你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何将推理模型与 Azure AI 模型推理配合使用
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何使用部署到 Azure AI 模型推理的聊天完成模型在 Azure AI 服务中的推理功能。
推理模型
推理模型可以在数学、编码、科学、策略和物流等领域达到更高的性能水平。 这些模型生成输出的方式是通过明确使用思维链来探索所有可能的路径,然后再生成答案。 他们在产生答案时会对其进行验证,这有助于他们得出更好、更准确的结论。 这意味着推理模型在提示时可能需要更少的上下文来产生有效的结果。
缩放模型性能的这种方式称为“推理计算时间”,因为它以较高的延迟和成本来换取性能。 它与通过“训练计算时间”缩放的其他方法形成鲜明对比。
然后,推理模型生成两种类型的输出:
- 推理完成
- 输出完成
这两个完成都计入模型生成的内容,因此也计入与模型相关的令牌限制和成本。 某些模型可能会输出推理内容,例如 DeepSeek-R1。 其他模型(例如 o1)仅输出完成的输出部分。
先决条件
要完成本教程,需要:
Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读从 GitHub 模型升级到 Azure AI 模型推理。
Azure AI 服务资源。 有关详细信息,请参阅创建 Azure AI 服务资源。
终结点 URL 和密钥。
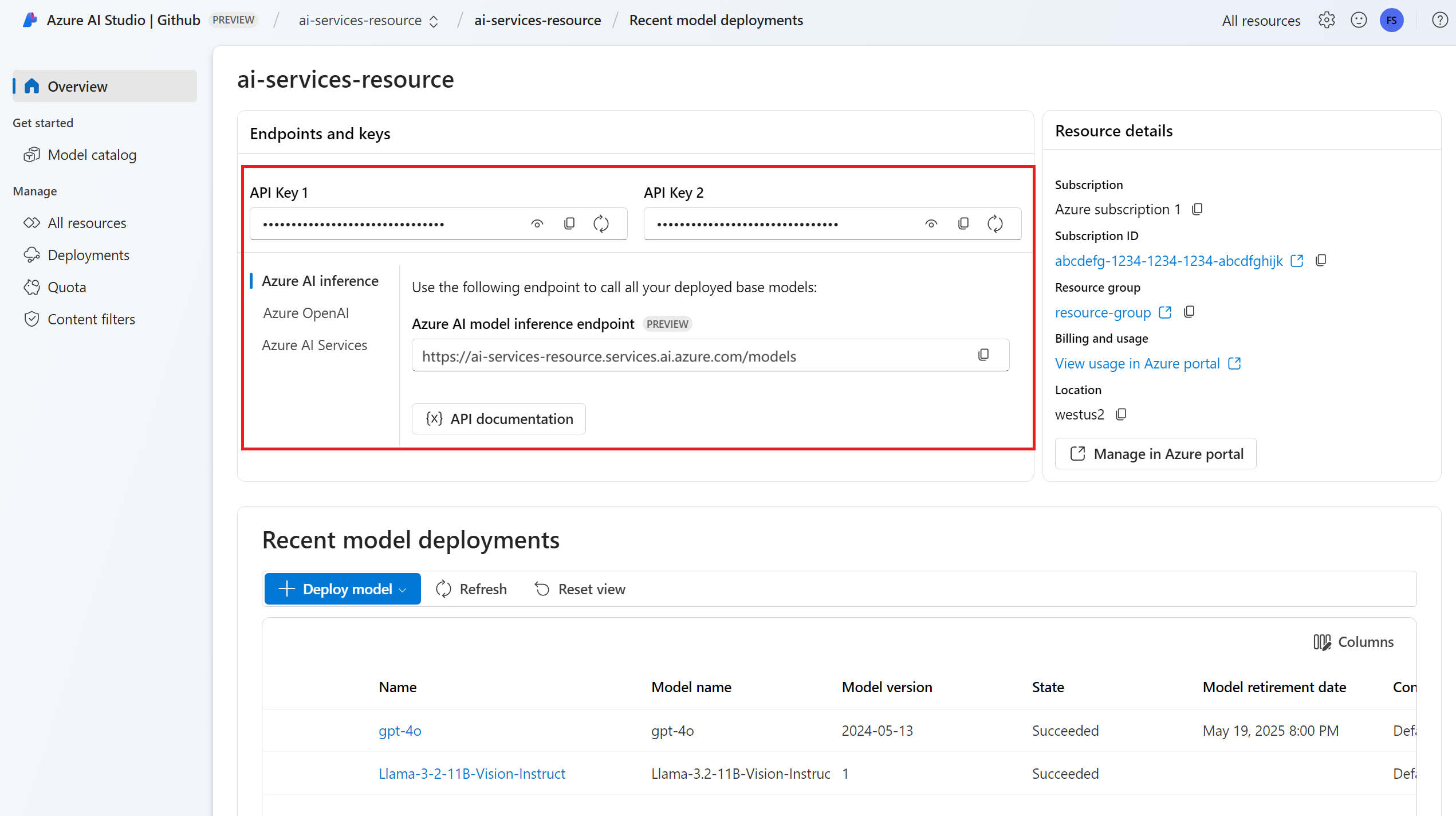

具有推理功能模型部署的模型。 如果没有,请参阅添加并将模型配置为 Azure AI 服务以添加推理模型。
- 此示例使用
DeepSeek-R1。
- 此示例使用
请使用以下命令安装 Azure AI 推理包:
pip install -U azure-ai-inference
通过聊天使用推理功能
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="deepseek-r1"
)
提示
使用 Azure AI 模型推理 API 验证是否已将模型部署到 Azure AI 服务资源。
Deepseek-R1 也可作为无服务器 API 终结点使用。 但是,这些终结点不采用本教程中所述的参数 model。 可以通过转到 Azure AI Foundry 门户> 模型 + 终结点来验证该模型是否列在 Azure AI 服务部分下。
如果将资源配置为具有 Microsoft Entra ID 支持,则可以使用以下代码片段创建客户端。
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=DefaultAzureCredential(),
credential_scopes=["https://cognitiveservices.azure.com/.default"],
model="deepseek-r1"
)
创建聊天补全请求
以下示例演示如何创建对模型的基本聊天请求。
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
UserMessage(content="How many languages are in the world?"),
],
)
生成推理模型的提示时,请考虑以下事项:
- 使用简单的说明,避免使用思维链技巧。
- 内置的推理功能使简单的零次提示和更复杂的方法一样有效。
- 提供其他上下文或文档(例如在 RAG 方案中)时,仅包含最相关的信息可能有助于防止模型过度复杂化其响应。
- 推理模型可能支持使用系统消息。 但是,它们可能不会像其他非推理模型那样严格地遵循它们。
- 创建多轮次应用程序时,请考虑仅追加模型的最终答案,而不考虑按“推理内容”部分所述对内容进行推理。
响应如下所示,可从中查看模型的使用统计信息:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer...</think>As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
推理内容
某些推理模型(如 DeepSeek-R1)会生成补全内容并包含其背后的推理。 与补全关联的推理包含在标记 <think> 和 </think> 内的响应内容中。 此模型可以选择针对哪些场景生成推理内容。 你可以从响应中提取推理内容来了解模型的思维过程,如下所示:
import re
match = re.match(r"<think>(.*?)</think>(.*)", response.choices[0].message.content, re.DOTALL)
print("Response:", )
if match:
print("\tThinking:", match.group(1))
print("\tAnswer:", match.group(2))
else:
print("\tAnswer:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
进行多轮次对话时,避免在聊天历史记录中发送推理内容非常有用,因为推理倾向于生成较长的解释。
流式传输内容
默认情况下,补全 API 会在单个响应中返回整个生成的内容。 如果要生成长补全内容,等待响应可能需要几秒钟时间。
可以流式传输内容,以在生成内容时获取它。 通过流式处理内容,可以在内容可用时开始处理补全。 此模式返回一个对象,该对象将响应作为仅数据服务器发送的事件进行流式传输。 从增量字段(而不是消息字段)中提取区块。
若要流式传输补全,请在调用模型时设置 stream=True。
result = client.complete(
model="deepseek-r1",
messages=[
UserMessage(content="How many languages are in the world?"),
],
max_tokens=2048,
stream=True,
)
若要可视化输出,请定义用于输出流的帮助程序函数。 以下示例实现仅流式传输答案且没有推理内容的路由:
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
is_thinking = False
for event in completion:
if event.choices:
content = event.choices[0].delta.content
if content == "<think>":
is_thinking = True
print("🧠 Thinking...", end="", flush=True)
elif content == "</think>":
is_thinking = False
print("🛑\n\n")
elif content:
print(content, end="", flush=True)
可以直观显示流式处理如何生成内容:
print_stream(result)
参数
一般情况下,推理模型不支持在聊天完成模型中找到的以下参数:
- 温度
- 出现惩罚
- 重复惩罚
- 参数
top_p
某些模型支持使用工具或结构化输出(包括 JSON 架构)。 请参阅“模型”详细信息页,了解每个模型的支持。
应用内容安全
Azure AI 模型推理 API 支持 Azure AI 内容安全。 在启用 Azure AI 内容安全的情况下使用部署时,输入和输出会经过一系列分类模型,旨在检测和防止输出有害内容。 内容筛选系统会在输入提示和输出补全中检测特定类别的潜在有害内容并对其采取措施。
以下示例展示了当模型在输入提示中检测到有害内容且内容安全已启用时如何处理事件。
from azure.ai.inference.models import AssistantMessage, UserMessage
try:
response = client.complete(
model="deepseek-r1",
messages=[
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
],
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
提示
若要详细了解如何配置和控制 Azure AI 内容安全设置,请查看 Azure AI 内容安全文档。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何使用部署到 Azure AI 模型推理的聊天完成模型在 Azure AI 服务中的推理功能。
推理模型
推理模型可以在数学、编码、科学、策略和物流等领域达到更高的性能水平。 这些模型生成输出的方式是通过明确使用思维链来探索所有可能的路径,然后再生成答案。 他们在产生答案时会对其进行验证,这有助于他们得出更好、更准确的结论。 这意味着推理模型在提示时可能需要更少的上下文来产生有效的结果。
缩放模型性能的这种方式称为“推理计算时间”,因为它以较高的延迟和成本来换取性能。 它与通过“训练计算时间”缩放的其他方法形成鲜明对比。
然后,推理模型生成两种类型的输出:
- 推理完成
- 输出完成
这两个完成都计入模型生成的内容,因此也计入与模型相关的令牌限制和成本。 某些模型可能会输出推理内容,例如 DeepSeek-R1。 其他模型(例如 o1)仅输出完成的输出部分。
先决条件
要完成本教程,需要:
Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读从 GitHub 模型升级到 Azure AI 模型推理。
Azure AI 服务资源。 有关详细信息,请参阅创建 Azure AI 服务资源。
终结点 URL 和密钥。
具有推理功能模型部署的模型。 如果没有,请参阅添加并将模型配置为 Azure AI 服务以添加推理模型。
- 此示例使用
DeepSeek-R1。
- 此示例使用
使用以下命令安装适用于 JavaScript 的 Azure 推理库:
npm install @azure-rest/ai-inference
通过聊天使用推理功能
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
提示
使用 Azure AI 模型推理 API 验证是否已将模型部署到 Azure AI 服务资源。
Deepseek-R1 也可作为无服务器 API 终结点使用。 但是,这些终结点不采用本教程中所述的参数 model。 可以通过转到 Azure AI Foundry 门户> 模型 + 终结点来验证该模型是否列在 Azure AI 服务部分下。
如果将资源配置为具有 Microsoft Entra ID 支持,则可以使用以下代码片段创建客户端。
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const clientOptions = { credentials: { "https://cognitiveservices.azure.com" } };
const client = new ModelClient(
"https://<resource>.services.ai.azure.com/models",
new DefaultAzureCredential(),
clientOptions,
);
创建聊天补全请求
以下示例演示如何创建对模型的基本聊天请求。
var messages = [
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
model: "DeepSeek-R1",
messages: messages,
}
});
生成推理模型的提示时,请考虑以下事项:
- 使用简单的说明,避免使用思维链技巧。
- 内置的推理功能使简单的零次提示和更复杂的方法一样有效。
- 提供其他上下文或文档(例如在 RAG 方案中)时,仅包含最相关的信息可能有助于防止模型过度复杂化其响应。
- 推理模型可能支持使用系统消息。 但是,它们可能不会像其他非推理模型那样严格地遵循它们。
- 创建多轮次应用程序时,请考虑仅追加模型的最终答案,而不考虑按“推理内容”部分所述对内容进行推理。
响应如下所示,可从中查看模型的使用统计信息:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer...</think>As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
推理内容
某些推理模型(如 DeepSeek-R1)会生成补全内容并包含其背后的推理。 与补全关联的推理包含在标记 <think> 和 </think> 内的响应内容中。 此模型可以选择针对哪些场景生成推理内容。 你可以从响应中提取推理内容来了解模型的思维过程,如下所示:
var content = response.body.choices[0].message.content
var match = content.match(/<think>(.*?)<\/think>(.*)/s);
console.log("Response:");
if (match) {
console.log("\tThinking:", match[1]);
console.log("\Answer:", match[2]);
}
else {
console.log("Response:", content);
}
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
进行多轮次对话时,避免在聊天历史记录中发送推理内容非常有用,因为推理倾向于生成较长的解释。
流式传输内容
默认情况下,补全 API 会在单个响应中返回整个生成的内容。 如果要生成长补全内容,等待响应可能需要几秒钟时间。
可以流式传输内容,以在生成内容时获取它。 通过流式处理内容,可以在内容可用时开始处理补全。 此模式返回一个对象,该对象将响应作为仅数据服务器发送的事件进行流式传输。 从增量字段(而不是消息字段)中提取区块。
若要流式传输补全,请在调用模型时设置 stream=True。
var messages = [
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
model: "DeepSeek-R1",
messages: messages,
}
}).asNodeStream();
若要可视化输出,请定义用于输出流的帮助程序函数。 以下示例实现仅流式传输答案且没有推理内容的路由:
function printStream(sses) {
let isThinking = false;
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
const content = choice.delta?.content ?? "";
if (content === "<think>") {
isThinking = true;
process.stdout.write("🧠 Thinking...");
} else if (content === "</think>") {
isThinking = false;
console.log("🛑\n\n");
} else if (content) {
process.stdout.write(content);
}
}
}
}
可以直观显示流式处理如何生成内容:
var sses = createSseStream(response.body);
printStream(result)
参数
一般情况下,推理模型不支持在聊天完成模型中找到的以下参数:
- 温度
- 出现惩罚
- 重复惩罚
- 参数
top_p
某些模型支持使用工具或结构化输出(包括 JSON 架构)。 请参阅“模型”详细信息页,了解每个模型的支持。
应用内容安全
Azure AI 模型推理 API 支持 Azure AI 内容安全。 在启用 Azure AI 内容安全的情况下使用部署时,输入和输出会经过一系列分类模型,旨在检测和防止输出有害内容。 内容筛选系统会在输入提示和输出补全中检测特定类别的潜在有害内容并对其采取措施。
以下示例展示了当模型在输入提示中检测到有害内容且内容安全已启用时如何处理事件。
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
model: "DeepSeek-R1",
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
提示
若要详细了解如何配置和控制 Azure AI 内容安全设置,请查看 Azure AI 内容安全文档。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何使用部署到 Azure AI 模型推理的聊天完成模型在 Azure AI 服务中的推理功能。
推理模型
推理模型可以在数学、编码、科学、策略和物流等领域达到更高的性能水平。 这些模型生成输出的方式是通过明确使用思维链来探索所有可能的路径,然后再生成答案。 他们在产生答案时会对其进行验证,这有助于他们得出更好、更准确的结论。 这意味着推理模型在提示时可能需要更少的上下文来产生有效的结果。
缩放模型性能的这种方式称为“推理计算时间”,因为它以较高的延迟和成本来换取性能。 它与通过“训练计算时间”缩放的其他方法形成鲜明对比。
然后,推理模型生成两种类型的输出:
- 推理完成
- 输出完成
这两个完成都计入模型生成的内容,因此也计入与模型相关的令牌限制和成本。 某些模型可能会输出推理内容,例如 DeepSeek-R1。 其他模型(例如 o1)仅输出完成的输出部分。
先决条件
要完成本教程,需要:
Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读从 GitHub 模型升级到 Azure AI 模型推理。
Azure AI 服务资源。 有关详细信息,请参阅创建 Azure AI 服务资源。
终结点 URL 和密钥。
具有推理功能模型部署的模型。 如果没有,请参阅添加并将模型配置为 Azure AI 服务以添加推理模型。
- 此示例使用
DeepSeek-R1。
- 此示例使用
将 Azure AI 推理包添加到项目:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.2</version> </dependency>如果使用 Entra ID,则还需要以下包:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>导入下列命名空间:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
通过聊天使用推理功能
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
ChatCompletionsClient client = new ChatCompletionsClient(
new URI("https://<resource>.services.ai.azure.com/models"),
new AzureKeyCredential(System.getProperty("AZURE_INFERENCE_CREDENTIAL")),
提示
使用 Azure AI 模型推理 API 验证是否已将模型部署到 Azure AI 服务资源。
Deepseek-R1 也可作为无服务器 API 终结点使用。 但是,这些终结点不采用本教程中所述的参数 model。 可以通过转到 Azure AI Foundry 门户> 模型 + 终结点来验证该模型是否列在 Azure AI 服务部分下。
如果将资源配置为具有 Microsoft Entra ID 支持,则可以使用以下代码片段创建客户端。
client = new ChatCompletionsClient(
new URI("https://<resource>.services.ai.azure.com/models"),
new DefaultAzureCredentialBuilder().build()
);
创建聊天补全请求
以下示例演示如何创建对模型的基本聊天请求。
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
.setModel("DeepSeek-R1")
.setMessages(Arrays.asList(
new ChatRequestUserMessage("How many languages are in the world?")
));
Response<ChatCompletions> response = client.complete(requestOptions);
生成推理模型的提示时,请考虑以下事项:
- 使用简单的说明,避免使用思维链技巧。
- 内置的推理功能使简单的零次提示和更复杂的方法一样有效。
- 提供其他上下文或文档(例如在 RAG 方案中)时,仅包含最相关的信息可能有助于防止模型过度复杂化其响应。
- 推理模型可能支持使用系统消息。 但是,它们可能不会像其他非推理模型那样严格地遵循它们。
- 创建多轮次应用程序时,请考虑仅追加模型的最终答案,而不考虑按“推理内容”部分所述对内容进行推理。
响应如下所示,可从中查看模型的使用统计信息:
System.out.println("Response: " + response.getValue().getChoices().get(0).getMessage().getContent());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate...</think>The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
推理内容
某些推理模型(如 DeepSeek-R1)会生成补全内容并包含其背后的推理。 与补全关联的推理包含在标记 <think> 和 </think> 内的响应内容中。 此模型可以选择针对哪些场景生成推理内容。 你可以从响应中提取推理内容来了解模型的思维过程,如下所示:
String content = response.getValue().getChoices().get(0).getMessage().getContent()
Pattern pattern = Pattern.compile("<think>(.*?)</think>(.*)", Pattern.DOTALL);
Matcher matcher = pattern.matcher(content);
System.out.println("Response:");
if (matcher.find()) {
System.out.println("\tThinking: " + matcher.group(1));
System.out.println("\tAnswer: " + matcher.group(2));
}
else {
System.out.println("Response: " + content);
}
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
进行多轮次对话时,避免在聊天历史记录中发送推理内容非常有用,因为推理倾向于生成较长的解释。
流式传输内容
默认情况下,补全 API 会在单个响应中返回整个生成的内容。 如果要生成长补全内容,等待响应可能需要几秒钟时间。
可以流式传输内容,以在生成内容时获取它。 通过流式处理内容,可以在内容可用时开始处理补全。 此模式返回一个对象,该对象将响应作为仅数据服务器发送的事件进行流式传输。 从增量字段(而不是消息字段)中提取区块。
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
.setModel("DeepSeek-R1")
.setMessages(Arrays.asList(
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
))
.setMaxTokens(4096);
return client.completeStreamingAsync(requestOptions).thenAcceptAsync(response -> {
try {
printStream(response);
} catch (Exception e) {
throw new RuntimeException(e);
}
});
若要可视化输出,请定义用于输出流的帮助程序函数。 以下示例实现仅流式传输答案且没有推理内容的路由:
public void printStream(StreamingResponse<StreamingChatCompletionsUpdate> response) throws Exception {
boolean isThinking = false;
for (StreamingChatCompletionsUpdate chatUpdate : response) {
if (chatUpdate.getContentUpdate() != null && !chatUpdate.getContentUpdate().isEmpty()) {
String content = chatUpdate.getContentUpdate();
if ("<think>".equals(content)) {
isThinking = true;
System.out.print("🧠 Thinking...");
System.out.flush();
} else if ("</think>".equals(content)) {
isThinking = false;
System.out.println("🛑\n\n");
} else if (content != null && !content.isEmpty()) {
System.out.print(content);
System.out.flush();
}
}
}
}
可以直观显示流式处理如何生成内容:
try {
streamMessageAsync(client).get();
} catch (Exception e) {
throw new RuntimeException(e);
}
参数
一般情况下,推理模型不支持在聊天完成模型中找到的以下参数:
- 温度
- 出现惩罚
- 重复惩罚
- 参数
top_p
某些模型支持使用工具或结构化输出(包括 JSON 架构)。 请参阅“模型”详细信息页,了解每个模型的支持。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何使用部署到 Azure AI 模型推理的聊天完成模型在 Azure AI 服务中的推理功能。
推理模型
推理模型可以在数学、编码、科学、策略和物流等领域达到更高的性能水平。 这些模型生成输出的方式是通过明确使用思维链来探索所有可能的路径,然后再生成答案。 他们在产生答案时会对其进行验证,这有助于他们得出更好、更准确的结论。 这意味着推理模型在提示时可能需要更少的上下文来产生有效的结果。
缩放模型性能的这种方式称为“推理计算时间”,因为它以较高的延迟和成本来换取性能。 它与通过“训练计算时间”缩放的其他方法形成鲜明对比。
然后,推理模型生成两种类型的输出:
- 推理完成
- 输出完成
这两个完成都计入模型生成的内容,因此也计入与模型相关的令牌限制和成本。 某些模型可能会输出推理内容,例如 DeepSeek-R1。 其他模型(例如 o1)仅输出完成的输出部分。
先决条件
要完成本教程,需要:
Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读从 GitHub 模型升级到 Azure AI 模型推理。
Azure AI 服务资源。 有关详细信息,请参阅创建 Azure AI 服务资源。
终结点 URL 和密钥。
具有推理功能模型部署的模型。 如果没有,请参阅添加并将模型配置为 Azure AI 服务以添加推理模型。
- 本示例使用
DeepSeek-R1。
- 本示例使用
请使用以下命令安装 Azure AI 推理包:
dotnet add package Azure.AI.Inference --prerelease如果使用 Entra ID,则还需要以下包:
dotnet add package Azure.Identity
通过聊天使用推理功能
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/models"),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL"))
);
提示
使用 Azure AI 模型推理 API 验证是否已将模型部署到 Azure AI 服务资源。
Deepseek-R1 也可作为无服务器 API 终结点使用。 但是,这些终结点不采用本教程中所述的参数 model。 可以通过转到 Azure AI Foundry 门户> 模型 + 终结点来验证该模型是否列在 Azure AI 服务部分下。
如果将资源配置为具有 Microsoft Entra ID 支持,则可以使用以下代码片段创建客户端。
TokenCredential credential = new DefaultAzureCredential(includeInteractiveCredentials: true);
AzureAIInferenceClientOptions clientOptions = new AzureAIInferenceClientOptions();
BearerTokenAuthenticationPolicy tokenPolicy = new BearerTokenAuthenticationPolicy(credential, new string[] { "https://cognitiveservices.azure.com/.default" });
clientOptions.AddPolicy(tokenPolicy, HttpPipelinePosition.PerRetry);
client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/models"),
credential,
clientOptions,
);
创建聊天补全请求
以下示例演示如何创建对模型的基本聊天请求。
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestUserMessage("How many languages are in the world?")
},
Model = "deepseek-r1",
};
Response<ChatCompletions> response = client.Complete(requestOptions);
生成推理模型的提示时,请考虑以下事项:
- 使用简单的说明,避免使用思维链技巧。
- 内置的推理功能使简单的零次提示和更复杂的方法一样有效。
- 提供其他上下文或文档(例如在 RAG 方案中)时,仅包含最相关的信息可能有助于防止模型过度复杂化其响应。
- 推理模型可能支持使用系统消息。 但是,它们可能不会像其他非推理模型那样严格地遵循它们。
- 创建多轮次应用程序时,请考虑仅追加模型的最终答案,而不考虑按“推理内容”部分所述对内容进行推理。
响应如下所示,可从中查看模型的使用统计信息:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: <think>Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate...</think>The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: deepseek-r1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
推理内容
某些推理模型(如 DeepSeek-R1)会生成补全内容并包含其背后的推理。 与补全关联的推理包含在标记 <think> 和 </think> 内的响应内容中。 此模型可以选择针对哪些场景生成推理内容。 你可以从响应中提取推理内容来了解模型的思维过程,如下所示:
Regex regex = new Regex(pattern, RegexOptions.Singleline);
Match match = regex.Match(response.Value.Content);
Console.WriteLine("Response:");
if (match.Success)
{
Console.WriteLine($"\tThinking: {match.Groups[1].Value}");
Console.WriteLine($"\tAnswer: {match.Groups[2].Value}");
else
{
Console.WriteLine($"Response: {response.Value.Content}");
}
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Thinking: Okay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.
Answer: The exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.
Model: DeepSeek-R1
Usage:
Prompt tokens: 11
Total tokens: 897
Completion tokens: 886
进行多轮次对话时,避免在聊天历史记录中发送推理内容非常有用,因为推理倾向于生成较长的解释。
流式传输内容
默认情况下,补全 API 会在单个响应中返回整个生成的内容。 如果要生成长补全内容,等待响应可能需要几秒钟时间。
可以流式传输内容,以在生成内容时获取它。 通过流式处理内容,可以在内容可用时开始处理补全。 此模式返回一个对象,该对象将响应作为仅数据服务器发送的事件进行流式传输。 从增量字段(而不是消息字段)中提取区块。
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestUserMessage("How many languages are in the world?")
},
MaxTokens=4096,
Model = "deepseek-r1",
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
若要可视化输出,请定义用于输出流的帮助程序函数。 以下示例实现仅流式传输答案且没有推理内容的路由:
static void PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
bool isThinking = false;
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
string content = chatUpdate.ContentUpdate;
if (content == "<think>")
{
isThinking = true;
Console.Write("🧠 Thinking...");
Console.Out.Flush();
}
else if (content == "</think>")
{
isThinking = false;
Console.WriteLine("🛑\n\n");
}
else if (!string.IsNullOrEmpty(content))
{
Console.Write(content);
Console.Out.Flush();
}
}
}
}
可以直观显示流式处理如何生成内容:
StreamMessageAsync(client).GetAwaiter().GetResult();
参数
一般情况下,推理模型不支持在聊天完成模型中找到的以下参数:
- 温度
- 出现惩罚
- 重复惩罚
- 参数
top_p
某些模型支持使用工具或结构化输出(包括 JSON 架构)。 请参阅“模型”详细信息页,了解每个模型的支持。
应用内容安全
Azure AI 模型推理 API 支持 Azure AI 内容安全。 在启用 Azure AI 内容安全的情况下使用部署时,输入和输出会经过一系列分类模型,旨在检测和防止输出有害内容。 内容筛选系统会在输入提示和输出补全中检测特定类别的潜在有害内容并对其采取措施。
以下示例展示了当模型在输入提示中检测到有害内容且内容安全已启用时如何处理事件。
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
Model = "deepseek-r1",
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
提示
若要详细了解如何配置和控制 Azure AI 内容安全设置,请查看 Azure AI 内容安全文档。
重要
本文中标记了“(预览版)”的项目目前为公共预览版。 此预览版未提供服务级别协议,不建议将其用于生产工作负载。 某些功能可能不受支持或者受限。 有关详细信息,请参阅 Microsoft Azure 预览版补充使用条款。
本文介绍如何使用部署到 Azure AI 模型推理的聊天完成模型在 Azure AI 服务中的推理功能。
推理模型
推理模型可以在数学、编码、科学、策略和物流等领域达到更高的性能水平。 这些模型生成输出的方式是通过明确使用思维链来探索所有可能的路径,然后再生成答案。 他们在产生答案时会对其进行验证,这有助于他们得出更好、更准确的结论。 这意味着推理模型在提示时可能需要更少的上下文来产生有效的结果。
缩放模型性能的这种方式称为“推理计算时间”,因为它以较高的延迟和成本来换取性能。 它与通过“训练计算时间”缩放的其他方法形成鲜明对比。
然后,推理模型生成两种类型的输出:
- 推理完成
- 输出完成
这两个完成都计入模型生成的内容,因此也计入与模型相关的令牌限制和成本。 某些模型可能会输出推理内容,例如 DeepSeek-R1。 其他模型(例如 o1)仅输出完成的输出部分。
先决条件
要完成本教程,需要:
Azure 订阅。 如果你正在使用 GitHub 模型,则可以升级体验并在此过程中创建 Azure 订阅。 如果是这种情况,请阅读从 GitHub 模型升级到 Azure AI 模型推理。
Azure AI 服务资源。 有关详细信息,请参阅创建 Azure AI 服务资源。
终结点 URL 和密钥。
具有推理功能模型部署的模型。 如果没有,请参阅添加并将模型配置为 Azure AI 服务以添加推理模型。
- 此示例使用
DeepSeek-R1。
- 此示例使用
通过聊天使用推理功能
首先,创建客户端以使用模型。 以下代码使用存储在环境变量中的终结点 URL 和密钥。
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
提示
使用 Azure AI 模型推理 API 验证是否已将模型部署到 Azure AI 服务资源。
Deepseek-R1 也可作为无服务器 API 终结点使用。 但是,这些终结点不采用本教程中所述的参数 model。 可以通过转到 Azure AI Foundry 门户> 模型 + 终结点来验证该模型是否列在 Azure AI 服务部分下。
如果已将资源配置为具有 Microsoft Entra ID 支持,请在 Authorization 标头中传递令牌:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
创建聊天补全请求
以下示例演示如何创建对模型的基本聊天请求。
{
"model": "deepseek-r1",
"messages": [
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
生成推理模型的提示时,请考虑以下事项:
- 使用简单的说明,避免使用思维链技巧。
- 内置的推理功能使简单的零次提示和更复杂的方法一样有效。
- 提供其他上下文或文档(例如在 RAG 方案中)时,仅包含最相关的信息可能有助于防止模型过度复杂化其响应。
- 推理模型可能支持使用系统消息。 但是,它们可能不会像其他非推理模型那样严格地遵循它们。
- 创建多轮次应用程序时,请考虑仅追加模型的最终答案,而不考虑按“推理内容”部分所述对内容进行推理。
响应如下所示,可从中查看模型的使用统计信息:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "DeepSeek-R1",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "<think>\nOkay, the user is asking how many languages exist in the world. I need to provide a clear and accurate answer. Let's start by recalling the general consensus from linguistic sources. I remember that the number often cited is around 7,000, but maybe I should check some reputable organizations.\n\nEthnologue is a well-known resource for language data, and I think they list about 7,000 languages. But wait, do they update their numbers? It might be around 7,100 or so. Also, the exact count can vary because some sources might categorize dialects differently or have more recent data. \n\nAnother thing to consider is language endangerment. Many languages are endangered, with some having only a few speakers left. Organizations like UNESCO track endangered languages, so mentioning that adds context. Also, the distribution isn't even. Some countries have hundreds of languages, like Papua New Guinea with over 800, while others have just a few. \n\nA user might also wonder why the exact number is hard to pin down. It's because the distinction between a language and a dialect can be political or cultural. For example, Mandarin and Cantonese are considered dialects of Chinese by some, but they're mutually unintelligible, so others classify them as separate languages. Also, some regions are under-researched, making it hard to document all languages. \n\nI should also touch on language families. The 7,000 languages are grouped into families like Indo-European, Sino-Tibetan, Niger-Congo, etc. Maybe mention a few of the largest families. But wait, the question is just about the count, not the families. Still, it's good to provide a bit more context. \n\nI need to make sure the information is up-to-date. Let me think – recent estimates still hover around 7,000. However, languages are dying out rapidly, so the number decreases over time. Including that note about endangerment and language extinction rates could be helpful. For instance, it's often stated that a language dies every few weeks. \n\nAnother point is sign languages. Does the count include them? Ethnologue includes some, but not all sources might. If the user is including sign languages, that adds more to the count, but I think the 7,000 figure typically refers to spoken languages. For thoroughness, maybe mention that there are also over 300 sign languages. \n\nSummarizing, the answer should state around 7,000, mention Ethnologue's figure, explain why the exact number varies, touch on endangerment, and possibly note sign languages as a separate category. Also, a brief mention of Papua New Guinea as the most linguistically diverse country. \n\nWait, let me verify Ethnologue's current number. As of their latest edition (25th, 2022), they list 7,168 living languages. But I should check if that's the case. Some sources might round to 7,000. Also, SIL International publishes Ethnologue, so citing them as reference makes sense. \n\nOther sources, like Glottolog, might have a different count because they use different criteria. Glottolog might list around 7,000 as well, but exact numbers vary. It's important to highlight that the count isn't exact because of differing definitions and ongoing research. \n\nIn conclusion, the approximate number is 7,000, with Ethnologue being a key source, considerations of endangerment, and the challenges in counting due to dialect vs. language distinctions. I should make sure the answer is clear, acknowledges the variability, and provides key points succinctly.\n</think>\n\nThe exact number of languages in the world is challenging to determine due to differences in definitions (e.g., distinguishing languages from dialects) and ongoing documentation efforts. However, widely cited estimates suggest there are approximately **7,000 languages** globally.",
"tool_calls": null
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 11,
"total_tokens": 897,
"completion_tokens": 886
}
}
推理内容
某些推理模型(如 DeepSeek-R1)会生成补全内容并包含其背后的推理。 与补全关联的推理包含在标记 <think> 和 </think> 内的响应内容中。 此模型可以选择针对哪些场景生成推理内容。
进行多轮次对话时,避免在聊天历史记录中发送推理内容非常有用,因为推理倾向于生成较长的解释。
流式传输内容
默认情况下,补全 API 会在单个响应中返回整个生成的内容。 如果要生成长补全内容,等待响应可能需要几秒钟时间。
可以流式传输内容,以在生成内容时获取它。 通过流式处理内容,可以在内容可用时开始处理补全。 此模式返回一个对象,该对象将响应作为仅数据服务器发送的事件进行流式传输。 从增量字段(而不是消息字段)中提取区块。
若要流式传输补全,请在调用模型时设置 "stream": true。
{
"model": "DeepSeek-R1",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"max_tokens": 2048
}
若要可视化输出,请定义用于输出流的帮助程序函数。 以下示例实现仅流式传输答案且没有推理内容的路由:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "DeepSeek-R1",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
流中的最后一条消息已设置 finish_reason,指示生成进程停止的原因。
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "DeepSeek-R1",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 11,
"total_tokens": 897,
"completion_tokens": 886
}
}
参数
一般情况下,推理模型不支持在聊天完成模型中找到的以下参数:
- 温度
- 出现惩罚
- 重复惩罚
- 参数
top_p
某些模型支持使用工具或结构化输出(包括 JSON 架构)。 请参阅“模型”详细信息页,了解每个模型的支持。
应用内容安全
Azure AI 模型推理 API 支持 Azure AI 内容安全。 在启用 Azure AI 内容安全的情况下使用部署时,输入和输出会经过一系列分类模型,旨在检测和防止输出有害内容。 内容筛选系统会在输入提示和输出补全中检测特定类别的潜在有害内容并对其采取措施。
以下示例展示了当模型在输入提示中检测到有害内容且内容安全已启用时如何处理事件。
{
"model": "DeepSeek-R1",
"messages": [
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
提示
若要详细了解如何配置和控制 Azure AI 内容安全设置,请查看 Azure AI 内容安全文档。