你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
什么是关键字识别?
关键字识别检测音频流中的单词或短语。 此技术也称为关键字辨识。
关键字识别最常见的用例是通过语音激活虚拟助理。 例如,“Hey Cortana”是 Cortana 助理的关键字。 识别出关键字后,会执行特定于方案的操作。对于虚拟助理方案,常见的操作是对关键字后面的音频进行语音识别。
通常,虚拟助理始终会侦听。 关键字识别充当用户的隐私边界。 关键字要求充当入口,防止不相关的用户音频从本地设备传输到云。
为了平衡准确度、延迟和计算复杂性,关键字识别以一个多阶段系统的形式实现。 对于第一个阶段之外的所有阶段,只有在此阶段之前的阶段已识别出意向关键字时,才会处理音频。
当前系统设计为具有跨边缘和云的多个阶段:
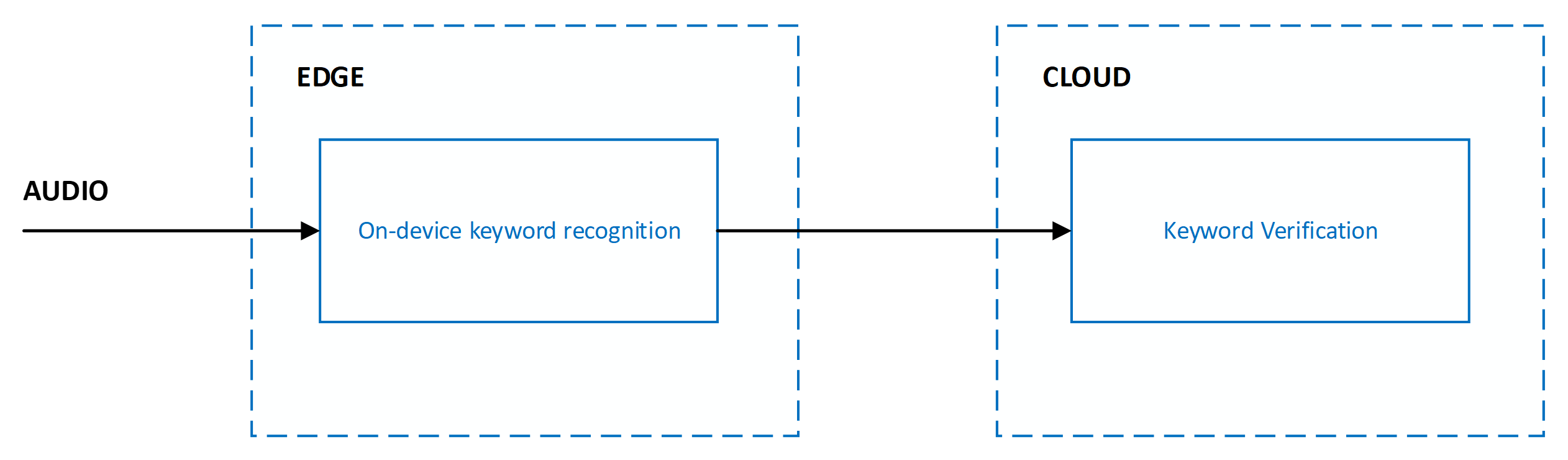
关键字识别的准确度通过以下指标进行衡量:
- 正确接受率:衡量系统识别用户说出的关键字的能力。 正确接受率也称为真正率。
- 错误接受率:衡量系统筛选出音频中不属于用户说出的关键字的能力。 错误接受率也称为假正率。
目标是最大程度地提高正确接受率,同时最大程度地降低错误接受率。 当前系统旨在检测前面有短时间沉默的关键字或短语。 不支持检测句子或话语中间的关键字。
设备模型的自定义关键字
你可以使用 Speech Studio 上的自定义关键字门户,通过指定任何字词或短语来生成在边缘执行的关键字识别模型。 可以通过选择适当的发音来进一步对关键字模型进行个性化设置。
定价
使用自定义关键字生成模型(包括基本模型和高级模型)不会产生费用。 当与其他语音服务功能(如语音转文本)结合使用时,使用语音 SDK 在设备上运行模型也不会产生任何费用。
模型类型
你可以使用自定义关键字,针对任何关键字生成两种类型的设备模型。
| 模型类型 | 说明 |
|---|---|
| 基本 | 最适合用于演示或快速原型制作。 模型是使用常见的基本模型生成的,最多需要 15 分钟才能准备就绪。 模型可能没有最佳准确度这一特性。 |
| 高级 | 最适合用于产品集成。 模型是使用模拟训练数据对常见基本模型进行调整而生成,在准确度方面有所提高。 模型最多需要 48 小时便可准备就绪。 |
注意
可以在关键字识别区域支持文档中查看支持高级模型类型的区域列表。
这两种模型类型都不需要上传训练数据。 自定义关键字可完全处理数据生成和模型训练。
发音
创建新模型时,自定义关键字会自动生成所提供关键字的可能发音。 你可以听取每个发音,并选择最能代表你期望最终用户说出关键字的所有变体。 不应选择所有其他发音。
为确保最佳准确度,请务必谨慎选择发音。 例如,如果选择的发音超过所需的发音,可能会得到更高的错误接受率。 如果选择的发音太少(未包含所有预期发音),你可能会得到较低的正确接受率。
测试模型
使用自定义关键字生成设备模型后,可直接在门户上对其进行测试。 你可以通过门户直接在浏览器中讲话,并获得关键字识别结果。
关键字验证
关键字验证是一项云服务,它使用在 Azure 上运行的可靠模型来减少设备模型产生的错误接受的影响。 关键字验证无需任何优化或训练即可处理关键字。 增量模型更新会持续部署到服务以提高准确度和降低延迟,对客户端应用程序公开透明。
定价
关键字验证始终与语音转文本结合使用。 除了语音转文本的费用之外,使用关键字验证无需任何费用。
关键字验证和语音转文本
使用关键字验证时,必须将其与语音转文本结合使用。 两个服务并行运行意味着音频将发送到这两个服务以同时处理。
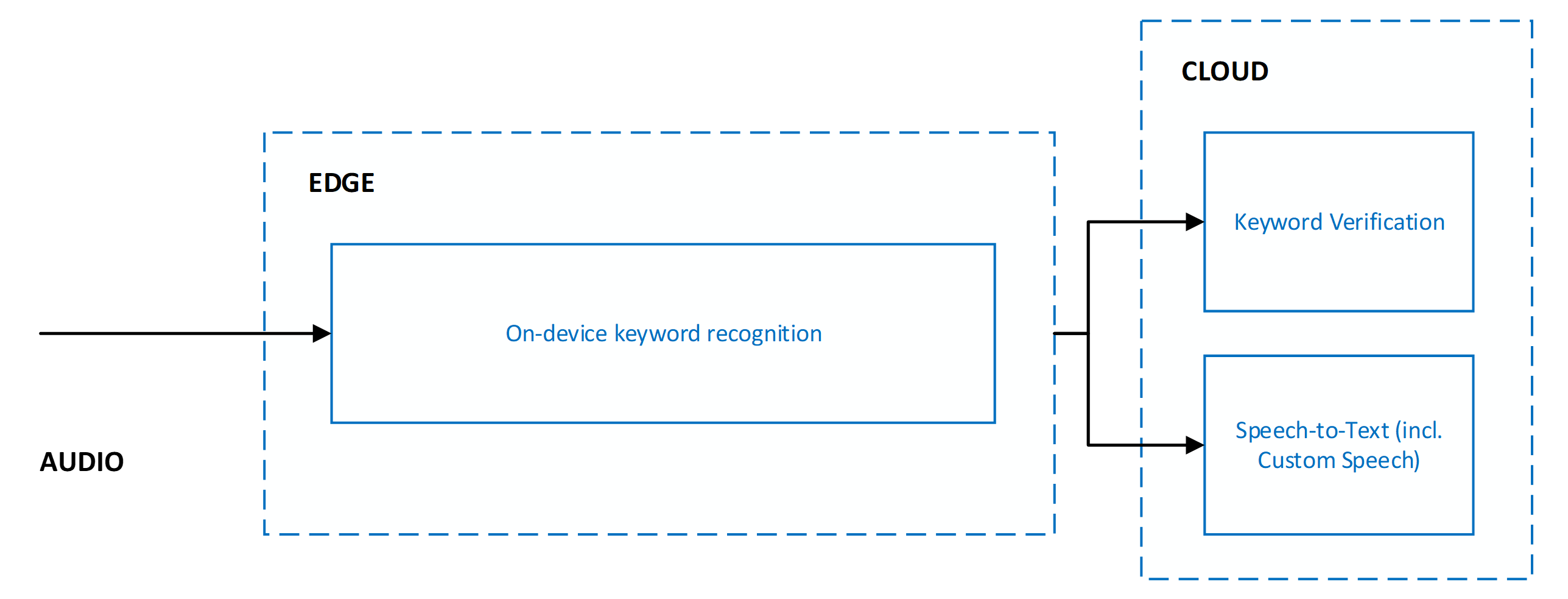
并行运行关键字验证和语音转文本将具有以下优势:
- 语音转文本结果没有其他延迟:并行执行意味着关键字验证不会增加延迟。 客户端将会以同样快的速度接收语音转文本结果。 如果关键字验证确定音频中不存在关键字,则语音转文本处理将终止。 此操作可防止进行不必要的语音转文本处理。 网络和云模型处理会增加用户感受到的语音激活延迟。 有关详细信息,请参阅建议和指南。
- 语音转文本结果中强制生成的关键字前缀:语音转文本处理将确保发送给客户端的结果以相应关键字为前缀。 此行为可提高关键字后面的语音的语音转文本结果的准确度。
- 增加语音转文本超时时间:由于在音频开始时选择了预期存在的关键字,因此语音转文本将允许在关键字后面停顿最多 5 秒,然后再确定语音结束和终止语音转文本处理。 此行为可确保分段命令 (<keyword><pause><command>) 和链接命令 (<keyword><command>) 都可正确处理用户体验。
关键字验证响应和延迟注意事项
对于向服务发出的每个请求,关键字验证都将返回以下两个响应之一:“已接受”或“已拒绝”。 延迟处理能力取决于关键字的长度和预期包含关键字的音频段的长度。 处理延迟不包括客户端与语音服务之间的网络开销。
| 关键字验证响应 | 说明 |
|---|---|
| 已接受 | 表示服务认为关键字存在于作为请求的一部分提供的音频流中。 |
| 已拒绝 | 表示服务认为关键字不存在于作为请求的一部分提供的音频流中。 |
在被拒绝的情况中,通常会产生较高的延迟,因为服务处理的音频比接受的案例更多。 默认情况下,关键字验证将处理最多两秒的音频以搜索关键字。 如果关键字不在这两秒钟的内容里,则该服务将超时并向客户端发送拒绝响应。
在设备端模型使用自定义关键字的关键字验证
你可以结合使用自定义关键字与关键字验证和语音转文本来生成设备端模型,语音 SDK 则有助于无缝使用这种模型。 它以透明方式处理以下操作:
- 基于设备端模型的结果对关键字验证和语音识别进行音频控制。
- 将关键字发送到关键字验证。
- 将更多元数据发送到云,以协调端到端方案。
无需显式指定任何配置参数。 将从自定义关键字生成的设备端模型中自动提取所有必要的信息。
以下带有链接的示例和教程演示了如何使用语音 SDK:
语音 SDK 集成和方案
语音 SDK 有助于轻松使用通过自定义关键字和关键字验证生成的个性化设备端关键字识别模型。 为了确保满足产品需求,SDK 支持以下两种方案:
| 方案 | 说明 | 示例 |
|---|---|---|
| 使用语音转文本的端到端关键字识别 | 最适合于使用自定义设备端关键字模型的产品,该模型由自定义关键字与关键字验证和语音转文本相结合而生成。 这是最常见的情况。 | |
| 脱机关键字识别 | 最适用于没有网络连接的产品,这些产品将使用自定义关键字生成的自定义设备端关键字模型。 |