How to Do Distributed Deep Learning for Object Detection Using Horovod on Azure
This post is co-authored by Mary Wahl, Data Scientist, Xiaoyong Zhu, Program Manager, Siyu Yang, Software Development Engineer, and Wee Hyong Tok, Principal Data Scientist Manager, at Microsoft.
Object detection powers some of the most widely adopted computer vision applications, from people counting in crowd control to pedestrian detection used by self-driving cars. Training an object detection model can take up to weeks on a single GPU, a prohibitively long time for experimenting with hyperparameters and model architectures.
This blog will show how you can train an object detection model by distributing deep learning training to multiple GPUs. These GPUs can be on a single machine or several machines. You will learn how to perform distributed deep learning on Azure, and how you can do this using Horovod running on Azure Batch AI.
Object Detection
Object detection combines the task of classification with localization, outputting both a category and a set of coordinates representing the bounding box for each object that it detects in the image, as illustrated in Figure 1 below.
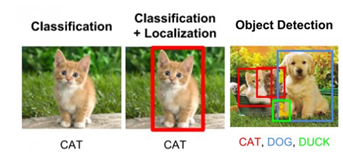
Figure 1. Different computer vision tasks (source)
Over the past few years, many exciting deep learning approaches for object detection have emerged. Models such as Faster R-CNN use a two-stage procedure to first propose regions containing some object followed by classification of the object in each region and adjusting its bounding box. Using a one-stage approach, models such as You Only Look Once (YOLO) and Single Shot MultiBox Detector (SSD), or RetinaNet, consider a fixed set of boxes for detection and skip the region proposal stage. These are a few examples of the array of model architectures available to you for doing object detection.
Instead of taking the raw image as input, these object detection models work off the feature map produced by a backbone network, which is often the convolutional layers of a classification network such as ResNet.
Amongst different object detection techniques, several promising approaches are introduced recently (e.g. Cascade R-CNN and Scale Normalization for Image Pyramids (SNIP)). This paper provides a good overview of the trade-offs between different object detection architectures.
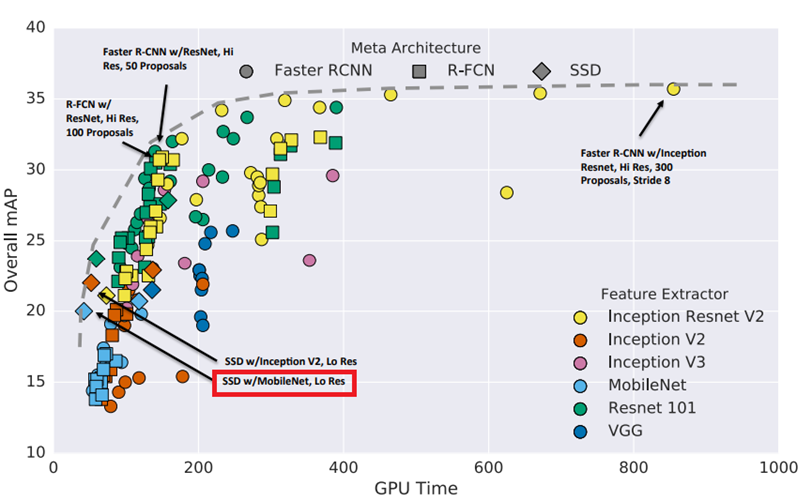
Figure 2. Object Detection Approaches (Tradeoffs between accuracy and inference time).
Marker shapes indicate meta-architecture and colors indicate feature extractor.
Each (meta-architecture, feature extractor) pair corresponds to multiple points on this plot
due to changing input sizes, stride, etc. (source)
Why Distributed Deep Learning?
While in many situations a powerful GPU could carry out model training in a reasonable amount of time, for elaborate models such as object detectors, it can take days or weeks to complete. To make hyperparameter search and rapid iterative experimentations practical, we look to speed up training time by distributing the computation to multiple GPUs in a computer or even across a cluster of computers.
Below we briefly discuss the several ways distributed training can be accomplished, and introduce Horovod, a distributed deep learning framework that can be used with TensorFlow, Keras and PyTorch.
Model Parallelism and Data Parallelism
The gain in speed from distributing training to more than one GPU comes from parallelizing compute operations across multiple processes, each running on a separate GPU, for instance. There are two approaches for doing this.
In the model parallelism approach, the parameters of the model are distributed across multiple devices and one batch of data is processed in each iteration. This is helpful for very large models that cannot fit on a single device. Parallelizing a model requires it to be implemented with the compute resource in mind, and so there is no easy way to rely on a framework to do this for new models or device settings.

Figure 3. Model parallelism
When using data parallelism, the same copy of the training script (a replica) is run on all devices, but each device reads in a different chunk of data at each iteration. The gradients computed by all copies are averaged by some mechanism and the model gets updated.

Figure 4. Data parallelism
Parameter Server vs Ring-Allreduce Algorithm for Gradient Updates
When considering "data parallelism", a key question is how we combine the gradients computed by each replica so that a single model is updated.
In distributed TensorFlow, parameter servers are used to average the gradients. Each process running in a distributed TensorFlow setup play either a worker or a parameter server role. Workers process training data compute the gradients of the model parameters and send them to one or more parameter servers to be averaged, and later obtain a copy of the updated model for the next iteration.
To use this, the training code designed for running on a single GPU needs to be carefully adapted, a rather error prone process. In addition, this distribution often suffers from various scaling inefficiencies, and GPUs are not fully utilized.
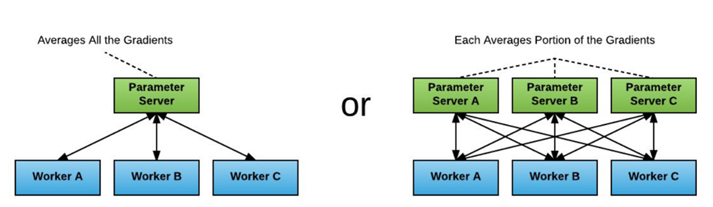
Figure 5. Parameter Server Approach (Source: Horovod Presentation)
A different approach to gradient averaging was popularized by Baidu in early 2017, called ring-allreduce, first implemented as a fork of TensorFlow. In this approach, workers are connected in a ring, communicating with two neighboring workers, and can average gradients and disperse them without a central parameter server. Below is an illustration on how ring-allreduce works.

Figure 6. Ring-allreduce approach
Why Horovod?
A key consideration in distributed deep learning is how to efficiently use the resources that are available (CPUs, GPUs, and more).
Horovod is an open source project initially developed at Uber that implements the ring-allreduce algorithm, first designed for TensorFlow. It provides several advantages when compared to the default TensorFlow implementation:
- The Horovod API enables you to easily convert a training script designed to run on one GPU to a distributed training ready scriptusing a few lines of code. We will demonstrate how to do this in the next section.
- Horovod provides an improvement of training speed by more fully utilizing the GPUs.
Horovod works with different deep learning frameworks: TensorFlow, Keras and PyTorch. Models written using these frameworks can be easily trained on Azure Batch AI, which has native support for Horovod. In addition, Batch AI enables you to train models used for different use cases at scale. The trained models can be deployed to the cloud, or edge devices.
Model Training and Deployment
In this section, you will learn how you can build, train and deploy an object detection model using Azure. We will use the following resources:
- Dataset
- Common Objects in Context (COCO), a canonical object detection dataset.
- Azure Blob Storage to store the dataset for easy access during training and evaluation.
- Technique
- A Keras implementation of the RetinaNet object detector, with a ResNet-50 backbone.
- Horovod for distributed training.
- Azure
- Azure Batch AI, a new Azure service for training models on GPUs with managed infrastructure, with Horovod support.
- Development and deployment tools
- Visual Studio Tools for AI, an extension to let you develop and debug your models in the comfort of the IDE.
- Azure Machine Learning, a suite of services for experiment run history, version control and model management and deployment.
The diagram below illustrates the architecture of our solution. Once the COCO dataset is placed in Azure blob storage, we train a RetinaNet (described below) to perform object detection using Horovod on Azure Batch AI so that training is distributed to multiple GPUs. We then deploy the model as a REST endpoint accessible to users and applications using Azure Machine Learning. Each of these steps is discussed in the following sections.
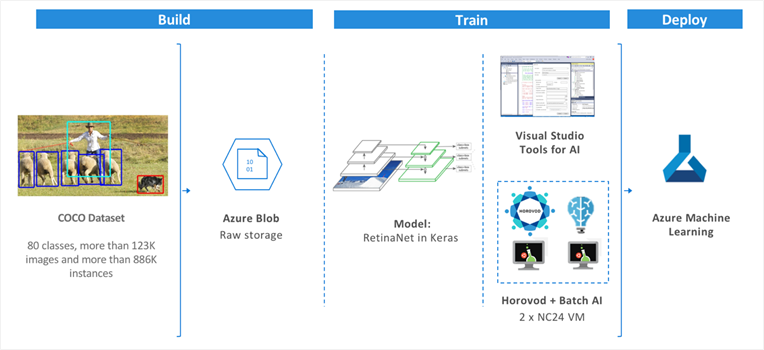
Figure 7. Training an object detection model on Azure
Obtaining the COCO Dataset
COCO (Common Objects in Context) is a commonly used dataset for benchmarking object detection models. The COCO 2017 training and validation sets contain over 120k images representing scenes in everyday life, annotated with bounding boxes labeling 80 classes of common objects such as bicycles and cars, humans and pets, foods, and furniture.
We downloaded the 2017 training and validation images and annotations from the COCO dataset download page, unzipped the files, and used the AzCopy utility to transfer them into a blob container on an Azure Storage Account for fast and easy access during training.

Figure 8. Sample image from the COCO dataset
Azure Batch AI Cluster Deployment
Azure Batch AI is a service that helps users provision and manage clusters of virtual machines for deep learning training jobs. We used the Azure Command Line Interface (CLI) to deploy our Batch AI cluster. to deploy our Batch AI cluster.
We create a cluster containing two Azure Data Science Virtual Machines of size NC24. Each VM has four NVIDIA K80 GPUs, as well as good mix of CPU, memory, and storage resources. During deployment, the Batch AI service coordinates setup tasks that need to be performed on each VM in the cluster. These include:
- Installation of less common Python and Anaconda packages
- Mounting the blob container with our training data
- Ensuring each VM can access a file share on our Azure Storage Account where scripts, logs, and output models will be stored.
After specifying our cluster's configuration, we created the cluster with the following command:
az batchai cluster create -n cocohorovod --image UbuntuDSVM --resource-group yourrgname -c cluster.json
Training RetinaNet Object Detector with Horovod
RetinaNet, an architecture developed by Tsung-Yi Lin and colleagues (2018), is a state-of-the-art object detector that combines the fast inference speed of one-stage detectors with accuracy surpassing that of previous detectors, including those using two-stage approaches. Below is the result on the COCO dataset for multiple architectures, and RetinaNet achieves the highest COCO AP (Average Precision) score with decent inference time.

Figure 9. Performance of RetinaNet using COCO Dataset (Lin et al., 2018)
We adapted an existing implementation of RetinaNet, keras-retinanet, for distributed training using Horovod, with just a handful of modifications to the repository's train.py script. One of the advantages of Horovod is its simplicity: you only need to modify a few lines of your code without touching the rest of the code. Notably, you need to:
- Import the Horovod package
- Configure the number of GPUs visible to Horovod
- Use a distributed optimizer to wrap a regular optimizer, such as Adam
- Add necessary callbacks to avoid conflicts between workers when saving the model
First, we added Horovod import and initialization statements at the top of the script:
import horovod.keras as hvd
hvd.init()
We also modified the method that defines the TensorFlow session's configuration, so that each running instance of the script would be assigned one GPU by Horovod:
def get_session():
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
config.gpu_options.visible_device_list = str(hvd.local_rank())
return tf.Session(config=config)
Then, we wrapped the script's parameter optimizer (Adam) with Horovod's distributed optimizer, to coordinate training between workers:
training_model.compile(
loss={
'regression' : losses.smooth_l1(),
'classification': losses.focal()},
optimizer=hvd.DistributedOptimizer(
keras.optimizers.adam(lr=1e-5, clipnorm=0.001)))
And finally, we replaced the script's callback for saving model checkpoints with versions recommended for Horovod:
callbacks = [hvd.callbacks.BroadcastGlobalVariablesCallback(0)]
if hvd.rank() == 0: # only one worker saves the checkpoint file
callbacks.append(keras.callbacks.ModelCheckpoint('./checkpoint-{epoch:02d}.h5'))
With these simple modifications, the script is ready for distributed training with Horovod. We uploaded the modified script to our storage account's file share so that it can be accessed by our Batch AI cluster during training.
Training with keras-retinanet
We used Azure Batch AI to create a training job using all eight available GPUs on our cluster. The training job configuration file, based on the Horovod recipe in the Azure Batch AI repository, specifies the arguments used to call the training script as well as where trained models and logs will be stored. The job is launched from the Azure CLI with the following command:
az batchai job create -n trainingjob -r xviewhorovod -c job.json
This eight-worker job ran at a rate of one epoch every 670 seconds, roughly 7.2times faster than when a single GPU was used:

Figure 10. Mean training epoch length vs. number of workers (GPUs)
We were able to monitor the logs from the Azure CLI using a streaming view. We simply specify the name of the job, the directory of interest (in our case, the directory where stdout and stderr are written), and the name of the file to view:
az batchai job stream-file -d stdOutErr -j trainingjob -n stdout.txt
We can also list the output trained models and checkpoint files directly from the CLI, including a URL to download each file:
az batchai job list-files -n trainingjob -d outputfiles
Use Visual Studio Tools for AI to Submit Jobs to Batch AI
Once the cluster is configured, we can use Visual Studio Tools for AI to submit jobs to the Batch AI cluster instead of using CLI commands. This allows the developer to use IDE features in Visual Studio, such as IntelliSense, and to take advantage of the easily scalable compute resources of the cloud.

Figure 11. Using Visual Studio Tools for AI to submit keras-retinanet training jobs to Batch AI
Using Azure Machine Learning to Operationalize the Object Detection Model
Azure Machine Learning services enable models to be operationalized as REST endpoints that can be consumed by your applications and other users.
To do this, we can use Azure CLI and specify the required configurations using the Azure Machine Learning (AML) operationalization module, as follows:
az ml service create realtime -f score.py --model-file model.pkl -s service_schema.json -n coco_retinanet -r python --collect-model-data true -c aml_config\conda_dependencies.yml
In this specific case for keras-retinanet, we need to convert the model checkpoint file (which contains only the layers which were updated during training) to an inference model with all model layers present. This is done as follows:
keras_retinanet/bin/convert_model.py /path/to/training/model.h5 /path/to/save/inference/model.h5
Summary
In this blog post, we showed you how to do distributed deep learning using Horovod on Azure. We walked through training a RetinaNet object detector on the COCO dataset, with distributed training enabled through Horovod and Batch AI. In subsequent blogs, we will share results of our experiments with different models and training schemes. If you have questions or comments, please leave a message on our GitHub repository.
Mary, Xiaoyong, Siyu & Wee Hyong
Acknowledgements
- We would like to thank Mathew Salvaris, Ilia Karmanov, and Miguel Fierro from Microsoft who shared their insights into distributed training and Horovod.