.split()[1])
start_time = now - timedelta(days=days)
elif 'hour' in time_range:
hours = int(time_range.split()[1])
start_time = now - timedelta(hours=hours)
else:
raise ValueError("Invalid time range format. Use 'past X day(s)' or 'past X hour(s)'")
start_timestamp = int(start_time.timestamp())
filter_string = f"created_at gt {start_timestamp}"
if status:
filter_string += f" and status eq '{status}'"
return filter_string
filter = time_filter()
headers = {'Authorization': 'Bearer ' + token.token}
params = {
"api-version": api_version,
"$filter": filter,
"$orderby": order
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
if response.status_code == 200:
print(json.dumps(json_data, indent=2))
else:
print(f"Request failed with status code: {response.status_code}")
print(response.text)
输出:
{
"data": [
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729011896,
"completion_window": "24h",
"created_at": 1729011128,
"error_file_id": "file-472c0626-4561-4327-9e4e-f41afbfb30e6",
"expired_at": null,
"expires_at": 1729097528,
"failed_at": null,
"finalizing_at": 1729011805,
"id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"in_progress_at": 1729011493,
"input_file_id": "file-f89384af0082485da43cb26b49dc25ce",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-62bebde8-e767-4cd3-a0a1-28b214dc8974",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
},
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1729016366,
"completion_window": "24h",
"created_at": 1729015829,
"error_file_id": "file-85ae1971-9957-4511-9eb4-4cc9f708b904",
"expired_at": null,
"expires_at": 1729102229,
"failed_at": null,
"finalizing_at": 1729016272,
"id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43",
"in_progress_at": 1729016126,
"input_file_id": "file-686746fcb6bc47f495250191ffa8a28e",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": "file-04399828-ae0b-4825-9b49-8976778918cb",
"request_counts": {
"total": 3,
"completed": 2,
"failed": 1
},
"status": "completed",
"endpoint": "/chat/completions"
}
],
"first_id": "batch_4ddc7b60-19a9-419b-8b93-b9a3274b33b5",
"has_more": false,
"last_id": "batch_6287485f-50fc-4efa-bcc5-b86690037f43"
}
先决条件
- Azure 订阅 - 免费创建订阅。
- 一个部署了部署类型为
Global-Batch的模型的 Azure OpenAI 资源。 有关此过程的帮助信息,可以参阅资源创建和模型部署指南。
准备批处理文件
与优化一样,全局批处理使用 JSON 行 (.jsonl) 格式的文件。 下面是一些包含不同类型的受支持内容的示例文件:
输入格式
{"custom_id": "task-0", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was Microsoft founded?"}]}}
{"custom_id": "task-1", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "When was the first XBOX released?"}]}}
{"custom_id": "task-2", "method": "POST", "url": "/chat/completions", "body": {"model": "REPLACE-WITH-MODEL-DEPLOYMENT-NAME", "messages": [{"role": "system", "content": "You are an AI assistant that helps people find information."}, {"role": "user", "content": "What is Altair Basic?"}]}}
custom_id 是必需的,用于识别哪个单独的批处理请求对应于给定的响应。 响应将不会按照 .jsonl 批处理文件中定义的顺序返回。
应将 model 属性设置为与你希望用作推理响应目标的全局批处理部署的名称相匹配。
重要
model 属性必须设置为与你希望用作推理响应目标的全局批处理部署的名称相匹配。 批处理文件的每一行上都必须存在相同的全局批处理模型部署名称。如果要以其他部署为目标,则必须在单独的批处理文件/作业中执行此操作。
为了获得最佳性能,建议提交大型文件进行批处理,而不是提交大量每个文件中只有几行内容小型文件。
创建输入文件
在本文中,我们将创建一个名为 test.jsonl 的文件,并将上面的标准输入代码块中的内容复制到该文件。 你需要修改该文件并将你的全局批处理部署名称添加到该文件的每一行。
上传批处理文件
准备好你的输入文件后,首先需要上传该文件,然后才能启动批处理作业。 文件上传可以通过编程方式或通过 Studio 完成。 此示例使用环境变量代替密钥值和终结点值。 如果你不熟悉通过 Python 使用环境变量,请参阅我们的快速入门之一,其中详细解释了设置环境变量的过程。
重要
如果使用 API 密钥,请将其安全地存储在某个其他位置,例如 Azure Key Vault 中。 请不要直接在代码中包含 API 密钥,并且切勿公开发布该密钥。
有关 Azure AI 服务安全性的详细信息,请参阅对 Azure AI 服务的请求进行身份验证。
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files?api-version=2024-10-21 \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=batch" \
-F "file=@C:\\batch\\test.jsonl;type=application/json"
上面的代码为你的 test.jsonl 文件假设了一个特定的文件路径。 请根据需要针对你的本地系统调整此文件路径。
输出:
{
"status": "pending",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
跟踪文件上传状态
可能需要一些时间才能完全完成上传和处理,具体取决于上传文件的大小。 若要检查文件上传状态,请运行:
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{file-id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
输出:
{
"status": "processed",
"bytes": 686,
"purpose": "batch",
"filename": "test.jsonl",
"id": "file-21006e70789246658b86a1fc205899a4",
"created_at": 1721408291,
"object": "file"
}
创建批处理作业
成功上传文件后,可以提交文件进行批处理。
curl -X POST https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"input_file_id": "file-abc123",
"endpoint": "/chat/completions",
"completion_window": "24h"
}'
注意
目前,完成窗口必须设置为 24 小时。 如果设置为 24 小时以外的任何其他值,作业将失败。 花费时间超过 24 小时的作业将继续执行,直到被取消。
输出:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:13:57.2491382+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:13:57.1918498+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_fe3f047a-de39-4068-9008-346795bfc1db",
"in_progress_at": null,
"input_file_id": "file-21006e70789246658b86a1fc205899a4",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
跟踪批处理作业进度
成功创建批处理作业后,可以在 Studio 中或以编程方式监视其进度。 检查批处理作业进度时,建议在每个状态调用之间等待至少 60 秒。
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
输出:
{
"cancelled_at": null,
"cancelling_at": null,
"completed_at": null,
"completion_window": "24h",
"created_at": "2024-07-19T17:33:29.1619286+00:00",
"error_file_id": null,
"expired_at": null,
"expires_at": "2024-07-20T17:33:29.1578141+00:00",
"failed_at": null,
"finalizing_at": null,
"id": "batch_e0a7ee28-82c4-46a2-a3a0-c13b3c4e390b",
"in_progress_at": null,
"input_file_id": "file-c55ec4e859d54738a313d767718a2ac5",
"errors": null,
"metadata": null,
"object": "batch",
"output_file_id": null,
"request_counts": {
"total": null,
"completed": null,
"failed": null
},
"status": "Validating"
}
以下状态值是可能的:
| 状态 | 描述 |
|---|---|
validating |
在批处理开始之前,正在验证输入文件。 |
failed |
输入文件未能通过验证过程。 |
in_progress |
输入文件已成功验证,批处理当前正在运行。 |
finalizing |
批处理已完成,正在准备结果。 |
completed |
批处理已完成,结果已准备就绪。 |
expired |
批处理没能在 24 小时时间窗口内完成。 |
cancelling |
批处理正被 cancelled(可能需要长达 10 分钟才能生效)。 |
cancelled |
批处理已被 cancelled。 |
检索批处理作业输出文件
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/files/{output_file_id}/content?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY" > batch_output.jsonl
其他批处理命令
取消批处理
取消正在进行的批处理。 批处理将处于 cancelling 状态最长达 10 分钟,然后变为 cancelled 状态,在这种状态下,输出文件中将有部分结果可用(如果有)。
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches/{batch_id}/cancel?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
列出批处理
列出给定 Azure OpenAI 资源的现有批处理作业。
curl https://YOUR_RESOURCE_NAME.openai.azure.com/openai/batches?api-version=2024-10-21 \
-H "api-key: $AZURE_OPENAI_API_KEY"
列表 API 调用会分页。 响应包含一个布尔值 has_more,用于指示何时有更多结果需要循环访问。
列出批处理(预览版)
使用 REST API 列出具有其他排序/筛选选项的所有批处理作业。
curl "YOUR_RESOURCE_NAME.openai.azure.com/batches?api-version=2024-10-01-preview&$filter=created_at%20gt%201728773533%20and%20created_at%20lt%201729032733%20and%20status%20eq%20'Completed'&$orderby=created_at%20asc" \
-H "api-key: $AZURE_OPENAI_API_KEY"
为了避免出现错误,可将 URL rejected: Malformed input to a URL function 空间替换为 %20。
全局批处理限制
| 限制名称 | 限制值 |
|---|---|
| 每个资源的最大文件数 | 500 |
| 最大输入文件大小 | 200 MB |
| 每个文件的最大请求数 | 100,000 |
全局批处理配额
该表展示了批处理配额限制。 全局批处理的配额值以入队令牌表示。 提交用于批处理的文件时,会计算文件中存在的令牌数。 在批处理作业达到终端状态之前,这些令牌将计入总入队令牌限制。
| 模型 | 企业协议 | 默认 | 基于信用卡的每月订阅 | MSDN 订阅 | 面向学生的 Azure 免费试用版 |
|---|---|---|---|---|---|
gpt-4o |
5 B | 200 M | 50 M | 90 K | 空值 |
gpt-4o-mini |
15 B | 1 B | 50 M | 90 K | 空值 |
gpt-4-turbo |
300 M | 80 M | 40 M | 90 K | 空值 |
gpt-4 |
150 M | 30 M | 5 M | 10 万 | 空值 |
gpt-35-turbo |
10 B | 1 B | 100 M | 2 M | 50 万 |
B = 十亿 | M = 百万 | K = 千
批处理对象
| properties | 类型 | 定义 |
|---|---|---|
id |
string | |
object |
string | batch |
endpoint |
string | 批处理使用的 API 终结点 |
errors |
object | |
input_file_id |
string | 批处理的输入文件的 ID |
completion_window |
string | 应在其中处理批处理的时间范围 |
status |
string | 批处理的当前状态。 可能的值:validating、failed、in_progress、finalizing、completed、expired、cancelling、cancelled。 |
output_file_id |
string | 包含成功执行的请求的输出的文件的 ID。 |
error_file_id |
string | 包含出错的请求的输出的文件的 ID。 |
created_at |
integer | 创建此批处理时的时间戳(采用 unix 纪元)。 |
in_progress_at |
integer | 此批处理启动处理时的时间戳(采用 unix 纪元)。 |
expires_at |
integer | 此批处理的到期时间戳(采用 unix 纪元)。 |
finalizing_at |
integer | 此批处理启动最终完成时的时间戳(采用 unix 纪元)。 |
completed_at |
integer | 此批处理启动最终完成时的时间戳(采用 unix 纪元)。 |
failed_at |
integer | 此批处理失败时的时间戳(采用 unix 纪元)。 |
expired_at |
integer | 此批处理的过期时间戳(采用 unix 纪元)。 |
cancelling_at |
integer | 此批处理启动 cancelling 时的时间戳(采用 unix 纪元)。 |
cancelled_at |
integer | 此批处理被 cancelled 时的时间戳(采用 unix 纪元)。 |
request_counts |
object | 对象结构:total 整数 批处理中的请求总数。 completed 整数 批处理中已成功完成的请求数。 failed 整数 批处理中已失败的请求数。 |
metadata |
map | 可以附加到批处理的一组键值对。 此属性可用于以结构化格式存储有关批处理的其他信息。 |
常见问题 (FAQ)
图像是否可以与批处理 API 一起使用?
此功能仅限于某些多模式模型。 目前只有 GPT-4o 支持将图像作为批处理请求的一部分。 可以通过图像 URL 或图像的 base64 编码表示形式提供图像作为输入。 GPT-4 Turbo 目前不支持对图像进行批处理。
是否可以将批处理 API 与优化的模型配合使用?
目前不支持。
是否可以将批处理 API 用于嵌入模型?
目前不支持。
内容筛选是否适用于全局批处理部署?
是的。 与其他部署类型类似,你可以创建内容筛选器并将其与全局批处理部署类型相关联。
我可以请求额外的配额吗?
是的,可以通过 Azure AI Foundry 门户中的配额页进行操作。 可以在配额和限制一文中找到默认配额分配。
如果 API 未在 24 小时内完成我的请求,会发生什么情况?
我们的目标是在 24 小时内处理这些请求;我们不会让需要更长时间的作业过期。 你随时可以取消作业。 当你取消作业时,将取消任何剩余的工作,并返回任何已完成的工作。 你将需要为任何已完成的工作付费。
我可以使用批处理对多少个请求进行排队?
你可以批处理的请求数量没有固定限制,不过,这将取决于你的入队令牌配额。 你的入队令牌配额包括一次可以排队的最大输入令牌数。
你的批处理请求完成后,批处理速率限制将重置,因为输入令牌已被清除。 该限制取决于队列中的全局请求数。 如果批处理 API 队列快速处理你的批处理,则批处理速率限制会更快地重置。
故障排除
当 status 为 Completed 时,作业成功。 成功的作业仍会生成一个 error_file_id,但它将与一个包含零字节的空文件相关联。
发生作业失败时,可在 errors 属性中找到有关失败的详细信息:
"value": [
{
"id": "batch_80f5ad38-e05b-49bf-b2d6-a799db8466da",
"completion_window": "24h",
"created_at": 1725419394,
"endpoint": "/chat/completions",
"input_file_id": "file-c2d9a7881c8a466285e6f76f6321a681",
"object": "batch",
"status": "failed",
"cancelled_at": null,
"cancelling_at": null,
"completed_at": 1725419955,
"error_file_id": "file-3b0f9beb-11ce-4796-bc31-d54e675f28fb",
"errors": {
"object": “list”,
"data": [
{
“code”: “empty_file”,
“message”: “The input file is empty. Please ensure that the batch contains at least one request.”
}
]
},
"expired_at": null,
"expires_at": 1725505794,
"failed_at": null,
"finalizing_at": 1725419710,
"in_progress_at": 1725419572,
"metadata": null,
"output_file_id": "file-ef12af98-dbbc-4d27-8309-2df57feed572",
"request_counts": {
"total": 10,
"completed": null,
"failed": null
},
}
错误代码
| 错误代码 | 定义 |
|---|---|
invalid_json_line |
输入文件中的一行(或多行)无法解析为有效的 json。 请确保没有拼写错误,左括号和右括号正确,引号遵循了 JSON 标准,然后重新提交请求。 |
too_many_tasks |
输入文件中的请求数超出了允许的最大值 100,000。 请确保请求总数低于 100,000,并重新提交作业。 |
url_mismatch |
输入文件中某一行的 URL 与其余行不匹配,或者输入文件中指定的 URL 与预期的终结点 URL 不匹配。 请确保所有请求 URL 都相同,并且它们与 Azure OpenAI 部署的关联终结点 URL 匹配。 |
model_not_found |
找不到在输入文件的 model 属性中指定的 Azure OpenAI 模型部署名称。请确保此名称指向有效的 Azure OpenAI 模型部署。 |
duplicate_custom_id |
此请求的自定义 ID 与另一个请求中的自定义 ID 重复。 |
empty_batch |
请检查输入文件,确保自定义 ID 参数对于批处理中的每个请求都是唯一的。 |
model_mismatch |
输入文件中此请求的 model 属性中指定的 Azure OpenAI 模型部署名称与该文件的其余部分不匹配。请确保批处理中的所有请求都指向请求的 model 属性中的同一 Azure OpenAI 服务模型部署。 |
invalid_request |
输入行的架构无效或部署 SKU 无效。 请确保输入文件中请求的属性与预期的输入属性匹配,并且 Azure OpenAI 部署 SKU 对于批处理 API 请求 globalbatch。 |
已知问题
- 使用 Azure CLI 部署的资源不能直接用于 Azure OpenAI 全局批处理。 这是因为使用此方法部署的资源具有不遵循
https://your-resource-name.openai.azure.com模式的终结点子域。 解决此问题的方法是使用其他常见部署方法之一部署新的 Azure OpenAI 资源,该方法在部署过程中将会正确处理子域设置。