Connections To Azure Role Not Getting Load Balanced Between Instances
Lot of times during testing a Cloud Service Role deployed on Microsoft Azure, users feel that the calls are not getting load balanced. The issue may manifest in one of the following or a mix of them.
1. All requests coming from a client are received by a single instance. The second instance is not receiving any calls.
2. Only when multiple clients are used the second instance gets calls (sometimes).
3. Also when these calls show up on the second instance it seems all the calls for these clients have ended up on the second instance.
4. Each call from a specific client always ends up on the same machine.
On the face of it, it appears that instead of having a round robin strategy there is some kind of sticky session present.
Schematically the test bed may look as below when one client is used to call the Cloud Service.

If we RDP to the Instances and look at the services we may something as below.

Then we move on to two clients and we will see something as below. Calls from Client 1 go to Instance 0 and all calls from Client 2 go to Instance 1. 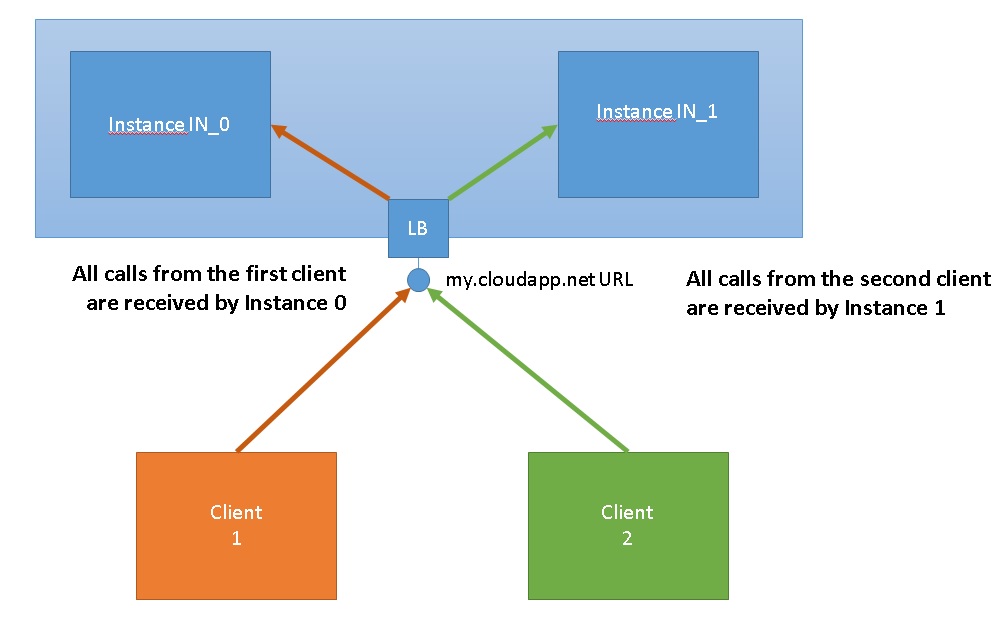
If we RDP to the Instances, we can see the actual calls as below. So all calls from Client 1 land up with Instance 0 and all calls from Client 2 land up with Instance 1. 
If most of the load goes to a single instance, the number one reason is due to the testing client creating and reusing the same TCP connections. The Azure loadbalancer does round robin load balancing for new incoming TCP connections, not for new incoming HTTP requests. So when a client makes the first request to the cloudapp.net URL, the LB sees an incoming TCP connection and routes it to the next instance in the LB rotation, and then the TCP connection is established between the client and the server. Depending on the client app, all future HTTP traffic from that client will may go over the same TCP connection or a new TCP connection. Since in the above cases the HTTP connections were rapidly opened and made a trivial request they all went over the same TCP connection. In order to balance traffic across other Azure role instances the client must break the TCP connection and reestablish a new TCP connection. Load balancing HTTP requests would lead to existing TCP connections getting killed and new ones getting created. TCP process creation is a resource intensive process hence reusing the came TCP channel for subsequent HTTP requests is an efficient use of the channel.
If the client application is modified to make new TCP connection instead of HTTP requests (you can use multiple browser instances on the same client machine) then the TCP requests will end up on either Azure Instance in a round robin fashion.
So depending on how the clients are establishing TCP connections, requests may be routed to the same instance.
Excerpt from the article - https://azure.microsoft.com/en-us/blog/azure-load-balancer-new-distribution-mode/
The distribution algorithm used is a 5 tuple (source IP, source port, destination IP, destination port, protocol type) hash to map traffic to available servers. It provides stickiness only within a transport session. Packets in the same TCP or UDP session will be directed to the same datacenter IP (DIP) instance behind the load balanced endpoint. When the client closes and re-opens the connection or starts a new session from the same source IP, the source port changes and causes the traffic to go to a different DIP endpoint.
Angshuman Nayak, Microsoft
Comments
- Anonymous
September 11, 2014
Great finding. Solves the mystery for me. Thanks. - Anonymous
September 30, 2016
Not sure why not just round robin...