你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
文档智能读取模型
重要
- 使用文档智能选公共预览版,可以提前使用目前正处于开发状态的功能。 在正式发布 (GA) 之前,根据用户反馈,功能、方法和流程可能会发生更改。
- 文档智能客户端库的公共预览版默认使用 REST API 版本 2024-07-31-preview。
- 公共预览版 2024-07-31-preview 目前仅在以下 Azure 区域中可用。 请注意,AI Studio 中的自定义生成式(文档字段提取)模型仅适用于美国中北部区域:
- 美国东部
- 美国西部 2
- “西欧”
- 美国中北部
此内容适用于:![]() v4.0(预览版) | 先前版本:
v4.0(预览版) | 先前版本:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
此内容适用于:![]() v4.0(预览版) | 先前版本:
v4.0(预览版) | 先前版本:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
注意
若要从标签、路标和海报等外部图像中提取文本,请使用 Azure AI 图像分析 v4.0 的读取功能,此功能借助性能增强的同步 API 针对常规非文档图像进行了优化,可以更轻松地在用户体验方案中嵌入 OCR。
文档智能读取光学字符识别 (OCR) 模型采用高于 Azure AI 视觉读取的分辨率运行,并从 PDF 文档和扫描的图像中提取打印文本和手写文本。 它还支持从 Microsoft Word、Excel、PowerPoint 和 HTML 文档中提取文本。 它可检测段落、文本行、单词、位置和语言。 除自定义模型外,该读取模型也是其他文档智能预生成模型(例如布局、常规文档、发票、收据、身份 (ID) 证件、医疗保险卡、W2)的基础 OCR 引擎。
什么是光学字符识别?
适用于文档的光学字符识别 (OCR) 针对采用多种文件格式和全球语言的大型文本密集型文档进行了优化。 它包括许多功能,例如更高分辨率的文档图像扫描(更好地处理小型且密集的文本);段落检测;以及可填充的表单管理。 OCR 功能还包括一些高级方案,例如单个字符框、准确提取发票和收据中常见的关键字段以及其他预生成方案。
开发选项 (v4)
文档智能 v4.0 (2024-07-31-preview) 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| 读取 OCR 模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
输入要求 (v4)
支持的文件格式:
型号 PDF 图像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML读取 ✔ ✔ ✔ 布局 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview、2023-10-31-preview) 常规文档 ✔ ✔ 预生成 ✔ ✔ 自定义提取 ✔ ✔ 自定义分类 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview) 为获得最佳结果,请针对每个文档提供一张清晰的照片或高质量的扫描件。
对于 PDF 和 TIFF,最多可处理 2,000 页(对于免费层订阅,仅处理前两页)。
用于分析文档的文件大小对于付费 (S0) 层为 500 MB,对于免费 (F0) 层为
4MB。图像尺寸必须介于 50 像素 x 50 像素与 10,000 像素 x 10,000 像素之间。
如果 PDF 是密码锁定的文件,则必须先删除锁,然后才能提交它们。
对于 1024 x 768 像素的图像,要提取的文本的最小高度为 12 像素。 此尺寸对应于 150 点/英寸 (DPI) 的大约
8号字文本。对于自定义模型训练,自定义模板模型的训练数据最大页数为 500,自定义神经模型的训练数据最大页数为 50,000。
对于自定义提取模型训练,模板模型的训练数据总大小为 50 MB,神经网络模型的训练数据总大小为
1GB。对于自定义分类模型训练,训练数据总大小为
1GB,上限为 10,000 页。 对于 2024-07-31-preview 及更高版本,训练数据总大小为2GB,上限为 10,000 页。
读取模型入门 (v4)
尝试使用文档智能工作室从表单和文档中提取文本。 需要准备好以下资产:
注意
目前,文档智能工作室不支持 Microsoft Word、Excel、PowerPoint 和 HTML 文件格式。
使用文档智能工作室处理的示例文档
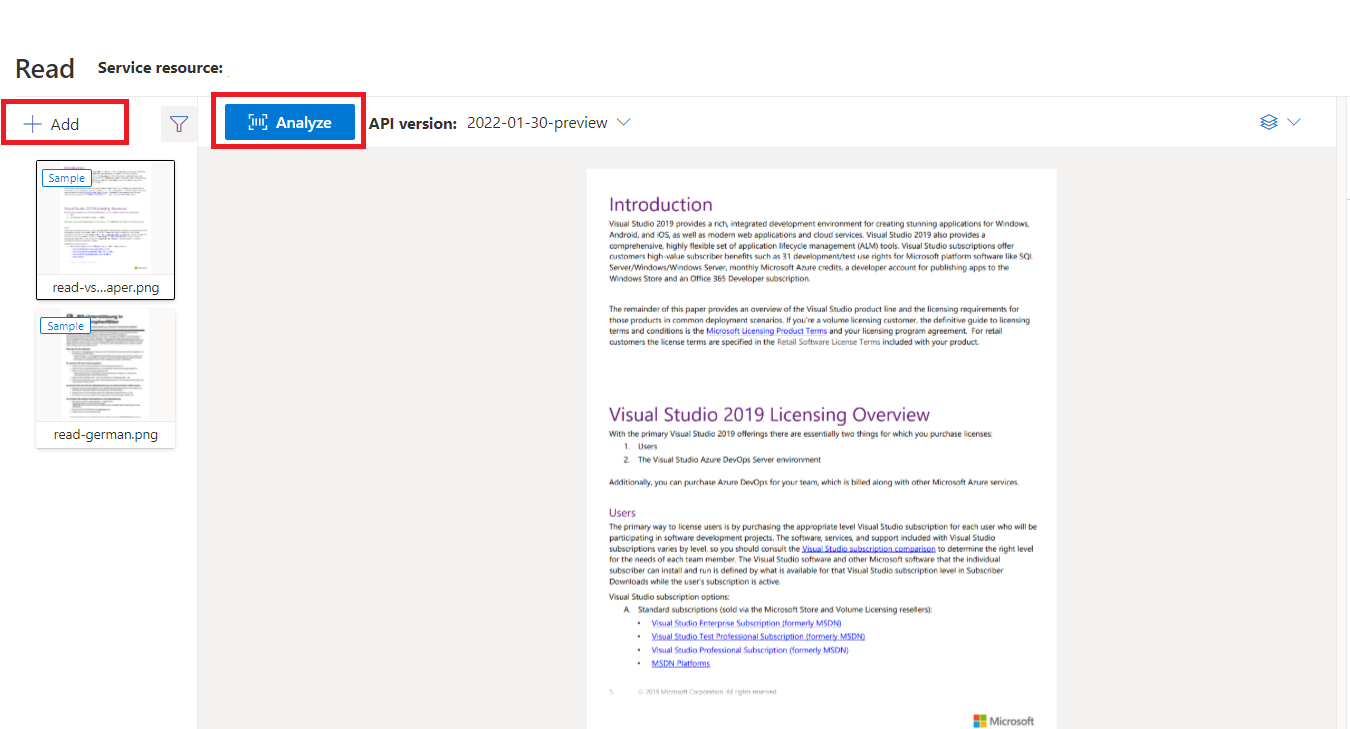
在文档智能工作室主页上,选择“读取”。
可以分析示例文档或上传自己的文件。
选择“运行分析”按钮,并根据需要配置“分析选项”:

支持的语言和区域设置 (v4)
如需支持的语言的完整列表,请参阅语言支持 - 文档分析模型页。
数据提取 (v4)
注意
v4.0 支持 Microsoft Word 和 HTML 文件。 与 PDF 和图像相比,不支持以下功能:
- 每个页面对象没有角度、宽度/高度和单位。
- 对于检测到的每个对象,没有边界多边形或边界区域。
- 页范围 (
pages) 不支持作为参数。 - 无
lines对象。
可搜索 PDF
借助可搜索的 PDF 功能,可以将模拟 PDF(如扫描图像 PDF 文件)转换为包含嵌入文本的 PDF。 嵌入文本通过在图像文件顶部覆盖检测到的文本实体,在 PDF 提取的内容中启用深度文本搜索。
重要
- 目前,可搜索 PDF 功能仅受读取 OCR 模型
prebuilt-read支持。 使用此功能时,请将modelId指定为prebuilt-read,因为其他模型类型将返回此预览版的错误。 - 可搜索 PDF 包含在 2024-07-31-preview
prebuilt-read模型中,用于生成可搜索的 PDF 输出,不收取额外费用。
使用可搜索 PDF
若要使用可搜索 PDF,请使用 Analyze 操作发出 POST 请求,并将输出格式指定为 pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
轮询 Analyze 操作的完成状态。 操作完成后,发出 GET 请求以检索 Analyze 操作结果的 PDF 格式。
成功完成后,可以检索 PDF 并将其下载为 application/pdf。 此操作允许直接下载 PDF 的嵌入文本形式,而不是 Base64 编码的 JSON。
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
页面数参数
页面集合是文档内页面的列表。 每个页面在文档中按顺序表示,并包括方向角度,表示页面是否旋转以及宽度和高度(以像素为单位)。 模型输出中的页面单位计算如下:
| 文件格式 | 计算页单位 | 全部页 |
|---|---|---|
| 图片(JPEG/JPG、PNG、BMP、HEIF) | 每个图像 = 1 个页面单位 | 图像总数 |
| PDF 中的每个页面 = 1 个页面单位 | PDF 中的总页数 | |
| TIFF | TIFF 中的每个图像 = 1 个页面单位 | TIFF 中的图像总数 |
| Word (DOCX) | 最多 3,000 个字符 = 1 个页面单位,不支持嵌入或链接的图像 | 每页最多 3,000 个字符的总页数 |
| Excel (XLSX) | 每个工作表 = 1 个页面单位,不支持嵌入或链接的图像 | 工作表总数 |
| PowerPoint (PPTX) | 每张幻灯片 = 1 个页面单位,不支持嵌入或链接的图像 | 幻灯片总数 |
| HTML | 最多 3,000 个字符 = 1 个页面单位,不支持嵌入或链接的图像 | 每页最多 3,000 个字符的总页数 |
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}")
使用页面进行文本提取
对于较大的多页 PDF 文档,请使用 pages 查询参数指示用于文本提取的特定页码或页面范围。
段落提取
文档智能中的读取 OCR 模型将 paragraphs 集合中所有识别出的文本块提取为 analyzeResults 下的顶级对象。 此集合中的每个条目都表示一个文本块,并包含提取的文本 (content) 和边界 polygon 坐标。 span 信息指向包含文档全文的顶级 content 属性中的文本片段。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
文本、行和字词提取
读取 OCR 模型将打印和手写样式的文本提取为 lines 和 words。 模型输出所提取单词的边界 polygon 坐标和 confidence。 styles 集合包含任何手写的行样式(如果检测到的话)以及指向关联文本的跨度。 此功能适用于受支持的手写语言。
对于 Microsoft Word、Excel、PowerPoint 和 HTML,文档智能读取模型 v3.1 及更高版本按原样提取所有嵌入文本。 文本被提取为字词和段落。 不支持嵌入图像。
# Analyze lines.
if page.lines:
for line_idx, line in enumerate(page.lines):
words = get_words(page, line)
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{line.polygon}'"
)
# Analyze words.
for word in words:
print(f"......Word '{word.content}' has a confidence of {word.confidence}")
手写样式提取
响应将分类说明每个文本行是否为手写体,同时包括置信度评分。 有关详细信息,请参阅手写语言支持。 以下示例显示了一个示例 JSON 片段。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
如果启用了字体/样式加载项功能,则还会获得作为 styles 对象的一部分的字体/样式结果。
后续步骤 v4.0
完成文档智能快速入门:
探索 REST API:
在 GitHub 上查找更多示例:
注意
若要从标签、路标和海报等外部图像中提取文本,请使用 Azure AI 图像分析 v4.0 的读取功能,此功能借助性能增强的同步 API 针对常规非文档图像进行了优化,可以更轻松地在用户体验方案中嵌入 OCR。
文档智能读取光学字符识别 (OCR) 模型采用高于 Azure AI 视觉读取的分辨率运行,并从 PDF 文档和扫描的图像中提取打印文本和手写文本。 它还支持从 Microsoft Word、Excel、PowerPoint 和 HTML 文档中提取文本。 它可检测段落、文本行、单词、位置和语言。 除自定义模型外,该读取模型也是其他文档智能预生成模型(例如布局、常规文档、发票、收据、身份 (ID) 证件、医疗保险卡、W2)的基础 OCR 引擎。
什么是适用于文档的 OCR?
适用于文档的光学字符识别 (OCR) 针对采用多种文件格式和全球语言的大型文本密集型文档进行了优化。 它包括许多功能,例如更高分辨率的文档图像扫描(更好地处理小型且密集的文本);段落检测;以及可填充的表单管理。 OCR 功能还包括一些高级方案,例如单个字符框、准确提取发票和收据中常见的关键字段以及其他预生成方案。
开发选项
文档智能 v3.1 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| 读取 OCR 模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
文档智能 v3.0 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| 读取 OCR 模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-read |
输入要求
支持的文件格式:
型号 PDF 图像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML读取 ✔ ✔ ✔ 布局 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview、2023-10-31-preview) 常规文档 ✔ ✔ 预生成 ✔ ✔ 自定义提取 ✔ ✔ 自定义分类 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview) 为获得最佳结果,请针对每个文档提供一张清晰的照片或高质量的扫描件。
对于 PDF 和 TIFF,最多可处理 2,000 页(对于免费层订阅,仅处理前两页)。
用于分析文档的文件大小对于付费 (S0) 层为 500 MB,对于免费 (F0) 层为
4MB。图像尺寸必须介于 50 像素 x 50 像素与 10,000 像素 x 10,000 像素之间。
如果 PDF 是密码锁定的文件,则必须先删除锁,然后才能提交它们。
对于 1024 x 768 像素的图像,要提取的文本的最小高度为 12 像素。 此尺寸对应于 150 点/英寸 (DPI) 的大约
8号字文本。对于自定义模型训练,自定义模板模型的训练数据最大页数为 500,自定义神经模型的训练数据最大页数为 50,000。
对于自定义提取模型训练,模板模型的训练数据总大小为 50 MB,神经网络模型的训练数据总大小为
1GB。对于自定义分类模型训练,训练数据总大小为
1GB,上限为 10,000 页。 对于 2024-07-31-preview 及更高版本,训练数据总大小为2GB,上限为 10,000 页。
读取模型入门
尝试使用文档智能工作室从表单和文档中提取文本。 需要准备好以下资产:
注意
目前,文档智能工作室不支持 Microsoft Word、Excel、PowerPoint 和 HTML 文件格式。
使用文档智能工作室处理的示例文档
在文档智能工作室主页上,选择“读取”。
可以分析示例文档或上传自己的文件。
选择“运行分析”按钮,并根据需要配置“分析选项”:
支持的语言和区域设置
如需支持的语言的完整列表,请参阅语言支持 - 文档分析模型页。
数据提取
注意
v3.1 及更高版本中支持 Microsoft Word 和 HTML 文件。 与 PDF 和图像相比,不支持以下功能:
- 每个页面对象没有角度、宽度/高度和单位。
- 对于检测到的每个对象,没有边界多边形或边界区域。
- 页范围 (
pages) 不支持作为参数。 - 无
lines对象。
可搜索 PDF
借助可搜索的 PDF 功能,可以将模拟 PDF(如扫描图像 PDF 文件)转换为包含嵌入文本的 PDF。 嵌入文本通过在图像文件顶部覆盖检测到的文本实体,在 PDF 提取的内容中启用深度文本搜索。
重要
- 目前,可搜索 PDF 功能仅受读取 OCR 模型
prebuilt-read支持。 使用此功能时,请将modelId指定为prebuilt-read,因为其他模型类型将返回此预览版的错误。 - 可搜索 PDF 包含在 2024-07-31-preview
prebuilt-read模型中,用于生成可搜索的 PDF 输出,不收取额外费用。- 可搜索 PDF 目前仅支持 PDF 文件作为输入。 以后将提供对其他文件类型(例如图像文件)的支持。
使用可搜索 PDF
若要使用可搜索 PDF,请使用 Analyze 操作发出 POST 请求,并将输出格式指定为 pdf:
POST /documentModels/prebuilt-read:analyze?output=pdf
{...}
202
轮询 Analyze 操作的完成状态。 操作完成后,发出 GET 请求以检索 Analyze 操作结果的 PDF 格式。
成功完成后,可以检索 PDF 并将其下载为 application/pdf。 此操作允许直接下载 PDF 的嵌入文本形式,而不是 Base64 编码的 JSON。
// Monitor the operation until completion.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}
200
{...}
// Upon successful completion, retrieve the PDF as application/pdf.
GET /documentModels/prebuilt-read/analyzeResults/{resultId}/pdf
200 OK
Content-Type: application/pdf
页
页面集合是文档内页面的列表。 每个页面在文档中按顺序表示,并包括方向角度,表示页面是否旋转以及宽度和高度(以像素为单位)。 模型输出中的页面单位计算如下:
| 文件格式 | 计算页单位 | 全部页 |
|---|---|---|
| 图片(JPEG/JPG、PNG、BMP、HEIF) | 每个图像 = 1 个页面单位 | 图像总数 |
| PDF 中的每个页面 = 1 个页面单位 | PDF 中的总页数 | |
| TIFF | TIFF 中的每个图像 = 1 个页面单位 | TIFF 中的图像总数 |
| Word (DOCX) | 最多 3,000 个字符 = 1 个页面单位,不支持嵌入或链接的图像 | 每页最多 3,000 个字符的总页数 |
| Excel (XLSX) | 每个工作表 = 1 个页面单位,不支持嵌入或链接的图像 | 工作表总数 |
| PowerPoint (PPTX) | 每张幻灯片 = 1 个页面单位,不支持嵌入或链接的图像 | 幻灯片总数 |
| HTML | 最多 3,000 个字符 = 1 个页面单位,不支持嵌入或链接的图像 | 每页最多 3,000 个字符的总页数 |
"pages": [
{
"pageNumber": 1,
"angle": 0,
"width": 915,
"height": 1190,
"unit": "pixel",
"words": [],
"lines": [],
"spans": []
}
]
# Analyze pages.
for page in result.pages:
print(f"----Analyzing document from page #{page.page_number}----")
print(
f"Page has width: {page.width} and height: {page.height}, measured with unit: {page.unit}"
)
选择页面以进行文本提取
对于较大的多页 PDF 文档,请使用 pages 查询参数指示用于文本提取的特定页码或页面范围。
段落
文档智能中的读取 OCR 模型将 paragraphs 集合中所有识别出的文本块提取为 analyzeResults 下的顶级对象。 此集合中的每个条目都表示一个文本块,并包含提取的文本 (content) 和边界 polygon 坐标。 span 信息指向包含文档全文的顶级 content 属性中的文本片段。
"paragraphs": [
{
"spans": [],
"boundingRegions": [],
"content": "While healthcare is still in the early stages of its Al journey, we are seeing pharmaceutical and other life sciences organizations making major investments in Al and related technologies.\" TOM LAWRY | National Director for Al, Health and Life Sciences | Microsoft"
}
]
文本、行、字词
读取 OCR 模型将打印和手写样式的文本提取为 lines 和 words。 模型输出所提取单词的边界 polygon 坐标和 confidence。 styles 集合包含任何手写的行样式(如果检测到的话)以及指向关联文本的跨度。 此功能适用于受支持的手写语言。
对于 Microsoft Word、Excel、PowerPoint 和 HTML,文档智能读取模型 v3.1 及更高版本按原样提取所有嵌入文本。 文本被提取为字词和段落。 不支持嵌入图像。
"words": [
{
"content": "While",
"polygon": [],
"confidence": 0.997,
"span": {}
},
],
"lines": [
{
"content": "While healthcare is still in the early stages of its Al journey, we",
"polygon": [],
"spans": [],
}
]
# Analyze lines.
for line_idx, line in enumerate(page.lines):
words = line.get_words()
print(
f"...Line # {line_idx} has {len(words)} words and text '{line.content}' within bounding polygon '{format_polygon(line.polygon)}'"
)
# Analyze words.
for word in words:
print(
f"......Word '{word.content}' has a confidence of {word.confidence}"
)
文本行的手写风格
响应将分类说明每个文本行是否为手写体,同时包括置信度评分。 有关详细信息,请参阅手写语言支持。 以下示例显示了一个示例 JSON 片段。
"styles": [
{
"confidence": 0.95,
"spans": [
{
"offset": 509,
"length": 24
}
"isHandwritten": true
]
}
如果启用了字体/样式加载项功能,则还会获得作为 styles 对象的一部分的字体/样式结果。
后续步骤
完成文档智能快速入门:
探索 REST API:
在 GitHub 上查找更多示例: