Running Apache Pig (Pig Latin) at Apache Hadoop on Windows Azure
Microsoft Distribution of Apache Hadoop comes with Pig Support along with an Interactive JavaScript shell where users can run their Pig queries immediately without adding specific configuration. The Apache distribution running on Windows Azure has built in support to Apache Pig.
Apache Pig is a platform for analyzing large data sets that consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets.
At the present time, Pig's infrastructure layer consists of a compiler that produces sequences of Map-Reduce programs, for which large-scale parallel implementations already exist (e.g., the Hadoop subproject). Pig's language layer currently consists of a textual language called Pig Latin, which has the following key properties:
- Ease of programming: It is trivial to achieve parallel execution of simple, "embarrassingly parallel" data analysis tasks. Complex tasks comprised of multiple interrelated data transformations are explicitly encoded as data flow sequences, making them easy to write, understand, and maintain.
- Optimization opportunities: The way in which tasks are encoded permits the system to optimize their execution automatically, allowing the user to focus on semantics rather than efficiency.
- Extensibility: Users can create their own functions to do special-purpose processing.
Apache Pig has two execution modes or exectypes:
- Local Mode: - To run Pig in local mode, you need access to a single machine; all files are installed and run using your local host and file system. Specify local mode using the -x flag (pig -x local).
Example:
$ pig -x local
$ pig
- Mapreduce Mode: - To run Pig in mapreduce mode, you need access to a Hadoop cluster and HDFS installation. Mapreduce mode is the default mode; you can, but don't need to, specify it using the -x flag (pig OR pig -x mapreduce).
Example:
$ pig -x mapreduce
You can run Pig in either mode using the "pig" command (the bin/pig Perl script) or the "java" command (java -cp pig.jar ...). To learn more about Apache Pig please click here.
After you have configured your Hadoop Cluster on Windows Azure, you can remote login to your Hadoop Cluster. To run Pig scripts you can copy sample pig files at the C:\Apps\dist\pig folder from the link here:
Now, you can launch the Hadoop Command Line Shortcut and run the command as below:
cd c:\apps\dist\examples\pig
hadoop fs -copyFromLocal excite.log.bz2 excite.log.bz2
C:\Apps\dist\pig>pig
grunt> run script1-hadoop.pig
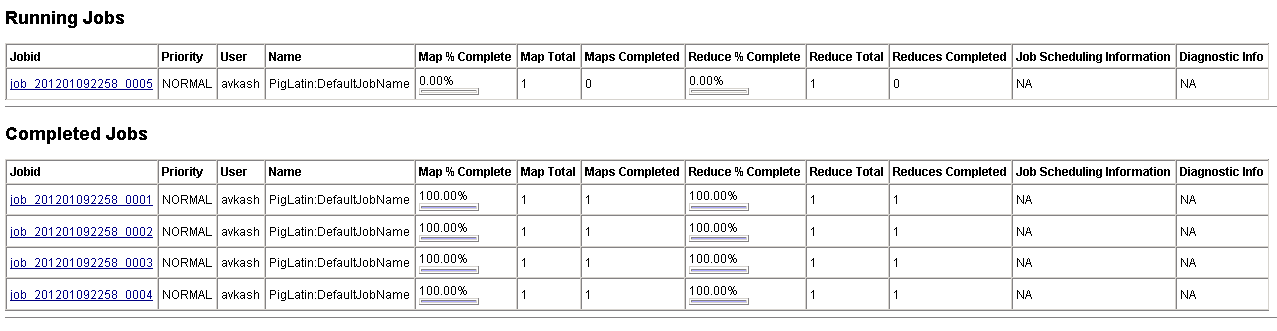
Once the Job has started you can see the job details at Job Tracker (https://localhost:50030/jobtracker.jsp)
script1-hadoop.pig:
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * https://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */
-- Query Phrase Popularity (Hadoop cluster)
-- This script processes a search query log file from the Excite search engine and finds search phrases that occur with particular high frequency during certain times of the day.
-- Register the tutorial JAR file so that the included UDFs can be called in the script. REGISTER ./tutorial.jar;
-- Use the PigStorage function to load the excite log file into the “raw” bag as an array of records. -- Input: (user,time,query) raw = LOAD 'excite.log.bz2' USING PigStorage('\t') AS (user, time, query);
-- Call the NonURLDetector UDF to remove records if the query field is empty or a URL. clean1 = FILTER raw BY org.apache.pig.tutorial.NonURLDetector(query);
-- Call the ToLower UDF to change the query field to lowercase. clean2 = FOREACH clean1 GENERATE user, time, org.apache.pig.tutorial.ToLower(query) as query;
-- Because the log file only contains queries for a single day, we are only interested in the hour. -- The excite query log timestamp format is YYMMDDHHMMSS. -- Call the ExtractHour UDF to extract the hour (HH) from the time field. houred = FOREACH clean2 GENERATE user, org.apache.pig.tutorial.ExtractHour(time) as hour, query;
-- Call the NGramGenerator UDF to compose the n-grams of the query. ngramed1 = FOREACH houred GENERATE user, hour, flatten(org.apache.pig.tutorial.NGramGenerator(query)) as ngram;
-- Use the DISTINCT command to get the unique n-grams for all records. ngramed2 = DISTINCT ngramed1;
-- Use the GROUP command to group records by n-gram and hour. hour_frequency1 = GROUP ngramed2 BY (ngram, hour);
-- Use the COUNT function to get the count (occurrences) of each n-gram. hour_frequency2 = FOREACH hour_frequency1 GENERATE flatten($0), COUNT($1) as count;
-- Use the GROUP command to group records by n-gram only. -- Each group now corresponds to a distinct n-gram and has the count for each hour. uniq_frequency1 = GROUP hour_frequency2 BY group::ngram;
-- For each group, identify the hour in which this n-gram is used with a particularly high frequency. -- Call the ScoreGenerator UDF to calculate a "popularity" score for the n-gram. uniq_frequency2 = FOREACH uniq_frequency1 GENERATE flatten($0), flatten(org.apache.pig.tutorial.ScoreGenerator($1));
-- Use the FOREACH-GENERATE command to assign names to the fields. uniq_frequency3 = FOREACH uniq_frequency2 GENERATE $1 as hour, $0 as ngram, $2 as score, $3 as count, $4 as mean;
-- Use the FILTER command to move all records with a score less than or equal to 2.0. filtered_uniq_frequency = FILTER uniq_frequency3 BY score > 2.0;
-- Use the ORDER command to sort the remaining records by hour and score. ordered_uniq_frequency = ORDER filtered_uniq_frequency BY hour, score;
-- Use the PigStorage function to store the results. -- Output: (hour, n-gram, score, count, average_counts_among_all_hours) STORE ordered_uniq_frequency INTO 'script1-hadoop-results' USING PigStorage(); |
The full output of the Job as below:
c:\Apps\dist\pig>pig 2012-01-10 07:22:23,273 [main] INFO org.apache.pig.Main - Logging error messages to: c:\Apps\dist\pig\pig_1326180143273.log 2012-01-10 07:22:23,695 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://10.2 8.202.165:9000 2012-01-10 07:22:24,070 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to map-reduce job tracker at: 10.28.2 02.165:9010 grunt> run script1-hadoop.pig grunt> /* grunt> * Licensed to the Apache Software Foundation (ASF) under one grunt> * or more contributor license agreements. See the NOTICE file grunt> * distributed with this work for additional information grunt> * regarding copyright ownership. The ASF licenses this file grunt> * to you under the Apache License, Version 2.0 (the grunt> * "License"); you may not use this file except in compliance grunt> * with the License. You may obtain a copy of the License at grunt> * grunt> * https://www.apache.org/licenses/LICENSE-2.0 grunt> * grunt> * Unless required by applicable law or agreed to in writing, software grunt> * distributed under the License is distributed on an "AS IS" BASIS, grunt> * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. grunt> * See the License for the specific language governing permissions and grunt> * limitations under the License. grunt> */ grunt> grunt> -- Query Phrase Popularity (Hadoop cluster) grunt> grunt> -- This script processes a search query log file from the Excite search engine and finds search phrases that occur with particular high frequen cy during certain times of the day. grunt> grunt> grunt> -- Register the tutorial JAR file so that the included UDFs can be called in the script. grunt> REGISTER ./tutorial.jar; grunt> grunt> -- Use the PigStorage function to load the excite log file into the ôrawö bag as an array of records. grunt> -- Input: (user,time,query) grunt> raw = LOAD 'excite.log.bz2' USING PigStorage('\t') AS (user, time, query); grunt> grunt> grunt> -- Call the NonURLDetector UDF to remove records if the query field is empty or a URL. grunt> clean1 = FILTER raw BY org.apache.pig.tutorial.NonURLDetector(query); grunt> grunt> -- Call the ToLower UDF to change the query field to lowercase. grunt> clean2 = FOREACH clean1 GENERATE user, time, org.apache.pig.tutorial.ToLower(query) as query; grunt> grunt> -- Because the log file only contains queries for a single day, we are only interested in the hour. grunt> -- The excite query log timestamp format is YYMMDDHHMMSS. grunt> -- Call the ExtractHour UDF to extract the hour (HH) from the time field. grunt> houred = FOREACH clean2 GENERATE user, org.apache.pig.tutorial.ExtractHour(time) as hour, query; grunt> grunt> -- Call the NGramGenerator UDF to compose the n-grams of the query. grunt> ngramed1 = FOREACH houred GENERATE user, hour, flatten(org.apache.pig.tutorial.NGramGenerator(query)) as ngram; grunt> grunt> -- Use the DISTINCT command to get the unique n-grams for all records. grunt> ngramed2 = DISTINCT ngramed1; grunt> grunt> -- Use the GROUP command to group records by n-gram and hour. grunt> hour_frequency1 = GROUP ngramed2 BY (ngram, hour); grunt> grunt> -- Use the COUNT function to get the count (occurrences) of each n-gram. grunt> hour_frequency2 = FOREACH hour_frequency1 GENERATE flatten($0), COUNT($1) as count; grunt> grunt> -- Use the GROUP command to group records by n-gram only. grunt> -- Each group now corresponds to a distinct n-gram and has the count for each hour. grunt> uniq_frequency1 = GROUP hour_frequency2 BY group::ngram; grunt> grunt> -- For each group, identify the hour in which this n-gram is used with a particularly high frequency. grunt> -- Call the ScoreGenerator UDF to calculate a "popularity" score for the n-gram. grunt> uniq_frequency2 = FOREACH uniq_frequency1 GENERATE flatten($0), flatten(org.apache.pig.tutorial.ScoreGenerator($1)); grunt> grunt> -- Use the FOREACH-GENERATE command to assign names to the fields. grunt> uniq_frequency3 = FOREACH uniq_frequency2 GENERATE $1 as hour, $0 as ngram, $2 as score, $3 as count, $4 as mean; grunt> grunt> -- Use the FILTER command to move all records with a score less than or equal to 2.0. grunt> filtered_uniq_frequency = FILTER uniq_frequency3 BY score > 2.0; grunt> grunt> -- Use the ORDER command to sort the remaining records by hour and score. grunt> ordered_uniq_frequency = ORDER filtered_uniq_frequency BY hour, score; grunt> grunt> -- Use the PigStorage function to store the results. grunt> -- Output: (hour, n-gram, score, count, average_counts_among_all_hours) grunt> STORE ordered_uniq_frequency INTO 'script1-hadoop-results' USING PigStorage(); 2012-01-10 07:22:48,614 [main] WARN org.apache.pig.PigServer - Encountered Warning USING_OVERLOADED_FUNCTION 3 time(s). 2012-01-10 07:22:48,614 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig features used in the script: GROUP_BY,ORDER_BY,DISTINCT,FILTER 2012-01-10 07:22:48,614 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - pig.usenewlogicalplan is set to true. New logica l plan will be used. 2012-01-10 07:22:48,958 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - (Name: ordered_uniq_frequency: Store(hdfs://10.2 8.202.165:9000/user/avkash/script1-hadoop-results:PigStorage) - scope-71 Operator Key: scope-71) 2012-01-10 07:22:48,989 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MRCompiler - File concatenation threshold: 100 optim istic? false 2012-01-10 07:22:49,083 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.CombinerOptimizer - Choosing to move algebraic forea ch to combiner 2012-01-10 07:22:49,192 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size before optimizati on: 5 2012-01-10 07:22:49,192 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MultiQueryOptimizer - MR plan size after optimizatio n: 5 2012-01-10 07:22:49,349 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job 2012-01-10 07:22:49,364 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buf fer.percent is not set, set to default 0.3 2012-01-10 07:22:50,536 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting up single store job 2012-01-10 07:22:50,536 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Setting identity combiner class . 2012-01-10 07:22:50,552 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - BytesPerReducer=1000000000 maxR educers=999 totalInputFileSize=10408717 2012-01-10 07:22:50,552 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - Neither PARALLEL nor default pa rallelism is set for this job. Setting number of reducers to 1 2012-01-10 07:22:50,646 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 1 map-reduce job(s) waiting for submission. 2012-01-10 07:22:51,145 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 0% complete 2012-01-10 07:22:51,349 [Thread-6] INFO org.apache.hadoop.mapreduce.lib.input.FileInputFormat - Total input paths to process : 1 2012-01-10 07:22:51,364 [Thread-6] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths to process : 1 2012-01-10 07:22:51,380 [Thread-6] INFO org.apache.pig.backend.hadoop.executionengine.util.MapRedUtil - Total input paths (combined) to process : 1 2012-01-10 07:22:52,661 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - HadoopJobId: job_201201092258_00 01 2012-01-10 07:22:52,661 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - More information at: https://10.2 8.202.165:50030/jobdetails.jsp?jobid=job_201201092258_0001 2012-01-10 07:23:59,655 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-10 07:24:02,655 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-10 07:24:07,655 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-10 07:24:12,654 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-10 07:24:17,654 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-10 07:24:22,653 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 10% complete 2012-01-10 07:24:23,653 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 13% complete 2012-01-10 07:24:26,653 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 16% complete 2012-01-10 07:24:27,653 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 16% complete 2012-01-10 07:24:42,652 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 19% complete 2012-01-10 07:24:57,229 [main] INFO org.apache.pig.tools.pigstats.ScriptState - Pig script settings are added to the job 2012-01-10 07:24:57,229 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.JobControlCompiler - mapred.job.reduce.markreset.buf fer.percent is not set, set to default 0.3 ….. ….. ….. 05 2012-01-10 07:29:07,411 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - More information at: https://10.2 8.202.165:50030/jobdetails.jsp?jobid=job_201201092258_0005 2012-01-10 07:29:36,487 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 90% complete 2012-01-10 07:29:51,501 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 93% complete 2012-01-10 07:30:12,171 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete 2012-01-10 07:30:12,187 [main] INFO org.apache.pig.tools.pigstats.PigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features 0.20.203.1-SNAPSHOT 0.8.1-SNAPSHOT avkash 2012-01-10 07:22:49 2012-01-10 07:30:12 GROUP_BY,ORDER_BY,DISTINCT,FILTER
Success!
Job Stats (time in seconds): JobId Maps Reduces MaxMapTime MinMapTIme AvgMapTime MaxReduceTime MinReduceTime AvgReduceTime Alias Feature Outputs job_201201092258_0001 1 1 54 54 54 39 39 39 clean1,clean2,houred,ngramed1,raw DISTINCT job_201201092258_0002 1 1 39 39 39 30 30 30 hour_frequency1,hour_frequency2 GROUP_BY,COMBINER job_201201092258_0003 1 1 18 18 18 24 24 24 filtered_uniq_frequency,uniq_frequency1,uniq_frequency2,uniq_f requency3 GROUP_BY job_201201092258_0004 1 1 12 12 12 21 21 21 ordered_uniq_frequency SAMPLER job_201201092258_0005 1 1 12 12 12 21 21 21 ordered_uniq_frequency ORDER_BY hdfs://10.28.202.165:9 000/user/avkash/script1-hadoop-results,
Input(s): Successfully read 944954 records (10409087 bytes) from: "hdfs://10.28.202.165:9000/user/avkash/excite.log.bz2"
Output(s): Successfully stored 13528 records (659755 bytes) in: "hdfs://10.28.202.165:9000/user/avkash/script1-hadoop-results"
Counters: Total records written : 13528 Total bytes written : 659755 Spillable Memory Manager spill count : 0 Total bags proactively spilled: 0 Total records proactively spilled: 0
Job DAG: job_201201092258_0001 -> job_201201092258_0002, job_201201092258_0002 -> job_201201092258_0003, job_201201092258_0003 -> job_201201092258_0004, job_201201092258_0004 -> job_201201092258_0005, job_201201092258_0005
2012-01-10 07:30:12,296 [main] WARN org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Encountered Warning ACCESSING_NO N_EXISTENT_FIELD 14 time(s). 2012-01-10 07:30:12,296 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success! grunt> |
Resources:
- Apache Hadoop on Windows Azure Technet WiKi
- Keywords: Apache Hadoop, Windows Azure, BigData, Cloud, MapReduce
Comments
- Anonymous
June 26, 2013
Greate tutorial sir I get all thing which I am searching for