CRM Reporting and SQL 2012 AlwaysOn Availability Groups – Better Together
TheProblem
A common issue that I have come across in CRM deployments, particularly for Enterprise customers, is deadlocking on the SQL server resulting in a degraded performance of our CRM environment.
I’ve experienced severe impact of this deadlocking to the degree that other CRM SQL processes are aborted resulting in errors being presented to the user, or systems integrating with CRM fail to retrieve data – In the early stages of a project and especially post go live, this can have a crippling effect on the user adoption of the new deployment.
More often than not, in my experience, the deadlocks were a result of long running reports and integrations being executed against SQL that could ultimately be better managed.
Wouldn’t it be nice if we could just offload these long running reports and redirect our integration to a second copy of our CRM data, so that we didn’t impact user experience?
PreviousMitigationOptions
To date, I have come across two ways to offload our read only workloads such as reporting or integration (where CRM is the data master). One of these options, Transactional Replication, was always chosen as a last resort over the other, SQL Mirroring, due to some constraints.
If you are reading this post, I will assume you have some knowledge of SQL high availability options such as SQL Mirroring and SQL Transactional Replication. Additionally, this article will not focus on how to create reports so a working knowledge of writing reports using tools such as SQL Data Tools is assumed.
SQLMirroring
This is a common option that I’ve deployed a number of times. As you may know, SQL mirroring requires that the secondary instance database remains in a ‘recovery’ state, thus rendering the database useless until you actually invoke DR or a manual failover. To overcome this need for the database to remain inaccessible, we would implement snapshot technology to produce essentially a 3rd copy of your data, this time in an accessible state which we can use to offload our workloads against.
This solution works well but comes with some limitations. For example, your report data would only be as up to date as your most recent snapshot and snapshots can take some time to produce, depending on the size of your database. Additionally, because we need to implement snapshots, you get yourself into a position where you need enough storage for the 3rd copy of your data. This probably isn’t such an issue with the cost of disk nowadays but if you have a VERY large database, which takes a long time to snapshot and you need to run reports frequently, that would mean that you may need enough storage for a 4th copy of your database so that reports can continue to run against the 3rd whilst the 4th is generated.
SQLTransactionalReplication
I pointed out that this option wouldn’t be something I recommended in the past. This is due to the fact that replication is not officially supported by Microsoft, definitely not something you want to risk. The second problem is that replication depends on a stable schema, so if you did chose to deploy Transactional Replication due to up to date report data requirements, you would need to essentially break replication prior to the deployment of any CRM customizations and then re-establish replication post deployment.
This does add complexity and additional time to your deployment process but transactional replication does help you meet data requirements and provide for more up to date data than SQL Mirroring with Snapshots would - You just need to keep the trade-offs in mind during design and when trying to maintain supportability.
TheSolution
Enter SQL2012. SQL 2012 introduces AlwaysOn Availability Groups. - https://www.microsoft.com/sqlserver/en/us/solutions-technologies/mission-critical-operations/SQL-Server-2012-high-availability.aspx
An Availability Group is essentially a host name that allows you to host a set of primary databases on a single primary replica, you can then host up to four secondary replicas that can be used as failover targets.
Availability Groups are in a way, similar to SQL Mirroring but one of the key differences that we leverage in this solution, is the fact the secondary instances (replicas) can remain in an accessible state. So with this capability and some configuration, we would be able to offload our CRM workloads against a secondary replica.
Configuration
SQLServerAlwaysOnAvailabilityGroups
This blog won’t focus too much on the configuration of SQL but there are some key points that you need to keep in mind. You would need to configure:
- A Availability Group Listener.
- Secondary replicas that would host read only copies of your CRM Organization database.
- Availability Group routing.
The listener is essentially a DNS hostname that you would use when configuring your SQL Server Reporting Server (SSRS) data source connection and the routing tells SQL which secondary replica should handle the incoming connection, depending on whether the connection intent is read-only or read-write.
The trigger that tells SQL what the connection attempt is, is a new parameter within the SQL Native Client 11.0 called Application Intent. So in short, SQL will access all incoming connections on that hostname, access the connection and if it is read-only, route the connection to your secondary replica that you have provisioned for offloading workloads.
After you have created your Availability Group and configured routing, there is a very simple way to test that the routing is working. If you run the SQLCMD below (specifying the –K switch to imply ‘ReadOnly’) and select server name, you will notice that prior to configuring my routing, the connected server is my primary SQL server, ‘APC-SQL1’.
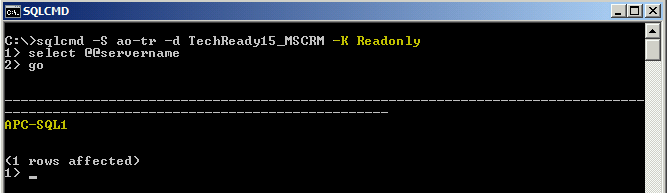
Post routing configuration, if we were to run the same command, we would expect the connected server to be the secondary replica defined whilst creating your AG, as seen below.

CRM &SSRS
Right, so we have tested that our Availability Group and associated routing is working correctly. If I now change roles and become a CRM administrator and the SQL guys had informed me that moving forward, I need to use some new parameters for the data source connection utilized by CRM reports, how would I go about implementing these parameters.
Before we go ahead with this section, we need to keep in mind, some limitations with offloading reports. These aren’t new limitations when comparing to the previous options but worth thinking about.
- FetchXML reports cannot currently be offloaded due to the fact that they connect via web services. The hope is that in future releases of CRM, this will be configurable.
- Related to the 1st, reports created through the CRM UI using report manager, are created by default in FetchXML format. As such, they would need to be recreated by administrators if you identify them as long running reports or that they are causing locking.
- Out the Box reports are created using a special data source that lets SQL know which organization the report is being run against. Again, this is a report that would need to be recreated by administrators if desired.
I have in my test environment, a very simple report created using SQL Data Tools that pulls a list of all accounts currently in CRM. During creation, this report was configured to use a custom data source.
To load this into CRM, we simply navigate to Workspace > Reports and select New from the ribbon. I select to use an Existing File and navigate to my saved report, then click to Save and Close the form.

Doing so will save the report in CRM and SQL Server Reporting Services under Home > ‘MyCRMorg’ > Custom Reports. As mentioned above, the report was created to use a custom data source so the first thing I do is manage this report and change the data source to use a shared data source, in this case, I configure it use the data source in the root of my organization tree in SSRS.
If I were to now run this report from within CRM, the report would run as expected and return a list of my accounts. This is standard functionality where the data is being pulled out of our production CRM database, as shown in this very simple SQL Profile Trace.

What we want to do, is leverage the parameters given to us by our SQL guys to essentially offload our CRM reports to a copy of our CRM database. In order to achieve this, I modify the shared MSCRM_DataSource above, to use these new parameters.

It is important at this stage, to note that the connection string contains two key parts used to connect to our AG secondary replica.
- Data Source = AO-TR. This is the listener that I created during setup of the Availability Group.
- Application Intent = ReadOnly. There are two options for this switch, ReadOnly and ReadWrite. If we were to choose ReadWrite, SQL would simply route the connection to our primary instance. Because we choose ReadOnly, and have the necessary routing defined for the AG, SQL will route the connection to our secondary replica.
Saving this off and rerunning the report, we can see that the select statement using SQL profiler no longer runs against the primary database, instead, it is being offloaded to our secondary replica for processing.

InSummary
To summarize, we have seen how new functionality introduced in SQL Server 2012 can be leveraged to improve the system performance and user experience of CRM 2011. This functionality provides a way to balance the load on SQL Server for CRM.
I see this functionality as being key to how we improve the scalability and performance of CRM Infrastructure for on premise customers however, please be aware that support for this solution is currently non-existent. Always engage the Microsoft Support team before customizing any of the Dynamics CRM reporting components to ensure that your solution is valid.
|
Adam Caulkett Senior Consultant Microsoft Consulting Services UK |

Comments
Anonymous
August 21, 2012
Nice blog Adam - Thanks for the knowledge sharing!Anonymous
October 25, 2013
Just researching how I configure the offloading reports on the internet and what do I find.. my old mate Adam has documented this.. Cool:)Anonymous
October 25, 2013
:) Glad it helped John...