微軟開發部門 DevOps 經驗談 (三) - 為 DevOps 量身打造的系統
本文接續:
微軟開發部⾨ DevOps 經驗談 (一) - 從 Agile 邁向 DevOps
微軟開發部門 DevOps 經驗談 (二) - 從經驗中學習
今天要來談的是如何為 DevOps 量身打造系統。
Visual Studio Online 是一個全球性的服務,必須提供 24x7x365 服務不中斷,也保證擁有 99% 的可靠度,甚至還有財務擔保。雖然這些 SLA 上的保證並不是我們產品的最終目標,但為了要讓我們的使用者更安心的使用我們的服務,我們必須至少要提供這樣的穩定性。Visual Studio Online 並不會因為需要維護而有任何的停機時間,也不會發生任何需要重新安裝設定的事情,所有的新功能都是透過更新的方式上線的,過程也是全自動化。這也代表我們服務架構必須要是低耦合性,明確定義服務與服務之間的邊界、溝通方式,以及準確的控制要更新程式碼的版本。為了能夠瞭解客戶的需求,Visual Studio Online 也是運行在 Azure 上,我們完全透過 Azure 所提供的功能來建立這項服務。
自動化部署
我們的開發部門中有一個叫做服務部署 (Service Delivery) 的小團隊,專門處理網站部署工作,以及維持我們服務穩定運行,這個團隊簡稱為 SD。在每個 Sprint 結束後的星期一,SD 會使用 Visual Studio Release Management 來進行部署 (參考圖 1)。通常我們會在上班時間進行新版本的發行,這是因為上線後我們必須要觀察線上運作是否正常,萬一有問題也能即時發現並修正。由於 Visual Studio Online 的服務中儲存了許多客戶的資料,加上資料庫的 Schema 經常更新,所以當遇到異常時,我們不會使用倒退版本 (Rollback) 的作法,來讓服務回復正常,而一律採用修復異常再更新新的版本來修正問題。我們的新版本發行後,也會如同前面所提到的 Canary Relase 流程,自動的從第 0 個擴展單元 (SU0),依序更新到其他的擴展單元,透過這樣的方式,可以讓我們的新版本在提供給所有使用者之前,控制使用新版本的使用者數量,並可以觀察新版本是否運作正常,和收集使用者體驗。

圖 1 、透過 Release Management 控制部署流程,讓新的程式碼按照順序從一個擴展單元 (Scale Unit) 到下一個
要能夠讓一個服務在不停機的狀況下,就進行新版本的更新,是一項十分具有挑戰性的工作,除了表面上的部署流程必須經過精心設計,並且能夠按照部署計畫依序進行之外,我們還必須在開發新功能時,同時考慮與現有程式碼是否相容,甚至與目前的資料庫 Schema 是否能夠相容,這些對於開發人員來說都是一個艱鉅的挑戰。所以如何穩定營運服務的同時,並持續讓開發和部署流程都能夠配合線上的服務,也是我們在未來開發各種新功能時需要不斷關注,並持續改善的課題之一。
遙測技術
在 Visual Studio Online 中最重要的一項功能是遠端偵測 (Telemetry)。就算我們的服務發生問題,我們的監控機制也必須要可以正常運作。一旦我們的服務發生問題了,監控機制會發出警告,儀表版上必須馬上顯示問題所在,圖 2 中呈現了服務的健康狀態。
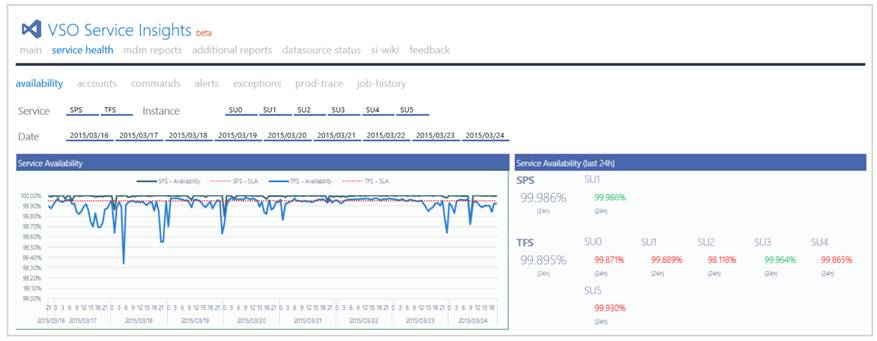
圖 2 、Visaul Studio Online 中使用遠端偵測技術偵測健康狀態的圖表之一
儀表版中的每一個部分都是為了提供 Visaul Studio Online 各種面像的健康狀態,例如可靠度、執行效率、使用量以及是否有異常。我們的遠端偵測主要遵循三個原則。
- 盡可能收集所有面向的資料。
- 盡可能只產生有意義的圖表,而不只是華麗的數據。
- 不僅僅只是收集資料,透過觀察使用者數據的反餽,來了解我們所做的實驗是否有效。
每一天,我們大約會收集 60~150GB 的遠端偵測資料。雖然我們收集的資料可以瞭解每一個帳號的使用狀況,但基於維護使用者的隱私權,所有收集的資料都是匿名的,除非使用者同意我們做進一步分析。以下是一些我們所收集資料的範例。
- 活動記錄- 我們收集所有對 Visual Studio Online 所發送的網路請求。這讓我們可以觀察每一個功能的執行時間以及執行次數,同時可以讓我們判斷是不是有功能或是相關的服務執行太慢,或是經常進行重試。
- 追蹤紀錄- 每一個異常發生時,都會記錄異常程式的呼叫歷程 (call sequence) 以及錯誤堆疊紀錄 (stack trace),方便我們除錯時使用。
- 工作歷史資料 - 每一個工作都是一系列在各服務間的操作所組合而成。
- 效能計數 - 這些計數就像我們平常對程式作效能除錯時,會追蹤系統資源以及健康狀態所使用的效能計數器類似。Visual Studio Online 每天約會產生 50M 的事件記錄。
- Ping Mesh - 這是針對網路基本層級單純的呈現,確保服務可以在世界上每一個地方都能連接到。
- Synthetic Transactions - 這同時也被稱為“外部進入測試”,透過我們的全球服務監控系統來執行,確保我們的服務在世界每個角落都是正常的。
- 使用者用量 - 我們觀察我們的服務入口的使用狀況,轉換樞紐,預測及分析使用量最高的客戶。
- KPI指標 - 這是根據遠端偵測所收集的各種資料統計而成,主要作為判斷目前我們的服務是否正常運作。
追蹤機制
當然,以上的紀錄與資訊都是透過長時間慢慢建置而成的。我們團隊倡導 “ 線上優先” 的文化。也就是說,所有的事情都不會比線上的狀況更重要。當線上服務發生異常時,我們必須將解決問題列為第一優先。我們有一個關於所有狀況的儀表版,每一個人可以看到目前各項工作項目的狀況。
我們會把所有線上異常輸入到 Viusal Studio Online 之中,並追蹤解決問題發生的根本原因,每週也會重新檢視問題的狀況,圖 3 呈現了線上網站問題紀錄的範例。
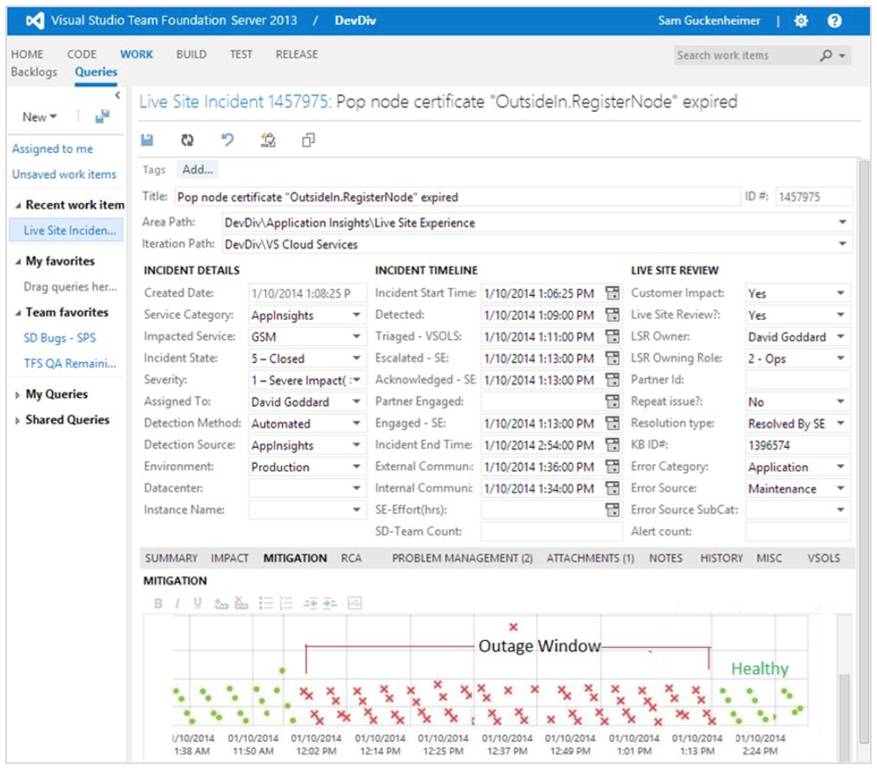
圖 3 、在正式環境的每一個異常狀況都會被詳細的紀錄發生原因,並持續追蹤直到問題解決
徹底解決問題對於營運一個線上服務來說是相當重要的,如果只有在表面上掩飾阻止問題的發生,可能也會在無形中留下了技術債務,而在未來的某個時間點,可能就會引發更加嚴重的異常,必須投入更多資源來解決,因此在問題發生初期就確實的找到根本原因是相當重要的,只有明確的瞭解每一個異常發生的背後意義,才能確保自己服務的健康狀況是可以掌控的。
環環相扣
我們最常被問到關於的 DevOps 問題是, “ 什麼時候該進行下一步?” 。服務部署團隊 (Service Delivery) 是讓我們能夠提供 24x7 服務的第一線維運人員,在全球各地都有這個團隊的成員。當線上有問題發生,服務部署團隊要回報問題給功能開發團隊時,他們會回報給功能開發團隊所指定的負責人 (Designated Responsible Individuals),在上班時間時,我們預期 DRIs 可以在五分鐘內被聯絡到 (例如透過網路電話),而如果在下班時間,也應該會在 15 分鐘內被聯絡到負責人。
我們相當重視徹底解決問題。除了能夠重現問題是如何發生之外,更重要的是找到問題發生的根本原因。我們的作法和豐田汽車 (Toyota) 工廠所採用的看板方法有點類似,每一個工作人員可以從看板上看到問題發生的紀錄,處理問題時也會經過完整的測試,並透過我們的循序部署流程更新到線上,避免問題再度發生,解決問題後的成效也會很快的在我們的線上看板中呈現。
除此之外,對於我們來說最棒的是,我們開發出了一套很好的警報系統,它可以準確的自動判斷服務是否有異常,甚至能夠自動回報 DRIs,不需要透過人力的介入。我們建立了一個關於服務健康的模型,讓它能夠有效過濾不精準、重複的警報訊息,判斷出哪些問題是我們真正需要注意的。如圖 4 所示,在 2015 年二月時,這個模型已經可以提供我們超過 40 個維度的監控指標,所有 P0 和 P1 的警告都可以正確並自動發送給相關人員。

圖 4 、服務健康模型可以自動過濾重複的警告,並且判斷哪一個地方是造成線上服務異常的主要原因
透過自動化的監控機制,除了可以減少人力成本的開銷之外,還能夠大大降低人為誤判的機率,透過收集常有錯誤模式的數據,也可以持續的改善或增強監控機制,讓問題在發生的當下就能夠被警覺,而不是等待使用者回報後才發現自己的服務有異常發生,這也會大大的影響使用者的使用體驗。在收集數據、監控數據指標以及自動通報異常整個流程是一環扣著一環,透過基礎建設的持續改善,才能持續的讓我們服務穩定,而每次問題的發生又相對於提供我們一個新的監控指標,讓下一次發生問題的機率更加的降低,不僅僅只是對於產品本身做到持續改善,更要能夠讓自己的服務營運也能越來越穩定。
TechDays 課程相關推薦 - DevOps 內容開發運維一體化(DevOps)的敏捷九劍!