计算组
适用于: SQL Server 2019 及更高版本的 Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server 2019 及更高版本的 Analysis Services Azure Analysis Services Fabric/Power BI Premium
通过将常见度量值表达式分组为“计算项”,计算组可显著减少冗余度量值的数量 。 1500 和更高 兼容级别的表格模型中支持计算组。
好处
计算组解决了复杂模型中可能使用相同的计算出现冗余度量值激增的问题-最常见的是时间智能计算。 例如,销售分析师想要按每月迄今为止查看总销售额和订单, (MTD) 、季度 (QTD) 、今年至今 (YTD) 、上一年度的订单 (PY) 等。 数据建模器必须为每个计算创建单独的度量值,这可能会导致数十个度量值。 对于用户来说,这可能意味着必须对同样多的度量值进行排序,并将它们单独应用于报表。
让我们先看看计算组在 Power BI 等报表工具中向用户显示的方式。 然后,我们将了解计算组的构成,以及如何在模型中创建计算组。
计算组在报告客户端中作为具有单个列的表显示。 该列不像典型的列或维度,而是表示一个或多个可重用的计算,或者可应用于任何已添加到可视化效果的“值”筛选器的度量值的 计算项 。
在以下动画中,用户正在分析 2012 年和 2013 年的销售数据。 在应用计算组之前,通用基本度量值 Sales 会计算每月总销售额的总和。 然后,用户想要应用时间智能计算来获取月份至今、季度至今、年份至今等的销售总额。 如果没有计算组,用户必须选择单独的时间智能度量值。
对于名为 “时间智能”的计算组,当用户将 “时间计算 ”项拖到 “列” 筛选器区域时,每个计算项将显示为单独的列。 每行的值根据基本度量值 Sales 进行计算。
计算组使用 显式 DAX 度量值。 在此示例中, Sales 是已在模型中创建的显式度量值。 计算组不适用于隐式 DAX 度量值。 例如,在 Power BI 中,当用户将列拖到视觉对象上以查看聚合值时,将创建隐式度量值,而无需创建显式度量值。 此时,Power BI 为作为内联 DAX 计算编写的隐式度量值生成 DAX ,这意味着隐式度量值不能与计算组一起使用。 引入了表格对象模型 (TOM) 中可见的新模型属性 ,即“化气对象模型”。 目前,若要创建计算组,必须将此属性设置为 true。 如果设置为 true,则Live Connect模式下的Power BI Desktop将禁用隐式度量值的创建。
计算组还支持多维数据表达式 (MDX) 查询。 这意味着,使用 MDX 查询表格数据模型的 Microsoft Excel 用户可以充分利用工作表数据透视表和图表中的计算组。
工作原理
既然你已经了解了计算组如何使用户受益,接下来让我们看看如何创建显示的时间智能计算组示例。
在详细介绍之前,让我们介绍一些专门针对计算组的新 DAX 函数:
SELECTEDMEASURE - 由计算项的表达式用于引用当前处于上下文中的度量值。 在此示例中,Sales 度量值。
SELECTEDMEASURENAME - 由计算项的表达式用于按名称确定上下文中的度量值。
ISSELECTEDMEASURE - 计算项的表达式用于确定在度量值列表中指定的上下文中的度量值。
SELECTEDMEASUREFORMATSTRING - 由计算项的表达式用于检索上下文中度量值的格式字符串。
时间智能示例
表名称 - 时间智能
列名称 - 时间计算
优先级 - 20
时间智能计算项
Current
SELECTEDMEASURE()
Mtd
CALCULATE(SELECTEDMEASURE(), DATESMTD(DimDate[Date]))
QTD
CALCULATE(SELECTEDMEASURE(), DATESQTD(DimDate[Date]))
YTD
CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date]))
PY
CALCULATE(SELECTEDMEASURE(), SAMEPERIODLASTYEAR(DimDate[Date]))
PY MTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "MTD"
)
PY QTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "QTD"
)
PY YTD
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
YOY
SELECTEDMEASURE() -
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation] = "PY"
)
YOY%
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
若要测试此计算组,请在 SSMS 或开源 DAX Studio 中执行 DAX 查询。 注意:此查询示例中省略了 YOY 和 YOY%。
时间智能查询
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
DimDate[CalendarYear],
DimDate[EnglishMonthName],
"Current", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "Current" ),
"QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "QTD" ),
"YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "YTD" ),
"PY", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY" ),
"PY QTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY QTD" ),
"PY YTD", CALCULATE ( [Sales], 'Time Intelligence'[Time Calculation] = "PY YTD" )
),
DimDate[CalendarYear] IN { 2012, 2013 }
)
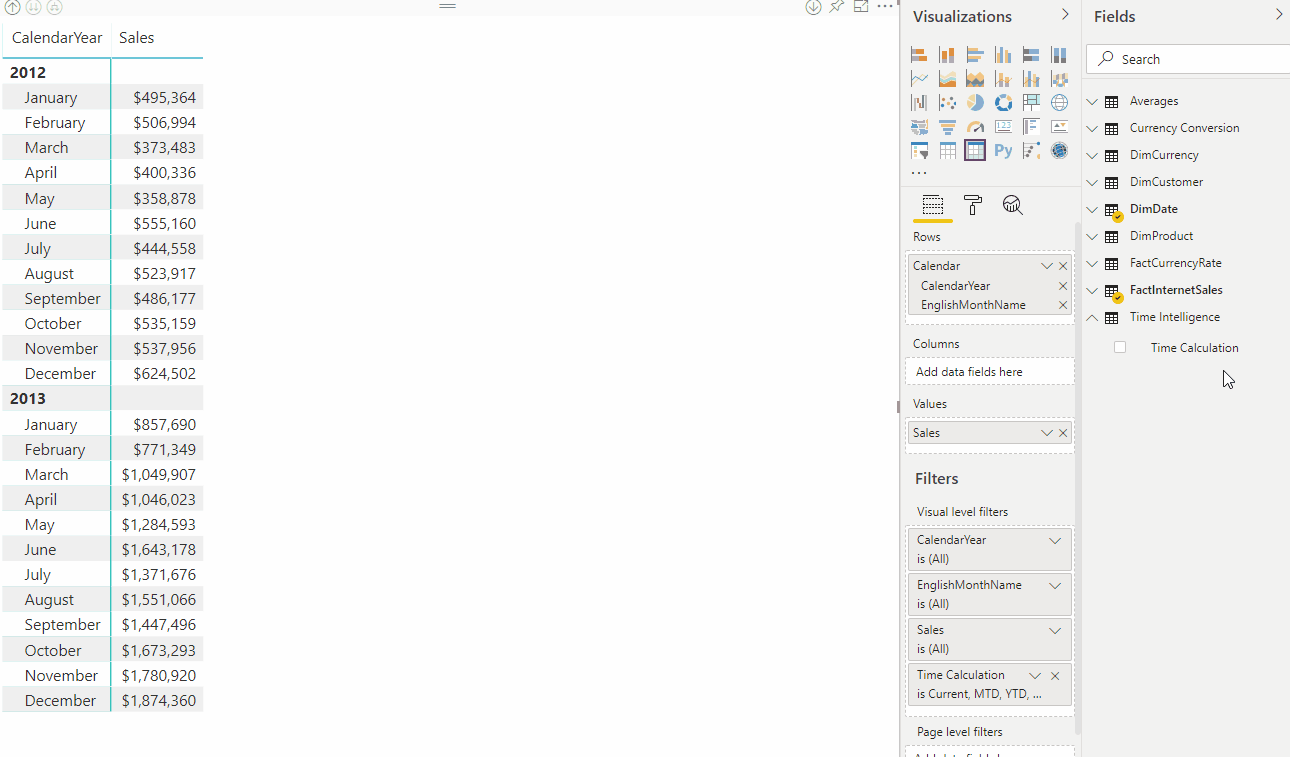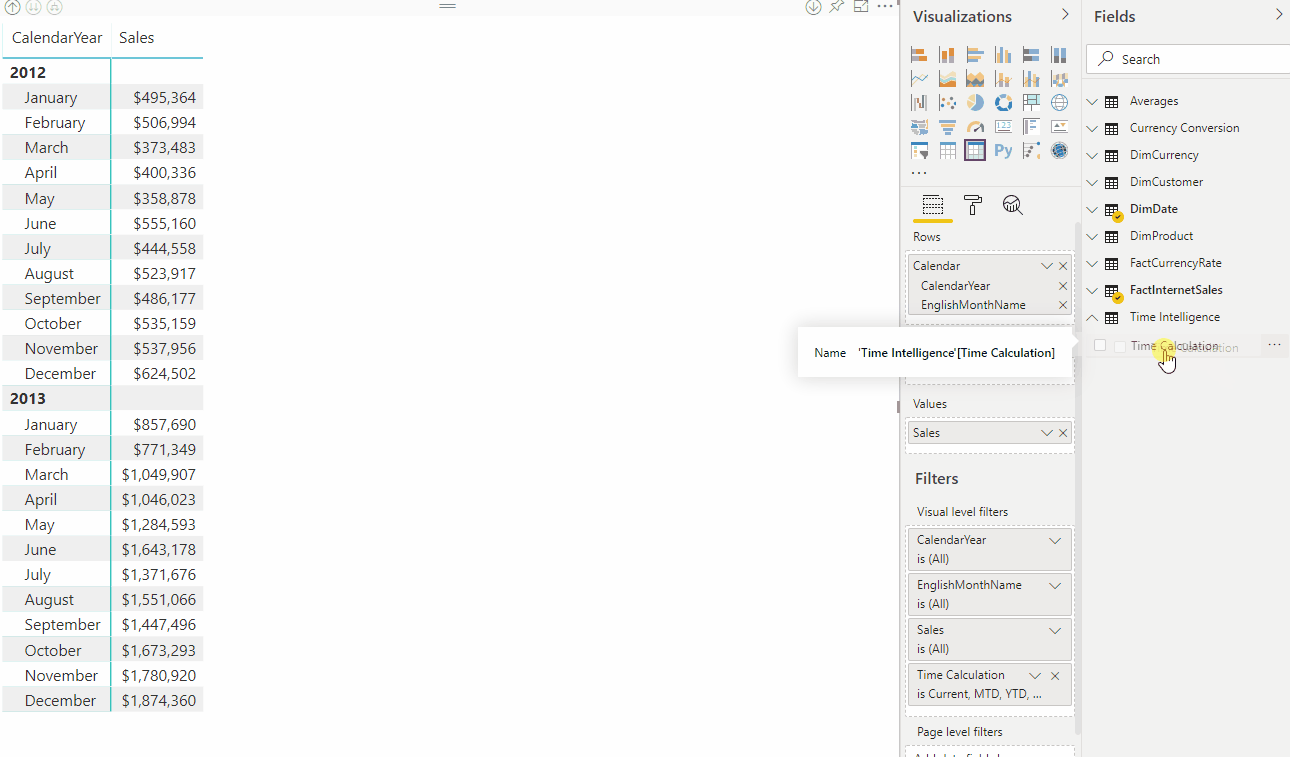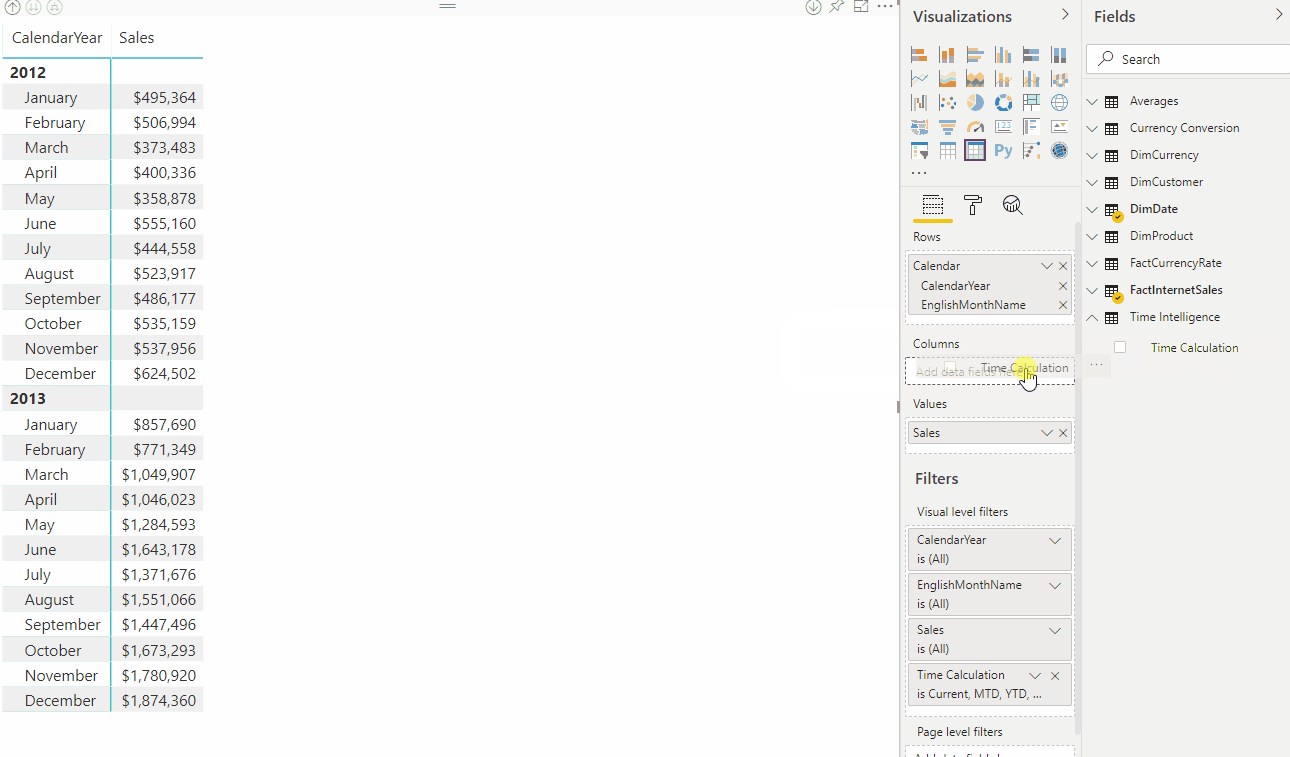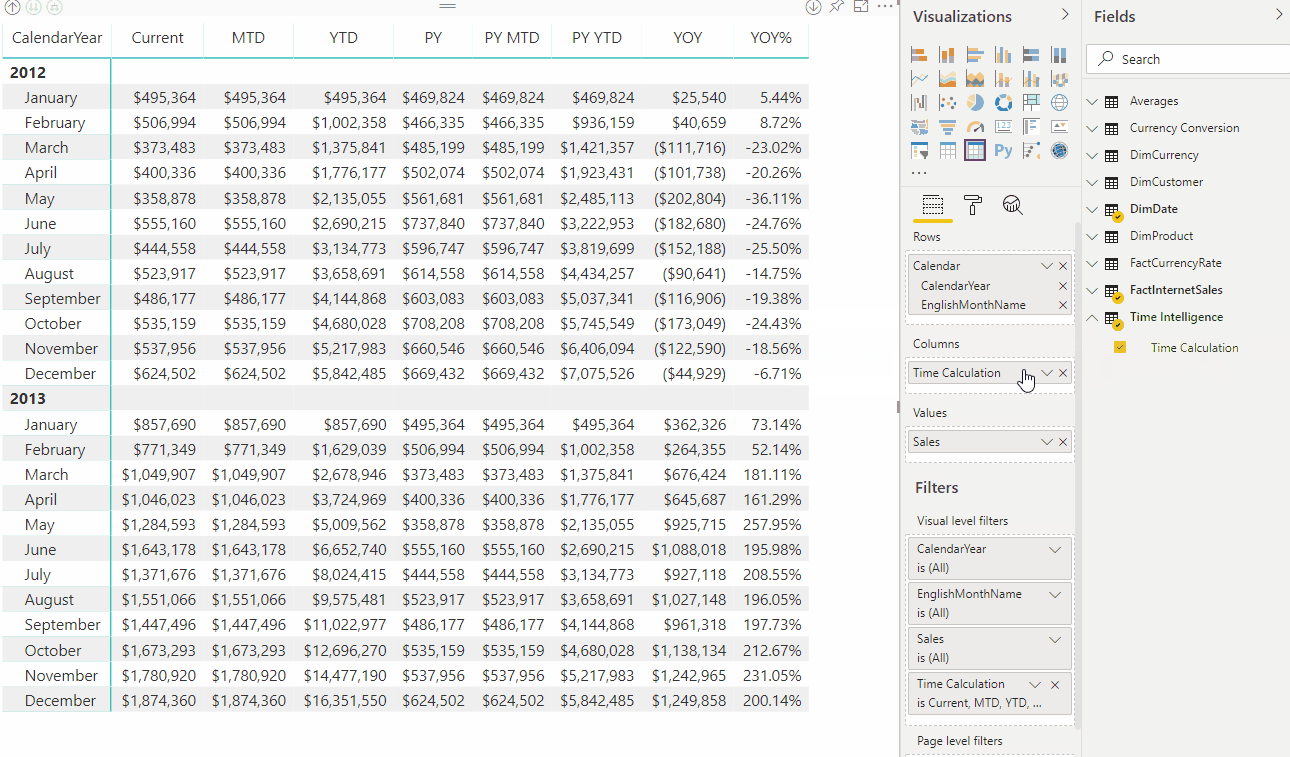
时间智能查询返回
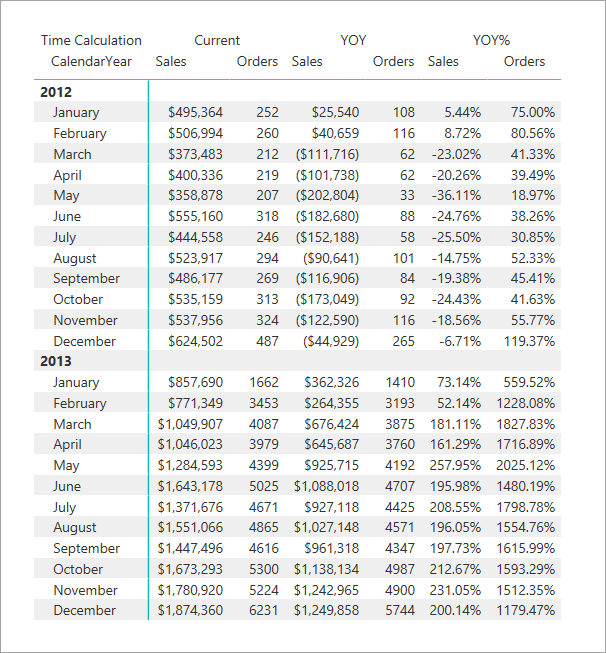
返回表显示应用的每个计算项的计算。 例如,请参阅 2012 年 3 月的 QTD 是 2012 年 1 月、2 月和 3 月的总和。

动态格式字符串
具有计算组的动态格式字符串允许将格式字符串有条件地应用于度量值,而无需强制它们返回字符串。
表格模型支持使用 DAX 的 FORMAT 函数动态设置度量值格式。 但是,FORMAT 函数的缺点是返回字符串,强制本来是数值的度量值也作为字符串返回。 这可能有一些限制,例如不能使用大多数 Power BI 视觉对象,具体取决于数字值,如图表。
在 Power BI 中,度量值的动态格式字符串还允许将格式字符串有条件地应用于特定度量值,而无需强制它们返回字符串,也无需使用计算组。 若要了解详细信息,请参阅 度量值的动态格式字符串。
用于时间智能的动态格式字符串
如果我们查看上面所示的时间智能示例,则除 YOY% 之外 的所有计算项都应在上下文中使用当前度量值的格式。 例如,根据 Sales 基度量值计算的 YTD 应为货币。 如果这是 Orders 基本度量值的计算组,则格式将为数值。 但是,无论基准度量值的格式如何,YOY%都应该是一个百分比。
对于 YOY%,可以通过将格式字符串表达式属性设置为 0.00%;-0.00%;来替代格式字符串;0.00%。 若要详细了解格式字符串表达式属性,请参阅 MDX 单元格属性 - FORMAT STRING 内容。
在 Power BI 的此矩阵视觉对象中,可以看到 Sales Current/YOY 和 Orders Current/YOY 保留各自的基本度量值格式字符串。 但是,销售额 YOY% 和 Orders YOY%会替代格式字符串以使用百分比格式。
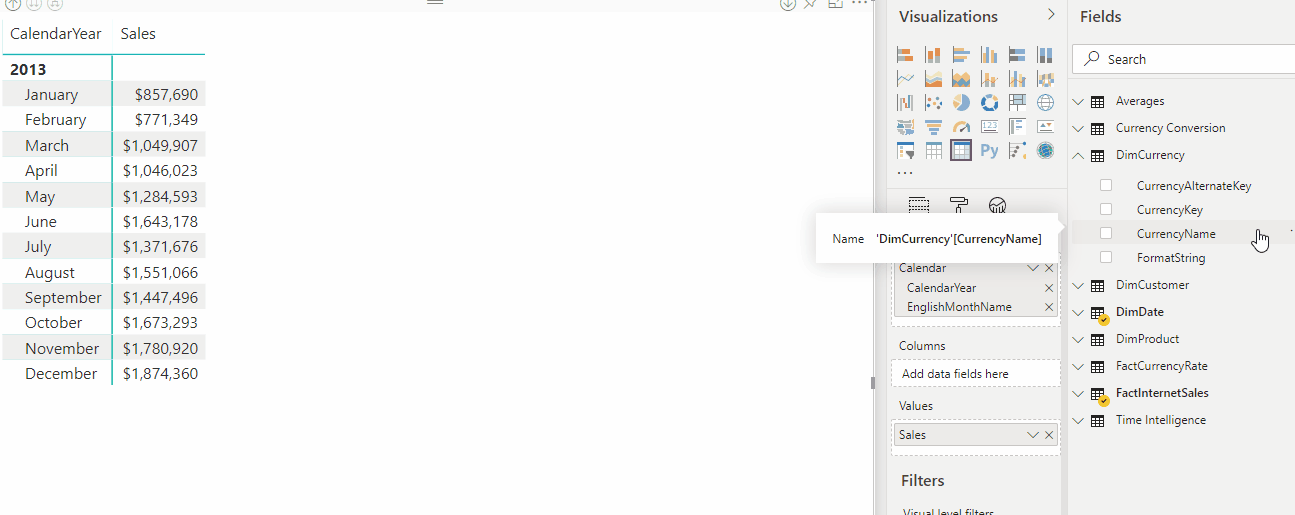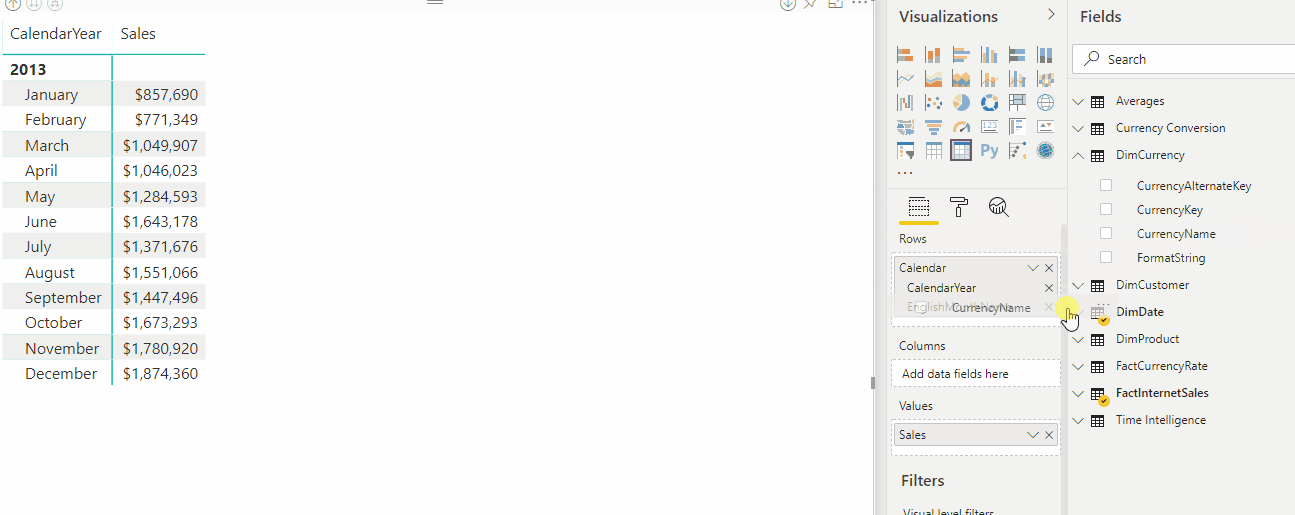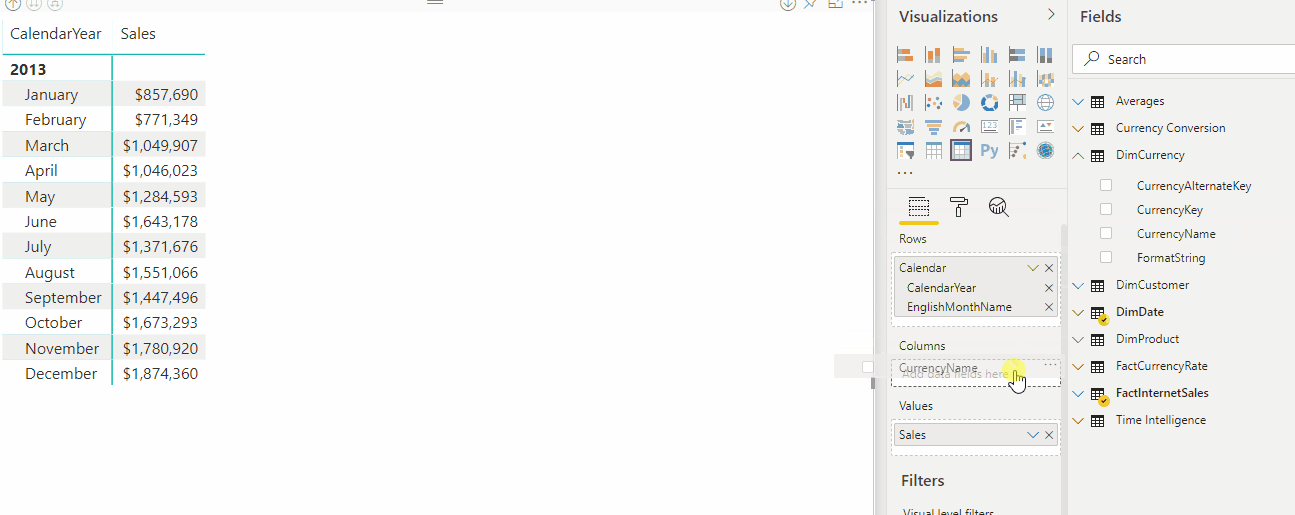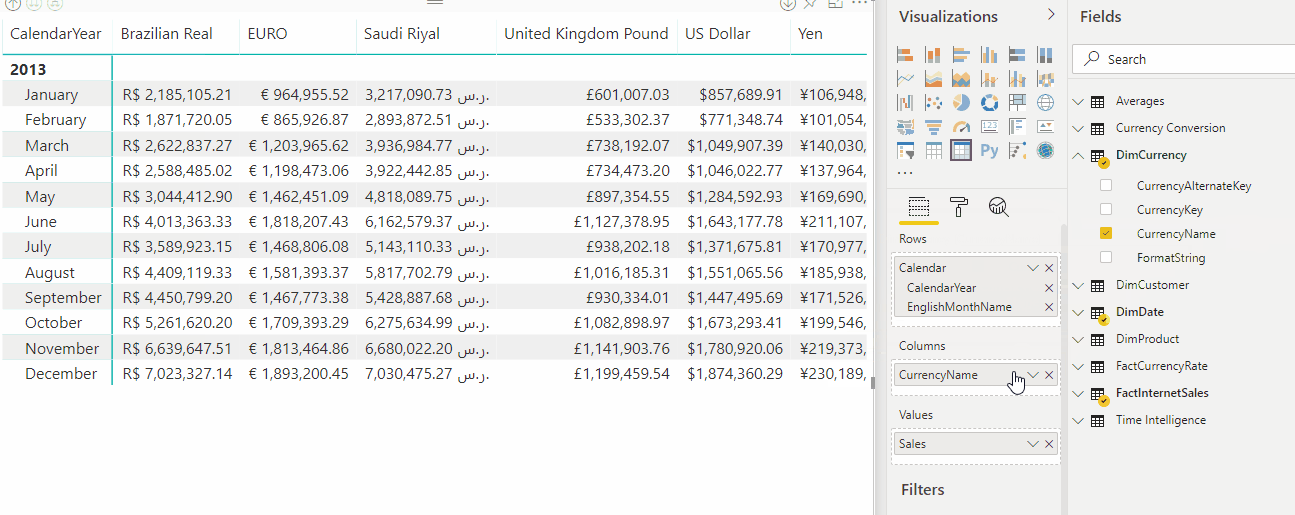
用于货币换算的动态格式字符串
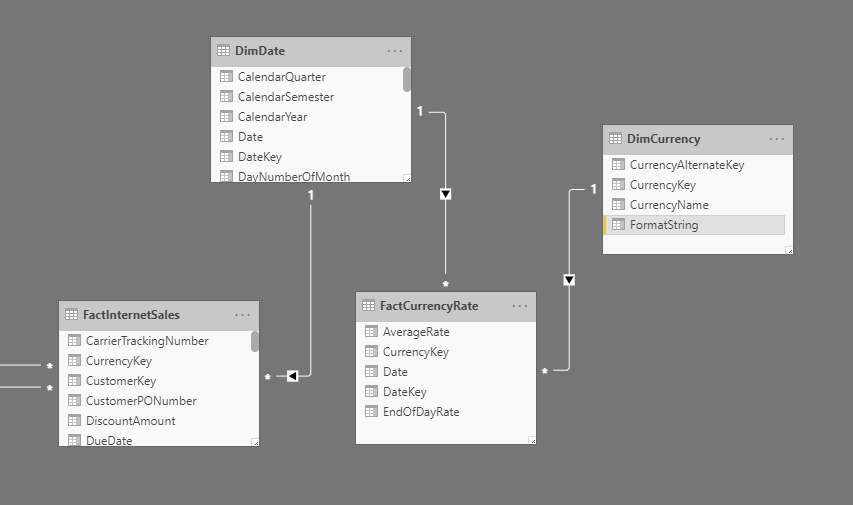
动态格式字符串提供简单的货币转换。 请考虑以下 Adventure Works 数据模型。 它针对转换类型定义的一对多货币换算进行了建模。
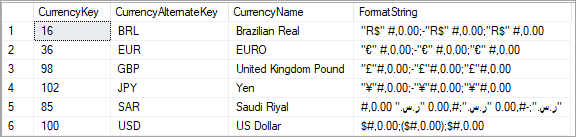
FormatString 列将添加到 DimCurrency 表,并使用相应货币的格式字符串填充。
对于此示例,以下计算组随后定义为:
货币换算示例
表名称 - 货币换算
列名称 - 转换计算
优先级 - 5
货币换算的计算项
无转换
SELECTEDMEASURE()
转换后的货币
IF(
//Check one currency in context & not US Dollar, which is the pivot currency:
SELECTEDVALUE( DimCurrency[CurrencyName], "US Dollar" ) = "US Dollar",
SELECTEDMEASURE(),
SUMX(
VALUES(DimDate[Date]),
CALCULATE( DIVIDE( SELECTEDMEASURE(), MAX(FactCurrencyRate[EndOfDayRate]) ) )
)
)
格式字符串表达式
SELECTEDVALUE(
DimCurrency[FormatString],
SELECTEDMEASUREFORMATSTRING()
)
注意
计算组的选择表达式目前处于预览状态,可用于在计算组上实现自动货币换算,无需有两个单独的计算项。
格式字符串表达式必须返回标量字符串。 如果筛选器上下文中有多个货币,它使用新的 SELECTEDMEASUREFORMATSTRING 函数还原基本度量值格式字符串。
以下动画显示了报表中 Sales 度量值的动态格式货币换算。
预览) (选择表达式
选择表达式是为计算组定义的可选属性。 有两种类型的选择表达式:
- multipleOrEmptySelectionExpression。 当已选择多个计算项、选择了一个不存在的计算项或进行了冲突的选择时,将应用此选择表达式。
- noSelectionExpression。 未筛选计算组时,将应用此选择表达式。
这两个选择表达式还具有 formatStringDefinition 动态格式字符串 表达式。
总之,在计算组上可以定义以下内容:
...
"calculationGroup": {
"multipleOrEmptySelectionExpression": {
"expression": "",
"formatStringDefinition": {...}
},
"noSelectionExpression": {
"expression": "",
"formatStringDefinition": {...}
}
...
}
注意
这些表达式(如果指定)仅适用于上述特定情况。 单个计算项的选择不受这些表达式的影响。
下面概述了这些表达式及其默认行为(如果未指定):
| 选择类型 | 未 (默认) 定义选择表达式 | 定义的选择表达式 |
|---|---|---|
| 单选 | 应用所选内容 | 应用所选内容 |
| 多重选择 | 未筛选计算组 | 返回计算 multipleOrEmptySelectionExpression 的结果 |
| 空选定内容 | 未筛选计算组 | 返回计算 multipleOrEmptySelectionExpression 的结果 |
| 无选定内容 | 未筛选计算组 | 返回计算 noSelectionExpression 的结果 |
多选或空选择
如果对同一计算组进行了多个选择,则计算组将计算并返回 multipleOrEmptySelectionExpression(如果已定义)的结果。 如果尚未定义此表达式,则计算组将返回以下结果:
SELECTEDMEASURE()
例如,让我们看看名为 MyCalcGroup 的计算组,该计算组配置了 multipleOrEmptySelectionExpression,如下所示:
IF (
ISFILTERED ( 'MyCalcGroup' ),
"Filters: "
& CONCATENATEX (
FILTERS ( 'MyCalcGroup'[Name] ),
'MyCalcGroup'[Name],
", "
)
)
现在,假设对计算组进行以下选择:
EVALUATE
{
CALCULATE (
[MyMeasure],
'MyCalcGroup'[Name] = "item1" || 'MyCalcGroup'[Name] = "item2"
)
}
在这里,我们在计算组上选择两个项:“item1”和“item2”。 这是一个多重选择,因此会计算 multipleOrEmptySelectionExpression 并返回以下结果:“Filters: item1, item2”。
接下来,对计算组进行以下选择:
EVALUATE
{
CALCULATE (
[MyMeasure],
'MyCalcGroup'[Name] = "item4" -- item4 does not exists
)
}
这是空选择的示例,因为此计算组中不存在“item4”。 因此,将计算 multipleOrEmptySelectionExpression 并返回以下结果:“Filters:”。
无选定内容
如果未筛选计算组,将应用计算组上的 noSelectionExpression。 这主要用于执行默认操作,而无需用户执行操作,同时仍为用户提供替代默认操作的灵活性。 例如,让我们看看以美元为中心支点货币的自动货币换算。
可以使用以下 noSelectionExpression 设置计算组:
IF (
//Check one currency in context & not US Dollar, which is the pivot currency:
SELECTEDVALUE (
DimCurrency[CurrencyName],
"US Dollar"
) = "US Dollar",
SELECTEDMEASURE (),
SUMX (
VALUES ( DimDate[DateKey] ),
CALCULATE (
DIVIDE ( SELECTEDMEASURE (), MAX ( FactCurrencyRate[EndOfDayRate] ) )
)
)
)
我们还将为此表达式设置 formatStringDefinition:
SELECTEDVALUE(
DimCurrency[FormatString],
SELECTEDMEASUREFORMATSTRING()
)
现在,如果未选择货币,则根据需要,所有货币将自动转换为先导货币 (美元) 。 除此之外,你仍然可以选择另一种货币来转换为该货币,而无需切换计算项,就像没有 noSelectionExpression 一样。
优先级
优先级是为计算组定义的属性。 它指定在计算项中使用 SELECTEDMEASURE () 时计算组与基础度量值的组合顺序。
优先级示例
让我们来举一个简单的示例。 此模型具有一个指定值为 10 的度量值和两个计算组,每个计算组都有一个计算项。 我们将这两个计算组的计算项应用于度量值。 下面是设置它的方式:
'Measure group'[Measure] = 10
第一个计算组为 'Calc Group 1 (Precedence 100)' ,计算项为 'Calc item (Plus 2)':
'Calc Group 1 (Precedence 100)'[Calc item (Plus 2)] = SELECTEDMEASURE() + 2
第二个计算组为 'Calc Group 2 (Precedence 200)' ,计算项为 'Calc item (Times 2)':
'Calc Group 2 (Precedence 200)'[Calc item (Times 2)] = SELECTEDMEASURE() * 2
可以看到计算组 1 的优先级值为 100,计算组 2 的优先级值为 200。
通过使用 SQL Server Management Studio (SSMS) 或具有 XMLA 读写功能的外部工具(如开源表格编辑器),可以使用 XMLA 脚本创建计算组并设置优先级值。 此处添加 "Calc group 1 (Precedence 100)":
{
"createOrReplace": {
"object": {
"database": "CHANGE TO YOUR DATASET NAME",
"table": "Calc group 1 (Precedence 100)"
},
"table": {
"name": "Calc group 1 (Precedence 100)",
"calculationGroup": {
"precedence": 100,
"calculationItems": [
{
"name": "Calc item (Plus 2)",
"expression": "SELECTEDMEASURE() + 2",
}
]
},
"columns": [
{
"name": "Calc group 1 (Precedence 100)",
"dataType": "string",
"sourceColumn": "Name",
"sortByColumn": "Ordinal",
"summarizeBy": "none",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
},
{
"name": "Ordinal",
"dataType": "int64",
"isHidden": true,
"sourceColumn": "Ordinal",
"summarizeBy": "sum",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
}
],
"partitions": [
{
"name": "Partition",
"mode": "import",
"source": {
"type": "calculationGroup"
}
}
]
}
}
}
此脚本添加 "Calc group 2 (Precedence 200)":
{
"createOrReplace": {
"object": {
"database": "CHANGE TO YOUR DATASET NAME",
"table": "Calc group 2 (Precedence 200)"
},
"table": {
"name": "Calc group 2 (Precedence 200)",
"calculationGroup": {
"precedence": 200,
"calculationItems": [
{
"name": "Calc item (Times 2)",
"expression": "SELECTEDMEASURE() * 2"
}
]
},
"columns": [
{
"name": "Calc group 2 (Precedence 200)",
"dataType": "string",
"sourceColumn": "Name",
"sortByColumn": "Ordinal",
"summarizeBy": "none",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
},
{
"name": "Ordinal",
"dataType": "int64",
"isHidden": true,
"sourceColumn": "Ordinal",
"summarizeBy": "sum",
"annotations": [
{
"name": "SummarizationSetBy",
"value": "Automatic"
}
]
}
],
"partitions": [
{
"name": "Partition",
"mode": "import",
"source": {
"type": "calculationGroup"
}
}
]
}
}
}
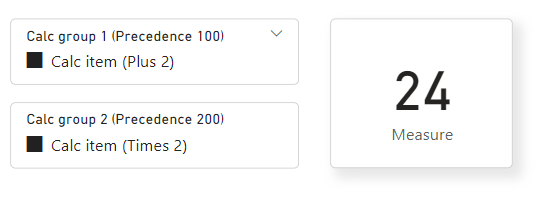
在 Power BI Desktop 中,我们有一个卡视觉对象,其中显示了报表视图中每个计算组的度量值和切片器:
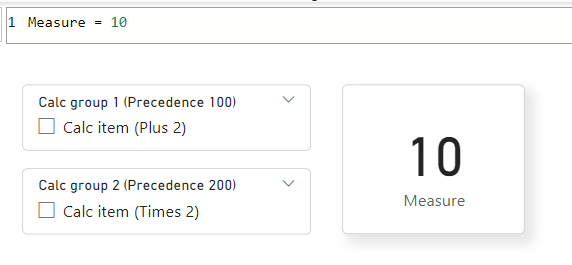
选择这两个切片器后,需要合并 DAX 表达式。 为此,我们从优先级最高的计算项 200 开始,然后将 SELECTEDMEASURE () 参数替换为下一个最高的 100。
因此,我们优先级最高的计算项 DAX 表达式是:
SELECTEDMEASURE() * 2
优先级第二高的计算项 DAX 表达式是:
SELECTEDMEASURE() + 2
现在,通过将最高优先级计算项的 SELECTEDMEASURE () 部分替换为下一个优先级最高的计算项,将它们组合在一起,如下所示:
( SELECTEDMEASURE() + 2 ) * 2
然后,如果有更多计算项,我们继续操作,直到到达基础度量值为止。 此模型中只有两个计算组,因此我们现在将 SELECTEDMEASURE () 替换为度量值本身,如下所示:
( ( [Measure] ) + 2 ) * 2
Measure = 10与我们的 一样,这与:
( ( 10 ) + 2 ) * 2
当没有更多 SELECTEDMEASURE () 参数时,将计算组合的 DAX 表达式:
( ( 10 ) + 2 ) * 2 = 24
在 Power BI Desktop 中,当两个计算组都通过切片器应用时,度量值输出如下所示:
但请记住,组合嵌套的方式不会是 10 + 2 * 2 = 14,如下所示:
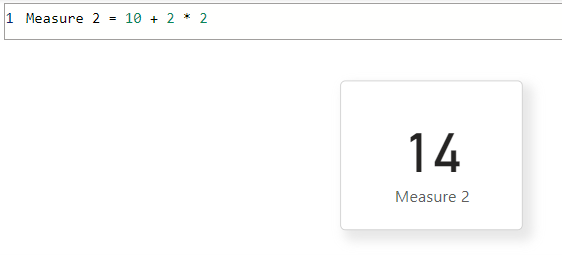
对于简单转换,评估的优先级从低到高。 例如,10 有 2 相加,然后乘以 2。 在 DAX 中,有一些函数(如 CALCULATE)可将筛选器或上下文更改应用于内部表达式。 在这种情况下,较高优先级会更改优先级较低的表达式。
优先级还确定将哪个动态格式字符串应用于每个度量值的组合 DAX 表达式。 优先级最高的计算组动态格式字符串是唯一应用的格式字符串。 如果度量值本身具有动态格式字符串,则它被视为模型中任何计算组的优先级较低。
包含平均值的优先级示例
让我们看看另一个示例,使用本文前面所述的时间智能示例中所示的同一模型。 但这一次,我们还要添加 一个 Averages 计算组。 “平均值”计算组包含独立于传统时间智能的平均计算,因为它们不会更改日期筛选器上下文 ,它们只是在其中应用平均值计算。
在此示例中,定义了每日平均计算。 计算(如每日平均桶石油)在石油和天然气应用中很常见。 其他常见业务示例包括零售商店平均销售额。
虽然此类计算独立于时间智能计算进行计算,但很可能需要将它们组合在一起。 例如,用户可能想要查看日石油桶的 YTD,以查看从年初到当前日期的每日油价。 在这种情况下,应为计算项设置优先级。
我们的假设是:
表名称为 Averages。
列名为 “平均计算”。
优先级为 10。
平均值的计算项
无平均值
SELECTEDMEASURE()
每日平均值
DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate))
下面是 DAX 查询和返回表的示例:
Averages 查询
EVALUATE
CALCULATETABLE (
SUMMARIZECOLUMNS (
DimDate[CalendarYear],
DimDate[EnglishMonthName],
"Sales", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "Current",
'Averages'[Average Calculation] = "No Average"
),
"YTD", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "YTD",
'Averages'[Average Calculation] = "No Average"
),
"Daily Average", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "Current",
'Averages'[Average Calculation] = "Daily Average"
),
"YTD Daily Average", CALCULATE (
[Sales],
'Time Intelligence'[Time Calculation] = "YTD",
'Averages'[Average Calculation] = "Daily Average"
)
),
DimDate[CalendarYear] = 2012
)
平均值查询返回
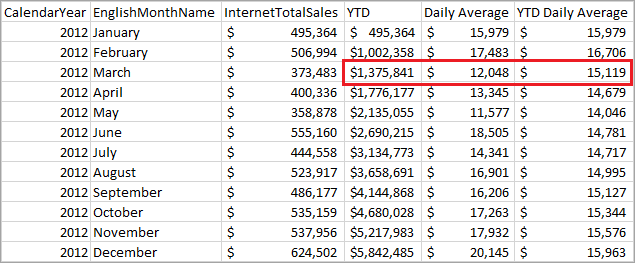
下表显示了如何计算 2012 年 3 月的值。
| 列名称 | 计算 |
|---|---|
| YTD | 2012 年 1 月、2 月、3 月的销售额总和 = 495,364 + 506,994 + 373,483 |
| 每日平均值 | 2012 年 3 月销售额除以 3 月天数 = 373,483 / 31 |
| YTD 每日平均值 | 2012 年 3 月的 YTD 除以 1 月、2 月和 3 月的天数 = 1,375,841 / (31 + 29 + 31) |
下面是以 20 为优先级应用的 YTD 计算项的定义。
CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date]))
此处为每日平均,应用的优先级为 10。
DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate))
由于时间智能计算组的优先级高于平均值计算组的优先级,因此应用范围尽可能广泛。 YTD 每日平均值计算将 YTD 应用于分子和分母 (每日平均值计算) 的天数计数。
这等效于以下表达式:
CALCULATE(DIVIDE(SELECTEDMEASURE(), COUNTROWS(DimDate)), DATESYTD(DimDate[Date]))
不是此表达式:
DIVIDE(CALCULATE(SELECTEDMEASURE(), DATESYTD(DimDate[Date])), COUNTROWS(DimDate)))
侧向递归
在上面的时间智能示例中,某些计算项引用同一计算组中的其他项。 这称为 侧归递归。 例如, YOY% 引用 YOY 和 PY。
DIVIDE(
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="YOY"
),
CALCULATE(
SELECTEDMEASURE(),
'Time Intelligence'[Time Calculation]="PY"
)
)
在这种情况下,这两个表达式将单独计算,因为它们使用不同的计算语句。 不支持其他类型的递归。
筛选器上下文中的单个计算项
在时间智能示例中, PY YTD 计算项有一个计算表达式:
CALCULATE(
SELECTEDMEASURE(),
SAMEPERIODLASTYEAR(DimDate[Date]),
'Time Intelligence'[Time Calculation] = "YTD"
)
CALCULATE () 函数的 YTD 参数替代筛选器上下文,以重用已在 YTD 计算项中定义的逻辑。 不能在单个评估中同时应用 PY 和 YTD。 仅当计算组中的单个计算项位于筛选器上下文中时,才 应用 计算组。
中间件排序
默认情况下,在报表中放置计算组中的列时,计算项按名称的字母顺序排序。 通过指定 Ordinal 属性可以更改报表中出现的计算项的顺序。 使用 Ordinal 属性指定计算项顺序不会更改计算项的 计算顺序的优先级。 也不会更改计算项在表格模型资源管理器中的显示顺序。
若要指定计算项的序号属性,必须将第二列添加到计算组。 与数据类型为文本的默认列不同,用于对计算项进行排序的第二列具有整数数据类型。 此列的唯一用途是指定计算组中计算项的显示顺序。 由于此列在报表中不提供任何值,因此最好将 Hidden 属性设置为 True。
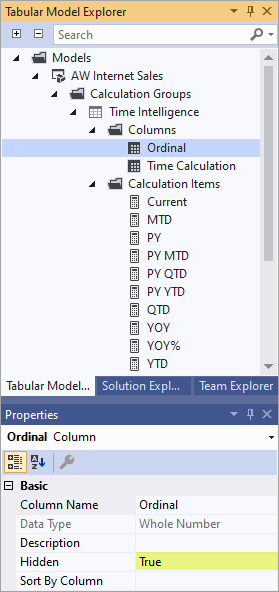
将第二列添加到计算组后,可以为要排序的计算项指定 Ordinal 属性值。
若要了解详细信息,请参阅 对计算项进行排序。
创建计算组
Visual Studio 支持 Analysis Services 项目 VSIX 更新 2.9.2 及更高版本的计算组。 也可以使用表格模型脚本语言 (TMSL) 或开放源代码表格编辑器来创建计算组。
使用 Visual Studio 创建计算组
在表格模型资源管理器中,右键单击“ 计算组”,然后单击“ 新建计算组”。 默认情况下,新的计算组具有单个列和单个计算项。
使用 “属性” 更改名称,并输入计算组、列和默认计算项的说明。
若要为默认计算项输入 DAX 公式表达式,请右键单击,然后单击“编辑公式”以打开 DAX 编辑器。 输入有效的表达式。
若要添加更多计算项,请右键单击“ 计算项”,然后单击“ 新建计算项”。
对计算项进行排序
在表格模型资源管理器中,右键单击计算组,然后单击“ 添加列”。
将列命名为 Ordinal (或类似) ,输入说明,然后将 Hidden 属性设置为 True。
对于要订购的每个计算项,将 Ordinal 属性设置为正数。 每个数字都是连续的,例如,先显示序号属性为 1 的计算项,第二个显示属性 2,依序排列。 默认为 -1 的计算项不包括在排序中,而是显示在报表中已排序的项之前。
限制
不支持在计算组表上定义的对象级别安全性 (OLS) 。 但是,可以在同一模型中的其他表上定义 OLS。 如果计算项引用受 OLS 保护的对象,则返回一般错误。
不支持行级别安全性 (RLS) 。 在同一模型中的表上定义 RLS,但不定义计算组本身 (直接或间接) 。
计算组不支持详细信息行表达式。
计算组不支持 Power BI 中的智能叙事视觉对象。
具有计算组的模型不支持 Power BI 中的隐式列聚合。 目前,如果 DiscourageImplicitMeasures 属性设置为 false (默认) ,则会显示聚合选项,但无法应用它们。 如果 DiscourageImplicitMeasures 设置为 true,则不显示聚合选项。
使用 LiveConnection 创建 Power BI 报表时,动态格式字符串不会应用于报表级度量值。