Clustered Column Store: Factors that impact size of a RowGroup
Clustered Column Store: Factors that impact size of a RowGroup:
A clustered column store index stores rows in columnar storage format in group of rows, referred to as rowgroups. There are two types of rowgroups as follows:
- Delta rowgroup – stores data in traditional row storage format.
- Compressed rowgroup: stores rows in columnar storage format to get high degree of compression.
The data compression achieved by columnar storage depends upon the number of rows in the rowgroup. In our experimentation, we have found that any rowgroup with 102400+ rows can achieve good column compression. Based on this, the clustered column store index follows these guidelines
- When loading 100k+ rows per batch into column store, the rows are directly loaded as compressed rowgroup
- Regular inserts loads rows into delta rowgroup. When the number of rows reach 1 million (1,048,5766), the rowgroup is closed and converted to columnar storage format by a background thread called tuple mover. Rowgroup with 1 million rows were chosen to strike a balance between too many rowgroups vs too large a rowgroup.
For details please refer to https://msdn.microsoft.com/en-us/library/gg492088(v=sql.120).aspx. Besides the bulk import, the factors that impact the size of rowgroup are
- Degree of parallelism (DOP)
- Size of dictionary
- Memory
Let us walk through each of these factors with examples
Create Index
Here I have a table where I have loaded million rows. Now I create a clustered column store index (CCI) with different DOPs
CREATE TABLE dbo.t_colstore ( c1 int NOT NULL, c2 INT NOT NULL, c3 char(40) NOT NULL, c4 char(1000) NOT NULL) go set nocount on go -- load 2000000 rows declare @outerloop int = 0 declare @i int = 0 while (@outerloop < 2000000) begin Select @i = 0 while (@i < 2000) begin insert t_colstore values (@i + @outerloop, @i + @outerloop, 'a', concat (CONVERT(varchar, @i + @outerloop), 'b')) set @i += 1; end set @outerloop = @outerloop + @i set @i = 0 end go CREATE CLUSTERED COLUMNSTORE INDEX t_colstore_cci ON t_colstore with (maxdop = 1)
Here is what I see for the rowgroup when querying the catalog view sys.colunm_store_row_groups. Note, you have 1 row group with 1 million rows (i.e. 1024 * 1024) and other rowgroup with < 1 million rows because this was the last rowgroup with < 1 million rows. Here is the output using a new DMV in SQL Server 2016. Key things to note are (a) when creating or rebuilding an index, all rows get compressed even if there are < 1 million. This is represented y 'RESIDUAL_ROW_GROUP' state (b) the operation that caused the compression of row group can be identified as 'INDEX_BUOILD here'
[caption id="attachment_3966" align="aligncenter" width="879"] Row Group Size with DOP = 1[/caption]
Row Group Size with DOP = 1[/caption]
Now, let us recreate the index with default DOP (i.e. = 0)
ALTER INDEX t_colstore_cci ON t_colstore REBUILD
[caption id="attachment_3975" align="aligncenter" width="879"] Row Groups with Default DOP[/caption]
Row Groups with Default DOP[/caption]
Here you see one extra rowgroup. This is because multiple threads (depending upon the number of COREs available) are creating rowgroups and they run out of rows before reaching the million rows. One thing to note is that there is no guarantee that each thread will get equal number of rows.
Dictionary size limitation
As part of column compression, a dictionary (primary/secondary) is used to store commonly occurring byte patterns. The dictionary is persisted with compression but the In-Memory size of dictionary is limited to 16MB. The size of rowgroup is automatically reduced if dictionary gets full. Let us walk through an illustrative example using the same table as before but after drop/recreate. In the data load below, notice the distinct prefix for column C4. This creates separate entries, each containing 950 bytes, causing the dictionary to grow larger than 16MB, which forces smaller rowgroups.
drop table t_colstore go CREATE TABLE dbo.t_colstore ( c1 int NOT NULL, c2 INT NOT NULL, c3 char(40) NOT NULL, c4 char(1000) NOT NULL)-- load 1100000 rows declare @outerloop int = 0 declare @i int = 0 while (@outerloop < 1100000) begin Select @i = 0 while (@i < 2000) begin insert t_colstore values (@i + @outerloop, @i + @outerloop, concat(convert(varchar, @I + @outerloop), 'b') set @i += 1; end set @outerloop = @outerloop + @i set @i = 0 end go
Now, I create the CCI as follows and check the rowgroups using the catalog view sys.column_store_row_groups and you will see I have 22 row groups instead of 2 and the trim reason is 'DICTIONARY_SIZE'. It is because the in-memory size of the dictionary can't exceed 16 MB.
CREATE CLUSTERED COLUMNSTORE INDEX t_colstore_cci ON t_colstore with (maxdop = 1)
[caption id="attachment_3985" align="aligncenter" width="1752"]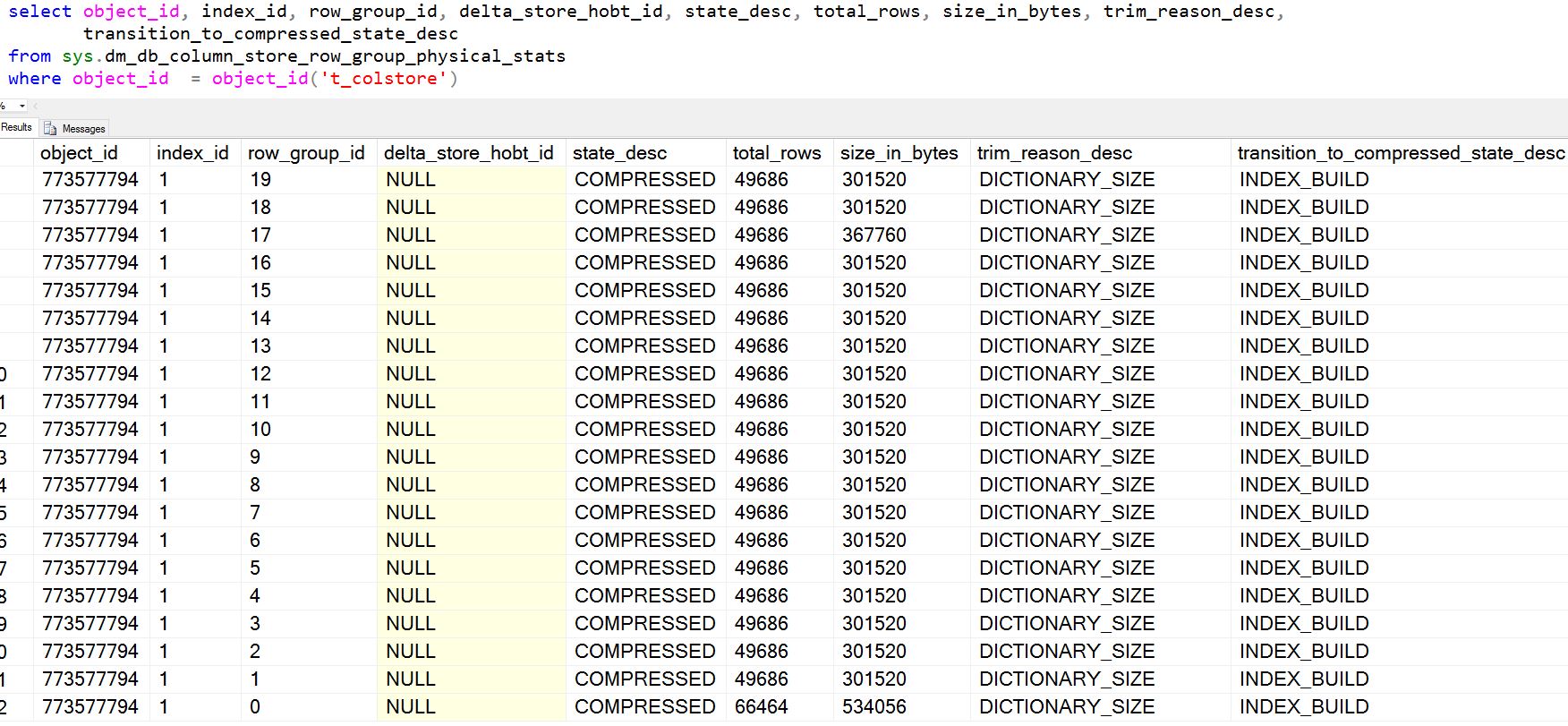 Row Group truncation due to dictionary size[/caption]
Row Group truncation due to dictionary size[/caption]
Now, let us try another variation by loading the 1.1 million rows through delta row groups and see how many compress row groups we get. Here are the additional rowgroups after loading the data.

Note, both of these are delta rowgroups. The closed rowgroup has 1 million rows as you would expect. Why did this not get split into multiple rowgroups due to dictionary? The simple answer is that dictionary is only relevant in the context of compressed rowgroup. Let us run the REORGANIZE command as follows to force compression of the delta rowgroup.
ALTER INDEX t_colstore_cci ON t_colstore REORGANIZE
Here is the output of the catalog view sys.column_store_row_groups. Note, that the closed 'delta' rowgroup' was broken into smaller rowgroups as part of compression

Memory Limitations
When compressing rowgroups, it is required that all the rows in the rowgroup must fit in-memory including the dictionary. If low memory is detected, the server closes the current segment even if the segment row count does not reach 1 million (i.e. leading to smaller sized rowgroup). As part of memory pressure, the index create/rebuild automatically adjusts the DOP to enable successful completion of index create/rebuild.
Thanks
Sunil