你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:使用自定义视觉门户生成图像分类模型
本快速入门会介绍如何使用自定义视觉 Web 门户创建图像分类模型。 生成模型后,可以使用新图像测试该模型,并最终将该模型集成到你自己的图像识别应用中。
先决条件
- Azure 订阅。 可以创建免费帐户。
- 一组用于训练分类模型的图像。 可以使用 GitHub 上的一组示例图像。 或者,可以使用以下提示选择自己的图像。
- 受支持的 Web 浏览器。
创建自定义视觉资源
若要使用自定义视觉服务,需要在 Azure 中创建“自定义视觉训练和预测”资源。 在 Azure 门户中,使用“创建自定义视觉”页创建训练资源和预测资源。
新建项目
导航到自定义视觉网页,然后使用登录 Azure 门户时所用的同一帐户登录。
若要创建首个项目,请选择“新建项目” 。 将显示“创建新项目”对话框。
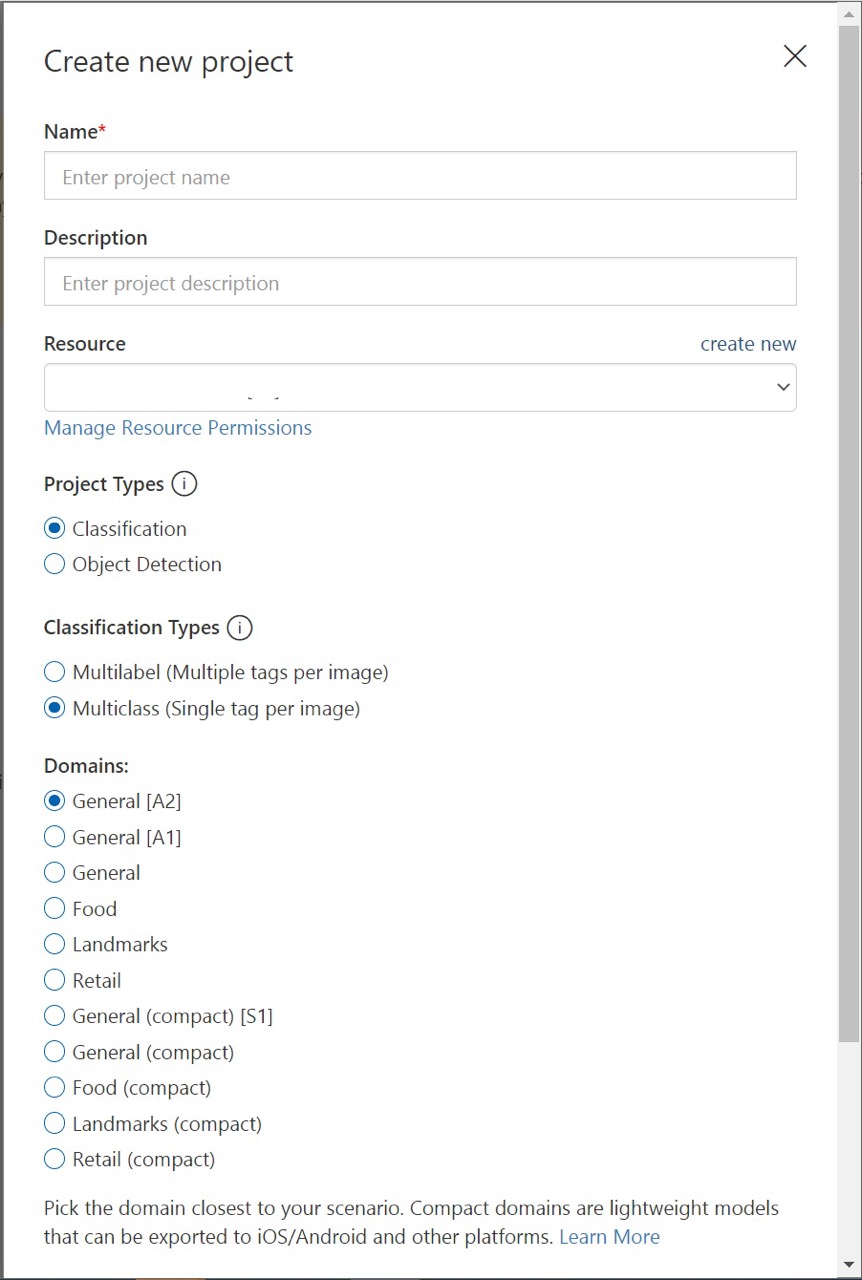
输入项目名称和描述。 然后选择自定义视觉训练资源。 如果登录帐户与 Azure 帐户相关联,则“资源”下拉列表将显示所有兼容的 Azure 资源。
注意
如果没有可用的资源,请确认已使用登录 Azure 门户时所用的同一帐户登录 customvision.ai。 此外,请确认在自定义视觉网站中选择的“目录”与自定义视觉资源所在 Azure 门户中的目录相同。 在这两个站点中,可从屏幕右上角的下拉帐户菜单中选择目录。
选择“项目类型”下的“分类”。 然后,在“分类类型”下,根据用例选择“多标签”或“多类”。 多标签分类将任意数量的标记应用于图像(零个或多个),而多类分类将图像分类为单个类别(提交的每个图像将被分类为最有可能的标记)。 以后可以更改分类类型(如果需要)。
接下来,选择一个可用域。 每个域都会针对特定类型的图像优化模型,如下表所述。 稍后可按需更改域。
域 目的 常规 针对各种图像分类任务进行优化。 如果其他域都不合适,或者不确定要选择哪个域,请选择“通用”域。 食物 针对餐厅菜肴的照片进行优化。 如果要对各种水果或蔬菜的照片进行分类,请使用“食品”域。 特征点 针对可识别的自然和人造地标进行优化。 在照片中的地标清晰可见的情况下,该域效果最佳。 即使照片中的人物稍微遮挡了地标,该域仍然有效。 零售 针对购物目录或购物网站中的图像进行优化。 若想对连衣裙、裤子和衬衫进行精准分类,请使用此域。 压缩域 针对移动设备上实时分类的约束进行优化。 可导出压缩域生成的模型在本地运行。 最后,选择“创建项目”。
选择训练图像
作为最低要求,你应该在初始训练集中为每个标记使用至少 30 张图像。 还应收集一些额外的图像,以便在训练模型后对其进行测试。
为了有效地训练模型,请使用具有视觉多样性的图像。 选择在以下方面有所不同的图像:
- 照相机角度
- 照明
- background
- 视觉样式
- 个人/分组主题
- 大小
- type
此外,请确保所有训练图像满足以下条件:
- 必须为.jpg、.png、.bmp 或 .gif 格式
- 大小不超过 6 MB (预测图像不超过 4 MB)
- 最短的边不小于 256 像素;任何小于 256 像素的图像将通过自定义视觉服务自动纵向扩展
上传和标记图像
可以上传图像并手动标记图像以帮助训练分类器。
若要添加图像,请选择“添加图像”,然后选择“浏览本地文件” 。 选择“打开”以移至标记。 标记选择将应用于上传的整组图像,因此根据其应用的标记将图像分成单独的组更容易上传。 上传图像后,也可以更改各图像的标记。
若要创建标记,请在“我的标记”字段中输入文本,然后按 Enter 键。 如果标记已存在,它会在下拉菜单中显示。 在多标签项目中,可以将多个标记添加到图像,但多类项目中只能添加一个标记。 若要完成上传图像,请使用“上传 [编号] 文件”按钮。
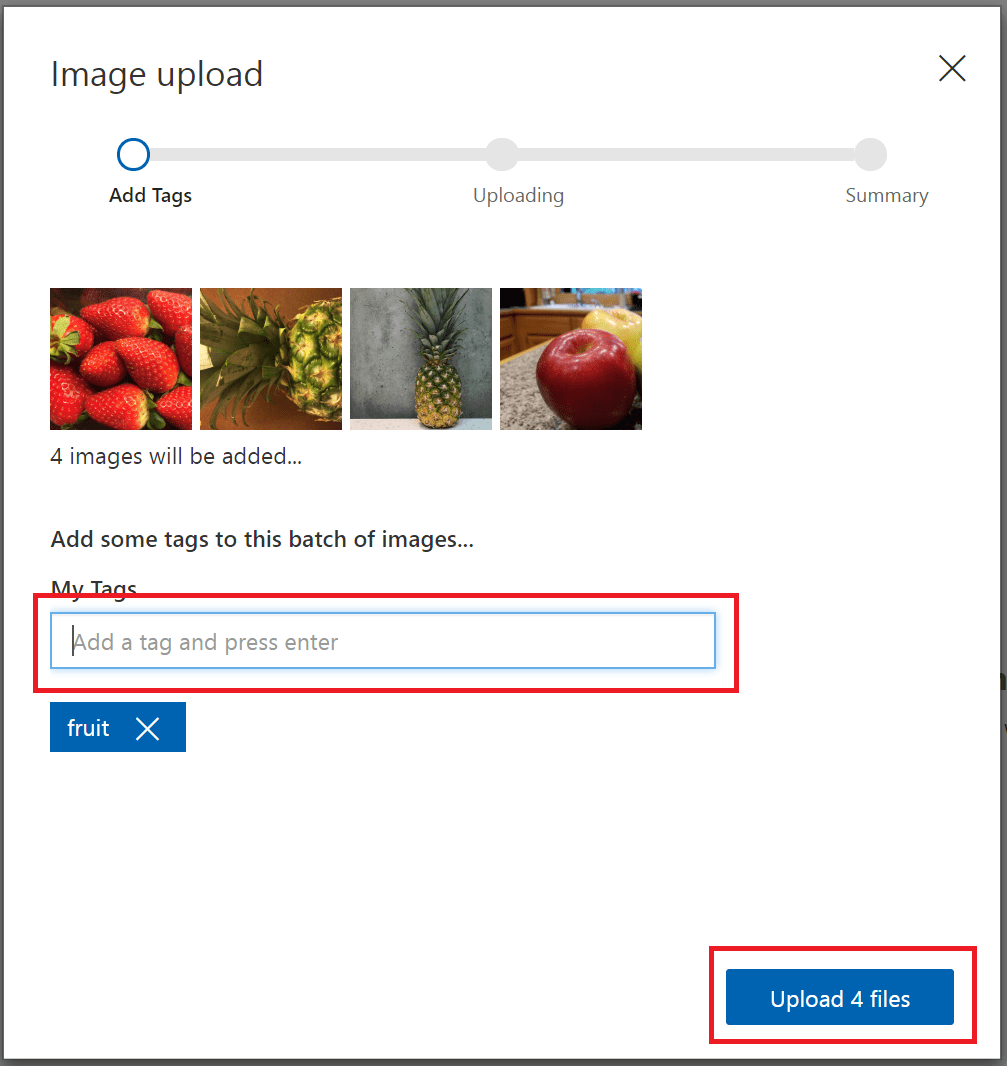
上传图像后,选择“完成”。
若要上传另一组图像,请返回到本部分顶部并重复上述步骤。
训练分类器
若要训练分类器,请选择“训练”按钮。 分类器使用所有当前图像来创建模型,该模型可标识每个标记的视觉质量。 这个过程可能需要几分钟。

此训练过程应该只需要几分钟的时间。 在此期间,会在“性能”选项卡显示有关训练过程的信息。
评估分类器
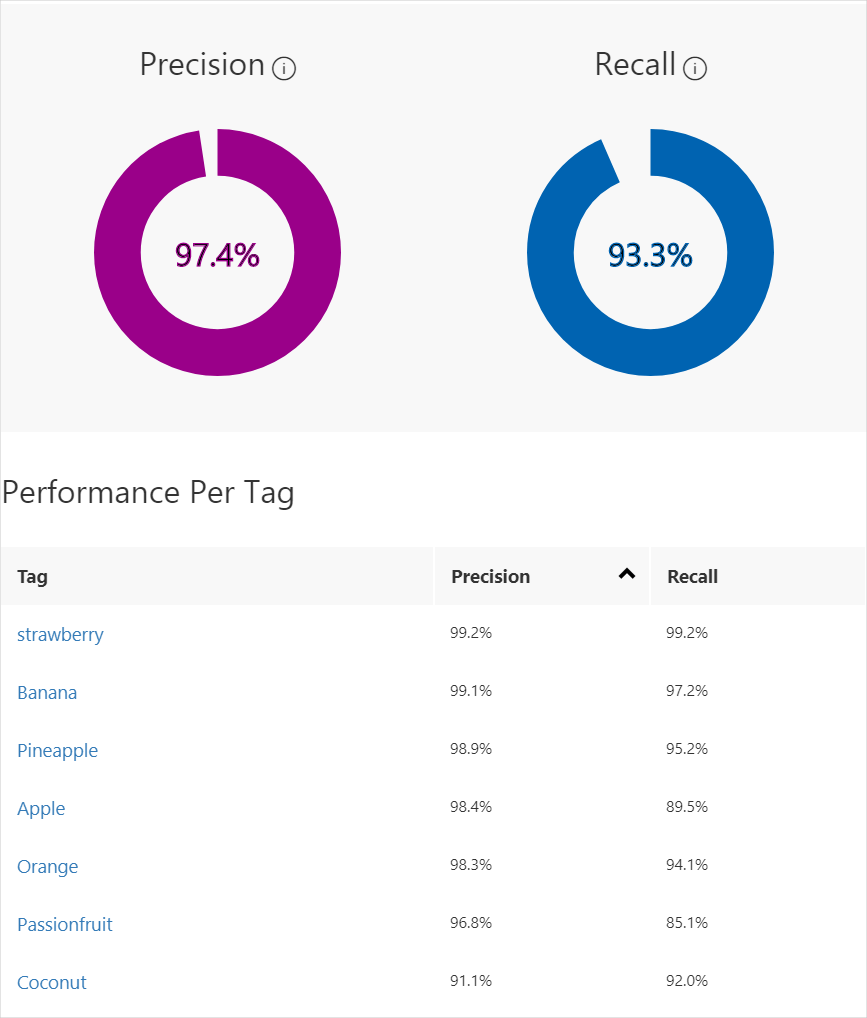
完成训练后,评估并显示该模型的性能。 自定义视觉服务使用提交用于训练的图像来计算精确度和召回率。 精确度和召回率是分类器有效性的两个不同的度量:
- 精确度表示已识别的正确分类的分数。 例如,如果模型将 100 张图像识别为狗,实际上其中 99 张是狗,那么精确度为 99%。
- 召回率表示正确识别的实际分类的分数。 例如,如果实际上有 100 张苹果的图像,并且该模型将 80 张标识为苹果,则召回率为 80%。
概率阈值
请注意“性能”选项卡左窗格上的“概率阈值”滑块 。这是预测被视为正确时所需具有的置信度(用于计算精度和召回率)。
当解释具有高概率阈值的预测调用时,它们往往会以牺牲召回为代价返回高精度的结果 - 检测到的分类是正确的,但许多分类仍然未被检测到。 使用较低的概率阈值则恰恰相反 - 大多数实际分类会被检测到,但该集合内有更多误报。 考虑到这一点,应该根据项目的特定需求设置概率阈值。 稍后,在客户端接收预测结果时,应使用与此处所用概率阈值相同的概率阈值。
管理训练迭代
每次训练分类器时,都会创建一个新的迭代,其中包含已更新的性能指标。 可以在“性能”选项卡的左窗格中查看所有迭代。还可以找到“删除”按钮,如果迭代已过时,可以使用该按钮删除迭代。 删除迭代时,会删除唯一与其关联的所有图像。
若要了解如何以编程方式访问已训练的模型,请参阅调用预测 API。
下一步
在本快速入门中,已了解了如何使用自定义视觉 Web 门户创建和训练图像分类模型。 接下来,获取有关改进模型的迭代过程的详细信息。