你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
文档智能 ID 文档模型
重要
- 使用文档智能选公共预览版,可以提前使用目前正处于开发状态的功能。 在正式发布 (GA) 之前,根据用户反馈,功能、方法和流程可能会发生更改。
- 文档智能客户端库的公共预览版默认使用 REST API 版本 2024-07-31-preview。
- 公共预览版 2024-07-31-preview 目前仅在以下 Azure 区域中可用。 请注意,AI Studio 中的自定义生成式(文档字段提取)模型仅适用于美国中北部区域:
- 美国东部
- 美国西部 2
- “西欧”
- 美国中北部
此内容适用于:![]() v2.1 | 最新版本:
v2.1 | 最新版本:![]() v4.0(预览版)
v4.0(预览版)
文档智能标识文档 (ID) 模型将光学字符识别 (OCR) 与深度学习模型相结合,可分析和提取标识文档中的关键信息。 该 API 分析身份证件(包括以下内容),并返回结构化 JSON 数据表示形式:
- 世界各地的护照簿、护照卡
- 美国、欧洲、印度、加拿大和澳大利亚的驾照
- 美国身份证、居住证(绿卡)、社会保障卡、军人身份证
- 欧洲身份证、居留证
- 印度 PAN 卡、Aadhaar 卡
- 加拿大身份证、居留证(枫叶卡)
- 澳大利亚带照片的身份证、钥匙通行证(包括电子版)
文档智能可以使用其预生成 ID 模型分析和提取政府颁发的标识文档 (ID) 中的信息。 它结合了强大的光学字符识别 (OCR) 功能与 ID 识别功能,可从全球护照和美国驾照(50 个州和华盛顿特区)中提取关键信息。 ID API 从这些标识文档中提取关键信息,如名字、姓氏、出生日期、文档编号等。 此 API 在文档智能 v2.1 中作为云服务提供。
身份证件处理
身份证件处理涉及手动提取或使用基于 OCR 的技术提取身份证件中的数据。 在任何需要证明身份的业务操作中,身份证件处理都是必不可缺的。 例如银行和其他金融机构中的客户验证、抵押贷款申请、就医、索赔处理、酒店入住等情况。 人们可以通过驾照、护照和其他类似的证件来证明自己的身份,以便企业在提供服务和福利之前有效地完成验证。
使用文档智能工作室处理的美国驾照示例
数据提取
预生成的 ID 服务将从全球护照和美国驾照中提取关键信息,并以组织有序的结构化 JSON 响应返回这些值。
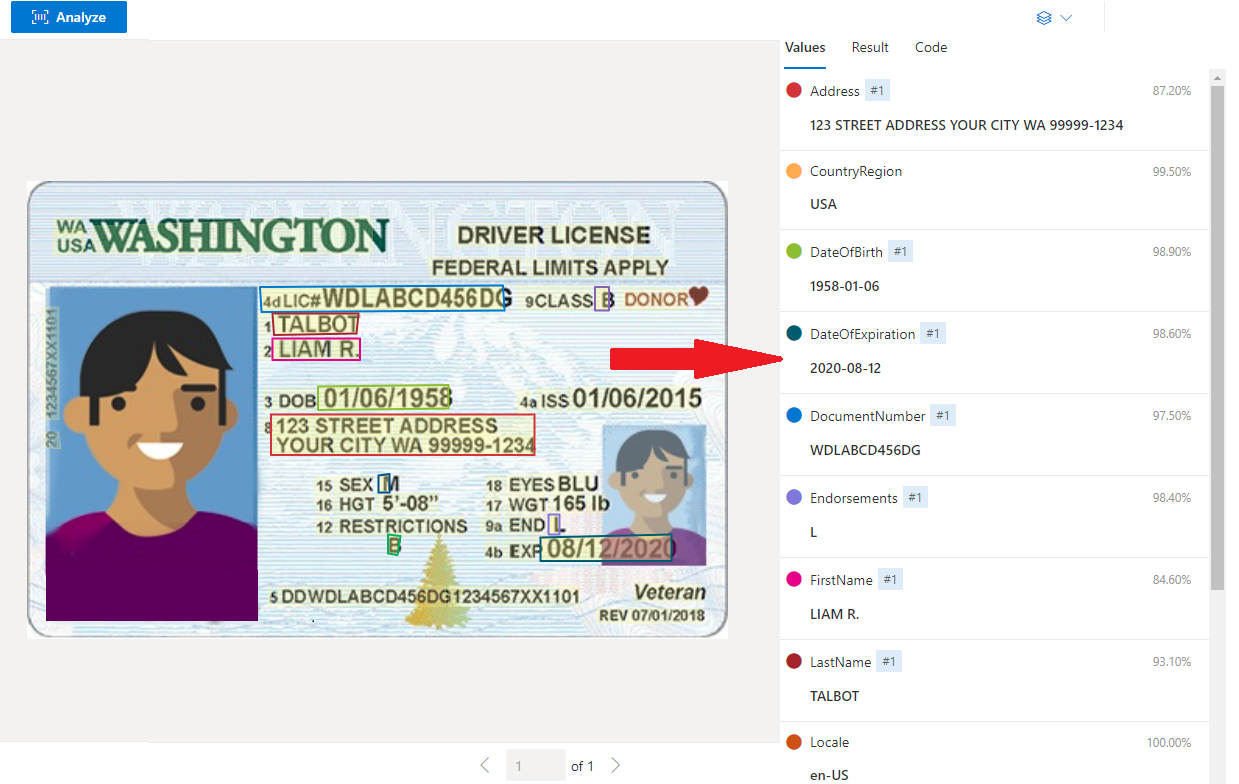
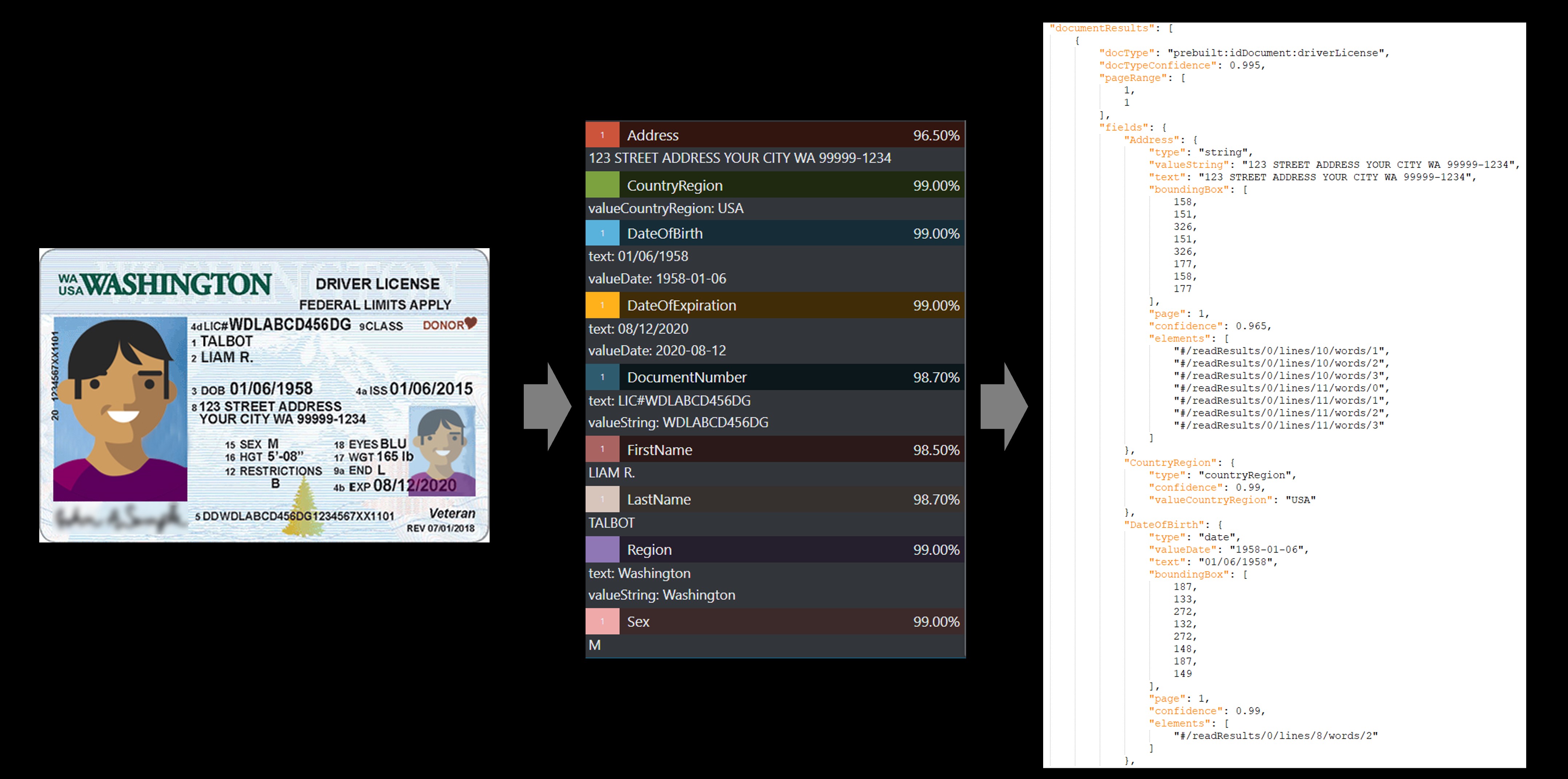
驾照示例
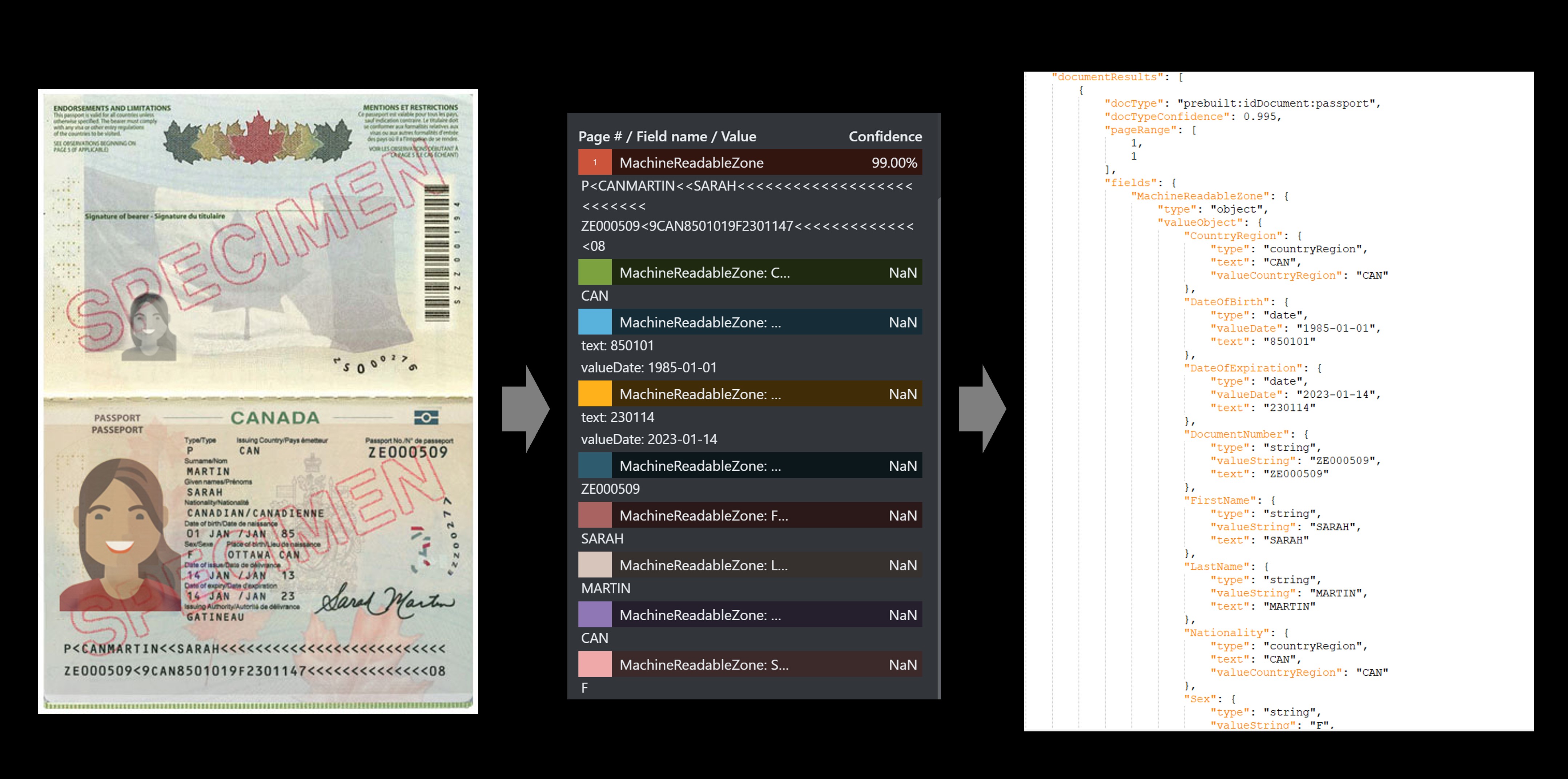
护照示例
开发选项
文档智能 v4.0 (2024-07-31-preview) 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| ID 文档模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
文档智能 v3.1 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| ID 文档模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
文档智能 v3.0 支持以下工具、应用程序和库:
| 功能 | 资源 | 模型 ID |
|---|---|---|
| ID 文档模型 | • 文档智能工作室 • REST API • C# SDK • Python SDK • Java SDK • JavaScript SDK |
prebuilt-idDocument |
文档智能 v2.1 支持以下工具、应用程序和库:
| 功能 | 资源 |
|---|---|
| ID 文档模型 | • 文档智能标记工具 • REST API • 客户端库 SDK • 文档智能 Docker 容器 |
输入要求
支持的文件格式:
型号 PDF 图像: JPEG/JPG、PNG、BMP、TIFF、HEIFMicrosoft Office:
Word (DOCX)、Excel (XLSX)、PowerPoint (PPTX)、HTML读取 ✔ ✔ ✔ 布局 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview、2023-10-31-preview) 常规文档 ✔ ✔ 预生成 ✔ ✔ 自定义提取 ✔ ✔ 自定义分类 ✔ ✔ ✔(2024-07-31-preview、2024-02-29-preview) 为获得最佳结果,请针对每个文档提供一张清晰的照片或高质量的扫描件。
对于 PDF 和 TIFF,最多可处理 2,000 页(对于免费层订阅,仅处理前两页)。
用于分析文档的文件大小对于付费 (S0) 层为 500 MB,对于免费 (F0) 层为
4MB。图像尺寸必须介于 50 像素 x 50 像素与 10,000 像素 x 10,000 像素之间。
如果 PDF 是密码锁定的文件,则必须先删除锁,然后才能提交它们。
对于 1024 x 768 像素的图像,要提取的文本的最小高度为 12 像素。 此尺寸对应于 150 点/英寸 (DPI) 的大约
8号字文本。对于自定义模型训练,自定义模板模型的训练数据最大页数为 500,自定义神经模型的训练数据最大页数为 50,000。
对于自定义提取模型训练,模板模型的训练数据总大小为 50 MB,神经网络模型的训练数据总大小为
1GB。对于自定义分类模型训练,训练数据总大小为
1GB,上限为 10,000 页。 对于 2024-07-31-preview 及更高版本,训练数据的总大小为2GB,上限为 10,000 页。
支持的文件格式:JPEG、PNG、PDF 和 TIFF。
PDF 和 TIFF 文件支持的页面数:最多 2,000 个页面,或者,对于免费层订阅者,仅支持前两个页面。
支持的文件大小:总共小于 50 MB;最小像素:50 x 50 像素;最大像素:10,000 x 10,000 像素。
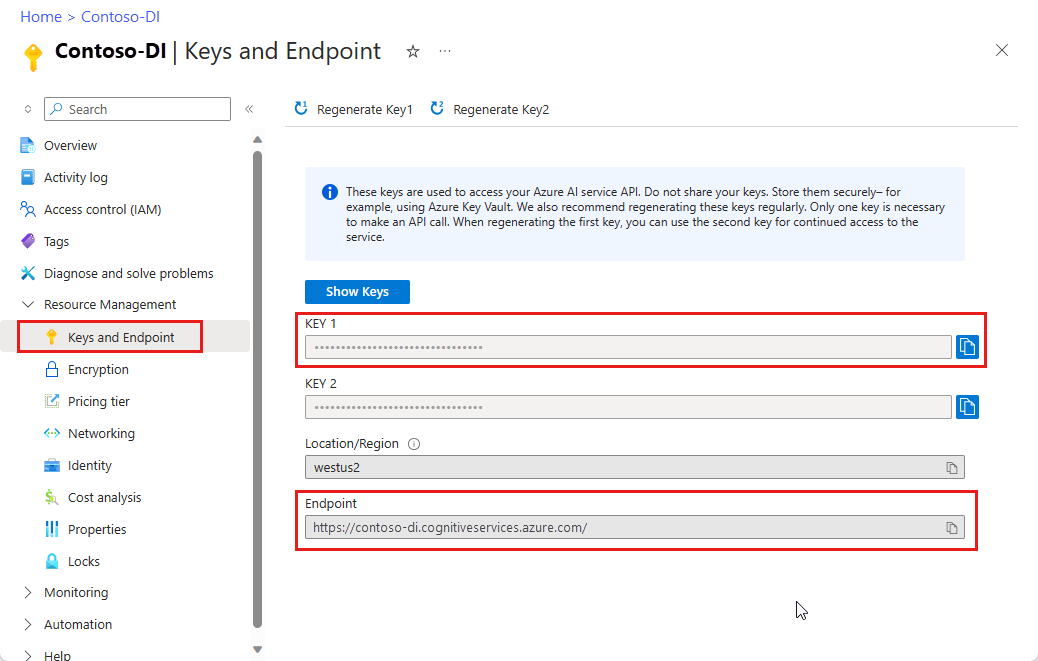
ID 文档模型数据提取
从 ID 文件中提取数据,包括姓名、出生日期和到期日期。 需要以下资源:
注意
文档智能工作室提供 v3.1 和 v3.0 API 及更高版本。
在文档智能工作室主页上,选择“标识文档”。
可以分析示例发票或上传自己的文件。
选择“运行分析”按钮,并根据需要配置“分析选项”:

文档智能示例标记工具
导航到“文档智能示例工具”。
在示例工具主页上,选择“使用预生成模型获取数据”磁贴。
从下拉菜单中选择要分析的“表单类型”。
从以下选项中选择要分析的文件的 URL:
从“源”字段的下拉菜单中选择“URL”,粘贴所选 URL,然后选择“提取”按钮。

在“文档智能服务终结点”字段中,粘贴使用文档智能订阅获得的终结点。
在“密钥”字段中,粘贴从文档智能资源中获取的密钥。

选择“运行分析”。 文档智能示例标记工具调用分析预生成 API 并分析文档。
查看结果 - 查看提取的键值对、明细项目、突出显示的提取的文本和检测到的表。
下载 JSON 输出文件,查看详细结果。
- “readResults”节点包含每一行文本,及其各自在页面上的边界框位置。
- “selectionMarks”节点显示每个选择标记(复选框、单选框),并显示其状态是“已选中”还是“未选中”。
- “pageResults”部分包含提取的表。 对于每个表,文档智能会提取文本、行和列索引、行和列跨距、边界框等。
- “documentResults”字段包含文档中相关度最高部分的键/值对信息和明细项目信息。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
注意
示例标记工具不支持 BMP 文件格式。 这是工具的一项限制,而不是文档智能服务的限制。
支持的文档类型
| 区域 | 文档类型 |
|---|---|
| 全球 | 护照簿、护照卡 |
| 美国 | 驾驶证、身份证、居留许可(绿卡)、社会保障卡、军人身份证 |
| 欧洲 | 驾驶证、身份证、居留许可 |
| 印度 | 驾驶证、PAN 卡、Aadhaar 卡 |
| 加拿大 | 驾驶证、身份证、居留许可(枫叶卡) |
| 澳大利亚 | 驾驶证、照片卡、Key-pass ID(包括数字版本) |
字段提取
有关受支持的文档提取字段,请参阅 GitHub 示例存储库中的“ID 文档模型架构”页。
支持的文档类型
目前,ID 文档模型支持美国驾照和国际护照的个人信息页提取(不包括签证和其他旅行文件)。
提取的字段
| 名称 | Type | 说明 | 值 |
|---|---|---|---|
| 国家/地区 | country | 符合 ISO 3166 标准的国家/地区代码 | “USA” |
| DateOfBirth | date | YYYY-MM-DD 格式的 DOB | “1980-01-01” |
| DateOfExpiration | date | YYYY-MM-DD 格式的到期日期 | “2019-05-05” |
| DocumentNumber | 字符串 | 相关护照号、驾照编号等。 | “340020013” |
| FirstName | 字符串 | 提取的名字和中间名(如适用) | “JENNIFER” |
| LastName | 字符串 | 提取的姓氏 | “BROOKS” |
| 国家/地区 | country | 符合 ISO 3166 标准的国家/地区代码 | “USA” |
| Sex | gender | 可能的提取值包括“M”、“F”和“X” | “F” |
| MachineReadableZone | object | 提取的护照 MRZ 包括两行,每行 44 个字符 |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | 字符串 | 文档类型,例如护照、驾照 | “passport” |
| 地址 | 字符串 | 提取的地址(仅限驾照) | “123 STREET ADDRESS YOUR CITY WA 99999-1234” |
| 区域 | 字符串 | 提取的区域、州、省/直辖市/自治区等(仅限驾照) | “Washington” |
迁移指南
- 请参阅我们的文档智能 v3.1 迁移指南,了解如何在应用程序和工作流中使用 v3.0。
后续步骤
尝试使用 Document Intelligence Studio 来处理你自己的表单和文档。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。
尝试使用文档智能示例标记工具来处理你自己的表单和文档。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。