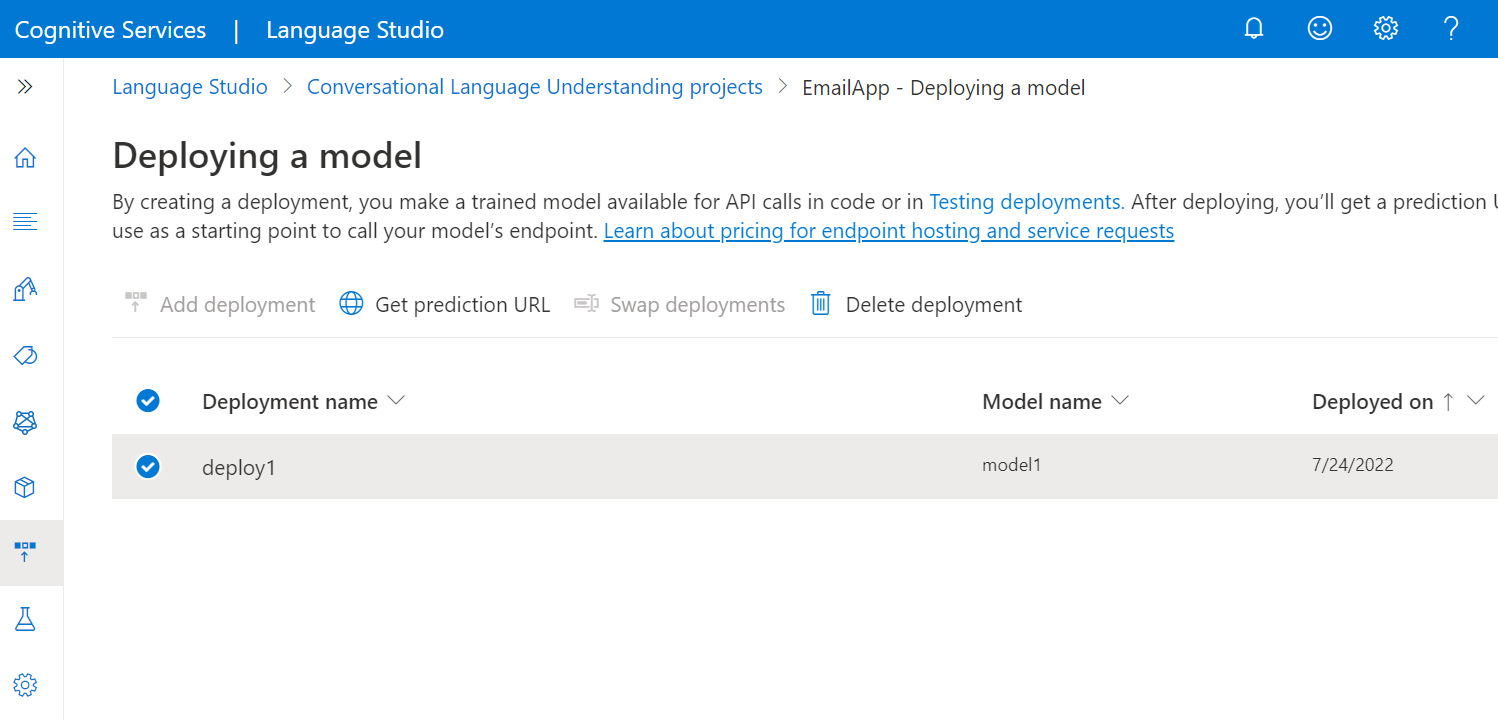
首先需要获取资源密钥和终结点:
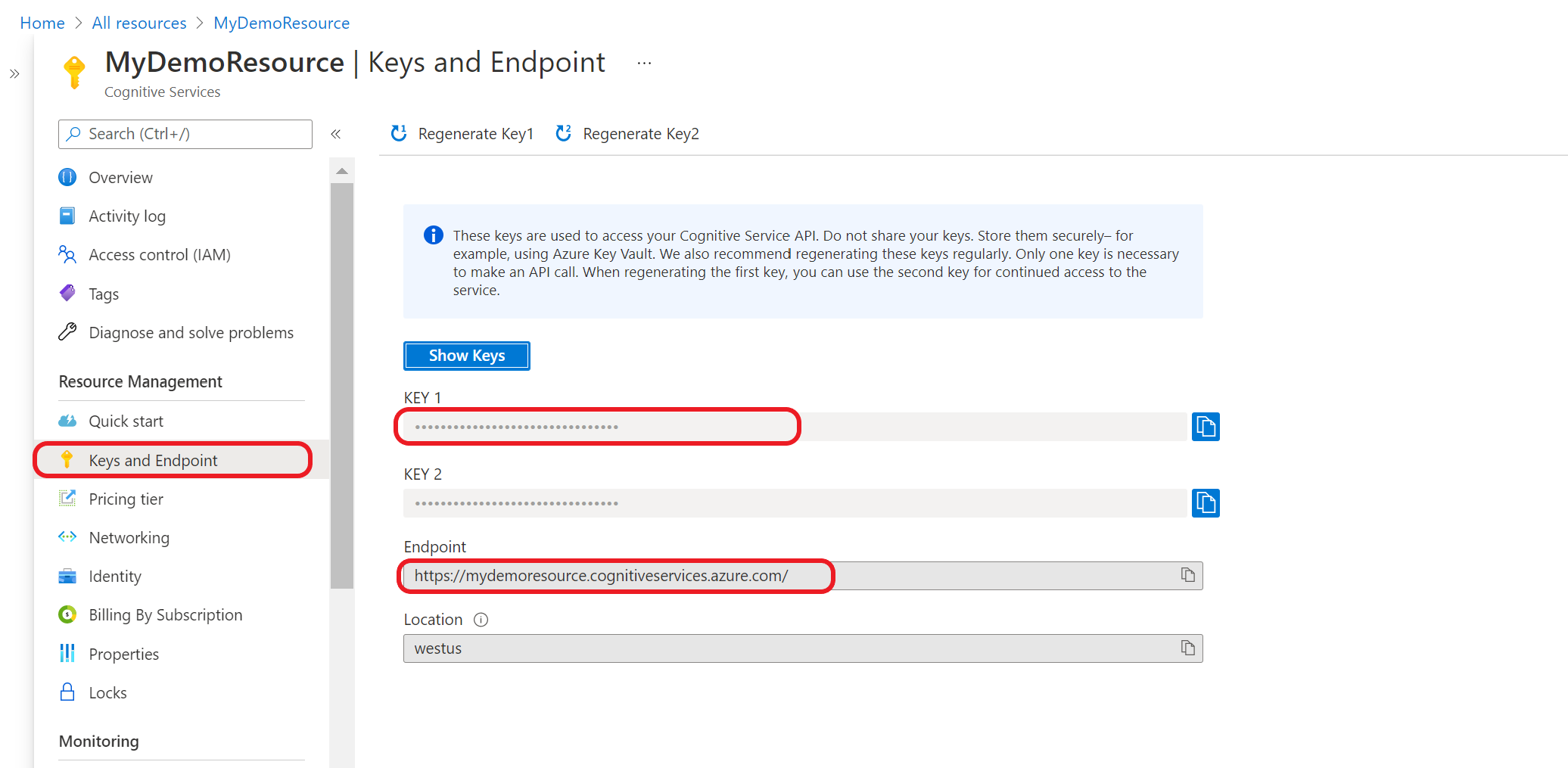
在 Azure 门户中,转到资源概述页面。 在左侧菜单中,选择“密钥和终结点”。 你将为 API 请求使用终结点和密钥
查询你的模型
使用以下 URL、标头和 JSON 正文创建 POST 请求,开始测试对话语言理解模型。
请求 URL
{ENDPOINT}/language/:analyze-conversations?api-version={API-VERSION}
| 占位符 |
值 |
示例 |
{ENDPOINT} |
用于对 API 请求进行身份验证的终结点。 |
https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
要调用的 API 的版本。 |
2023-04-01 |
使用以下标头对请求进行身份验证。
| 键 |
值 |
Ocp-Apim-Subscription-Key |
资源密钥。 用于对 API 请求进行身份验证。 |
请求正文
{
"kind": "Conversation",
"analysisInput": {
"conversationItem": {
"id": "1",
"participantId": "1",
"text": "Text 1"
}
},
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}",
"stringIndexType": "TextElement_V8"
}
}
| 密钥 |
占位符 |
值 |
示例 |
participantId |
{JOB-NAME} |
|
"MyJobName |
id |
{JOB-NAME} |
|
"MyJobName |
text |
{TEST-UTTERANCE} |
你要预测其意向并从中提取实体的语句。 |
"Read Matt's email |
projectName |
{PROJECT-NAME} |
项目名称。 此值区分大小写。 |
myProject |
deploymentName |
{DEPLOYMENT-NAME} |
部署的名称。 此值区分大小写。 |
staging |
发送请求后,你将获得有关预测的以下响应
响应正文
{
"kind": "ConversationResult",
"result": {
"query": "Text1",
"prediction": {
"topIntent": "inten1",
"projectKind": "Conversation",
"intents": [
{
"category": "intent1",
"confidenceScore": 1
},
{
"category": "intent2",
"confidenceScore": 0
},
{
"category": "intent3",
"confidenceScore": 0
}
],
"entities": [
{
"category": "entity1",
"text": "text1",
"offset": 29,
"length": 12,
"confidenceScore": 1
}
]
}
}
}
| 键 |
示例值 |
说明 |
| query |
"Read Matt's email" |
提交以供查询的文本。 |
| topIntent |
"Read" |
置信度分数最高的预测意向。 |
| 意向 |
[] |
针对查询文本所预测的所有意向的列表,每个意向有一个置信度分数。 |
| 实体 |
[] |
一个数组,包含从查询文本中提取的实体列表。 |
会话项目的 API 响应
在会话项目中,你将获得对项目中的意图和实体的预测。
- 意图和实体包括一个介于 0.0 到 1.0 之间的置信度分数,该分数与模型对于预测项目中某个元素的信心程度相关。
- 评分最高的意图包含在其自己的参数内。
- 只有预测的实体才会显示在响应中。
- 实体指示:
- 提取的实体的文本
- 用偏移值表示的开始位置
- 用长度值表示的实体文本的长度。