SQL Server chez les clients – Parallel Data Warehouse (PDW)

SQL Server 2012 Parallel Data Warehouse est une Appliance qui offre une puissance de traitement de données exceptionnelles basée sur une architecture dites MPP (Massive Parallel Processing).
Elle permet d’obtenir des performances jusqu’à 100 fois supérieures à un serveur traditionnel.
Elle est capable de gérer des données structurées comme non structurées (notamment avec PolyBase)
Elle est, entre autres, la brique essentielle aux besoins en volume et traitement d’un environnement « Big Data ».
Problématique
- Implémenter un entrepôt de données d’entreprise pouvant stocker une forte volumétrie (plusieurs dizaines de TO).
- Fournir des solutions analytiques adaptées à l’explosion des données structurées et non structurées.
- Pouvoir faire évoluer simplement et à moindre coût une infrastructure en fonction de l’accroissement des besoins de stockage.
Bénéfices
- Des performances exceptionnelles sur de très fortes volumétries grâce au traitement massivement parallèle.
- Une évolutivité jusqu’à 7 Péta-octets.
- Une solution livrée prête à l’emploi (préinstallée et préconfigurée)
Introduction
Le monde des données évolue en permanence, nouveaux types, nouveaux besoins, volumétrie en évolution constante (facteur 10 tous les 5 ans).
Le besoin en analyse de ces données est un chalenge pour l’IT, d’un côté pour répondre à une exigence toujours plus forte de ses utilisateurs (performance, qualité, besoins composites) et de l’autre pour devoir y répondre avec, bien souvent, une gestion maîtrisée des coûts.
 |
SQL Server 2012 Parallel Data Warehouse est une Appliance extrêmement performante, évolutive et à faible coût, elle propose le plus bas prix au téraoctet du marché
Cette Appliance proposée par HP ou DELL peut aisément répondre aux challenges IT d’aujourd’hui et de demain : - Une version SQL Server spécifique pour du traitement massivement parallèle. - De quelques Téraoctets à plusieurs Péta-octets de stockage offrant une haute évolutivité. - Les Appliances sont prêtes à l’emploi et bénéficient :
|
Architecture logique
Voici brièvement comment un PDW est constitué de manière logique.

Constitué de plusieurs types de nœuds voici le rôle de chacun :
“Compute Node” représente autant d’éléments de calcul présents dans l’Appliance. Chaque nœud possède une instance SQL Server 2012 PDW.
“Control Node” représente l’élément fondateur du PDW et par lui transite toutes activités comme nous le verrons par la suite. Il est constitué également d’un SQL Server 2012 PDW et contient une copie « logique et systèmes (métadatas, statistics » de toutes les bases de données présentes sur l’Appliance.
« Management Node » regroupe tous les services de gestion de l’Appliance en elle-même.
L’ensemble de l’Appliance est basé sur Windows Server 2012 et s’appuie sur des services essentiels du système (Cluster, Virtualisation et gestion du stockage).
Les données
Le principe fondateur de PDW est de distribuer les données des tables volumineuses sur l’ensemble des « Compute Nodes » de l’Appliance.
PDW s’appuie de plus sur une version spécifique de SQL Server 2012 qui utilise les indexes « columnstore » pouvant être mis à jour, permettant un haut taux de compression et une performance extrême dans la lecture des données.
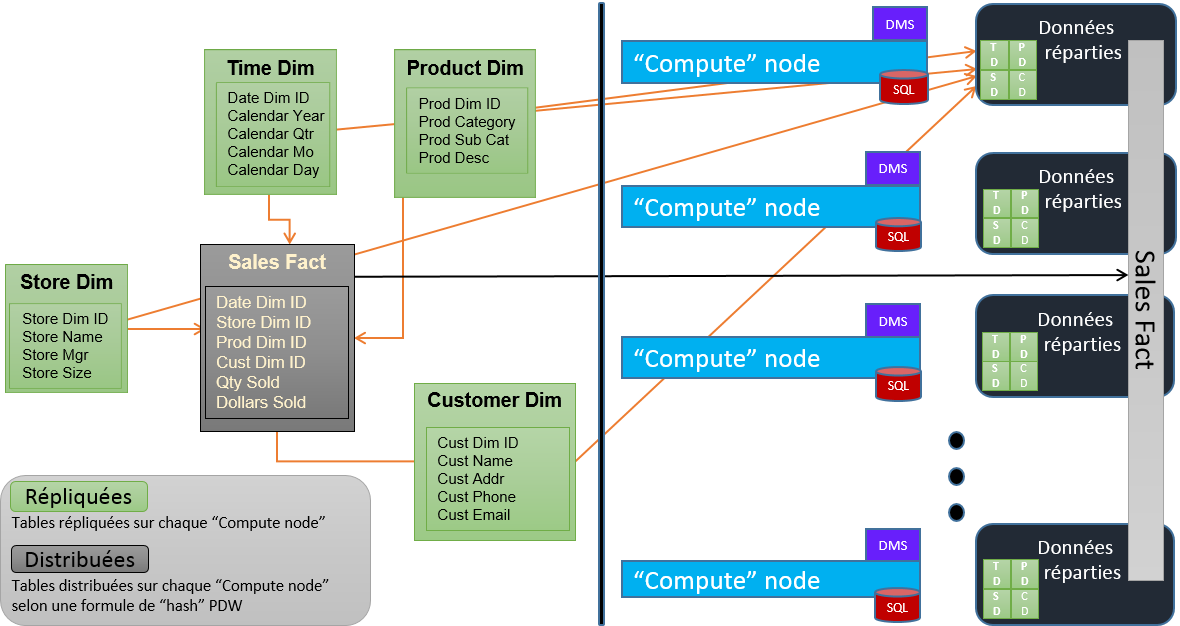
Le découpage d’un modèle type BI pourrait se présenter ainsi :
Les tables les plus volumineuses sont ainsi réparties physiquement sur l’ensemble des « Compute nodes » disponibles selon une formule de Hashage spécifique au PDW.
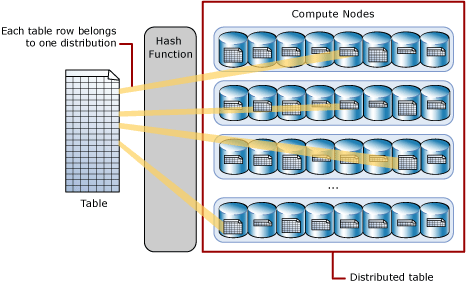
Les tables peu volumineuses sont répliquées (automatiquement et à la création) sur chaque « Compute Node » afin de favoriser la proximité des données et améliorer les performances.
Typiquement une requête utilisateur sera traitée ainsi :

1 – L’utilisateur se connecte sur l’Appliance (Control Node) et soumet sa requête
2- Le « Control node » découpe et analyse la requête et détermine le meilleur plan de requête parallélisée
3- Le moteur PDW du « Control node » distribue alors les sous-requêtes sur chaque « compute node »
4- Chaque « Compute node » exécute sa requête sur ses propres données
5- Dès qu’un “Compute node” termine sa requête il retourne le résultat au “Control node” géré par le DMS
6- Si nécessaire le moteur PDW du « Control node » réalise des agrégations et/ou calculs supplémentaires.
7- Enfin le « Control node » retourne les données à l’utilisateur.
“Data Movement Services (DMS)” représente le cœur névralgique du PDW et assure tous les mouvements de données entre les différents « compute node » puis avec le « control node ».
Chargement de données
Le chargement des données est assuré par un « loader » spécifique qui assure une performance jusqu’à 7 fois plus rapide que sur un environnement classique.
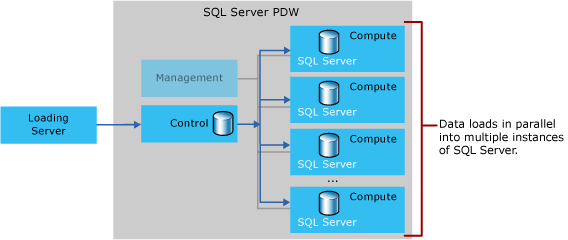
L’alliance « Répartition des données », Indexes « ColumnStore », plusieurs instances SQL travaillant en parallèle et la haute qualité du hardware assure ces performances exceptionnelles du PDW.
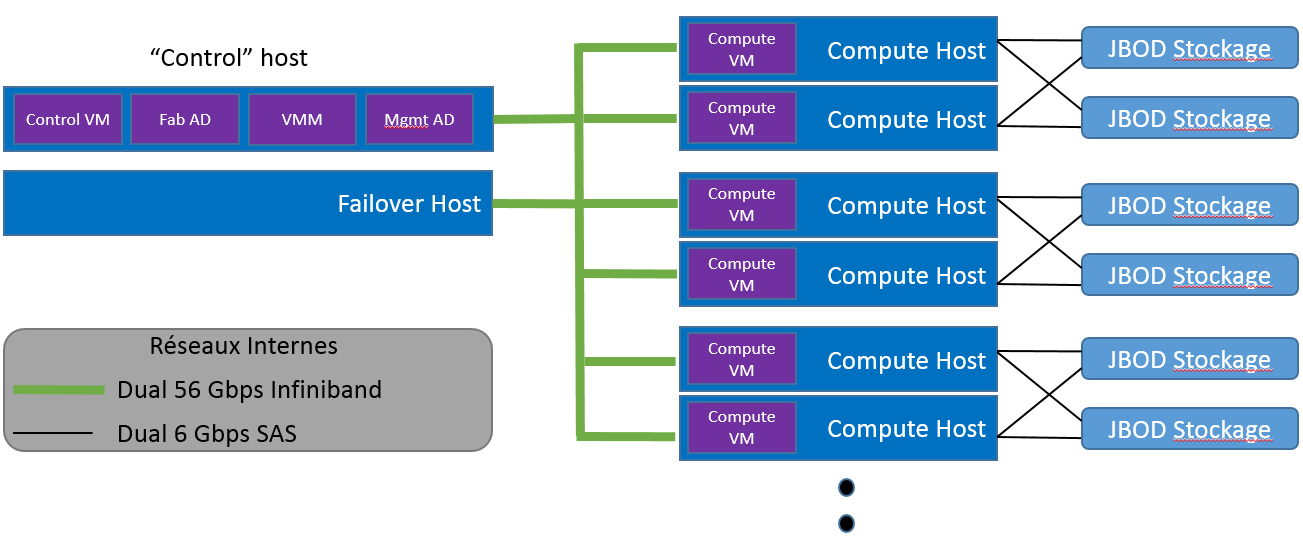
Architecture Physique
L’Appliance s’appuie sur une architecture qui assure performance et haute disponibilité.
Voici schématiquement comment elle se présente :
Système et virtualisation
- Tous les hosts et les services sont virtualisés et utilisent Windows Server 2012
- Control Management (Control VM)
- Compute Nodes (Compute VM)
- Virtual Machine Management (VMM) (gère l’ensemble des images virtuelles et la tolérance de panne)
- Fabric Active Directory (Fab AD) (AD interne, nécessaire pour le cluster et tous les accès entre hosts)
- Management / Active Directory (Mgmt AD) (Support et patch de l’Appliance, WSUS disponible éventuellement)
- Tous les hosts et les services sont placés dans un cluster Hyper-V V3 à deux nœuds (dans sa version standard) :
- Tous les types de host (Control ou Compute) et services peuvent basculer sur le nœud passif
Serveurs
- Tous les serveurs sont équipés de 2 CPU * 8 cores et 256GB RAM
- HP DL360 G8 / Dell Poweredge R620
Stockage (Compute Host) et réseau
- Attachement double canaux Direct SAS JBOD (Just a Bunch Of Disks) (HP – 70 disques / Dell – 102 disques)
- La fonctionnalité de Windows 2012, Storage Spaces, est utilisée pour gérer le stockage (attribution, redondance, swap, etc)
- Clustered Shared Volumes est également utilisé pour gérer le stockage dans le cluster Hyper-V
- L’ensemble de la communication inter serveur est assuré par un réseau Infiniband de très haute performance à 56 Gpbs
- Les liens entre les Compute Nodes et le stockage est quant à lui assurer par un réseau à 6Gbps
Voici une vue physique d’un PDW et son agencement au sein d’un rack (ici de type HP) :

Evolution
Comme nous l’avons déjà précisé, l’évolution en termes de puissance et de stockage est un des avantages de l’Appliance. L’évolution se fait par « quart de rack » pour HP et par « tiers de rack » pour DELL.
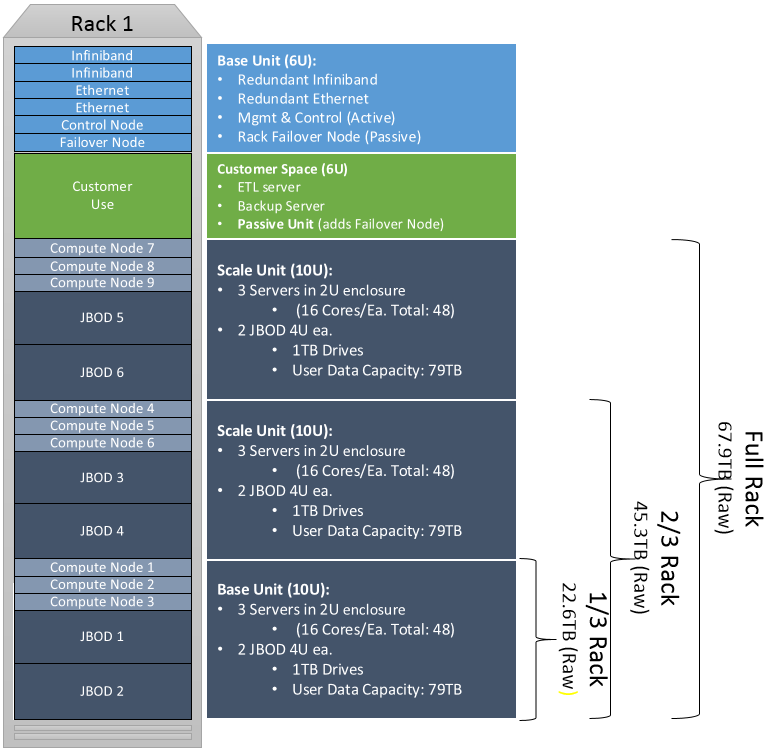
Configuration type pour HP, ici un exemple avec 3 racks complets :
Chaque unité (7U) ajoute 2 « Compute Nodes » et 1 unité de stockage.

Configuration type Dell, ici avec 1 rack complet :
Chaque unité (10U) ajoute 3 « Compute Nodes » et 2 espaces de stockages.
Architectures Applicatives
SQL Server 2012 PDW peut s’inscrire dans plusieurs types d’architecture BI afin de répondre à des scénarii métiers complexes.
Architecture BI de type MOLAP
Placer le Datamart sur un PDW permettrait de gagner en temps de process de cubes complexes et très volumineux, en améliorant drastiquement le temps de lecture des données.
Aucune modification de développement n’est pas à prévoir par contre il faut prévoir que le Serveur SSAS soit dans l’Appliance afin d’être sur le même réseau Infiniband que le PDW.
Architecture BI de type MOLAP vers ROLAP
Il s’agirait dans ce scénario de passer les cubes dans un type de stockage ROLAP (Relationnel OLAP).
Les requêtes « BI » (MDX) seront « transformées » à la volée en requêtes SQL par Analysis Service, requêtes qui s’exécuteront sur le PDW.
Sa puissance peut faire la différence dans plusieurs scénarii et concurrencer les temps de réponses en MOLAP.
Ex : les traitements de type « comptage distinct » sont déportés vers l’architecture MPP (PDW) qui apportent des gains de temps d’exécution significatifs qui s’accentuent avec l’augmentation des volumétries.
De plus ce scénario permettrait de s’affranchir du temps de process des cubes (approche BI temps réel) et de la volumétrie des cubes générés.
Architecture BI de type tabulaire
A l’instar des projets BI de type Multi Dimension en mode ROLAP, l’équivalent en projets BI de type Tabulaire serait d’utiliser le mode Direct Query.
Ainsi les requêtes « BI » (DAX) seront « transformées » en requêtes SQL qui s’exécuteront sur le PDW.
Quand la mémoire nécessaire est trop importante ou les résultats non satisfaisant en mode In-memory, ce type de scénario peut s’envisager.
Autres types
Ce qu’il faut tenir compte c’est le fait qu’un SQL Server 2012 PDW peut se positionner dans une architecture comme un SQL Server « classique », modulo sa puissance et sa volumétrie.
Il peut être source de données SQL dans tous les outils actuels : Report Service, SSIS, SSAS, PowerView, PowerPivot, etc…
L’expertise Microsoft Consulting Services au service de ses clients
Les consultants et architectes de l’équipe MCS SQL/BI sont formés pour mettre en œuvre des projets engageant SQL Server 2012 Parallel Data Warehouse.
MCS travaille déjà étroitement sur plusieurs projets avec des clients dans les domaines de la Banque, Assurance ou Telecom.
Egalement, MCS peut s’appuyer sur des ressources internes pour mener des POC (Proof Of Concept), afin d’éprouver une solution client envisagée avec du PDW :
- Plusieurs Architectes solutions, dont Lionel Pénuchot, au sein du Centre Of Excellence SQL Server PDW, qui ont pour rôle d’aider à la mise en œuvre de POC et de former les partenaires sur PDW.
- Au sein du Microsoft Technology Center (MTC) situé sur le campus d’Issy les Moulineaux, qui mettra à disposition les ressources techniques et logistiques nécessaires.
Pour plus d’informations sur les offres packagées Microsoft Consulting Services, rendez-vous sur https://www.microsoft.com/france/services
Plus d’informations sur les blogs « SQL Server chez les clients ».
 |
Hervé MARIE, Consultant BI/SQL, Microsoft Consulting Services Après une expérience de 9 ans en tant que responsable technique de compte en développement, j’ai rejoint MCS en 2006 pour me spécialiser en SQL Server afin d’accompagner nos clients dans la mise en œuvre d’architecture hautement disponible, d’architecture SQL & BI et des projets de migration Sybase.
|
Comments
- Anonymous
November 13, 2013
Sounds interesting. Could translate your post into English?